
基于MOOC的课程讨论文本话题挖掘研究
2020-06-22 13:15田娜周驿严蓉
软件导刊 2020年5期
田娜 周驿 严蓉


摘 要:为深入挖掘和分析在线课程讨论区中的文本数据,有效识别出参与该课程学习者关注的话题,改进在线课程教学效果,通过对学习者讨论文本进行高频词汇分析,得到词云图,形成对学习者关注内容的整体认识;利用LDA话题模型对学习者的讨论文本数据进行话题挖掘,得到9个热点话题。实验结果表明,学习者在线讨论关注话题主要涉及Python语言编程基础知识、课程证书、作业测试、开发环境配置以及第三方库的安装等。利用LDA模型可以从大量课程讨论文本数据中有效识别出学习者关注话题,进而改进在线课程。
关键词:MOOC;课程讨论话题;LDA;主题模型;话题挖掘
DOI:10. 11907/rjdk. 191855 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2020)005-0168-05
0 引言
MOOC一词自出现以来,就以其课程资源开放性、不受观看时间地点限制等特点引起广泛关注[1]。这种新型的课程教学方式打破了传统教学局限于教室、学校的时空界限,使教学内容不再局限于课本,推动了传统教育教学模式的转变,给教育教学注入了新活力[2]。教育部《2019年教育信息化和网络安全工作要点》中提出:“要扩大高校优质教育资源覆盖面,积极服务学习型社会建设,继续推动国家开放大学网络学习课程、通识课程、五分钟课程等,使上线的网络课程总量超过350门,启动100门大规模在线开放课程建设[3]。”在这样的背景下,各高校积极进行MOOC课程建设,涌现了一批优秀在线课程学习平台,如中国大学MOOC、网易云课堂、爱课程网等。
在线课程讨论区作为在线学习平台学习者与学习者之间、学习者与教师之间最直接的交流空间,是当前在线课程教学常用的辅助手段之一,其中包含学习者的重要学习内容与学习行为数据,对学习者的知识建构、增强学习者之间的互动以及教师进行教学设计等具有重要意义[4]。但实践中发现也有学习者没有从MOOC平台的学习中获得足够的知识,MOOC未体现出应有的价值,导致MOOC的高退学率。在MOOC论坛开展相互讨论在一定程度上可以解决该问题[5]。
Kiemer等[6]研究证明,通过课堂的交互性对话,能够激发学习者的内在学习动机和能力,增强课堂活力。虽然在线课程讨论区具有众多优势,但是许多讨论区存在学习者参与互动频率低、互动话语质量差等问题。由于缺乏积极有效的引导,在讨论区中进行讨论时,学习者之间的对话稍有不慎就会偏离主题;而讨论区主题大都强调以教师为中心,忽视了不同学习者的个性化需求,造成学习者参与讨论不积极。现在的在线课程讨论区支持学习者发布文本,以此表达对某一问题的看法或提出自己的问题。文本作为学习群体之间一种普遍的交流方式,能够表现出学习者自身心理加工过程,是学习动机、认知发展、情感态度、学习体验等的真实表现[7]。通过对在线课程讨论区学习者互动文本进行挖掘与分析,可以有效反映学习者的学习现状、促进教师教学方法创新,对学生整體行为进行监控和预警。当前,在线学习平台主要依赖学习时长、观看视频时长、参与讨论次数、考试成绩等结构化数据反馈学习情况,较少对半结构化或非结构化数据(文本、图片、视频等)进行研究与运用 [8]。如果采用传统的内容分析法会存在费时费力、评价主观性和反馈滞后性等问题[9]。因此,通过对在线课程论坛中的文本数据进行挖掘与分析,对促进在线课程开展具有重要意义。
1 文献综述
