
全球性剥削型人口贩运发案率的评估策略研究
2020-06-30 01:42:06张晓东凯尔文森特吴一澜
河南警察学院学报 2020年3期
张晓东,凯尔·文森特 (著); 吴一澜(译)
一、基于外推法的全球估算
在评估全球性剥削人口贩运的发案率方面,学术界面临两大挑战:共同或商定的措施以及可行的数据收集方法。应对第二项挑战,本文提出了一些数据收集策略,这些策略的前提是性剥削主要发生在商业性交易中,并且有一些可确定的地理边界,潜在的受害者保持着社会网络,或以某种方式与其他人联系在一起。
本研究的策略可以适用于在估计人口贩运活动中常见的两个主要数据背景:使用现有记录和收集主要数据。第一种方法旨在分析已查明的贩运案件,获得其已经存在且须加以挖掘的数据。第二种策略旨在通过调查方法从难以找到的受害者那里收集第一手数据。关于人口贩运的实证研究仍然不发达,许多空白仍然充斥着野性的主张和耸人听闻的故事。缺乏可靠的实证证据,打击人口贩运的运动就无法持续下去,甚至无法保持可信度。
任何对人口贩运活动的全球性的评估都受到了限制,往往会引起批评甚至是其他误解。有些人甚至质疑在宏观层面评估人口贩运活动的可行性。例如威策(Weitzer)(1)Weitzer, R. 2014. New Directions in Research on Human Trafficking. Annals of the American Academy of Political and Social Science 653(1): 6-24.列举了一些值得注意的宏观评估出错的具体例子。然而政治的需要使这项评估成为必要,以便各国和国际组织能够调动资源打击人口贩运或其他严重侵犯人权行为。更重要的是,研究界有责任从科学的角度回答人口贩运是否是一种相当严重的社会弊病,需要采取相应的反制措施。由于关于人口贩运的全球调查费用昂贵得令人望而却步,从逻辑上说是不切实际的。因此必须采用一些外推法(或概括法),通过收集地方和区域数据点来得出全球估计数。
二、外推GSI模型
外推模型中的一个例子是全球奴隶制指数(GSI),该指数由设在澳大利亚的步行自由基金会(www.walkfree.org)编制,该基金会利用盖洛普民意测验国际(Gallup Poll International)战略性地收集国家数据,使用“脆弱性”模型来估计邻近国家“现代奴隶制”的普遍程度,这种做法是基于这样一种理念,即社会经济和政治条件相似的国家很可能有相似程度的奴隶制。虽然有些人可能会质疑将一个国家的条件适用于另一个国家的有效性,但这可能是进行区域或全球评估的唯一可行方法。此外,GSI的漏洞模型自2014年首次出现以来经历了几次迭代和审查。基于人类安全和预防犯罪的理论,“脆弱性”模型由24个变量组成,分为四个维度:政治权利和安全、金融和健康保护、弱势群体的保护和冲突。人口学家通常使用类似的估算方法研究人口普查间人口的流动和趋势的变化,在公共卫生中也经常使用外推策略来估计疾病的流行率。
在无法进行国家调查或无法获得有效数据的情况下,这种外推法也可能奏效。德科克(De Cock)[De Cock, M. 2007. Directions for national and international data collection on forced labor (Working Paper No.30). Geneva, Switzerland: International Labor Organization.]运用了几项评估贩运活动程度的策略,包括估计发案数程度的国家调查、针对具体劳工部门的相关机构的调查、寻求深入了解贩运受害性质的定性研究以及收集所有引起警察或服务组织注意的案件的国家数据库。虽然很少,但一些研究也使用了传统的调查方法。
最好的例子可能是甘地和平基金会和国家劳工研究所在20世纪70年代末进行的调查。该调查随机抽取了印度10个州的1000个村庄的样本,那里的农民被广泛认为依附于土地所有者。这项研究估计印度有260万抵押劳工。最近的一个例子是斯坦法特和贝克(Steinfatt and Baker)(2)Steinfatt, T.M., and Baker, S. 2011. Measuring the extent of sex trafficking in Cambodia: 2008. Bangkok, Thailand: United Nations Interagency Project on Human Trafficking.在柬埔寨进行的一项研究,研究人员在研究中使用地理绘图技术和线人访谈来估计该国性贩运受害者的人口数量。
