
深度学习在药物研发中的研究进展
2020-06-27 05:03廖俊徐洁洁皮志鹏窦智扬尚靖
药学进展 2020年5期
廖俊,徐洁洁,皮志鹏,窦智扬,尚靖
(1.中国药科大学理学院,江苏 南京211198;2.中国药科大学中药学院,江苏 南京211198)
药物研发过程主要包括药物靶点确定、先导化合物的发现与优化、候选药物确定、临床前研究和临床研究[1]。整个药物研发进程,就是在验证某个靶点在人体中的生物学功能的过程。而药物靶点的缺乏、动物模型临床转化差、疾病异质性及生物系统内在的复杂性等问题,使得药物研发成为一个漫长而又艰难的过程。开发一种新型处方药,平均税前支出约为25.58亿美元[2],大约需要10 ~ 15年。尽管投入成本高,但在药物研发过程中创新小分子的临床批准成功率却只有13%,失败的风险相对较高。早期药物发现主要基于经验尝试,化合物筛选以及偶然发现获得。在现代药物研发中,机器学习在定量结构-活性关系(quantitative structure activity relationship,QSAR)模型[3]、定量结构-性质关系(quantitative structure property relationship,QSPR)模型[4]等方面发挥重要作用。不同于传统的机器学习方法使用手动设计的特征,最新的深度学习(deep learning,DL)方法可以自动从输入数据中学习特征,通过多层特征提取将低层特征转换为高层特征。由于其强大的泛化和特征提取能力,将其应用在药物开发的不同环节,包括蛋白质结构与功能预测、药物代谢动力学性质预测、药物有效性及安全性预测以及药物相互作用预测等,显示出巨大的前景。本综述回顾了近几年来DL在药物研发中的应用,并对当前问题提出建议以及展望。
1 深度学习与药物研发数据
DL的概念由Hinton等[5]于2006年提出,其概念源于人工神经网络的研究。DL的结构是一种含多隐层的多层感知器结构,其通过组合底层特征形成更加抽象的高层来表示属性类别或特征,以发现数据的分布式特征表示。DL理论中包含了许多不同的深度神经网络模型,例如经典的深层神经网络(deep neural network,DNN)、深层置信网络、卷积神经网络(convolutional neural network,CNN)、深层玻尔兹曼机(deep boltzmann machines,DBM)、循环神经网络(recurrent neural network,RNN)等。不同结构的网络适用于处理不同的数据类型,例如CNN适用于图像处理,RNN适用于语音识别等。同时,通过与不同算法的联用这些网络模型还会产生一些不同的变种。
目前正处在医药产业发展的关键节点,由于新药物靶点和作用机制的发现越来越难,新药研发需要投入更多的资金和精力。提升研发效率和深度挖掘已有数据来发现新的规律是解决该问题的有效途径之一,而DL在这2个方面都可以有广泛的应用,因此许多制药公司和药物研发机构都将DL方法用于辅助药物研发。例如:Berg公司基于人工智能的Interrogative Biology平台技术[6]通过分析海量病人和正常人样本(如蛋白相互作用网络)来寻找治疗疾病的新靶点和诊断疾病的生物标志物,以Berg公司进行肿瘤药物研究为例,通过收集大量生物样本,如血液、肿瘤组织或肿瘤患者的尿液,同时也收集捐助者的健康组织样本。研究人员会创建细胞株,然后将其放进不同的模拟患者发病时的实际状态环境下进行观察,有比如低氧环境,高血糖患者细胞及肿瘤细胞喜欢生活的环境。细胞株建立之后,对其中的基因、蛋白质、代谢物和脂肪进行标识并形成节点,不同节点的重要程度不同,重要程度越高与疾病的关联越大。Narain等[7]曾基于此平台介导发现胰腺癌的检测、分层和预后的分子标记; IBM Watson为IBM旗下的认知计算系统,技术平台。认知计算代表一种全新的计算模式,它包含信息分析,自然语言处理和机器学习领域的大量技术创新。该新药发现系统[8]通过自然语言处理技术分析海量文献,寻找潜在的关联性来预测新的假说推动新药研发;Engine Biosciences[9],也是利用人工智能技术来进行老药新用、新靶点开发以及精准医疗等服务的互联网产品。图1列举了目前DL在药物研发不同阶段已经取得成果的相关应用。
