
基于Python的豆瓣影视短评的数据采集与分析
2020-06-28 00:54高雨菲毛红霞
现代信息科技 2020年24期
高雨菲 毛红霞

摘 要:豆瓣是一个通过提供书籍影视相关内容发展起来的网站,能够提供电影的各类信息。豆瓣用户的评论有时能引领一代新的风尚潮流。文章使用Python语言结合有关爬虫的知识设计了有关豆瓣影视短评的爬取系统,采用了URL管理器、网页结构分析、数据采集、数据清洗、数据分析、数据可视化等模块,将指定的电影影评内容保存,精准的获取不同电影的被喜爱程度以及电影上映后带来的反响。
关键词:Python;数据采集;数据清洗;数据可视化
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2020)24-0010-04
Data Collection and Analysis of Douban Film and Television Short Commentary Based on Python
GAO Yufei,MAO Hongxia
(School of Computer and Software,Jincheng College of Sichuan University,Chengdu 611731,China)
Abstract:Douban is website that is gradually developed through providing books,film and television related content,it can provide different kinds of information about film. Sometimes,Douban userscomments can lead a generation of new fashion trend. In this paper,using Python language and combining with the knowledge on crawlers to design a crawling system about Douban film and television short commentary,which adopts the following modules such as URL manager,webpage structure analysis,data collection,data cleaning,data analysis and data visualization etc to save the specified film review content,so as to accurately obtain the popularity extent of the different films and response produced after the filmsshowing.
Keywords:Python;data collection;data cleaning;data visualization
0 引 言
