
压缩感知在视频编解码中的发展与应用
2020-06-30 09:13
广东通信技术 2020年6期
1 引言
近些年,随着物联网和移动互联网的发展出现了如移动可视电话、无线可视会议等大量的视频应用。这些视频应用终端设备一般都具有计算和存储能力有限的特点。而随着图像和视频的使用在日常生活和工作中所占比重逐渐增大,庞大的多媒体数据给数据的采集、计算、存储和传输带来了巨大的挑战。传统的视频编解码标准,如MPEG-x和H.26x,在编码端由于要进行非常复杂的计算,其编码设备往往需要具有较高的计算性能,这就导致传统视频编解码标准很难适用于这类新兴视频应用。
为解决上述问题,一种以无损编码理论[1]和有损编码理论[2]为基础的无线视频编码方案——分布式视频编码(Distributed Video Coding,DVC)被提出并得到了广泛的关注。与传统视频编解码标准不同的是,分布式视频编码将视频序列看做是统计相关的信源进行独立编码,在解码端利用帧间相关性进行联合译码。该方案在一定程度上降低了编码端的复杂度,并且具有抗误码性能好、易形成分级编码码流等特点。但是其仍受奈奎斯特采样定理限制,依然具有非常高的采样率。
2006年,压缩感知理论被提出[3],该理论指出对于稀疏信号可通过远低于奈奎斯特定理要求的采样率进行采样并且能高概率恢复。因此有研究学者将压缩感知与分布式视频编码结合,提出了分布式视频压缩感知(Distributed Video Compressed Sensing,DVCS)方案。由于DVCS具备分布式视频编码与压缩感知的双重优点,使其一直成为近些年的研究热点。
近年来,深度学习技术在机器学习问题上取得了众多令人瞩目的成果,成为机器学习领域中最亮眼的一个分支[4]。由于其在特征提取和图像分类方面有着明显的优势,使其与压缩感知技术的结合成为一种新的思路。基于深度学习的压缩感知视频重建技术具有极高的重构速度与可比的重构质量,目前也成为了视频压缩重构领域的研究热点之一。
2 压缩感知理论
压缩感知突破了奈奎斯特采样定理的瓶颈,可以实现在信号采样的同时完成压缩,并利用较少的采样值对信号进行重建,实现了低复杂度的压缩编码。压缩感知理论原理描述如下:
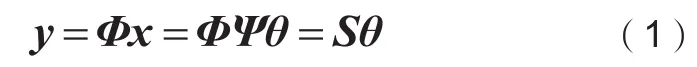
3 分布式视频压缩感知
分布式视频压缩感知在分布式视频编码的基础上引入了压缩感知技术,其可以直接对测量值进行量化传输,少了DVC中较多繁琐的操作,因此具有较低的编码计算复杂度,非常适合在近些年新兴出现的无线视频终端中应用。
在早期,Prades-Nebot J等人在DVC的基础上提出了基于压缩感知的分布式视频编码系统DISCUS[5]。该系统针对关键帧依然采用传统帧内编码方法,而对于CS帧则需要经过CS测量、均匀量化和比特存储等步骤。在解码端,根据反馈信道传输的比特数结合关键帧对CS帧进行重构。该系统由于存在反馈信道,因此实时性较差,而且关键帧仍然采用传统帧内编码方法,因此编码端复杂度较高。之后Kang L W等人对DISCUS系统进行了改进,提出了一种新的DVCS方案[6],如图1所示。该方案在编码端对关键帧和CS帧均采用CS测量,而且去掉了反馈信道。在解码端,利用重构关键帧内插生成的边信息恢复CS帧。
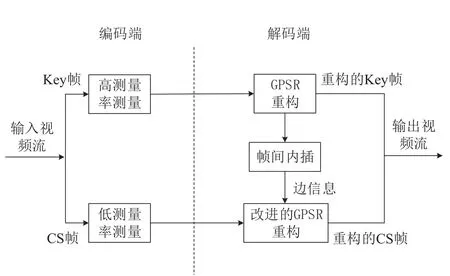
图1 Kang L W提出的DVCS方案
该方案虽然解决了实时性问题,但是由于其编码端均是整帧测量,因此编码端存储开销较大。
由于上述框架在视频重构质量上与传统框架仍有一定的差距,因此为了提高视频重构效果,有较多学者在上述框架基础上进行了深入的研究,主要是如何突破以下几个方面的问题:① 根据图像结构复杂程度,如何提出更高效的自适应采样率分配方案,以最大效率利用采样值;② 探索更高效的重构算法,使视频信号的重构更加精确;③ 如何根据视频信号的时空相关性构造更精确的边信息,以达到更好的重构效果。
针对第一个问题,文献[7]根据图像块的复杂程度,利用图像块的全变差分值进行采样率的自适应分配。该算法虽然提高了重构质量,但是算法复杂度较高。文献[8]对图像进行小波变换分解,以均值及熵为标准进行自适应采样,实现了图像块的分类压缩重构。文献[9]利用不同图像块间的不同统计特性对采样率进行自适应分配,提高了图像的重构质量。文献[10]根据视觉显著特性提出了一种自适应分块压缩感知算法,进一步提高了视频的重构质量。
