
基于Wi-Fi时空数据的位置预测
2020-06-28 06:14张书钦王金洋白光耀张敏智
现代信息科技 2020年24期
张书钦 王金洋 白光耀 张敏智


摘 要:在位置预测研究中,历史轨迹通常呈现分布稀疏和结构单一的特点,导致预测模型准确率下降。针对此问题,利用用户属性特征和历史轨迹特征度量用户相似性,对相似用户进行分簇;并提出基于相似用户簇的LSTM神经网络预测模型SG-LSTM(Similar Group based LSTM model),以改善轨迹数据的稀疏性问题。实验表明,模型能够较好地捕捉用户的移动规律,预测准确率超过87.90%,在准确率和时间复杂度方面均优于传统模型。
关键词:稀疏时空数据;用户相似性;LSTM;位置预测
中图分类号:TN92 文献标识码:A 文章编号:2096-4706(2020)24-0164-05
Location Prediction Based on Wi-Fi Spatiotemporal Data
ZHANG Shuqin,WANG Jinyang,BAI Guangyao,ZHANG Minzhi
(School of Computer Science,Zhongyuan University of Technology,Zhengzhou 450007,China)
Abstract:In the research of location prediction,historical trajectories usually show the characteristics of sparse distribution and single structure,which leads to a decline in the accuracy of the prediction model. To solve this problem,the similarity of users is measured by using user attribute characteristics and historical track characteristics,and similar users are clustered;and proposes similar user cluster based LSTM neural network prediction model SG-LSTM(Similar Group based LSTM model)to improve the sparsity of trajectory data. The experimental results show that the model can better capture the users movement rule,and the prediction accuracy is more than 87.90%,which is better than the traditional model in terms of accuracy and time complexity.
Keywords:sparse spatiotemporal data;user similarity;LSTM;location prediction