国外对在线学习研究起步较早,主要聚焦于学习行为研究、学习效果影响因素研究及在线学习工具、学习预警等。对于在线课程论坛,国外研究者也从聚焦于研究行为数据转向分析论坛文本,关注于发现与挖掘论坛讨论主题。Ezen-Can等[10]使用聚类方法对系统平台发表的文本数据进行自动识别,以此帮助理解学习者之间的学习行为和交互内容;Ramesh等[11]以学习者文本数据为研究对象,提出基于种子词的话题模型方法以预测学习者的课程通过率;Gianluca等[12]设计了RAMS(Rapid Monitoring of Learners' Satisfaction)系统,通过挖掘Moodle讨论区中的文本数据以及问卷调查数据,分析单个学习者的学习状态并评估学习者对于该课程的满意度。
目前国内对于在线课程论坛文本数据的研究逐渐增多。如刘三等[13]以某课程为例,应用非监督学习方法LDA模型对某在线课程中未完成和已完成两种类型的学习者的评论文本信息特征结构及语义内容进行挖掘,为改进该课程提供建议;刘智等[4]通过概率话题建模,分析论坛发帖,提取不同学习群体的热点话题以及不同成效的学习者在不同时间段的学习情绪,为学习者知识建构过程提供干预;左明章等[7]以互动话语分析理论为基础,对某大学云平台的课程论坛发帖进行实证研究,构建基于在线学习平台的互动话语分析模型,旨在描述在线课程论坛学习行为,帮助教师识别特殊学习者并进行干预。
2 研究设计
2.1 研究思路
本实验首先通过网络爬虫获取学习者讨论文本并对原始数据进行预处理,然后通过编程对预处理数据进行词云分析,形成对学习者关注内容的整体印象;之后利用LDA主题模型方法对学习者讨论文本进行聚类,找出学习者关注的话题。将获得结果反馈给教师以改进教学,也可帮助教学管理者完善在线平台功能,实现更好的用户体验,还可帮助学习者对该课程形成基本的了解。研究框架如图1所示。
2.2 研究对象
本实验研究对象是中国大学MOOC平台上某课程讨论区的发帖内容。该课程作为中国大学MOOC上的一门国家级精品课程,课程共9周,开课时间为2018年9月18日至2018年11月30日,拥有较多的学习参与者和丰富的交互数据,本实验主要对课程讨论区文本数据进行研究。讨论区包括教师答疑区、课堂交流区和综合讨论区3部分。
2.3 数据收集与预处理
网页包含许多信息,如文本、script脚本、html标记等,网络数据收集指利用一种程序自动收集网络中包含的有用信息,一般是文本信息。现有的网络数据收集方法主要分为两种:①采用商业爬虫软件获取数据,如八爪鱼采集器;②编写网络爬虫程序获取网络数据。本实验通过编写Python程序获取学习者讨论区发帖文本数据,收集到的数据主要包含发帖者的用户名或ID、发帖时间、发帖内容。在去除空值、无效数据之后,得到学习者论坛发帖数据共8 090条。
在获取学习者论坛讨论文本后,需要对原始论坛数据进行预处理,主要目的是将在线课程论坛讨论文本转化为主题挖掘模型能够识别的文本词向量形式,有中文分词、去重及去停用词、词频统计、文本向量化几个过程[14]。
2.3.1 分词处理
不同于英文文本采用空格区分词,中文文本词与词之间的间隔不明确,需要对文本进行分词操作。在众多的中文分词软件中,本文采用中国科学院计算技术研究所开发的ICTCLAS汉语分词系统作为分词工具对讨论文本进行分词处理。
2.3.2 去重与去停用词
仔细观察会发现文本中包含着大量的重复及无效词汇,比如“啊”、“虽然”、“是的”、“好好好”等,这些词汇会对LDA建模结果产生很大影响。对于文本中出现的虚词、介词等无实际意义词汇,通过引用停用词词典(将哈工大停用词表、四川大学机器智能实验室停用词库和百度停用词表整理去重得到本实验所用停用词表)进行过滤。对于重复文本,本文在不考虑语义关系的情况下将其强制压缩成单个词语。
2.4 研究方法
