
基于集成学习方法的PPP项目结果预测
2020-06-29 09:40刘爽
大众科学·上旬 2020年7期
刘爽
摘 要:随着政府与社会资本合作模式在基础设施建设当中的推广与应用,探究PPP(public-private partnership)项目能否实施成功的关键影响因素和判断项目实施结果等问题已经引起了学者们的关注。根据已有文献中总结出的PPP项目成效关键影响因素,提出一种结合SMOTE(synthetic minority over-sampling technique)过采样技术和Random Forest算法的集成学习分类模型,该模型可帮助研究人员预测PPP项目实施结果的成败。通过与其他十个基线分类器进行对比实验,可以证明SMOTE过采样技术对PPP项目数据集中不平衡数据的处理是有效的。研究结果表明所提模型在Presicion、F-measure和ROC Area三个指标上比基线分类器具有更好的性能表现。
关键词:政府和社会资本合作(PPP);数据挖掘;集成学习;预测
0引言
基础设施建设作为影响国家产品服务的质量和效率的重要因素,对经济发展具有深远的影响。一些发展中国家虽然意识到了基础设施建设的重要性,但受到政府资源、融资、技术缺乏等方面的限制。因此,引入私人投资作为基础设施建设的融资渠道被视为可行的方法之一。政府与社会资本合作模式有效解决了基础设施融资难题,提高了基础设施产出的经济价值。以我国为例,财政部政府和社会资本合作中心官网的数据显示,截止到2020年4月16日,全国PPP综合信息平台项目管理库的入库项目数量达到9456个,入库项目金额达到144075亿元。
数据挖掘方法可用于从目标数据集中提取信息、模式和规律来预测目标的未来趋势。常用集成学习算法包括Bagging和Logit Boost等。它们都涉及到结合独立分类器并提供集合而成的最有效结果。本文的数据来源为由世界银行建立的Private Participation in Infrastructure(PPI)数据库。该数据库旨在识别和传播发展中国家基础设施建设项目中私人部门参与的信息,涵盖各国基础建设项目的数量超过6400个。
在本研究中提出了一种基于Random Forest[1]算法的集成机器学习模型,来预测PPP项目实施结果,并通过与其他10个基分类器的预测准确性进行比较,证明了所提出模型的优越性。
1相关工作
在对国内外文献的梳理中,我们可以总结出以下影响PPP项目成效的因素:
(1)PPP项目开展时所在区域是否有PPP成功实施的经验。在公共采购中,PPP模式可以将服务的不确定性最大程度地降低,从而带来潜在收益。这些服务领域存在过去的经验以告知参与方在事态发展时会产生的状况。
(2)PPP项目的内部风险因素。Ahmadabadi等人[2]基于其开发的PLS-SEM模型评估关键成功因素对PPP项目成功的影响,提出私营部门能力直接影响项目成功。
(3)PPP项目所属国家的政治和社会环境。政治和社会环境与特定地区密切相关,我们无法轻易量化这些因素。
(4)PPP项目所属国家的宏观经济环境。随着宏观经济条件的改善,公共项目将会对私人部门投资具有更大的吸引力。
学者们对PPP项目成功关键因素的研究方法以文献、案例分析以及访谈等定性研究方法为主,或是使用传统的统计学模型探究PPP项目产出效率的影响因素。罗煜[3]等人采用Probit模型对二值因变量進行回归分析从而判断PPP项目的成败。刘穷志[4]等人采用随机前沿模型分析中国PPP水务项目的22个省份非平衡面板数据,对项目投资效率及其影响因素进行研究。
PPI数据库中存在大量失败的基础设施PPP项目,使得私人投资者和政府部门遭受经济损失,降低了社会整体福利水平。本文结合不平衡数据处理和集成学习方法,根据已有研究成果设置参数,将机器学习方法运用到PPP项目实施结果的预测当中,可为私人部门对PPP项目的投资决策提供参考。
2集成学习模型
本文提出一种集成机器学习模型来预测PPP项目实施结果,结合了一系列数据预处理步骤。其中PPP项目数据取自世界银行主导建立的Private Participation in Infrastructure(PPI)数据库,选取了PPI数据库中有数据收录的已得出实施结果的全部项目数据作为研究对象。实验工具为Weka Data Mining Tool for Java。
2.1数据描述
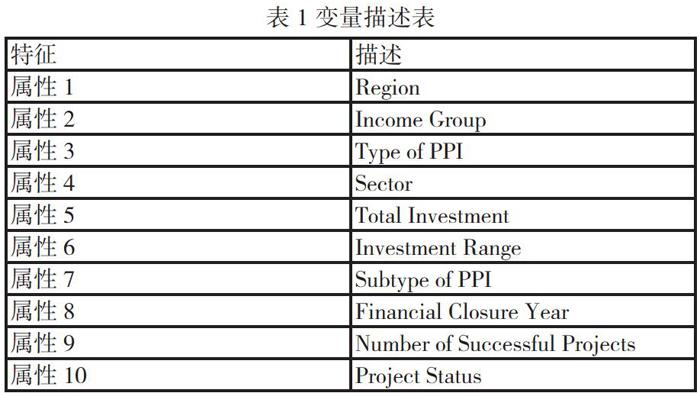
