
基于BERT+BiLSTM+CRF的中文景点命名实体识别①
2020-06-20 07:32孙连英
计算机系统应用 2020年6期
赵 平,孙连英,万 莹,葛 娜
1(北京联合大学 智慧城市学院,北京 100101)
2(北京联合大学 城市轨道交通与物流学院,北京 100101)
1 引言
随着社会媒体的发展,越来越多的旅游者喜欢通过游记分享旅游体验.游记文本中景点的提取对旅游领域问答系统、个性化推荐等研究具有重要的意义.
1996年,命名实体识别(Named Entity Recognition,NER)一词在MUC-6[1]上提出来的,为自然语言处理的一项基础任务.早期基于规则和词典[2]主要依赖语言学家根据上下文语义结构归纳的模板.该方法对于难以归纳的总结无法解决,识别效果不明显,且归纳总结过程代价比较大,所以学者们使用机器学习方法[3-5]来解决这一问题,机器学习的方法主要采用数学统计进行建模,对NER 问题分类3 类小问题:特征选择、机器学习策略、序列标注等.在处理NER 问题时,使用大规模的标注语料让机器来训练模型,通过训练好的模型对测试语料进行序列解码等,得到命名实体.但机器学习方法对文本特征提取要求较高.目前,基于深度学习的NER 方法[6,7]比前两种方法得到了更广泛的应用,目前流行的方法为BiLSTM 方法.由于BiLSTM 是对序列中各个位置的分数值进行独立分类,不能考虑相邻标签之间的信息.而CRF 能较好解决这个问题,模型最后一层使用条件随机场模型作为句子级的序列标注,如Li 等[8]提出基于LSTM-CRF 的命名实体识别方法.
在对于旅游领域内的景点识别研究,现有的主要是基于机器学习的方法,薛征山等[9]提出的基于隐马尔可夫模型的旅游景点识别方法,该方法虽然在景点实体识别上有一定的效率,但是其未能考虑到上下文之间的语义信息,且在对文本提取特征的过程中未能解决文本特征表示的一词多义问题,旅游领域景点词语一般会存在不同语境下不同含义,比如“黄山”在不同语境下可以指安徽省黄山市,属于地名,也可以指旅游景区“黄山”等,继而景点实体识别效率一般.针对这个问题本文提出将深度学习方法应用到旅游领域景点识别中,在现有研究基础上,提出将BiLSTM+CRF 方法应用旅游领域景点实体识别中.郭剑毅等[10]提出的基于层叠条件随机场方法,该方法过于依赖人工构建特征模板,对于旅游领域,景点实体数量过多,无法一一列举,且在人工构建特征模板的时候耗时耗力,未能考虑到上下文语境和语义的信息.针对该问题,本文将BERT 语言模型[11](Bidirectional Encoder Representation from Transformers,BERT)融合到BiLSTM-CRF 命名实体识别模型中.BERT 语言模型对自然语言处理任务效率有很大的提升,利用该模型可以解决文本特征表示时的一词多义问题.BiLSTM 能够充分利用先验知识,获取有效的上下文信息,CRF 可以考虑句子级相邻标签之间的信息,并且获得全局最优序列.在实际旅游领域内景点识别的测试中比以往学者的研究方法效率有显著提升.P值,R值,F值分别为8.33%,1.71%,6.81%.
2 BERT+BiLSTM+CRF 模型
2.1 模型框架
BERT+BiLSTM+CRF 模型由BERT 模块、BiLSTM和CRF 3 个模块组成.整体模型如图1所示.首先使用BERT 模型获取字向量,提取文本重要特征;然后通过BiILSTM 深度学习上下文特征信息,进行命名实体识别;最后CRF 层对BiLSTM 的输出序列处理,结合CRF 中的状态转移矩阵,根据相邻之间标签得到一个全局最优序列.