0 引 言
隨着5G通信技术的发展及智能设备的普及,人们得以获取大规模的时空数据,基于海量时空数据的人类移动性预测受到人们的广泛关注[1-3]。在公共服务方面,轨迹预测可应用于交通管理[4]、公共安全预警[5]等,以提升公共设施的服务效率;在个人服务方面,也可用于个性化推荐[6]、智能导航等,以提升用户体验。随着此类基于个性化服务的应用激增,从人们的历史轨迹中挖掘移动模式,并预测未来去向已成为一种迫切的需要。
目前,基于时空数据的位置预测研究面临以下问题:
(1)时空数据稀疏性。可获取的时空数据大多是低采样的,在采集过程中由于数据丢失或者用户拒绝分享位置信息导致采集的用户历史轨迹数据较为稀疏。
(2)时空数据单一性。人类移动具有规律性,通常每天只访问固定的几个位置,因此在低采样的情况下,用户的历史轨迹包含的位置点比较单一。
以上问题导致预测模型在训练过程中因缺少足够的上下文信息,不能很好地捕捉用户的移动偏好特征,降低了预测准确率。
针对以上问题,本文采用划分相似用户簇的方法强化用户的历史轨迹上下文信息,有效缓解历史轨迹的稀疏性和单一性;并提出了一种基于相似用户簇的LSTM神经网络预测模型,以更好地建模轨迹序列数据。
1 相关工作
目前基于时空数据的轨迹预测工作主要分为基于模式的方法和基于模型的方法[7-9]。基于模式的方法首先从大量的历史轨迹中发现频繁轨迹模式,例如顺序模式和周期模式等,然后将当前查询轨迹与频繁轨迹模式进行匹配,从而达到轨迹预测的目的。Monreale等[10]提出了基于模式的轨迹预测模型WhereNext,该方法从移动对象的历史轨迹数据中挖掘频繁项集作为移动模式,并用该模式表示用户频繁访问的地点,同时利用T-Pattern Tree查询发现最优匹配轨迹。基于模式的方法由于每次更新都需要重新挖掘频繁项集,此外在面向稀疏或者单一性数据时可能存在无法挖掘频繁模式的情况,导致预测效果不理想。LSTM作为时序数据处理的主流工具,在轨迹预测领域应用广泛。高雅等[11]为了解决马尔可夫模型在处理长序列数据时存在的维度爆炸问题,提出位置分布式表示模型(LDRM),将高维的One-Hot位置表示向量嵌入到低维空间,并与LSTM结合,对移动对象的轨迹做预测研究,提升了预测准确性。
2 术语定义及问题描述
定义1(兴趣点):兴趣点(Point Of Interest,POI)是指给定空间区域内任何可以被抽象为一个位置点的地理实体,用p表示,该区域中所有POI集合记为S={p1,p2,…,pn},其中n为兴趣点个数。
定义2(停留点):给定的时间阈值θt,若用户u在p的停留时间超过该阈值,则将p定义为该用户的一个停留点,记为sp。停留点是具有一定时间约束的POI。
定义3(轨迹序列):轨迹序列由一系列按照时间排序的停留点构成,记为TS={sp1,sp2,…,spn},spi为第i个停留点,1≤i≤n。
定义4(用户属性):用户属性指用户固有的且在短时间内不易发生变化的标签,记AT={a1,a2,…,an},ai为用户的第i个属性,1≤i≤n。
用户属性即为用户的标签,例如,一名学生的用户属性包括:学号、性别、年级和专业等,可记为AT={001,male,freshman,CS}。