三、 主要数据收集策略
研究人员通常依靠两个数据来源来评估人口贩运活动:媒体已经报道的案件和报告到政府机构或社会服务组织的案件。这些案件的记录存在于某处,使用系统方法对这些案件进行初步数据收集以得出估计数。现有的人口贩运知识大多数是第一类数据的反映。在提出笔者的数据收集策略之前,必须建立一些参数来划定方法的边界。首先,性贩运是一种商业活动,赚钱是贩运者的首要目标。基于这项假设,性剥削应该主要发生在已知的地方,并且有足够的潜在客户可以接触到,例如在城市中心或主要边境沿线。其次,和大多数商业活动一样,性贩运者寻求收益最大化。这意味着性贩运者必须想办法吸引顾客,比如通过散发传单或利用口碑做广告。如果使受害者完全被孤立、彼此远离,将增加贩运者操作复杂性,减少获利空间。
当然,这两个假设也有例外。笔者提出了这些数据收集方法,以适应两组实地研究基本条件:要么我们知道商业性服务机构的地理边界,要么我们对受害者可能在哪里知之甚少。
(一)标志重捕法
估计隐藏种群规模的少数可行方法之一是标记捕获抽样策略。标志重捕法起源于野生动物研究,近年来多次被用在对非法药物制造者和性工作者等犯罪人口的研究中。其基本逻辑相当直截了当:对目标群体的初始样本进行识别,并对样本中的所有个体进行标记,然后将其释放回总人口中。在这些标记的个体被分散后,绘制第二个样本。第二个样本中标记的比例近似等于被标记的个体在总体中所占的比例,如经典的Lincoln-Petersen评估模型所示,
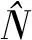
然而,当标记捕获方法应用于人类时面临着不同的挑战,由于人类种群的聚集模式可能与野生动物种群有很大的不同,在获取有意义的评估时通常需要例如以“自我选择”为形式的复杂的标记捕获模型。
(二)受访者驱动抽样(RDS)
赫卡松(1991)开发了一种基于网络的方法,称为受访(应答)者驱动抽样(RDS),旨在消除链式参考抽样方法中固有的偏差。RDS方法依靠马尔可夫链理论来实现多样性和均衡(连续样本/波不再反映初始样本的点),具体来说是通过一系列主题的招募。这种方法通过两个基本方面来改变传统的雪球抽样设计:它采用了一种双重激励系统,即奖励受访者本人参与和招募他人参与研究,并使用推荐券,这意味着受访者不必直接推荐给研究人员,由此产生的匿名性鼓励更多被试的参与。
通过结构化的流程限制招募机会以确保多样性,从而可以被实证检验。此外,因为采用了双重激励制度来鼓励参与和招募,志愿服务也被最小化了。这种招募程序也可以阻止研究人员有意寻找特定的对象,“掩蔽”被最小化,因为研究人员不能指定群体成员的方向,成员是由群体成员自己招募的。同质性也被最小化,因为招募仅限于每个受访者再招募三人,马尔可夫链理论表明,均衡性可以通过相对较少的波来实现。最后RDS最小化了那些具有较大社交网络的个体可能引入的偏差。RDS方法已成功地应用于许多关于难以接近的人群的研究中。
(三) 自适应抽样
自适应性抽样最初是为了研究分布不均匀的种群,如濒危物种或高度聚集的、隐藏的吸毒人群。该方法利用了一旦发现了高关注单元,就能观察到被抽样个体的相邻单元的能力。该程序也能够保留传统抽样策略的优点,例如获得无偏评估和控制最终样本量的能力。
在选择初始样本时,可以开发推荐(也称为提名),并在被选中的受访者中观察重叠和映射关系,从而自动建立最终样本。文森特和汤普森(Vincent and Thompson)(3)Vincent, K., and Thompson, S.K. 2016. Estimating population size with link-tracing sampling. Journal of the American Statistical Association. Accepted for publication.概述的Rao-Blackwell推理策略能够将自适应选择的成员纳入推理过程,而不引入对人口规模和其他人口数量估计的任何偏见。
用自适应抽样评估难以接近的人群的规模在文献中很少受到关注。最早的已知研究,是由弗兰克和施耐德(Frank and Snijders)(4)Frank, O. and Snijders, T. 1994. Estimating the size of hidden populations using snowball sampling. Journal of Official Statistics 10.1:53-67.开发的基于雪球抽样设计。最近费利克斯·梅迪纳和汤普森(Felix-Medina and Thompson)(5)Felix-Medina, M.H., and S.K. Thompson. 2004. Combining link-tracing sampling and cluster sampling to estimate the size of hidden populations. Journal of Official Statistics 20:19-38.研发了一种方法,其基础的假设是可以通过为隐藏的人口提供部分抽样框架来完成招募,并且以可预测的方式进行推荐。