2 深度学习在药物研发中的应用
2.1蛋白质结构与功能
蛋白质的功能研究在生命科学中占据重要的地位,大多数疾病的发生都与蛋白质功能障碍有关。1973年,An finsen[10]发现变性的只保留了一级结构的核糖核酸酶可以重新折叠并恢复生物活性,说明代表蛋白质一级结构的氨基酸序列中隐含了蛋白质二级、三级结构的信息。而蛋白质二级结构预测又可为蛋白质三维结构预测和蛋白质功能预测提供重要信息。因此从一级氨基酸序列预测二级结构及蛋白质的性质是药物研发中的重要任务。表1简要列举了DL在蛋白质结构和功能预测中的应用。
尽管近年来X-射线晶体学和冷冻电镜技术的不断发展在蛋白质结构解析上获得突破,但其检测蛋白质的成本过高,利用DL对蛋白质进行预测显然是一个更高效的方法。通过对数据库提供的蛋白质数据特征提取,预测出蛋白质结构与功能,为解决蛋白质结构和功能的预测问题提供了可能的途径,并在蛋白质结构和功能预测方面取得了较好的结果。
2.2 活性药物靶点的确定
药物靶点与疾病或生物分子的病理状态相关,药物靶点的确定是药物研究和开发的基础。传统的药物发现主要遵循“一种药物,一种靶点,一种疾病”的观念,最近越来越多的研究人员接受了药物靶点是多种靶蛋白的观点[15-16],并且多种靶蛋白倾向于出现在同一种疾病中[17]。因此,如何快速准确地识别药物与靶点之间复杂的相互作用已成为药物开发的关键。
Pu等[18]采用CNN训练检测和分类核苷酸与血红素结合位点,准确度达到了95%,且实验模型能够推广到类固醇结合蛋白和肽酶。Hamanaka等[19]提出的DL模型在检测药物活性靶点时可以在保证98.2%的准确率的情况下对400万个数据进行计算。Wen等[20]首先对未处理的原始数据进行预处理,标记出已知的药物靶点相互作用,然后应用已知的标记过的药物靶点对来训练分类模型,该模型的10-折交叉验证的曲线下面积(area under curve,AUC)得分为0.915 8±0.005 9,该得分越趋近于1则说明效果越好,该模型可进一步用于预测新靶点。
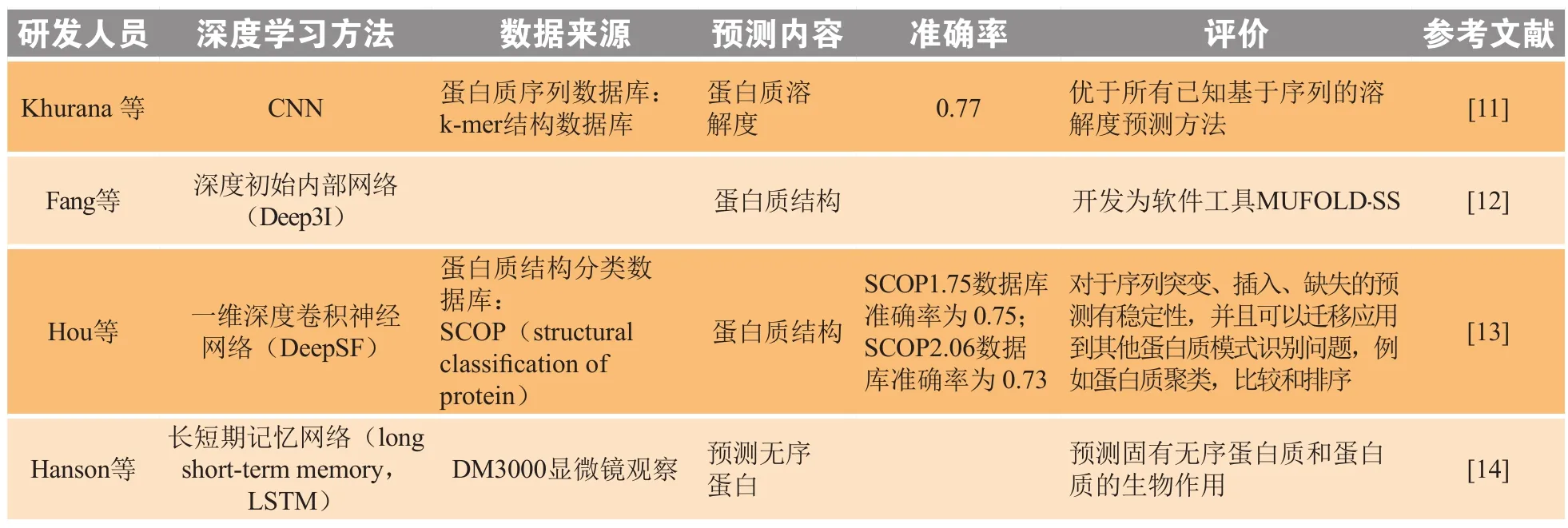
表1 深度学习在蛋白质结构和功能预测中的应用Table 1 Application of DL in the prediction of protein structure and function
Tian等[21]通过分层抽象学习药物靶点对的有用特征,在平衡和不平衡数据集(平衡数据集是指各个样本数量差距不大,而不平衡数据集则相反,在一些模型中数据集是否平衡对预测结果有着不同影响)上的预测性能均比现有方法更好。Tsubaki等[22]结合化合物的图形神经网络(graph neural network,GNN)和蛋白质的CNN开发了新的复合蛋白相互作用预测技术。此外,所提出的方法在不平衡数据集上明显优于现有方法。这表明由端到端GNN和CNN获得的化合物和蛋白质的数据驱动表示比从数据库获得的传统化学和生物学特征更稳健。Zong等[23]采用DL算法DeepWalk基于异构拓扑计算药物-药物和靶点-靶点的相似性,基于“牵连犯罪”原则推断药物靶点关联,AUC得分为0.989 6。
Xie等[24]基于药物干扰和基因敲除试验收集的药物和药物对,靶点和靶点对的相似性数据库L1 000中的转录组数据提出了活性药物靶点的确定(drug target identi fication,DTI) 预 测 框 架,训练集达到98%以上的准确率,验证集准确率为90.53%±1.44%。同时使用其他DTI数据库如STITCH、 DGIdb以及CTD验证了模型预测新DTI的能力,均取得较好的结果。
计算机在处理复杂运算方面具有天然优势,而DL可以进一步发现对象之间的隐性联系。DL的方法应用于复杂的药物与多靶点作用问题,通过合适的网络模型得到潜在靶点,将大大提高药物靶点研究的效率。
2.3 药物代谢动力学分析
