
基于随机森林和支持向量机在小麦种子分类中的比较研究
2020-06-28 07:47:04张涛
河西学院学报 2020年2期
张 涛
(兰州财经大学统计学院,甘肃 兰州 730020)
小麦是中国四大主粮之一,是仅次于水稻而居第二的重要粮食作物.我国作为人口大国,对口粮的压力越来越大,保障国家粮食安全理所当然成为了头等大事,因此,小麦产业发展直接影响到国家粮食安全和社会稳定.然而,不同品种的小麦对病害的感染程度有差异[1],那么如何以极高的准确率将小麦品种正确分类就成为一个具有重要研究意义的课题.
机器学习的本质就是算法,其核心问题在于有意义地变换数据,换句话说,在于学习输入数据的有用表示,这种有用表示可以让数据更加地接近预期输出.机器学习的技术定义是在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示.我们可以将机器学习想象成一个“黑盒”,利用机器学习,人们输入的是数据和从这些数据中预期得到的答案,而这个黑盒系统输出的是规则.这些规则随后可应用于新的数据,并且使计算机自主地生成答案.
本文基于Anaconda 脚本,选取UCI数据库的seeds数据集,并将其划分成训练集和测试集.选择机器学习中的随机森林和支持向量机(Support vector machine,SVM)两种算法分别构建模型以对划分好的训练集进行学习,并在其测试集上进行分类,接着选取分类精度(Accuracy)作为模型的评估指标,然后利用网格搜索技术进行参数寻优以取得令人满意的分类结果,进而证明基于两种算法所构建的小麦种子分类模型具有良好的分类性能,最后通过实验结果的对比和分析,评价两种算法的优缺点,总结出基于随机森林所构建的小麦种子分类模型整体上要优于基于支持向量机所构建的模型.
1 两种算法的理论概述
随机森林是一个包含多个决策树的分类器,其输出类别由个别树输出的类别的众数而定,最早由Leo Breiman[2]和Adele Cutler提出.SVM是一种分类方法,最早由Vladimir N.Vapnik[3]和Alexan⁃der Y.Lerner提出,两种算法都是机器学习领域中的研究热点.
1.1 随机森林的相关理论基础
1.1.1 基本单元—决策树
决策树是广泛用于分类和回归任务的模型,因其结构呈树形,故称决策树.学习决策树,本质上讲就是学习一系列if/else问题,目标是通过尽可能少的if/else问题来得到正确答案,我们从这些一层层的if/else问题中进行学习并以最快的速度找到答案.
1.1.2 集成学习
集成学习是合并多个机器学习模型来构建更强大模型的方法.目前,集成学习主要有两大流派(bagging 派系和boosting 派系),其中boosting 派系的代表算法主要有AdaBoost 算法[4]、梯度提升机(GBDT)[5]和极限提升机(XGBoost)[6],而本文中选择的随机森林是属于bagging 派系的典型代表,其算法描述在表1中给出,从本质上讲就是许多决策树的集合,其中每棵树都和其他树略有不同.对于分类问题,随机森林中的每棵树都是一个分类器,也就是说,每棵树做出一个分类结果,随机森林集成了所有树的分类投票结果且结果的投票是等权的[7],即对所有的投票取平均值,并将投票次数最多的结果作为输出.

表1 bagging算法流程
1.2 SVM的相关理论

2 数据的获取与描述性统计分析
2.1 数据的获取和结构分析
本文使用的数据来自于UCI数据库的seeds数据集[10],其官方网址为:http://archive.ics.uci.edu/ml/datasets/seeds.
该数据集一共有210个数据样本,每个样本包含了小麦的7种测量数据,即7种特征,分别是面积(A)、周长(P)、种子饱满度(C)、谷粒长度(L)、谷粒宽度(W)、偏度系数(AC)、谷粒槽长度(LKG).
这210个样本根据小麦品种的不同分为三类,分别是Rosa品种,包含样本1~70,对应类别标签(label)为1;Kama品种,包含样本71~140,对应类别标签(label)为2;Canadian品种,包含样本141~210,对应类别标签(label)为3.