该数据集包含700个实例,每个实例有10个属性,如表1所示。在该数据集的预测期内,有476个失败的PPP项目,224个成功的PPP项目。
2.2数据预处理
根据PPP项目运行结果关键影响因素,选取区域(Region)、国家收入水平(Income Group)、项目类型(Type of PPI/Subtype of PPI)、所投资部门(Sector)、投资规模(Total Investment/Investment Range)、项目启动年份(Financial Closure Year)以及过往成功的项目数量(Number of Successful Projects)作为特征属性,项目现状(Project Status)为预测类别标签。其中各区域过往成功的项目数量经过手工整理得来,Total Investment存在缺失值,用0值代替。正在运行的项目结果具有较大不确定性,因此只考虑已完结的项目或合约。合同结束即视为项目成功,使Project Status取值为1,项目取消和项目危机即视为项目失败,使Project Status取值为0[3]。
2.3建模
在本节中共使用11种分类器来预测PPP项目运行的结果,该模型包括三个部分:
(1)依次使用Standardize、Normalize 、Add Cluster、Numeric To Nominal方法对数据集进行特征处理;
(2)采用Synthetic Minority Over-sampling Technique(SMOTE)技术处理此模型中的不平衡数据集;
(3)使用Random Forest[1]分类器学习训练数据集并进行评估。
通过该模型对测试数据集进行分类和验证后,将预测准确性与其他10个基分类器进行比较,可证明此模型的优越性。
2.3.1特征工程
为最大限度地从原始数据中提取特征供算法和模型使用,提高模型的预测精度,我们采用下列步骤对其进行特征处理。Standardize可标准化给定数据集中的所有数字属性,使其具有零均值和单位方差。Normalize用于规范化给定数据集中的所有数值。Add Cluster作为一个添加新名义属性的过滤器,表示由指定的聚类算法分配给每个实例的集群。Numeric To Nominal是将数字属性转换为名义属性的过滤器。
2.3.2SMOTE
过采样技术可用于解决数据集不平衡的问题,然而通过简单复制数据集中少数类的已有元素容易使模型过拟合,不利于模型的推广与应用。SMOTE技术可根据少数类元素的分布来人工创造新样本,随后被广泛运用于高维不平衡数据集处理流程当中。它包含两个主要步骤:第一步为定义每个少数类元素的邻域,第二步为随机选择邻域内元素并通过插值法创造新样本。由于SMOTE独立于分类器,它可以与任何算法组合使用。
2.3.3Random Forest
Random Forest[1]算法是一种集成机器学习模型,它的基本思想是将多个决策树集成到一个更强大的分类器中,每棵树独立作出预测,最终通过加权得出结果。Random Forest实际上是一种特殊的Bagging方法,它将决策树用作Bagging中的模型,用bootstrap方法生成m个训练集后在决策树每个节点的特征中随机抽取子集,寻找最优解并进行分裂。因此它可避免样本过度拟合的问题。
3实验
本节包括所提出模型的实验过程和使用各分类器进行对比实验的结果。我们将原始数据集中的80%划分为训练数据集,依次使用Standardize、Normalize、Add Cluster以及Numeric To Nominal进行特征处理。由SMOTE技术将数据集调整为平衡数据集后,通过Random Forest分类器学习训练数据集,并使用测试数据集测试模型性能,获取验证结果。我们进行了多次实验以确保模型分类结果是可靠的。
3.1模型评估指标
本研究中的分类器需解决的是二分类问题,即PPP项目运行结果是成功还是失败。可能发生如下四种情况:a) True Positive(TP):将正类预测为正类数;b) True Negative(TN):将负类预测为负类数;c) False Positive(FP):将负类预测为正类数,即误报 (Type I error);d) False Negative(FN):将正类预测为负类数,即漏报 (Type II error)。本文中将PPP项目成功定义为正类,项目失败定义为负类。我们选用Precision、F-Measure和ROC Area来评估所提出的模型。