主题模型主要用于计算机及相关领域,潜在语义分析(Latent Semantic Analysis,LSA)、概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)以及潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)等都属于传统的主题模型方法。数据爬取、数据获取、文本预处理、主题挖掘算法、主题建模与主题生成是主题挖掘的主要工作流程[15]。随着模型的深入应用,研究者发现LDA模型在文本方面有很好的处理效果,比如Phan等[16]发现LDA主题模型在表达文本主题时具有很好的聚类效果;Basher[17]运用LDA主题处理交互式文本,为文本主题抽取提供了新思路。
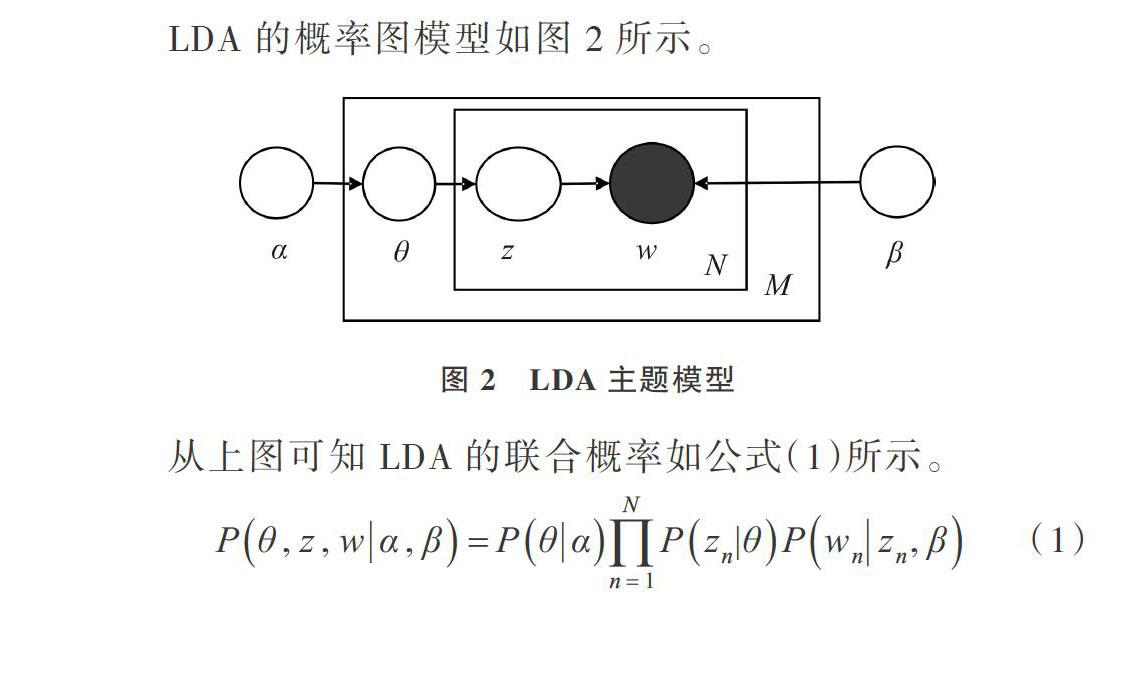
LDA由Blei[18]等于2003提出,其由文档、主题和词3层结构组成,适合挖掘大规模文档集中潜藏的主题信息。基于“词袋(Bag of words)”假设,LDA把文档视为多个潜在主题,每个主题又满足单词的多项式分布。因此,一篇文档可以看作由多个主题构成,每个主题又由多个单词构成[19]。对于一篇文档来说,其生成过程如下:首先从代表文档主题分布向量的θ中抽取一个主题,之后从抽取到的主题对应的词分布中抽取一个单词,不断重复此过程N,直至生成一篇含有N个词的文档。
3 研究结果分析
3.1 高频词汇分析
从图3可以看出,学习者参与讨论文本中出现频率较高的词为“Python”、“老师”、“代码”、“视频”、“作业”、“成绩”、“课件”、“证書”等,这些词汇大致反映出学习者学习该课程的主要目的以及该课程的基本内容,即该课程是一门介绍Python编程的网络课程,学习者对该课程的视频资源、作业测试、课程证书等方面讨论较多。此外,还有一些单词是对该课程内容的表述,如“Jieba”、“判断”、“循环”、“函数”、“变量”、“字符”、“版本”等,这些词在一定程度上是该课程主要知识内容的总结,比如“Jieba”作为目前中文文本预处理的主要工具,在该课程涉及文本处理的代码中广泛使用;而“判断”、“循环”等属于该课程第三节中程序控制结构的重要内容。
3.2 LDA话题聚类
通过词云图对学习者参与讨论的主要内容形成整体印象,利用LDA模型对经过预处理之后的讨论文本进行主题建模。首先确定主题个数,研究发现,在LDA话题模型中先验参数一般设定为[20]:[α]=0.1,[β]=0.01,经过多次调参实验,发现当主题数目num_topics=9时表1实验效果最为显著。表1是学习者参与课程讨论的话题—词汇矩阵,在代码编写过程中,通过计算学习者关注话题概率值,抽取概率值较高的9个话题,并抽取每个话题中出现概率较大的前10个单词,这些单词在一定程度上可以表现出该话题下的主要内容。
由表1可以看出,话题1中学习者关注该课程学习之后证书的获得,说明参与该课程的学习者希望获得课程证书,而这些学习者大都能持续参与学习,是该课程的主要参与者,是研究学习行为的主要对象;话题2主要是关于课程学习平台以及课后作业、测验,以及对该课程视频资源、课件等内容的关注,说明该平台功能还有需完善的地方。学习者对于作业、测验的关注,在一定程度上说明了学习者参与学习的积极性,后期作业设置时要引起注意;话题3 中“turtle”是Python编程中常用的一种库,也是课程进行蟒蛇绘制的主要工具,此外还有“温度转换”实例,也是该课程的主要实例之一,说明学习者对蟒蛇绘制和温度转换两个例子还存在问题;话题4中出现概率较高的前4个单词分别是“函数”、“定义”、“调用”、“变量”,说明学习者主要关注函数相关知识,如何定义一个函数、如何调用函数、函数的执行等都是学习者关注的重点;从话题5 中的单词分布可以看出该话题主要集中于文本数据处理和格式化,其中“Jieba”库是编程人员进行中文文本分词的主要工具包,也是绘制词云,进行词频统计以及其它文本操作需要用到的工具,“解答”、“疑问”等词说明学习者在进行文本数据处理过程中还存在一定问题,需要教师或同学帮助;话题6中“元组”、“集合”、“列表”、“字典”等是Python编程中的数据类型,说明该话题主要是关于组合数据类型的描述;话题7中“if”、“else”、“for”是Python编程语言中循环结构的基本构成。