随着互联网时代的到来,网络上的数据量持续高速增长,已经呈现出数以千万计的数据大爆发。面对着这样庞大的数据仅仅使用人工来筛选有价值的数据是不现实的。通过Python编写程序来自动获取信息的网络爬虫应运而生。在当下,娱乐行业蓬勃发展,电影作为其中的主力之一,有着庞大的受众,大量的豆瓣用户在豆瓣网站上留下了他们对于不同电影的评论。本文采用Python作为编程语言,爬取当下热门电影的影评,并对于爬取的数据内容进行了一系列的清洗与整理,将有价值的数据进行了分析并通过可视化技术展现出来。
1 爬虫原理
网络爬虫是通过获取的不同的URL作为核心的支撑,来寻找和抓取在URL之下的各种文章,链接和图片等内容。在给定的URL中,网络爬虫会不断地从中抽取URL,然后对当下URL的内容进行筛选和获取,当一个URL从头到尾都查找完了之后,网络爬虫会自动地进入到下一个URL中,重复之前的步骤,直到所有的URL都被查找了一次。转到技术层面来说,是通过程序模拟浏览器请求站点的行为,把站点返回的数据(HTML代码/JSON数据/二进制数据)存放在本地,等待后期使用。根据不同需要有目的地进行爬取,要增加目标的定义和过滤机制。本文采用简单的框架结构来编写爬虫程序,分别有以下四个模块:URL管理器、网页下载器、网页解析器、网页输出器,这四个模块共同完成抓取网页的整个过程[1]。
2 影评爬取数据系统设计
2.1 网页URL分析
首先通过对于本文要获取的豆瓣的电影的网页影评界面进行分析,观察需要的URL地址。可以发现,豆瓣的每一部电影在subject/之后的数字则对应了每一部固定的电影。如图1所示,在start=与limit=20之间的数值都是以每页20的速度递增的,可以通过改变程序中有关于抓取网页URL时候的数值的改变来进行程序的简单模拟翻页。解析网页URL的代码为:
for i in range(n):
url='https://movie.douban.com/subject/26754233/comments?start={&limit=20&status=P&sort=new_score'url = url.format(i*20)
2.2 网页内容解析
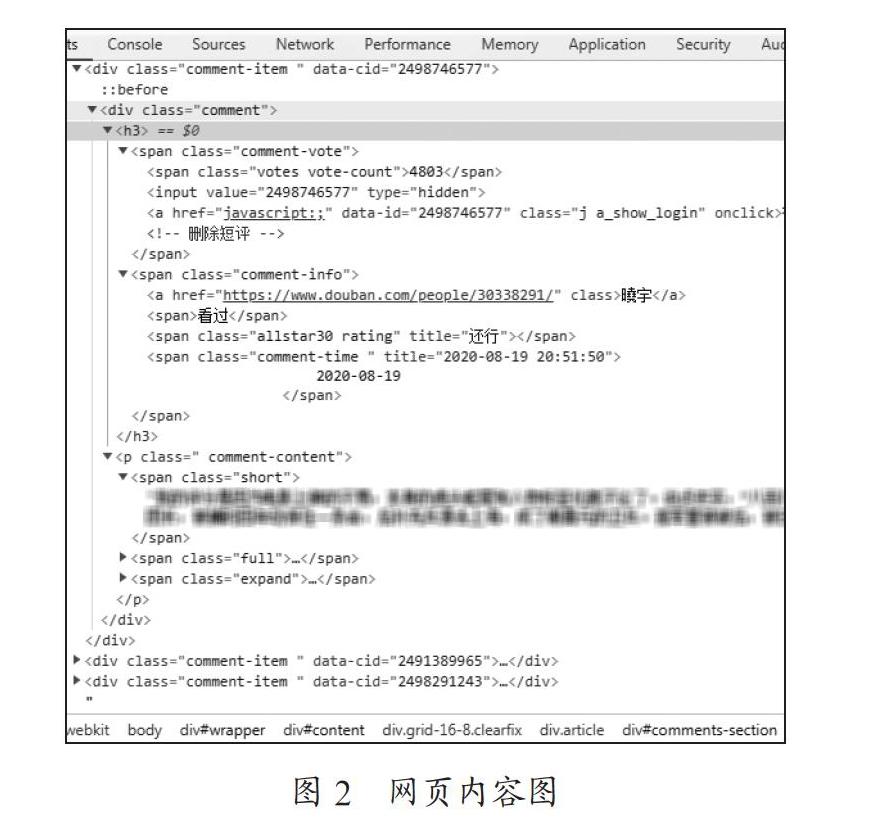
对于页面解析不同的使用者在不同的网站上使用的解析方法都不一样,主要的解析方式有正则表达式,其次是解析庫,常用的有两个解析库有lxml和BeautifulSoup。通过确定每个数据对应的元素及Class名称后,使用find,find_all,select等方法进行标签的定位,进行数据提取[2]。通过Chrome浏览器的开发者工具,可以看到如图2所示的源代码。通过源代码可以找到影评中的评论者信息,评论者主页网址,影评评论的内容,具体评论的时间,以及评论者对于这部电影的喜好程度等级。
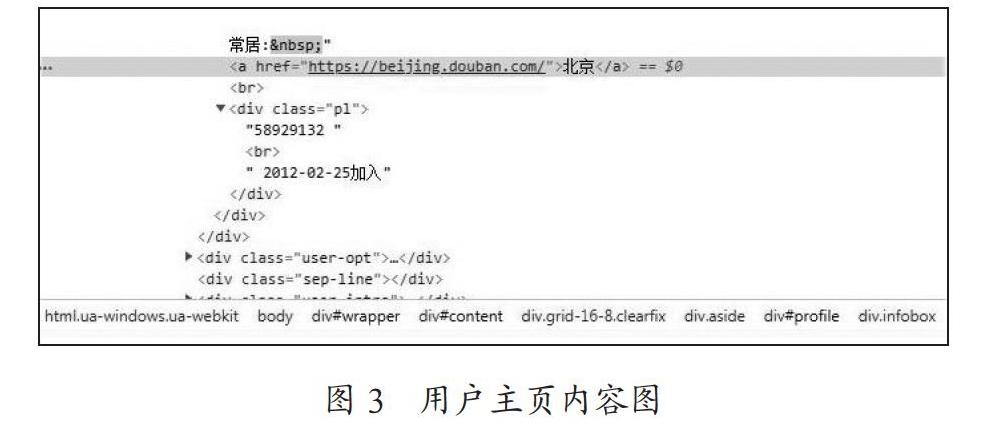
同样的方式打开用户的主页,如图3所示,可以找到在主页的右上方有一份关于用户的个人信息的简单补充。
2.3 反爬虫措施的应对
针对爬虫,很多网站都有了反爬虫手段,而建立网络爬虫的第一原则是:所有信息都是伪造的[3]。本文主要采用了四种方式来应对反爬虫措施:
(1)使用Cookies。豆瓣网站上,每一个注册了豆瓣账号的用户都有一个独一无二的Cookies。Cookies是辨别用户身份的重要途径。可以通过Session跟踪而储存用户在网页登录时候的Cookies来进行模拟用户登录访问网页,来获取只有登录之后才能被查找到的内容。