图1 BERT+BiLSTM+CRF 模型图
模型第一层是利用预训练的BERT 语言模型初始化获取输入文本信息中的字向量记为序列X=(x1,x2,x3,···,xn),所获取的字向量能够利用词与词之间的相互关系有效提取文本中的特征.
模型第二层为双向LSTM 层,第一层获取的n维字向量作为双向长短时记忆神经网各个时间步的输入,得到双向LSTM 层的隐状态序列(表示前向)和(表示后向),待前向与后向全部处理完,对各个隐状态序列进行按照位置拼接得到完整的隐状态序列记为ht=(h1,h2,···,hn)∈Rn×m,接着线性输出层将完整的隐状态序列映射到s维(s维为标注集的标签类别数目),记提取的句子特征为全部映射之后的序列为矩阵L=(l1,l2,···,ln)∈Rn×s,li∈Rs的每一维li,j分别对应其字xi对 应每个类别标签yi的分数值.如果此时直接对每个位置的分数值进行独立分类,选取每个分值最高的直接得到输出结果,则不能考虑相邻句子之间的信息,不能得到全局最优,分类结果不理想.所以引入模型最后一层.
2.1.1 BERT 模型
BERT[11]是一种自然语言处理预训练语言表征模型.BERT 能够计算词语之间的相互关系,并利用所计算的关系调节权重提取文本中的重要特征,利用自注意力机制的结构来进行预训练,基于所有层融合左右两侧语境来预训练深度双向表征,比起以往的预训练模型,它捕捉到的是真正意义上的上下文信息,并能够学习到连续文本片段之间的关系.模型预训练结构图如图2所示.
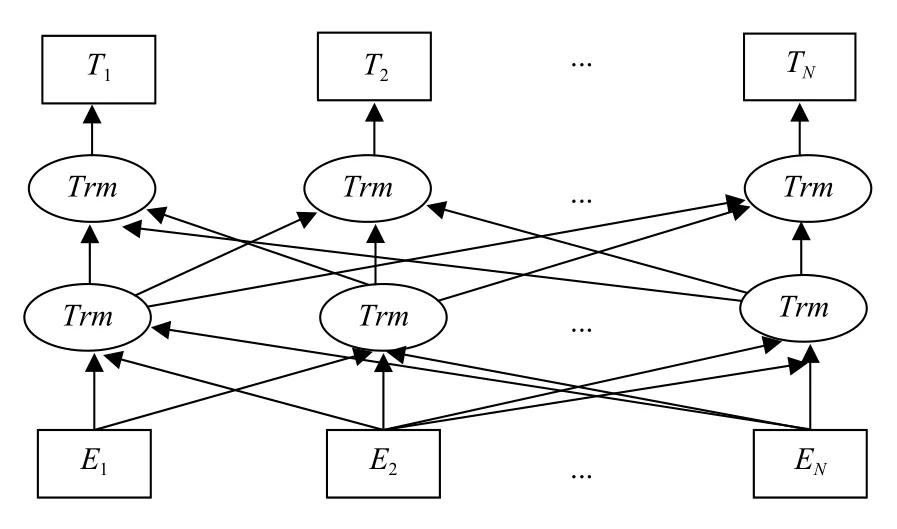
图2 BERT 模型预训练结构图
图2中,Trm表示[11]自注意力机制(Transformer)编码转换器,E1,E2,···,EN表示模型的输入,为词向量,而T1,T2,···,TN表示模型的输出.由于一般的语言模型不能很好理解句子之间的关系,而在命名实体识别中句子之间的语义关系是非常重要的,所以BERT 模型拼接句子L和M,并预测M是否位于原始文本中L之后.语言模型的预训练在文本特征提取时,能解决一词多义问题继而能够改进命名实体识别的任务,所以本文将BERT 语言模型结合到命名实体识别的任务中,取得了显著的效果.
2.1.2 BiLSTM
长短时记忆神经网[12]是1997年提出来的,是目前最流行的递归神经网络,其不仅对短期的输入比较敏感,更能保存长期的状态.LSTM 的主要由3 个开关来控制单元的输入输出.
(1)遗忘门:单元状态ct-1保留到当前时刻ct的决策,计算公式如式(1):

式中,Wfh对应输入项ht-1;Wfx对应输入项Xt;Wfh和Wfx组成遗忘门的权重矩阵Wf,bf为偏置顶,σ为激活函数.
(2)输入门:当前输入Xt保存到ct的决定,计算公式如式(2):
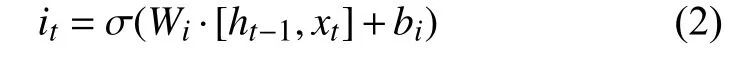
式中,Wi为 权重矩阵,bi是偏置顶.
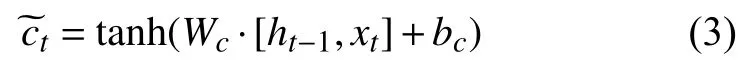
当前时刻单元状态ct,如式(4):

式中,ct-1表 示前一个的单元状态,ft为遗忘门.符号.表示按元素乘.
(3)输出门:计算如式(5):
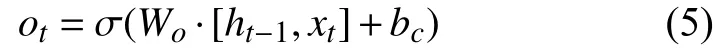
输入门和单元状态确定了长短时记忆神经网络的输出,如式(6):