此外,“分支”一词说明学习者对分支结构也有所关注,由此可见,该话题主要是对Python编程语言中程序控制结构的描述;在话题8中“字符串”、“字符”、“类型”等词说明该话题主要表达学习者对基本数据类型的关注;话题9主要是Python学习所需开发环境的配置以及第三方库安装。
[11] RAMESH A,GOLDWASSER D, HUANG B,et al. Understanding MOOC discussion forums using seeded LDA[C]. Proceedings of the 9th ACL Workshop on Innovative Use of NLP for Building Educational Applications. New York:ACM Press,2014:28-33.
[12] GIANLUCA ELIA,GIANLUCA SOLAZZO,GIANLUCA LORENZO,et al. Assessing learners' satisfaction in collaborative online courses through a big data approach[J]. Computers in Human Behavior, 2019(92): 589-599.
[13] 刘三,彭晛,刘智,等. 面向MOOC课程评论的学习者话题挖掘研究[J]. 电化教育研究,2017,38(10):30-36.
[14] 潘怡,葉辉,邹军华. E-learning评论文本的情感分类研究[J]. 开放教育研究,2014,20(2):88-94.
[15] 陈迪,代艳君,王志锋. 论坛主题挖掘研究综述[J]. 计算机工程与应用,2017,53(16):36-44.
[16] PHAN X H,NGUYEN L M, HORIGUCHI S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections[C]. Proceedings of the 17th Inter?national Conference on World Wide Web. ACM, 2008:91-100.
[17] BASHER A R M A, FUNG B C M. Analyzing topics and authors in chat logs for crime investigation[J]. Knowledge and Information Systems, 2014, 39(2): 351-381.
[18] BLEI D M,NG A Y,JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research,2003,3(3):993-1022.
[19] 王鹏,高铖,陈晓美. 基于LDA模型的文本聚类研究[J]. 情报科学,2015,33(1):63-68.
[20] HAO H, ZHANG K, WANG W, et al. A tale of two countries: International comparison of online doctor reviews between china and the united states[J]. International Journal of Medical Informatics, 2017(99):37-44.
(责任编辑:杜能钢)