3.2实验结果与分析
3.2.1基线分类器的性能
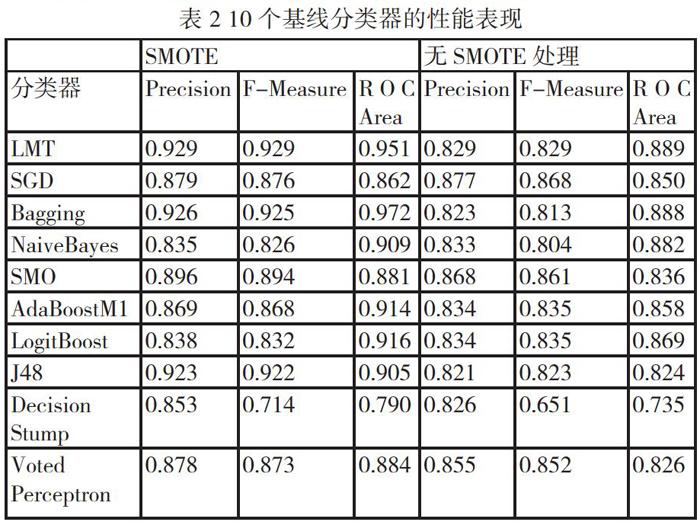
为了与我们提出模型的性能进行比较,在本节中展现了10个基线分类器的性能表现,实验结果如表3所示。为确保实验结果的稳健性,我们进行了5次重复实验。其中未进行SMOTE技术处理的数据集所得出分类器精度作为对照组同样呈现在表2中。
结果显示,在经过SMOTE技术处理前后LMT和SGD算法都是表现最佳的两个算法。
3.2.2建议模型的性能与分析
在本节中我们测试了所提出模型的精度,并将其结果与最佳基线分类器的结果进行了比较。与上节操作相同,进行了5次重复实验。
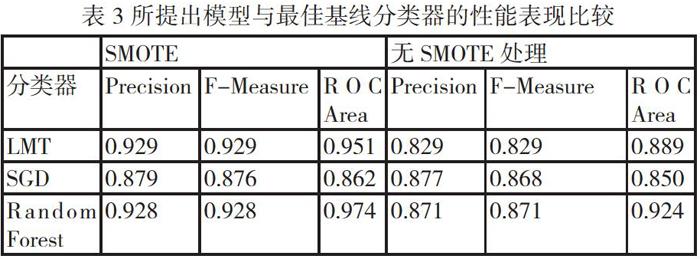
我们分别将经过相同的SMOTE过采样技术处理之后的数据集和未经过SMOTE过采样技术处理的数据集在所提出模型及最佳基线分类器下得出的预测准确性进行比较,具体结果如表3所示。
我们可以看出,经过SMOTE技术处理之后,基线分类器与我们所提出模型的Precison、F-Measure和ROC Area得到了全面的提升,说明SMOTE技术对PPP项目数据集中不平衡数据的处理是有效的。SMOTE技术使Random Forest和LMT的预测精度得到了整体的提升,而SGD的性能提升并不明显。Random Forest的Precision和F-Measure略低于LMT,而ROC Area显然优于LMT,因此综合性能表现最良好。
4结果与讨论
PPP模式要求政府和私人部门承担不同等级风险,合作提供公共服务,已成为众多发展中国家实施基础设施建设时选择的途径。然而PPP项目的运行结果存在风险,因此对PPP项目成功关键因素及运行结果预测的相关研究日益引起学者们的关注。
在本文中,我们构建了一个基于集成学习的模型来预测PPP项目实施的结果,使用特征处理步骤和SMOTE过采样技术之后利用Random Forest算法对数据集进行预测。通过与其他10个基线分类器的性能表现作比较,我们可以证明所提出模型在Precision、F-Measure和ROC Area三个指标上的优越性。同时,我们可以验证SMOTE技术在处理本数据集中的不平衡問题时表现突出,使Random Forest的三个评估指标数值都得到了显著提高。
由于数据集中总投资金额这列属性存在缺失值,可能影响分类器的预测精度。此外,由于数据集属性数量较少,我们应寻找是否存在遗漏变量,以便于提升模型的性能,在未来的工作中我们将继续进行研究并加以改进。
参考文献
[1]Cheng L, Chen X, Vos J D. Applying a random forest method approach to model travel mode choice behavior[J]. Travel Behaviour and Society, 2019, 14:1-10.
[2]Ahmadabadi A A, Heravi G. The effect of critical success factors on project success in Public-Private Partnership projects: a case study of highway projects in Iran[J]. Transport Policy, 2019, 73: 152-161.
[3]罗煜, 王芳, 陈熙. 制度质量和国际金融机构如何影响 PPP 项目的成效——基于“一带一路”46 国经验数据的研究[J]. 金融研究, 2017, 4: 61-77.
[4]刘穷志, 彭彦辰. 中国PPP项目投资效率及决定因素研究[J]. 财政研究, 2017, 11: 34-46.
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
西部交通科技(2021年9期)2021-01-11
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
哈尔滨理工大学学报(2016年2期)2016-09-12
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