神经网络可以根据文本中词的分布式表示自动提取特征,字向量的BiLSTM-CRF 模型,在BiLSTM 输出预测曾后,由CRF 层利用上下文已经预测的标签,找到全局最优的标注序列,实验对比分析见文第四部分.
2.1.3 CRF
CRF[13]用来分割和标记序列数据,根据输入的观察序列来预测对应的状态序列,同时考虑输入的当前状态特征和各个标签类别转移特征,被广泛应用于NER 的问题中.CRF 应用到NER 的问题中主要是根据BiLSTM 模型的预测输出序列求出使得目标函数最优化的序列.
两个随机变量X和Y,在给定X的条件下,如果每个YV满足未来状态的条件概率与过去状态条件独立[13],如式(7):
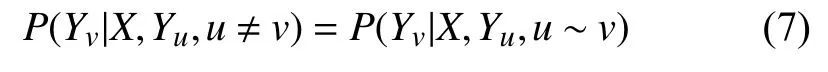
则(X,Y)为一个CRF.常用的一阶链式结构CRF[13]如图3所示.
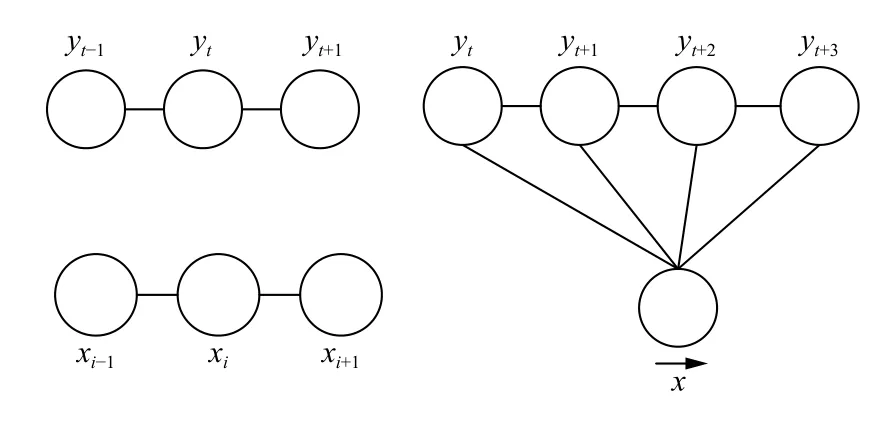
图3 条件随机场一阶链式结构
CRF 应用到NER 中是在给定需要预测的文本序列X={x1,x2,···,xn},根据BERT-BiLSTM 模型的输出预测序列Y={y1,y2,···,yn},通过条件概率P(y|x)进行建模,则有式(8):
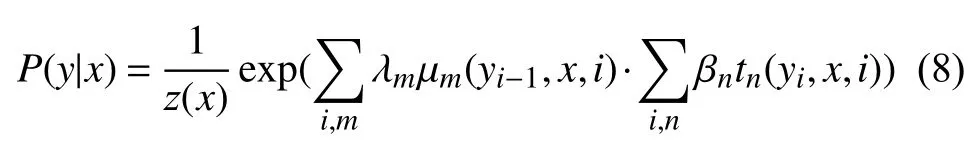
其中,i表示当前节点在x中的索引,m,n表示在当前节点i上的特征函数总个数.tn表示节点特征函数,只和当前位置有关.μm表示局部特征函数,只与当前位置和前一个节点位置有关.βnλm分别表示特征函数tn和 μm对应的权重系数,用于衡量特征函数的信任度.z(x)归一化因子,如式(9):
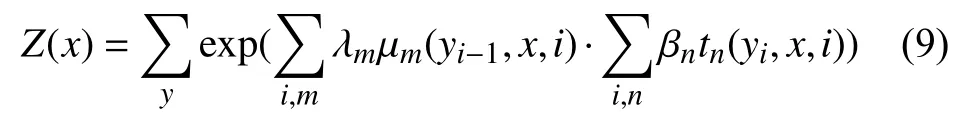
2.2 算法描述