适应性抽样通过对科罗拉多斯普林斯研究中从艾滋病毒/艾滋病高危人群中观察到的实际数据的经验模拟得到了验证(6)Vincent, K., and Thompson, S.K. 2016. Estimating population size with link-tracing sampling. Journal of the American Statistical Association. Accepted for publication.。研究样本由595个个体组成,网络中的链接代表着成对个体之间的毒品共享关系。抽样是基于随机选择初始样本,然后通过链接跟踪添加一组单元。在相应的推论设置中,必须观察最终样本中成员之间的所有推荐。样本以外的推荐的情况则不需要观察。在这项验证研究中,文森特和汤普森(Vincent and Thompson)估计了人口规模和其他人口数量,并发现即使有少量的适应性抽样的努力,新策略在提高精度方面也比传统的应对方法有了很大的提高。这是自适应抽样最有吸引力的特点:它有能力通过增加从现有研究对象中招募的新观察数据来迅速改进评估。
四、利用现有记录估计发案数
利用现有记录中的数据挖掘来评估人口贩运活动已经持续了一段时间。在最近的一个典型案例中,劳工组织根据对已查明受害者人数以及标记重捕程序已发布的报告,公布了其对全球贩运受害情况的评估。劳工组织利用两个研究小组进行单独的编码计划以核实所有报告的案件,通过对这些已知的案件运用标记重捕方法,估计被强迫劳工的总人数约为2090万人,其中绝大多数受到个别雇主或私营企业的剥削。强迫性剥削的受害者约占受害者的22%。尽管做出了这一重大努力,劳工组织还是承认使用现有受害者报告的局限性,并呼吁通过国家或区域调查加大收集基础数据的努力。在这些调查中标记回收(重捕)方法可能更为合适。
从本质上讲,劳工组织的抽样方法依靠使用两个独立的研究助理小组,建立一个独立的数据库,收集每个小组可以发现的所有强迫劳动案例,以利用标记回收原则。这种方法背后的想法是,如果一个团队搜索并发现所有报告的强迫劳动案件,这些报告将代表已确定的强迫劳动事件样本。如果两个团队捕获相同的报告案例,它们将代表两个“独立”样本之间的重叠。
遵循劳工组织相同的抽样逻辑,基本标记回收(捕获)模型假定样本情况的二项概率分布。因此,贩运报告要么是“捕获”,要么是“未捕获”,具有预测概率p和1-p。对于所有报告,p的值都是相同的,但在团队之间可能不同,例如对于团队1,p=p1,对于团队2,p=p2。
由于全球性评估数不太可能系统地从世界各地收集基础数据,因此必须使用数据挖掘手段。劳工组织的例子表明,利用所报告的案件是可行的且在统计上是合理的,这些案件往往是违法贩运行为中最严重的一些案件。此外可以加强劳工组织的方法,例如在资金充足的情况下,人们可以探索多次标记捕获的策略,在这种策略中,指派四个研究助理小组寻找性交易的案例,每个小组代表一个抽样机会,精心设计的标记捕获模型使得这些分析场景的任何组合成为可能。
基于单个团队捕获的样本将包括假设的样本,因此标记捕获分析不仅适用于两个样本设置,还可以使用更精细的标记捕获估计模型。 例如在零模型下(M0),其中所有捕获概率在采样场合内和之间是相等的,可能捕获历史的集合的概率分布分别表示捕获场合的丢失和捕获的零及捕获的向量。其中nω是具有捕获历史ω的个体数,ω(1)指至少有一个捕获历史的捕获,N是种群中的总个体数,Mt+1是捕获的不同个体数,p是捕获的概率,t是抽样次数,n.是研究中的捕获总次数。种群规模和捕获概率的估计量是使方程最大化的估计量。
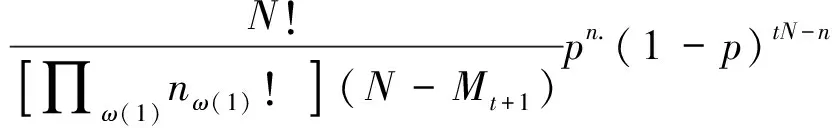
基于异质性/分层效应,每个样本中捕获概率的异质性是允许的,例如从学术出版物中捕获的单元将与从报纸文章中捕获的单元不同,因此异质性效应也可以归因于研究团队。对于这样一个模型,假设捕获分布来自理论分布F,