(2)使用用户的代理信息。通过F12,找到Headers,主要关注用户代理User-Agent字段。User-Agent代表用户是使用什么设备来访问网站的。不同浏览器的User-Agent值是不同的。通过在Headers中添加User-Agent就可以在爬虫程序中,将其伪装成不同的设备访问浏览器信息。
(3)设置延时访问。在使用程序访问网页的时候往往在一秒钟内可以访问几百上千次,而在现实生活中,用户是无法在一秒钟内达到这样一个访问速度的。这样爬虫的程序就很容易被网站监测出来。因此,可以使用sleep()来降低爬虫在一段时间之内的爬取速度,由此来模拟用户行为。
(4)建立用户代理池来达到随机爬取的目的。在爬取过程中,一直用同样一个地址爬取是不可取的。如果每一次访问都是不同的用户,对方就很难进行反爬,那么用户代理池就是一种很好的反爬攻克的手段。首先需要收集大量的用户代理User-Agent,对于收集到的用户代理信息建立函数UA(),用于切换用户代理User-Agent。最后利用上面所提到的用户代理池进行爬取,使用Python中的随机函数random()来随机获取用户代理信息,来使用不同的用户来访问网页信息。
2.4 网页内容的获取与保存
首先要获取有需求的网页内容信息。可以使用多线程的网络爬虫来提高获取内容的速度。对于指定需要获取内容的获取代码为:
def query(get_url):
#函数功能获取内容并存入对应的文件
rqg = requests.get(get_url, headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding'l
html=rqg.content.decode(utf-8", "ignore")
html = etree.HTML(html, parser=etree.HTMLParser (encoding='utf-8'))search = html.xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a/text()")
path='C:/Users/hby/PycharmProjects/pythonProject1/地址.txt'
f = open(path, mode=w", encoding='utf-8)
f.writelines(search)
f.close()
将从网页之中爬取下来的数据转化为本地的csv文件或者是txt文本。可以得到如图4所示的几个类别信息,分别为评论者、时间、评分、内容和主页地址。通过对主页内容的抓取可以获得大量的参与评论的用户的常居住的文本信息。保存为本地文件的代码为:
#to_csv导出为.csv文件; to_excel导出为.xls或.xlsx文件
df.to_excel(r'C:/Users/hby/PycharmProjects/pythonProject1/0.xls'.format(name),index=False)
print('导出完成!)
def write_txt(file_name,wirte_name):
df = pd.read_excel(file_name, header=None)
#使用pandas模块读取数据
print('开始写入txt文件...")
df1=df[3]
df1.to_csv(wirte_name, header=None,sep=",", index=False)
#写入,逗号分隔
print('文件写入成功!'")
