
基于改进CNN的宫颈细胞自动分类算法①
2020-06-20 07:32孙星星户媛姣
计算机系统应用 2020年6期
李 伟,孙星星,户媛姣
(长安大学 信息工程学院,西安 710064)
在人工智能技术日趋成熟的今天,人们将人工智能技术越来越多的应用在各个领域.AI+医疗是当下最火热的人工智能应用场景之一,并且AI 在乳腺癌,糖尿病等预防和治疗方面,创造了诸多突破和成就.宫颈癌发病率高,且病变周期长,早期发现治疗效果好[1,2],目前临床检测仍为人工筛选,耗时,昂贵且准确率低[3].前期筛查是对癌变进行预防和控制的关键途径[4,5].我国宫颈癌早期普查工作量十分繁重,然而病理医生数量却严重不足.因此,采用AI 技术进行宫颈细胞病理辅助诊断在癌前病变诊断中具有重要意义[6].
2009年,Pan SJ 等[7]提出了一种元启发式算法进行宫颈细胞分类,将遗传算法与KNN 相结合,从宫颈细胞图像中构建了20 个特征,使用遗传算法进行最优特征子集的选取,使KNN 算法进行分类,并证明了有效性.2014年,Chankong 等[8]提出一种宫颈癌细胞自动分割和分类的方法,利用FCM 聚类技术将单细胞图像分割为细胞核,细胞质,并进行特征提取,利用人工神经网络进行分类,并与其他分类器结果进行比较,证明了人工神经网络的分类效果与其他分类器相比,精度较高.2015年,Kaaviya 等[9]提出了一种新的分类方法对宫颈细胞进行分类.为了提高宫颈细胞分类结果,采用集成方法,集成了3 个分类器的决策,并使用五折交叉验证进行评估.
2010年,暨南大学的范金坪[10]提出基于矢量量化的C-V 模型进行彩色宫颈图像分割,利用遗传算法进行特征选择,BP 神经网络算法进行原始特征子集以及最优特征子集分类,验证特征选择的有效性.2018年,四川大学的缪欣等[11]提出了基于神经网络集成模型的宫颈细胞分类算法,集成神经网络相对于单个神经网络误识别率明显下降.2018年,胡卉等[12]提出了基于卷积神经网络对宫颈细胞进行分类.验证了卷积神经网络用于宫颈细胞分类的可行性.
基于以往研究学者对宫颈细胞识别方法的研究,可以总结出传统的算法都是先经过细胞分割,其次从分割后的图像中人工提取细胞图像的特征,然后设计算法进行特征降维等操作,最后选取合适的分类器进行识别[13-15].此类方法通常要求在分割阶段有较高的分割准确率,否则会对后续的特征提取产生影响,其次选择特征提取需要人工来决定,这就使得研究人员首先具备一定的病理知识,尽管如此,人工选取的特征也不一定具有代表性,这就导致识别效果不好.基于此,本文因此采用深度学习算法中的DCNN 来进行特征提取[16],以及细胞识别分类的研究[17,18].DCNN 将卷积计算同BP 神经网络相结合的神经网络,具有特征自动特取以及分类识别的功能[19].卷积的引入使其能够感知图像局部细节[20,21],提取数据的局部特征,其权值共享的特性减少了网络参数运算量[22],且无需考虑图像中特征出现的位置,因此,其在图像识别领域具有显著的优势[23].基于此,本文将采用深度卷积神经网络模型进行宫颈细胞图像识别,以解决特征提取不完善的问题,从而提高宫颈细胞图像识别的准确率以及效率,实现智能化识别.
1 研究方法
针对宫颈细胞自动分类的研究过程,主要分为图像集的预处理,模型的选取,模型的训练以及模型的测试.在图像集的预处理阶段,对图像进行灰度化,去噪增强等操作[24],接着对处理后的图强提取ROI 区域,并根据神经网络的输入要求统一尺寸.
在模型选取阶段,本文采用深度卷积神经网络对宫颈图像进行分类,卷积神经网络是一种具有不同功能网络层的深度学习算法,其分为输入层,特征提取层,以及分类结果输出层[25].
输入层一般是带有分类标签的图像数据,需要根据不同网络的要求来统一尺寸[26].在这一层一般是要对输入的图像数据进行预处理,使之适应网络计算要求.常用的预处理分为:去均值,归一化,PCA 降维.