因此其中Fi是捕获i次的单元数,t是采样次数。一个广泛运用的具有此设置的评估模型是下界估计模型,由超(Chao)(7)Chao, A. 1989. Estimating population size for sparse data in capture-recapture experiments. Biometrics 45: 427-438.导出,
由于行为和时间效应,被捕获单位的概率可以随样本的不同而变化,一个研究团队捕获单位的概率可以与样本不同。 例如,使用时间效应模型Mt:偏差校正后的超(Chao)估计量Zj是仅在第jth次捕获的个体数量

五、标记重捕方法的局限性
除了可能违反标记捕获模型背后的假设外,利用这种方法来估算全球性贩运人口还有很大的局限性。
首先,标记捕获方法依赖于不可能或不切实际的“隐藏”种群的独立样本,就像排干池塘水来计算所有的鱼一样。然而如今的出版物很少能通过公开的方式获取,特别是互联网上的资料。如果所有研究助理团队都在尽最大努力,理论上说他们应该在媒体、政府报告或机构报告中找到所有已知的人口贩运案件。换言之,所有研究助理小组发现的贩运案件应该是相同的,重叠应该是100%或者接近100%。如果两个“独立”样本之间的重叠完全匹配,标记捕获方法就变得毫无意义。
其次,在列表中必然会有一些依赖性——一个“源”被捕获的概率可以很容易影响在同一抽样场合被捕获的另一个“源”,也就是说,由同一研究团队捕获。例如,一本刊物可以报道在一个大城市中营救两个或两个以上的贩运受害者案件。显然,如果一个案件被捕获,那么另一个案件很可能也会被捕获。 这违反了标记捕获中的基本假设之一,即在抽样时个体之间的被捕获的概率是独立的。
不过,有办法缓解这些问题。例如只记录团队遇到的第一个捕获案例,停止,然后从零开始找到一个新的捕获案例,这样就可以避免在抽样场合进行依赖性抽样。 此外,最初的方法可以用来提出一组半详尽的捕获案例,随机地对它们进行处理,然后将最终样本作为每个kth捕获的案例放在被处理的列表中。人们也可以通过重新交换和评估这些列表上的估计量来重复标记捕获推理过程,每个列表都基于kth项。这种策略有助于抑制依赖的影响,考虑自相关的类似效应,它仅适用每个kth条目来消除依赖。随着标记检索软件的到来,统计学家们现在可以进行复杂的分析。其中一些软件包括R包版本(8)Rivest, L., and Baillargeon, S. (2014). Rcapture: Log- linear Models for Capture-Recapture Experiments. R package version 1.4-2. https://CRAN.R-project. org/package=Rcapture.、程序标记(9)www.phidot.org/software/mark/.和CARE(10)Chao, A. 2001. An Overview of Closed Mark- recapture Models. Journal of Agricultural, Biological, and Environmental Statistics 6: 158-175.。
六、链接源:将自适应抽样应用于记录搜索
采用与适应性抽样相同的逻辑,可以将已报告的贩运案件链接(联网)。也就是说,一个来源提名另一个来源,可能是通过网络链接(如果是基于在线资料的案件)或通过参考文献/引用(如果是在出版物中找到的案件)。在这种情况下,可以采用现有的网络抽样方法来估计人口规模。如果网络中的链接是丰富的,那么模拟研究表明这种方法可能会产生比标记捕获方法更精确的估计量,并且使用多个和独立的团队也不会引起问题。研究人员与他们的发现沟通越多,这种单样本方法的精度就越高。
这项策略的纲要是:
以适当的方式界定与其他性贩运案件的链接(也称为推荐或提名)。 例如,从学术资源到其他案例的引用,或者从在线资源到另一个案例的链接,都将被视为定向链接(定义了链接,以便可以映射此类关系,并且可以将在文献中的进一步选择引导到有希望的领域,以自适应地建立样本)。
采取以下步骤:
根据所报告的案件是否属于学术报刊、新闻报道、非政府组织报告或政府报告案件,将人口分成几个阶层。
定义Uk为阶层k。在每个阶层中选择一个随机样本。假设对于阶层k,样本为S0k和n0k,是该样本中的单位数。对于阶层l定义为rlk,是从S0l到S0k的链接数,Slk是从S0l到UkS0k的链接数。
阶层k的大小的一致估计量为:
人口规模估算值就是分层规模估算值的总和,
要获得Rao-Blackwellized(改进的)估计量,需要使用计算量大且精心设计的马尔可夫链蒙特卡洛程序(11)Vincent, K. 2016. Recent advances in estimating population size with link-tracing sampling. Submitted.以获取详细信息。为了最好地应用此程序,应从每个单元的提名子集中跟踪链接选择初始样本。方差估计建议使用文森特概述的折刀程序。