问题定义:本文将所研究的轨迹预测问题定义为:对于某一用户u,给定用户属性ATu={a1,a2,…,an}和用户u在t时刻的轨迹序列TSu={sp1,sp2,…,spn},预测该用户t+1时刻最可能访问的兴趣点p。
3 轨迹预测模型
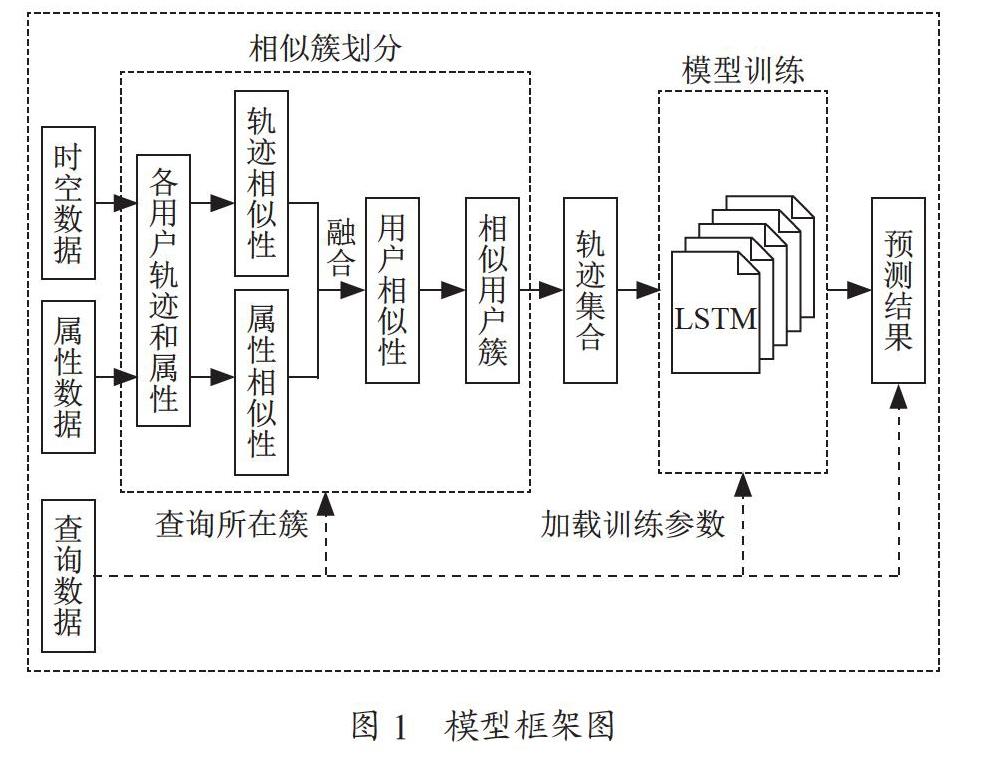
传统的LSTM位置预测模型只根据单个用户的历史轨迹进行建模,而忽略了历史轨迹数据的稀疏性和单一性特点,导致预测精度降低。针对此问题,本文对通过对相似用户进行分簇,实现稀疏历史信息增強的效果。具体来说,首先,从用户数据集中提取属性和历史轨迹数据,再分别计算用户的属性相似性和移动行为相似性,并对以上两种相似性得分进行融合,将最终的相似性得分作为划分用户簇的依据,并在此基础上划分用户簇,将一类用户的历史轨迹作为训练数据进行轨迹预测模型的训练,以提高模型性能。本文模型框架如图1所示。
3.1 用户相似性度量
3.1.1 属性相似度度量
对任意用户u和用户v以及对应的属性ATu={au1,au2,
…,aun}和ATv={av1,av2,…,avn},若对应的属性值相同则取1,否则为0,如式(1)所示:
(1)
考虑到不同的属性对用户下一个轨迹点的选择会产生不同的影响力,为每个属性分配不同的权重。任意两个用户的属性相似度计算如式(2)所示:
(2)
其中,simAT
3.1.2 轨迹相似度度量
本文将轨迹相似度度量转换为序列匹配任务,即两条轨迹之间匹配度越高,则相似性越高,采用LCSS算法(Longest Common Subsequence,LCSS)估计用户之间的历史轨迹相似度。对任意的用户u和用户v,轨迹序列分别为TSu={sp1,sp2,…,spm}和TSv={sp1,sp2,…,spn},m,n分别为用户u,v的轨迹序列长度,用户u和用户v的轨迹最长公共子序列LCSS(u,v)={spk1,spk2,…,spkz},spki∈TSu∪TSv,1≤i≤z,z为用户u和用户v的轨迹序列包含的最长公共子序列长度。任意两个用户的历史轨迹相似度计算如式(3)所示:
(3)
len(TS)表示轨迹序列的长度,simTS∈[0,1]。当simTS=0时,表示两条轨迹完全不相似;当simTS=1时,表示两条轨迹完全重合。
3.1.3 用户相似性度量
将用户的属性相似度与轨迹相似度进行加权融合,得到任意两个用户相似度,计算公式如式(4)所示:
sim(u,v)=α·simAT(u,v)+(1-α)·simTS(u,v) (4)
其中α为用户属性对用户相似度的影响因子。
3.2 基于用户相似度的用户簇划分
由相似度度量式(4)可以度量任意两个用户之间的相似度,据此可得包含所有用户的相似度查询表。设定相似度阈值βs,依据查找表为每个用户划分相似用户簇,得到最终的用户簇集合。该算法优点在于缓解了相似用户分簇的冷启动问题,当出现新用户时,只需在相似度查询表中更新该用户与已有用户的相似度即可完成用户簇划分,具体如算法1所示。
算法1:用户簇划分算法
Input: U, AT, TS,βs.//输入用户集合,及各用户的属性信息、轨迹记录。
Output: 用户相似矩阵M,相似簇Dict = {ui : list(uj)}.