3 数据分析系统设计
3.1 数据清洗
检测数据中存在冗余、错误、不一致等噪声数据,利用各种清洗技术,形成“干净”的一致性数据集合,而数据清洗技术包括清除重复数据、填充缺失数据、消除噪声数据等[4]。常用数据清洗函数:排序,搜索np.sort函数;从小到大进行排序np.argsort函数;返回的是数据中从小到大的索引值np.where;可以自定义返回满足条件的情况np.extract;返回满足条件的元素值。
Pandas常用数据结构Series和方法通过pandas.Series来创建Series数据结构。pandas.Series(data,index,dtype,name)。上述参数中,data可以为列表,array或者dict。上述参数中,index表示索引,必须与数据同长度,name代表对象的名称Pandas常用數据结构dataframe和方法通过pandas.DataFrame来创建DataFrame数据结构。pandas.DataFrame (data,index,dtype,columns)。上述参数中,data可以为列表,array或者dict。上述参数中,index表示行索引,columns代表列名或者列标签。对于一些空值的位置可以适当的直接删除当前位置。部分具体清洗数据代码为:
def cleanout(path_file1):
result =[]
with open(path_file1, 'r', encoding='utf-8') as f:for line in f:
result.append(line.strip(r'\n').split('\n')[O])
df = pd.DataFrame(result)
drop=df.replace('[]',np.nan)
data=drop.dropna(how='all')list= data.values.tolist()
counts = dict(zip(*np.unique(list, return_counts=True)))
3.2 数据可视化
数据可视化是数据科学领域中的一种技术,它使复杂的数据看起来简单易懂。词云图,也称为文字云,是用图像的方式对文本中频繁出现的词语进行展現,形成“关键词渲染”或者“关键词云层”的效果[5]。如图5所示,通过词云的删减可以直观地看到电影的主要文本内容和一些突出的要素。可以借助Python的第三方库,如jieba库来获取有关于影评内容的中文分词,对于分词后的内容有着大量的无实际意义的词语。也可导入自行增加删减的stopwords来进行无实际意义的词语的删减,达到想要的实际效果。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF[6]。
通过对于用户的常居住地的处理和清洗之后,为了能够更好、更直观的呈现不同地区的差异,借助Python中的Basemap库,可以获取到中国各省份的区分图,如图6所示,能够发现不同地区的人对电影的讨论热度的差异。
4 结 论
通过Chrome的开发者查看源代码我们可以直观的看到不同的内容在网页上的位置,而利用Python编写的程序可以帮助我们解析URL网页。在网页上获取到所需要的内容,保存到本地。针对爬取到的数据存在着格式不规范,内容有空缺,数据出错等情况,需要在使用之前进行数据的清洗与整理。对数据运用不同的分析方法,最后借助图表的方式来清晰直观的展现出所要呈现的结果,由结果可以看出观众对于本文电影的感受是受到了非常大的历史震撼的,而北京和上海的用户对于本文电影的内容在豆瓣网上的评论较多。
参考文献:
[1] 孙冰.基于Python的多线程网络爬虫的设计与实现 [J].网络安全技术与应用,2018(4):38-39.
[2] 成文莹,李秀敏.基于Python的电影数据爬取与数据可视化分析研究 [J].电脑知识与技术,2019,15(31):8-10+12.
[3] XIE D X,XIA W F. Design and implementation of the topic-focused crawler based on scrappy [J].Advanced Materials Research,2014(850-851):487-490.
[4] 孔钦,叶长青,孙赟.大数据下数据预处理方法研究 [J].计算机技术与发展,2018,28(5):1-4.
[5] 祝永志,荆静.基于Python语言的中文分词技术的研究 [J].通信技术,2019,52(7):1612-1619.
[6] 涂小琴.基于Python爬虫的电影评论情感倾向性分析 [J].现代计算机(专业版),2017(35):52-55.
作者简介:高雨菲(1999.07—),女,汉族,四川内江人,本科在读,研究方向:数据科学与大数据技术。
猜你喜欢
教书育人·高教论坛(2016年12期)2017-01-17
艺术与设计·理论(2016年4期)2017-01-16
科技传播(2016年19期)2016-12-27
中国管理信息化(2016年21期)2016-12-27
软件工程(2016年8期)2016-10-25
软件工程(2016年8期)2016-10-25
中国新通信(2016年16期)2016-10-18