算法1.景点实体提取算法输入:旅游游记文章输出:景点实体集1.get_train_example(data_dir),get_test_example(data_dir),get_labels()/*获取训练数据examples、测试数据predict_examples、标签集labels;2.convert_single_example()/* 分析样本,将字、标签全部转化为id,次数对文本进行按照序列截断,在句子开头结尾加上标识符,结构化存储到InputFeature 对象中,存为一个类*/3.TFRecordWriter(output_file)/*将步骤2 中的数据转化为TF_Record格式*/4.for (ex_index,example)in enumerate (examples)/*遍历所有训练样本重复步骤2 和步骤3*/5.create_model(),model_fn()/*构建模型,初始化参数,使用BERT加载获取每个字对应的embedding,训练基于BERT-BiLSTMCRF 的实体识别模型*/6.filed_based_convert_examples_to_features()/*使用步骤2 中的predict_examples 作为模型的输入,得到实体识别结果result*/7.end for 8.return result
3 数据集
3.1 构建数据库
本文从马蜂窝等互联网旅游网站上通过爬虫技术获取1 万余篇旅游游记文章,将数据解析成TXT 文件,进行数据清洗,通过正则表达式去除无用的网址、特殊的标点符号以及一些符号化的字等信息,按照优先级处理特殊符号,但是保留逗号,句号等重要的标点符号.数据预处理流程如图4所示.
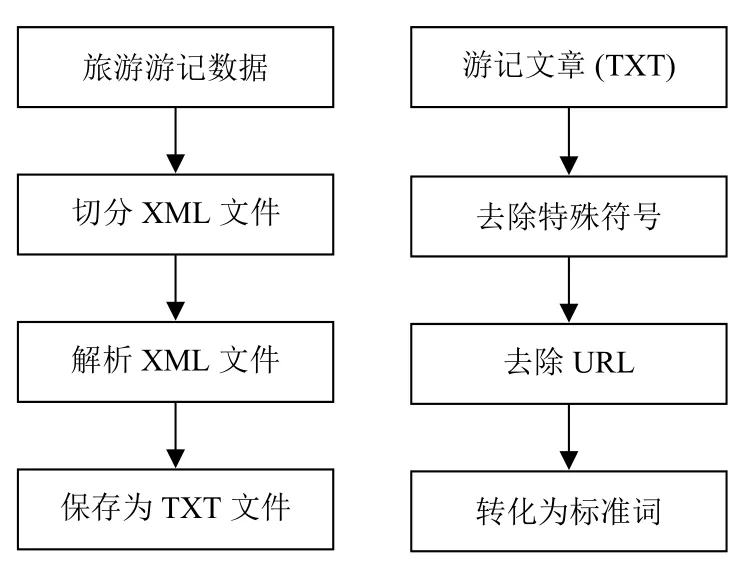
图4 数据清洗预处理
词边界特征能很好地表示边界字符的位置信息,有助于确定实体边界,所以本文按照BIO 标注格式(B 表示景点开始标志,I 表示词的中间部分,O 表示其他非景点的词)进行自动化标注,并建立自己的旅游游记数据库(TDB).标注实例如表1所示,数据分布情况如表2所示.

表1 标注实例

表2 数据分布情况
4 实验过程
4.1 评价指标
本文采用MUC 评测会议上所提出的命名实体识别的评价指标,MUC-2 上[1]提出的NER 的最初评价指标:精确率(Precision,P),召回率[1](Recall,R).本文中主要采用P、R和F值(F值为召回率和精确率的加权调和平均值)作为评价指标计算式(10)~式(12).如表3所示.