1.n = lenth(U); //用户个数
2.create similar matrix Mn×n//记录用户间相似度
3.create empty dictDict;//记录相似用户簇
4.i = 0;//设定用户索引起始值
5.whilei≤ n-1
6.create empty list L; //创建空列表
7.j = i//设定用户索引起始值
8.while j≤n-1:
9.sim(ui, uj);//计算相似度
10.mij = mji = sim(ui, uj);//mij是M的元素
11. if sim(ui, uj) ≥ βs://满足相似阈值
12.add uj to L; //添加到相似用户
13.j = j + 1;
14.add
15.i = i + 1;
16.return M, Dict. //返回相似度矩阵和相似簇字典
若用户簇中用户个数为m,每个用户包含n个属性,且平均轨迹长度为l,则该算法关键步骤在于计算相似矩阵M,因此算法1时间复杂度为O,函数的表达式为((n+12)·m+ m(m-1))。
3.3 基于相似用户簇的SG-LSTM模型
稀疏轨迹通常呈现出单一性特点,轨迹序列包含POI类别个数较少,导致用户历史轨迹上下文信息大大减少,不能很好地反映用户的实际移动偏好特征。本文将相似用户的历史轨迹集合作为该相似群体的整体历史轨迹,用以丰富个体用户地历史轨迹,缓解个体用户历史轨迹上下文不足的问题,并在此基础上提出基于相似用户簇的轨迹预测模型SG-LSTM,模型基于相似用户群体轨迹建模,其中考虑了用户的属性信息,在一定程度上缓解了用户轨迹数据的稀疏性问题。SG-LSTM模型实现如算法2所示。
算法2:SG-LSTM模型算法实现
Input:Dict={ui : list(uj)}, AT, TS,ε.//输入相似簇字典、用户属性、轨迹记录及损失阈值
Output: Trained SG-LSTM model.
1.select ui from Dict.keys; //选择相似用户簇
2.add ui to list(uj);
3.train user set S = list(uj); //获取训练数据
4.m = lenth(list(uj));//相似簇中用户个数
5.set bitchsize = m; timestep = n; //设置模型参数
6.construct trainset X = {TS}m×n ; //构造神经网络输入
7.initialize δ={ωf,ωu,ωo,ωc,bf,bu,bo,bc};//初始化
8.loss = J(X, δ); //计算损失函数
9.whileloss ≥ ε:
10. adjust δ; //调整参数
11.loss = J(X, δ);
12.return δ.
4 实验及结果分析
4.1 数据集
本文采用某高校包含学生属性信息的Wi-Fi签到日志数据集。该数据集为11 524名在校学生在2019年10月1日—2019年10月19日期间的3 646 592条签到日志记录,其中包括:学生编号、设备MAC地址、经度和纬度、连接时间等,用户属性信息数据包括:学生编号、性别、年级和专业班级,数据样例如表1所示。
4.2 评价指标
本文采用准确率作为模型性能评价指标,记为Acc,计算公式为:
(5)
其中,PTrue表示模型在测试集上预测正确的样本个数,NAll表示测试集的样本总个数。
4.3 实验参数影响
为了找到更优的参数组合,使得模型预测性能更高,分别设计了不同的参数组合进行实验对比。图2为每次输入模型的轨迹点个数变化对模型预测准确率的影响,图例中的N_step即timestep表示每次输入模型中的轨迹长度,即轨迹点个数。由图2可以看出,N_step=5时模型的性能最好,表明刚访问的5个POI对用户下一个轨迹点的选择有较强影响力;图3展示模型隐藏层神经元个数对模型准确率的影响,N_hidden表示每层LSTM的神经元个数。經过不断调整优化,最终选取模型参数:N_step=5,N_hidden=12。
4.4 实验对比
为了验证本文所提出的SG-LSTM模型的有效性,将本文模型与基于MF的轨迹预测模型、基于HMM的轨迹预测模型、基于SimpleRNN的轨迹预测模型和基于Single-LSTM的轨迹预测模型做准确率和预测效率对比,结果如图4和图5所示。
结合图4预测准确率和图5训练时间对比结果,基于MF的兴趣点预测模型训练耗时最短,但是准确率最低,这是因为MF模型并未考虑用户属性特征和历史轨迹信息对下一个位置选择的影响,只是对User-POI矩阵进行简单分解,导致准确率较低;基于HMM的预测模型准确率略低于基于SimpleRNN,不过训练耗费的时间却远远高于后者,因为HMM在计算状态转移矩阵时,受隐状态以及阶数影响很大,当数据量较大时,耗时较长,本文将HMM模型的阶数设置为1,即考虑前一个轨迹信息对下个位置的影响,增加了历史信息影响,因此准确率与SimpleRNN相差较小;本文提出的SG-LSTM模型相较于Single-LSTM准确率提升超过1%,而且训练时间也明显降低,是由于相似用户簇对用户的历史信息进行了增强,使得模型学习到更加丰富的特征,因此准确率比Single-LSTM高。总的来说,基于RNN的模型预测性能优于HMM和MF,而且SG-LSTM无论准确率还是训练时间都优于其他模型,也证明了本文模型的有效性。