从直观上看,这是一个典型的平衡数据.因此,我们要处理的问题就是平衡多分类问题.我们使用Anaconda中的scikit-learn库的train_test_split函数将数据集打乱并拆分,这个函数将数据集中75%的样本及对应的类别标签作为训练集,共计157 个样本(其中类别1 有53 个,类别2 有49 个,类别3有55个),剩下25%的样本及对应的类别标签作为测试集,共计53个样本(其中类别1有17个,类别2有21个,类别3有15个).
2.2 描述性统计分析和特征分布图
我们使用pandas库的describe函数来实现数据集的描述性统计,并通过绘制散点矩阵图,实现数据集特征分布的可视化,从而两两查看所有的特征.

表2 seeds数据集的描述性统计
从表2可观察到数据集各个特征的条目统计(count),平均值(mean),标准差(std),最小值(min),25%,50%,75%分位数和最大值(max).
从图1可以观察到面积(A)—周长(P),面积(A)—谷粒长度(L),面积(A)—谷粒宽度(W),周长(P)—谷粒槽长度(LKG)等图像呈现线性关系;面积(A)—偏度系数(AC),周长(P)—偏度系数(AC),谷粒长度(L)—偏度系数(AC)等图像的关系比较复杂,很难用线性关系表示.
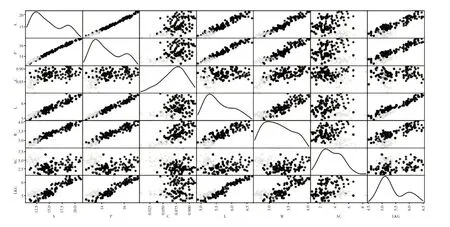