药物代谢动力学(pharmacokinetics,PK)分析是药物研发过程的重要组成部分,调查显示大约一半的候选药物由于PK性质或毒性不令人满意而无法进入市场[25]。DL正是PK分析的一项重要技术手段。
图2分别从药物的吸收、分布、代谢与毒性几个方面举例了DL应用。以PK的关键性质之一水溶性为例,药物的水溶性将直接影响化合物在生物体中的吸收。Li等[26]建立了基于半监督学习模型的多层深度信念网络( deep belief network,DBN)来预测化合物的水溶性,准确率达到85.9%。不只是吸收分布的PK性质,候选药物的代谢毒性也是其后续能否成药的关键因素。分析1 824种美国FDA批准的药物,其中29.6%的药物经计算确定具有潜在的hERG(human ether-à-go-go-related gene)抑制活性,突出了hERG风险评估在早期药物发现中的重要性。为了在药物发现阶段和上市后监测中对hERG介导的心脏毒性进行风险评估,Cai等[27]开发了一种DNN模型用于预测药物发现和上市后监测过程中小分子的hERG阻滞剂。在验证集中,最佳模型的AUC为0.967。
DL为以传统模型为基础的PK分析带来了新的模型以及新的分析方式,并且就特定的问题给出了更为精确的答案。
2.4 药物相互作用
当药物与另一种药物共同服用时,此药物的预期功效可以发生显著改变。因此,了解DDI对于减少意外的不良药物事件(adverse drug event,ADE)的发生以及在治疗疾病时产生最大化协同效益至关重要。另外由DDI引起的ADR是药物退出市场的主要原因之一[28]。随着用于疾病治疗的多种药物(至少2种药物)的处方数量持续增加,了解DDI的意义越来越大。探索用于检测相互作用药物的大量药物组合的最实用方法是通过计算机DDI检测。
虽然一些已知的DDI可以在专门建立的数据库中找到,但大多数信息仍然埋藏在文献中。因此,迫切需要从生物医学文本中自动提取DDI。为了检验仅使用字嵌入作为输入特征的CNN是否可以成功应用于生物医学文本中的DDI分类,Suárez-Paniagua等[29]提出仅具有一个隐藏层的CNN架构,使得模型在计算上更有效。Jari等[30]使用CNN同时提取事件和关系,与不同的向量空间嵌入一起应用于各种文本分类任务。Zhao等[31]提出语法卷积神经网络(syntax convolutional neural network ,SCNN),基于单词嵌入、语法单词嵌入来使用句子的句法信息,引入位置和词性特征以扩展每个单词的嵌入,引入自动编码器来编码传统的特征文本词袋(稀疏0-1向量)作为全连接向量。
除CNN外RNN也常用于生物医学关系提取,Zhang等[32]基于候选句子的依赖图生成最短依赖路径(shortest dependent path,SDP),将SDP划分为依赖词序列和关系序列。RNN和CNN分别用于自动学习句子序列和依赖序列的特征。最后,将RNN和CNN的输出特征结合起来检测和提取生物医学关系。
Sahu等[33]提出了3种长短时记忆模型(long short-term memory,LSTM)网络模型,即双向长短时记忆网络(bi-directional long short-term memory,Bi-LSTM),基于Attention模型的Bi-LSTM(attention based bi-directional long short-term memory,AB-LSTM)和基于联合模型的AB-LSTM(joint attention based bi-directional long short-term memory,joint AB-LSTM)。这3种模型都使用文字和位置嵌入作为潜在特征。此外,使用Bi-LSTM网络允许从整个句子中提取隐含特征。2个模型AB-LSTM和joint AB-LSTM也在Bi-LSTM层输出中应用注意池,以便为特征分配权重。
Song等[34]利用支持向量机模型(support vector machine,SVM)建立了一个机器学习模型。所建立的相似性测度包括二维分子结构相似性、三维结构相似度、相互作用指纹图谱相似性、靶标相似性和ADE相似性。根据所建立的5种相似性度量方法,将已知有作用的药物和可能有作用的药物进行处理,使结构以数据形式表示,并将处理结果作为SVM的输入向量。SVM模型建立的思路以及所用数据库如图3所示。最终,此SVM模型预测准确率达到0.97,远高于之前的DDI模型。