5 结 论
本文研究了稀疏时空数据场景下用户的轨迹预测问题,提出融合用户属性和历史轨迹的用户相似性度量框架,并在此基础上提出基于相似用户簇的轨迹预测模型SG-LSTM,缓解了轨迹预测模型的用户历史数据稀疏性和单一性问题,并且通过将轨迹语义化,使得预测结果更具有物理意义和实用价值;在真实的数据集上对模型性能进行实验评估,结果表明,在具有稀疏性和单一性的时空数据中,SG-LSTM模型能够较好地捕获用户的移动规律,有效缓解稀疏轨迹导致的上下文信息缺乏问题,轨迹预测的准确率达到87.90%,优于传统轨迹预测模型。SG-LSTM模型具有广泛的应用前景,例如可用于城市区域规划、智能交通疏导和基于位置的个性化服务,在实际应用中具有较高的价值。
参考文献:
[1] 徐彪,霍欢,陈尚也,等.基于位置服务的轨迹预测方法 [J].小型微型计算机系统,2016,37(6):1191-1196.
[2] ALAHI A,GOEL K,RAMANATHAN V,et al. Social LSTM:Human Trajectory Prediction in Crowded Spaces [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:961-971.
[3] LEE N H,CHOI W,VERNAZA P,et al. DESIRE:Distant Future Prediction in Dynamic Scenes with Interacting Agents [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:2165-2174.
[4] ZHENG Y,LIU Y C,YUAN J,et al. Urban Computing with Taxicabs [C]//Proceedings of the 13th ACM International Conference on Ubiquitous Computing.Beijing:Ubicomp,2011:98-98.
[5] 孙未未,毛江云.轨迹预测技术及其应用——从上海外滩踩踏事件说起 [J].科技导报,2016,34(9):48-54.
[6] 李寒露,解庆,唐伶俐,等.融合时空信息和兴趣点重要性的POI推荐算法 [J].计算机应用,2020,40(9):2600-2605.
[7] GIANNOTTI F,NANNI M,PINELLI F,et al. Trajectory pattern mining [C]//Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining.New York:Association for Computing Machinery,2007:330-339.
[8] GAMBS S,KILLIJIAN M,NUNEZ M. Next place prediction using mobility Markov chains [C]//EuroSys 2012 Workshop on Measurement,Privacy,and Mobility.New York:Association for Computing Machinery,2012:1-6.
[9] CHEN M,LIU Y,YU X. NLPMM:A Next Location Predictor with Markov Modeling [C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining.Cham:Springer,2014.
[10] MONREALE A,PINELLI F,TRASARTI R,et al. WhereNext:a location predictor on trajectory pattern mining [C]//The 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2009:637-646.
[11] 高雅,江國华,秦小麟,等.基于LSTM的移动对象位置预测算法 [J].计算机科学与探索,2019,13(1):23-34.
作者简介:张书钦(1978—),男,汉族,河南禹州人,副教授,博士后,主要研究方向:物联网、数据挖掘、网络攻防、无线网络;王金洋(1995—),男,汉族,河南周口人,硕士研究生在读,主要研究方向:大数据挖掘、自然语言处理;白光耀(1996—),男,回族,河南郑州人,硕士研究生在读,主要研究方向:物联网大数据;张敏智(1998—),女,汉族,河南郑州人,硕士研究生在读,主要研究方向:物联网大数据。