图1 seeds数据集的散点矩阵图
3 基于随机森林算法的分类模型
3.1 构建一个“基准”的随机森林算法模型
首先尝试直接使用默认参数去构建模型.这里我们调用Anaconda中的scikit-learn库的ensemble模块,通过将该模块中的RandomForestClassifier类实例化来实现模型的构建,然后利用划分好的训练集拟合该模型并在测试集上进行分类预测,实验结果表明其分类精度达到92%.
3.2 决策树的可视化
树的可视化有助于深入理解算法是如何进行预测的,也易于非专家理解机器学习算法这个“黑盒”.作为随机森林的一部分,树被保存在estimators_属性中.我们可以利用tree模块的export_graph⁃viz函数来将树可视化.这里我们以构建的随机森林中的其中一颗树为例,将其决策过程可视化.
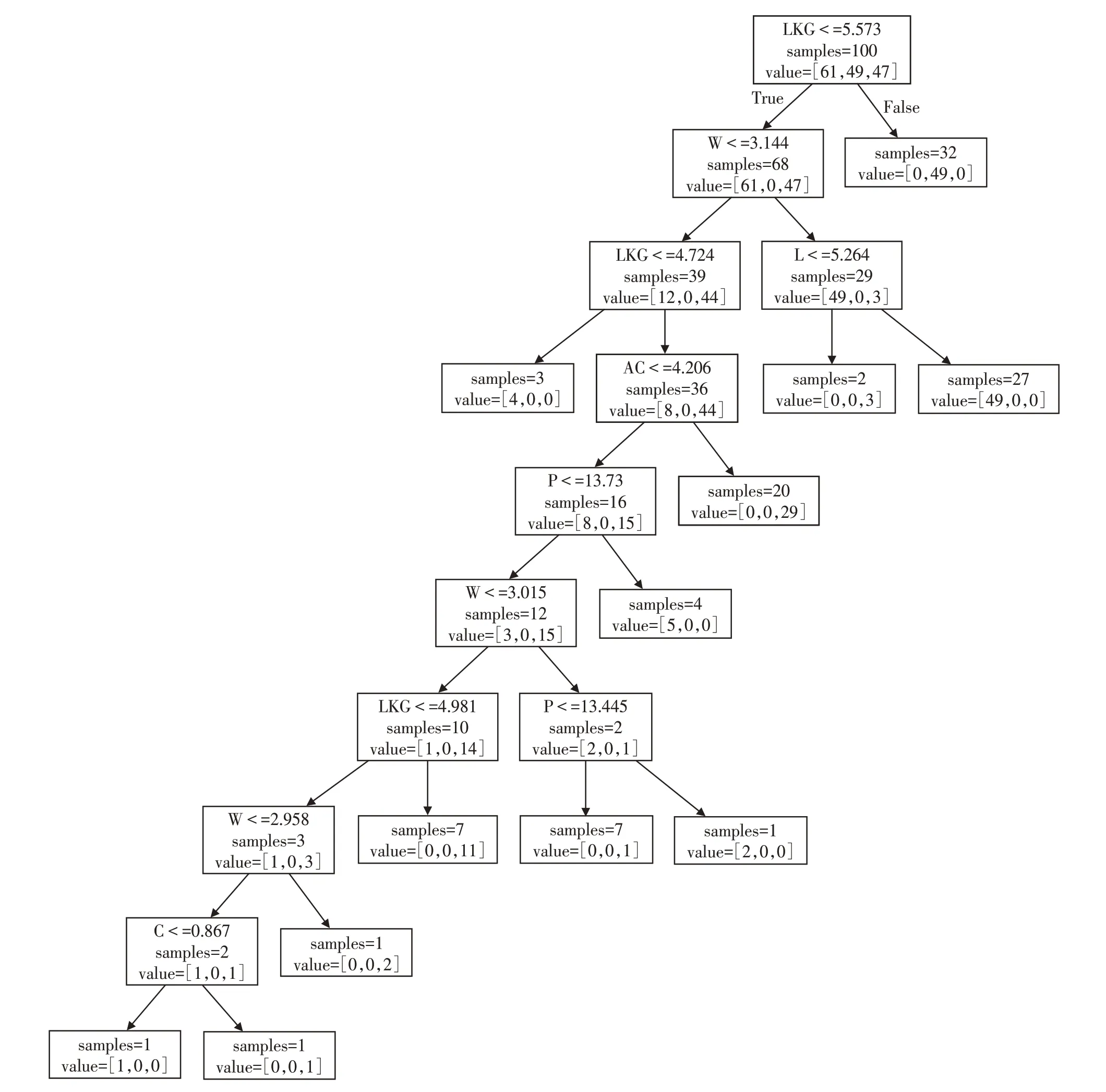
图2 seeds数据集构造的随机森林中一颗树的可视化
其中图2每个节点的samples给出了该节点的样本个数,value给出的是每个类别的样本个数.
3.3 树的特征重要性可视化
除了将树的决策过程可视化之外,我们还可以利用树的特征重要性来总结树的工作原理.它为每个特征对树的决策的重要性进行排序,通常被被保存在feature_importance_属性中.我们可以通过构建一个自定义函数来实现树的特征重要性可视化.