表3 评价指标相关解释

当 α =1时,式(12)为最常见的F1 值,计算公式如式(12),当F1 值较高说明实验方法比较有效.
4.2 模型分层测试实验结果
为了验证本文所提出模型的有效性,从TDB 数据库随机抽取19 965 条句子作为训练集和19 690 条句子作为测试集进行实验.本文设置了4 组对比试验,分别与CRF 模型,BiLSTM 模型,BiLSTM+CRF 模型进行分层测试对比,来验证每个模块的重要性.以下实验训练数据和测试数据均为同一数据集.实验对比分析如表4所示.
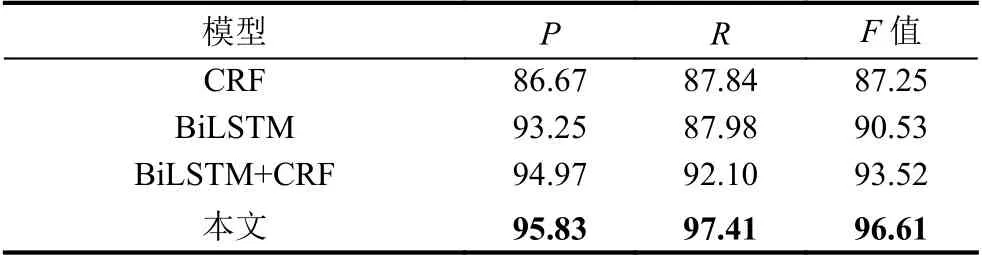
表4 模型验证实验分析(%)
由表4可知,本文所提出的方法P值,R值,F值在相对于其他3 组对比实验中效果最好的,P值,R值,F1 值上分别提升了0.86%,5.31%,3.09%.
(1)单层BiLSTM 模型
观察实验测试数据可知,由于CRF 能够充分考虑标注序列的顺序性,得到全局最优标注序列,所以缺少CRF 层会将一个完整实体拆分(如“故宫博物院”)拆分成“故宫”“博物院”两个实体,而BiLSTM虽说能够考虑上下文信息,但是其输出序列只根据当前词输出得分最大值,容易将完整实体细分.所以对于BiLSTM、BiLSTM+CRF 两种方法而言,后者识别效果较好.
(2)单层CRF 模型
由于CRF 只是传统的机器学习方法,过于依赖人工构建的特征模板,缺乏深度学习方法中上下文信息的特征,而景点实体的识别对上下文语义理解依赖较大,所以BiLSTM+CRF 方法相比较而言,在P值上比CRF 提高了8.3%,R值提高了9.57%.
(3)双层BiLSTM+CRF 层
去除BERT 模型时,由于在文本特征提取的时候不能解决同一个单词不同语境下的特征表示问题,针对一词多义问题不能得到很好的解决,比如“北京海洋馆”中的“海洋”在不同语境下可以指人名也可以指景点名,对于此类问题不能得到解决,导致准确率,召回率等下降.
(4)BERT+BiLSTM+CRF 模型
结合三层的模型,可以通过BiLSTM 获取上下文有效信息特征,可以解决特征表示的一词多义问题,结合BiLSTM+CRF 的优势,识别效率相对较高.
4.3 相关工作对比分析
经调研发现,目前对旅游领域内景点识别的方法最好的方法为薛征山[9]和郭剑毅[10]两人所提出的,为验证本文所提出方法的应用性,从所构建的TDB 数据库中随机抽取19 965 个句子作为训练集,和19 690 个句子作为测试集进行实验设计了3 组实验对比分析,对旅游领域内的游记文章进行景点实体识别,并与以往研究者薛征山[9]提出的基于HMM 的中文旅游景点识别方法与郭剑毅[10]所提出的基于层叠条件随机场方法进行对比分析;使用3.3 节中的评价指标得到实验结果如表5.
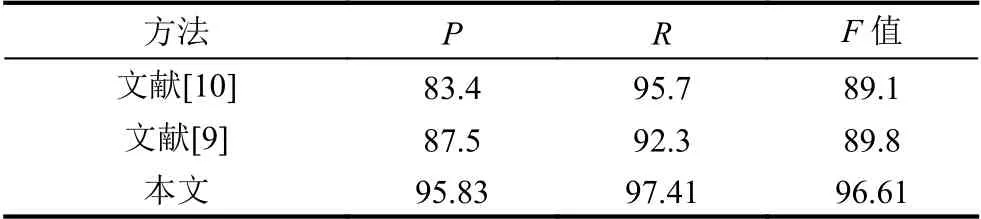
表5 景点识别验证结果(%)
观察实验结果可知,本文所提出的基于深度学习方法比机器学习方法在识别效率上有大幅度的提升,主要原因为深度学习能够学习文本上下文语义信息,而本文在此基础上解决了文本特征表示时的一词多义问题,所以该模型在旅游领域内景点识别相对以往研究者效率有一定提升,其中P值和F值相对于薛征山[9]分别提高了8.33%和6.81%,R值相对于郭剑毅[10]提高了1.71%.
5 结论
本文研究设计了一种融合新的语言模型BERT 的BiLSTM+CRF 景点实体识别方法.利用BERT 语言模型能够解决在文本特征表示的一词多义问题,结合BiLSTM 深度学习方法充分学习上下文信息的特点以及CRF 机器学习方法提取全局最优标注序列,得到景点实体.在实验中进行了验证,P值,R值和F值均高达95%以上,且P,R,F值相比以往研究者所提出的方法分别提高了8.33%,1.71%,6.81%.解决了旅游景点实体识别效率一般的问题,将为解决从旅游游记文本中自动提取旅游线路的问题提供了技术支撑.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
计算机系统应用(2021年11期)2022-01-06
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年5期)2019-03-21
意林·全彩Color(2018年7期)2018-08-13
21世纪商业评论(2018年3期)2018-03-02
海外星云(2016年7期)2016-12-01
Coco薇(2015年11期)2015-11-09
股市动态分析(2015年12期)2015-09-10