针对第二个问题,其主要依赖于单帧图像的重构算法。文献[11]利用图像梯度域具有稀疏性的特征,通过最小全变差算法重建二维图像。该方法虽然能够获得较好的重构质量但是具有极大的重构复杂度。平滑投影Landweber算 法[12](Smoothed Projected Landweber,SPL)专门针对图像分块测量情形,通过维纳滤波有效消除了图像的块效应。由于该算法的高效性,其被广泛应用于视频图像重构。组稀疏重构(Group-based Sparse Representation,GSR)算法[13]以相似块组的奇异值具备稀疏性为前提,对每个相似块组建立自适应稀疏表示字典,进一步提高了图像的重构质量。
对于第三个问题,文献[14]将多假设预测运用到DVCS中,并利用SPL算法对视频信号进行残差重构,提出了多假设预测重构算法(Multihypothesis Prediction BCS-SPL,MH-BCS-SPL)。该算法在一定程度上利用了视频信号的时空相关性,但不够充分。文献[15]在MHBCS-SPL算法基础上对假设集进行了改进,提高了多假设预测精度。文献[16]提出一种基于弹性网的多假设视频压缩感知重构算法,其通过求解弹性网回归问题使得各假设块的权值分配更加精确。由于GSR算法的出色表现,文献[17]通过强化图像块基本特征来提高相似块匹配效果,同时引入结构相似度标准,提出了一种多假设局部增强重构算法,有效提高了视频重构质量。
4 基于深度学习的压缩感知视频重构
基于压缩感知的传统视频编解码方法是建立在信号具有稀疏性这一先验条件上的,并且需要进行多次的迭代才能达到一定的重构质量。这类方法一般存在两个问题:(1)由于重构算法多次迭代,重构时间一般较长,难以实现实时性,限制了压缩感知在视频编解码中的应用。(2)自然信号在变换域中往往不是精确稀疏的,仅由稀疏性建模的重构算法在重构过程中会带来一定质量的下降。
近年来,深度学习在计算机视觉和图像处理中显示出良好的性能。因此,许多学者将深度学习引入到视频压缩感知重构中。最先将深度学习技术与压缩感知结合的是R.G.Baraniuk团队,该团队提出了一种利用SDA对欠采样测量值进行重建的全连接框架[18]。
该框架将测量值分为线性测量和非线性测量两种方式。重建网络将SDA作为一种特征学习器来获得信号中不同元素之间的统计相关性,以此提高信号重构性能。文献[19]使用DeepInverse深度卷积神经网络来学习从测量值到原始信号的逆变换。DeepInverse网络框架如图2所示,重建网络的输入为测量值,然后通过全连接层得到原始信号的估计值,最后通过卷积层重构信号。文献[20]在实现了图像分块处理的情况下提出了ReconNet网络。该网络是基于CNN设计的网络结构,但由于卷积核较大且网络层较少,影响了重构精度。Bora等人利用生成模型构建了一个基于深度学习的压缩感知重构框架[21]。该框架虽没有利用到信号的稀疏特性,但是其假设信号接近生成模型的值域,因此能获得一定的重构性能保证。
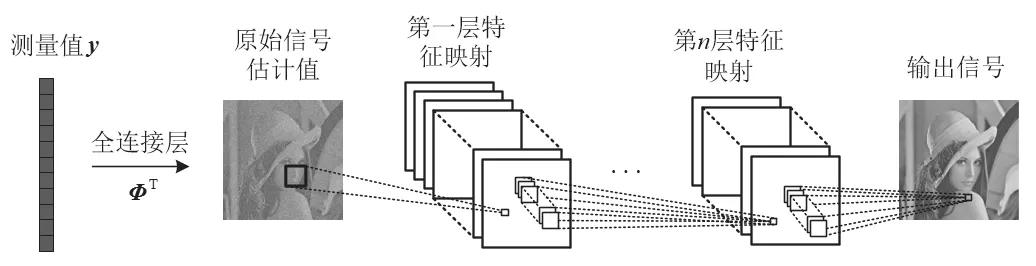
图2 DeepInverse网络框架
5 总结
由于压缩感知在信号处理方面具有独特的优势,现已广泛应用于视频图像处理领域。在传统的分布式视频压缩感知方法中,由于迭代算法重构复杂度较高,因此很难在有实时性要求的应用中实现。此外,DVCS对非关键帧的重构质量也有待进一步提高。为了提高视频图像处理的速度和质量,深度学习被应用到压缩感知视频重构中。基于深度学习的压缩感知视频重构算法具有着极高的重构速度,能实现实时重构,但其灵活性较差,在不同采样率下均需进行模型训练,并且重构性能也有待提高。总之,不论是分布式视频压缩感知方法还是基于深度学习的压缩感知重构方法,其重构质量与传统编解码方法对比还有一定差距。如何将DV1CS与深度学习有效结合还需要研究者们积极、共同的努力。
猜你喜欢
微处理机(2020年5期)2020-10-20
空间科学学报(2020年4期)2020-04-22
传播与制作(2019年9期)2019-10-20
民用飞机设计与研究(2019年2期)2019-08-05
中国惯性技术学报(2019年6期)2019-03-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
雷达与对抗(2015年3期)2015-12-09