表3 小麦种子的7种特征重要性
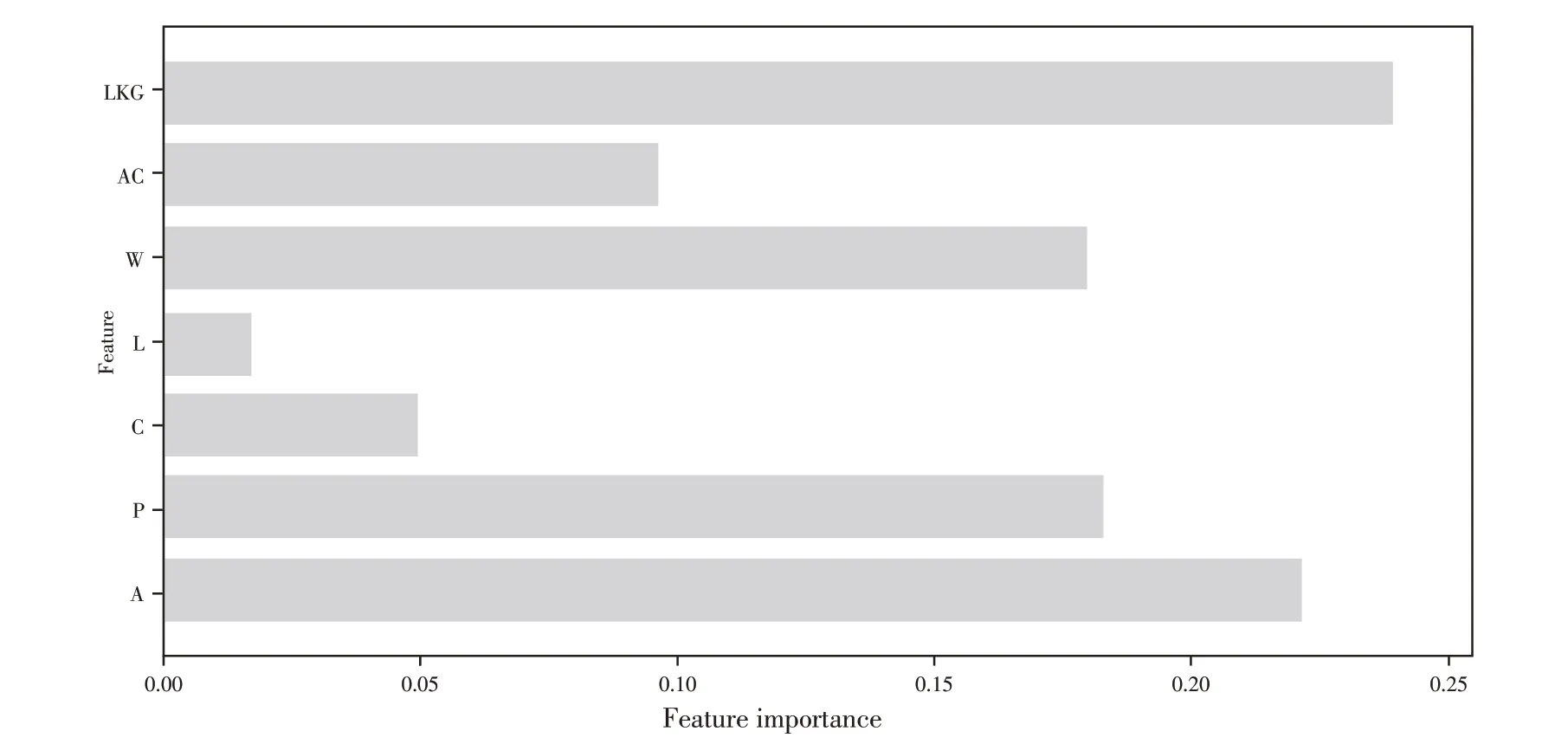
图3 seeds数据集上学到的树的特征
表3 显示的是各个特征重要性的数值.从图3 中可以观察到谷粒槽长度(LKG)是最重要的特征,说明所构建的随机森林模型是以谷粒槽长度(LKG)这一特征作为最重要的分类依据.
3.4 模型的调参优化—简单的网格搜索
通过调参来提升模型的泛化能力,达到优化模型的目的.这是一项棘手的任务,但对于所有模型和数据集来说都是必要的.最常用的调参方法有网格搜索技术,通过指定参数n_estimaors取不同的取值(1,5,10,50)—该参数用于确定构造的随机森林的树的个数,即分别构造1 颗树、5 颗树、10颗树和50颗树组成的模型.原则上来讲,参数n_estimaors 总是越大越好,不过收益是递减的,即模型的反馈效果是边际递减的.在参数n_estimaors 上使用for 循环,通过穷举搜索式的“贪婪”算法来得到最优的结果.

表4 各参数模型的预测结果
从表4中可以观察到最优参数为50,其对应的分类精度为96.22%.与基准模型(92%)相比,经过调参优化后的模型在分类精度有了不少的提高,在小麦种子分类性能上有优秀的体现.