这种链接跟踪方法的数据源可以包括媒体报告(报纸、广播、电视、互联网站点);地方、国家、区域、国际或专题非政府组织;来自司法、劳工、社会事务、移民、外交和内政部门的政府文件,或者来自专门警察或其他打击贩运和强迫劳动的部门的文件;其他国际组织、通过其国家办事处或总部提供的文件;学术报告;劳工组织的报告,包括公约和建议适用专家委员会(CEARC)的报告;工会和雇主的组织报告
为了估计性贩运的受害者人数,将ys0k定义为S0k报告的平均数。估计k层中性贩运受害者的人数,然后
将所有阶层的值相加得出受害者人口规模的估计值。插件方差估算为:
该估计数可被视为对报告的性贩运受害者总数的估计。为了估计一个阶层/地理区域中报告和未报告的受害者数量,可能需要基于原始数据的独立研究获得的知识。在这种情况下,可以根据社会经济因素(如GSI脆弱性模型的使用方式)建立一个复杂的回归模型,来近似报告现有受害者的百分比pk,例如

折刀程序可用于获得该估计模型的方差估计。
使用自适应抽样设计的最吸引人之处是,与传统的类似抽样的设计相比,在抽样工作量相当的情况下,预期的效率提高。文森特和汤普森(Vincent和Thompson)发现,即使有少量的自适应努力,新策略在提高精度方面相比传统策略(如标人口规模和标记—重捕估计值)取得了显著的提高。
关于文献,研究助理团队不必担心对所有报告的案例进行详尽而深入的搜索,因为事实证明,估算模型具有很高的效率。在这种自适应采样方法中研究团队之间交流越多,估计量就越精确。
七、如何利用“冰山一角”进行评估
在利用报告的贩运案件估计流行率方面,最大的方法挑战是评估犯罪暗数。在犯罪学术语中,“黑暗人物”指的是被报告的犯罪与当局未掌握犯罪之间的差距。虽然永远不会知道贩运人口或现代奴隶制的真正程度,但官方犯罪统计数字只占实际犯罪的一小部分,这一点几乎没有异议。
假定大致知道已报告的案件代表了所有人口贩运活动的“冰山”的多少,就可以对问题的严重程度作出一些估计。即使在最好的情况下,利用已报告的贩运案件来估计未报告的案件(如犯罪学术语中的犯罪黑数)也是有问题的。研究人员将自我报告的犯罪活动与官方逮捕记录中的犯罪活动进行了比较(大多数是青少年犯罪),普遍认为在所有犯罪活动中,只有大约10%的犯罪活动受到当局的注意。然而这种估算还指出某些犯罪(杀人和汽车盗窃)往往比其他犯罪(如袭击和毒品犯罪)有更多的报告记录。
目前尚无已知的关于贩运受害者的预测的研究文献,也没有与已知的贩运案件相比的隐藏案件率。这是冰山一角。根据所报告的贩运案件进行的任何外推或扩大估计不可避免地会被视为是既不能证实也不能否认的纯粹推测。解决这一问题的一个策略是效仿劳工组织的做法,并将调查数据与新闻媒体报道的案例进行比较。可以添加一个调查问题,以确定受害者是否向当局或新闻媒体报告了他/她的案件。
对贩运人口的性剥削问题进行的实证研究非常必要,两种有前途的策略可能有助于回答这议题的重要性。如上所述,这两种方法在最近的研究论文和劳工组织报告中得到了应用。由于这两种方法都隐含了所需的研究资源,因此尚不清楚研究人员在实证研究中可以应用这些方法的程度。
结语
总的来说,目前没有简单的解决方案。任何试图建立全球人口贩运活动估计量的做法都必然会遭到批评和质疑,这仅仅是因为在不涉及巨大预算问题的情况下,很少有切实可行的方法来研究这个问题。由于缺乏有关问题范围的可靠信息,大多数试图影响决策者的措施都必须诉诸耸人听闻的主张和道德诉求,这迟早会造成信任问题。涉及原始数据收集的实证研究也可以帮助警察机构制定有效的对策。
猜你喜欢
青春期健康(2022年13期)2022-07-18 01:23:44
英语文摘(2022年4期)2022-06-05 07:45:12
水上消防(2021年4期)2021-11-05 08:51:36
学生天地(2020年2期)2020-08-25 09:03:04
公民与法治(2020年5期)2020-05-30 12:33:40
小天使·一年级语数英综合(2018年3期)2018-06-22 10:38:58
领导决策信息(2018年10期)2018-05-22 04:19:32
中国交通信息化(2016年10期)2016-06-08 06:07:18
中国卫生(2015年9期)2015-11-10 03:11:24
中国健康心理学杂志(2015年5期)2015-09-05 09:55:54