2.5 药物不良反应
ADR是一个严重的问题,即尽管给予常规剂量的药物,但仍会出现不良反应。据估计,住院患者中有超过200万例发生严重ADR,每年导致大于 100 000例患者死亡[35]。因此识别或预测潜在的ADR显得尤为重要,表2介绍了4个DL在ADR方面的应用,并对各自的结果进行了简要评价。

表2 深度学习在ADR中的应用Table 2 Application of DL in the prediction of ADR
DL帮助科研人员从庞大复杂的ADR报告中筛选并识别了可能具有临床价值的ADR,辅助药物的应用并且可能会揭示未知的药物代谢途径。
3 结语与展望
人工智能通过分析海量的文献、专利和临床结果,找出潜在的、被忽视的通路、蛋白和机制等与疾病的相关性,从而提出新的可供测试的假说,通过实验验证已经取得一定的成果,并显著提高新药研发流程中某些阶段的效率。值得注意的是,DL提供了一种新的方法来探索基因组变异与药物基因组学研究中的多种事件之间的复杂关联,为全基因组关联分析的数据复杂性提供有效的解决方案。但是目前DL并不能直接预测一个化合物能否成为药物,DL在发现药物研发新机制和新靶点上的突破仍然面临以下挑战:
1)基于大数据的人工智能,擅长的是对已有知识的挖掘、重新组织和分配,为DL算法提供大量数据,并且将需要解决的问题正确地呈现出来,它们才有可能捕捉到人类无法捕捉到的规律,在海量的数据中寻找已有知识的关联性。在新药研发过程中,新药研发规则不明确,数据不明晰甚至含有错误信息,而且充满了高度不确定性等问题,给以高质量标识数据集为基础的DL人工智能带来巨大的挑战;
2)DL依赖于高质量、有标识的大数据集。例如:Santos等[39]统计了美国FDA批准的1 578个药物总共的靶点数目是667个,而Ensembl数据库标注的潜在药物靶点就有4 479个,药物靶点数据库(therapeutic target database,TTD)含有2 360个可成为药物靶点的分子信息,包括388个已有相应药物上市的、461个处于临床试验阶段的以及其他正在研究的和已停止研究的药物的靶点信息,由于数据库涵盖面不同,信息来源亦不同,导致有实验支持的信息和预测的信息混杂在一起,药物和靶点的命名也未采用统一规则,如何整合成DL依赖的靶点数据是关键;
3)DL是非常出色的算法工具,能够学习数据,但无法判断数据准确性,尤其是遇到不常见的情况时,它缺乏灵活性,表现并不算好。同时存在无法修正学习结果,除非重新训练的问题;
4)DL的内部机制一直是困扰现今科学家的难题,DL是一个“黑箱”,药物在人体中作用的机制是另一个“黑箱”。通过DL研究药理问题被视为用一个“黑箱”代替另一个“黑箱”,也就是说DL并没有实际解决药物机制这一重大难题。即DL仅展示了可能的结果,而没找到真正的因果关系;
5)DL的评价机制仍然存在欠缺。DL具备发现隐藏在复杂的生物系统下的各种关系的能力,帮助药物研发找到了一个模型来解释生物复杂系统中发生的事情,但模型预测结果依然需要实验验证。如何用少量合适的实验使得药物研发人员进行有效验证和评价DL的结果是一个待解决的问题。
综上,面对药物研发需要解决的问题的多样性,也需要有更为灵活和细致入微的思考方式,构建适合药物研发各阶段的特殊DL模型,并且将这些模型整合才能在未来实现智能的药物研发。
猜你喜欢
黄河之声(2022年10期)2022-09-27
肝博士(2022年3期)2022-06-30
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中老年保健(2021年3期)2021-12-03
海外星云(2021年9期)2021-10-14
中国生殖健康(2020年7期)2020-12-10
医学研究杂志(2015年7期)2015-06-22
同位素(2014年2期)2014-04-16