4 基于SVM算法的分类模型
4.1 数据预处理
观察seeds数据集,原始数据包含面积、周长、无量纲的量都混合在一起,例如面积(A)是有量纲的,其量纲为平方米,而种子饱满度(C)是无量纲的.这些量纲不同、数量级不同的特征对其他模型(比如随机森林)可能是小问题,但对SVM却又极大影响,会影响其分类决策的贡献度[11].因此,我们需要对原始数据集进行预处理—归一化,确保每个特征的值落在0到1的范围之间,这里我们调用scikit-learn库的preprocessing模块,通过将MinMaxScaler类实例化来实现对原始数据集的归一化,并通过箱线图和小提琴图将归一化后的数据集实现其可视化.
从图4中可以观察到归一化后的训练集的7种特征都位于0到1之间,而归一化后的测试集的特征绝大部分也位于0 到1 之间,有些特征在0 到1 的范围之外,其原因是实例化的MinMaxScaler对象总是对训练集和测试集应用相同的变换,换句话说,总是减去训练集的最小值,然后除以训练集的范围,而这两个值可能与测试集的最小值和范围并不相同.不过,这并不影响实验结果.从图5中可以观察到归一化后的训练集和测试集的分布形状及其概率密度,相当于箱线图和密度图的结合.
4.2 构建一个“基准”的SVM算法模型
这里同样使用默认参数去构建SVM模型,调用Anaconda中的scikit-learn 库的svm模块,通过将该模块中的SVC类实例化来实现模型的构建,然后利用归一化后的训练集拟合该模型并在测试集上进行分类预测,实验结果表明其分类精度达到91%.
4.3 模型的调参优化—带交叉验证的网格搜索
带交叉验证的网格搜索是一种常用的调参方法.这里调用Anaconda 中的scikit-learn 库的mod⁃el_selection模块,通过将该模块中的GridSearchCV类实例化来实现.我们用一个字典指定要搜索的参数组合:C和({C:0.01,0.1,1,10,100;:0.01,0.1,1,10,100})—参数C是正则化参数,参数是控制高斯核宽度的参数,两者控制的都是模型的复杂度,相关度高,应同时调节.这样我们就构建了25组不同的参数组合,然后指定要使用的交叉验证策略(这里选择5折交叉验证)来拟合实例化的GridSearchCV对象,通过cv_results_属性找到其保存的网格搜索的所有内容,并将其转换成pandas数据框以供查看,最后我们截取数据框中的部分重要结果做成表格.

图4 归一化后的训练集(左)及测试集(右)的箱线图
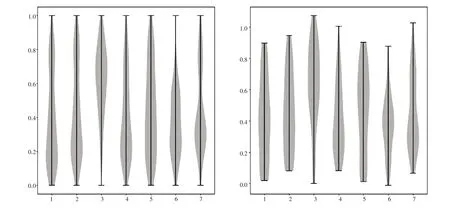
图5 归一化后的训练集(左)及测试集(右)的小提琴图

表5 各参数组合模型的预测结果
5 结论
本文将随机森林算法和SVM算法应用到小麦种子分类模型中,根据各个模型的输出结果,对其进行比较和分析,得到以下几点结论:
(1)在分类精度方面,基于随机森林算法构建的分类模型要优于基于SVM算法构建的分类模型,即用随机森林算法构建的分类模型所得到的分类精度(Accuracy)高于用SVM 算法构建的模型的分类精度.
(2)在数据预处理方面,两者有明显差异.数据预处理对SVM 影响较大,而随机森林不需数据预处理.这也是如今很多应用中用的都是树的模型,比如随机森林(需要很少的预处理,甚至不需要预处理).
(3)在调参方面,显然SVM需要调整的参数个数明显多于随机机森林,其调参需过程也比较繁琐.而随机森林的调参就比较简单且易实现,通常不需要繁琐的调参过程,甚至不调参(使用默认参数),也能达到相对满意的效果.
总体而言,基于随机森林算法构建的模型是比SVM算法更有加效的小麦种子识别技术,而且还可以将决策过程以可视化的方式向非专家展现出来.将该模型应用于小麦种子分类问题,提高分类精度以辨识不同品种的小麦对病害的感染程度,促进我国小麦产业的健康发展.
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
金桥(2021年10期)2021-11-05 07:23:28
今日农业(2021年13期)2021-08-14 01:38:00
作文小学中年级(2020年4期)2020-06-11 12:47:08
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