特征提取层包含卷积层,激励层,池化层.卷积层采用类似滑动滤波器一样的滑动窗口对图像进行特征提取,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征,且局部权重共享[27].权值共享减少了网络参数运算量,降低了模型的复杂性,且无需考虑图像中特征出现的位置.激励层的主要作用是将卷积层的输出结果做一个非线性的映射,一般采用ReLU 函数作为激励层的激活函数,它具有收敛速度快,且梯度计算简单的特点.池化层处于两个相连的卷积层中间,用于压缩传输数据与参数,减小分类过程中出现过拟合[28].池化的方法一般分为平均池化和最大池化,本文采用最大池化的方法进行压缩传输图像.池化层在卷积神经网络中的作用是用来识别经过位移,缩放变换以及其他形式扭曲且不发生性质变化的图像[29].
分类结果输出层即特征映射层,由图像特征与图像类别变迁的映射关系,本文采用Sigmoid 函数作为输出层的激活函数.Sigmoid 函数的输出范围在(0,1)之间,具有指数函数的平滑性,在分类输出结果中,越接近于1,说明该类的可能性越大.Sigmoid 函数使得特征映射具有位移不变性[30].
本文选取VGG16 网络作为基础模型来进行改进,VGG 卷积神经网络是2014年被提出的,其在图像分类以及图像检测中表现很好,并在2014年ILSVRC 比赛中取得了很好的成绩,其准确率达到了92.3%.在VGG模型中,VGG-16 表现良好,且应用较多,它是一个具有16 层深度的模型,模型结构如图1所示.
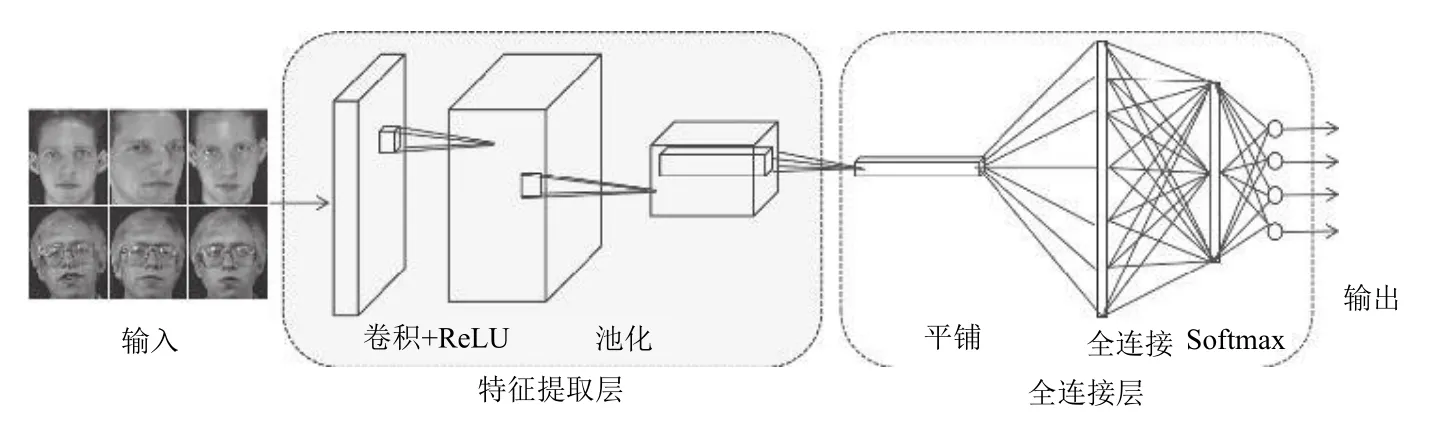
图1 CNN 模型图
在模型训练阶段,由于宫颈细胞图像的数量较少,为了提高分类准确率,本文采用迁移学习的方法对网络进行预训练,采用ImageNet 数据集训练模型,将得到的模型参数作为宫颈细胞分类模型的初始化参数,由于ImageNet 是一个具有1000 类的数据集,而宫颈细胞的分类只有7 类,所以将原始模型的特征映射层Softmax 层进行修改,并对全连接层参数进行调整,以加快收敛速度,提高准确率.模型如图2所示.
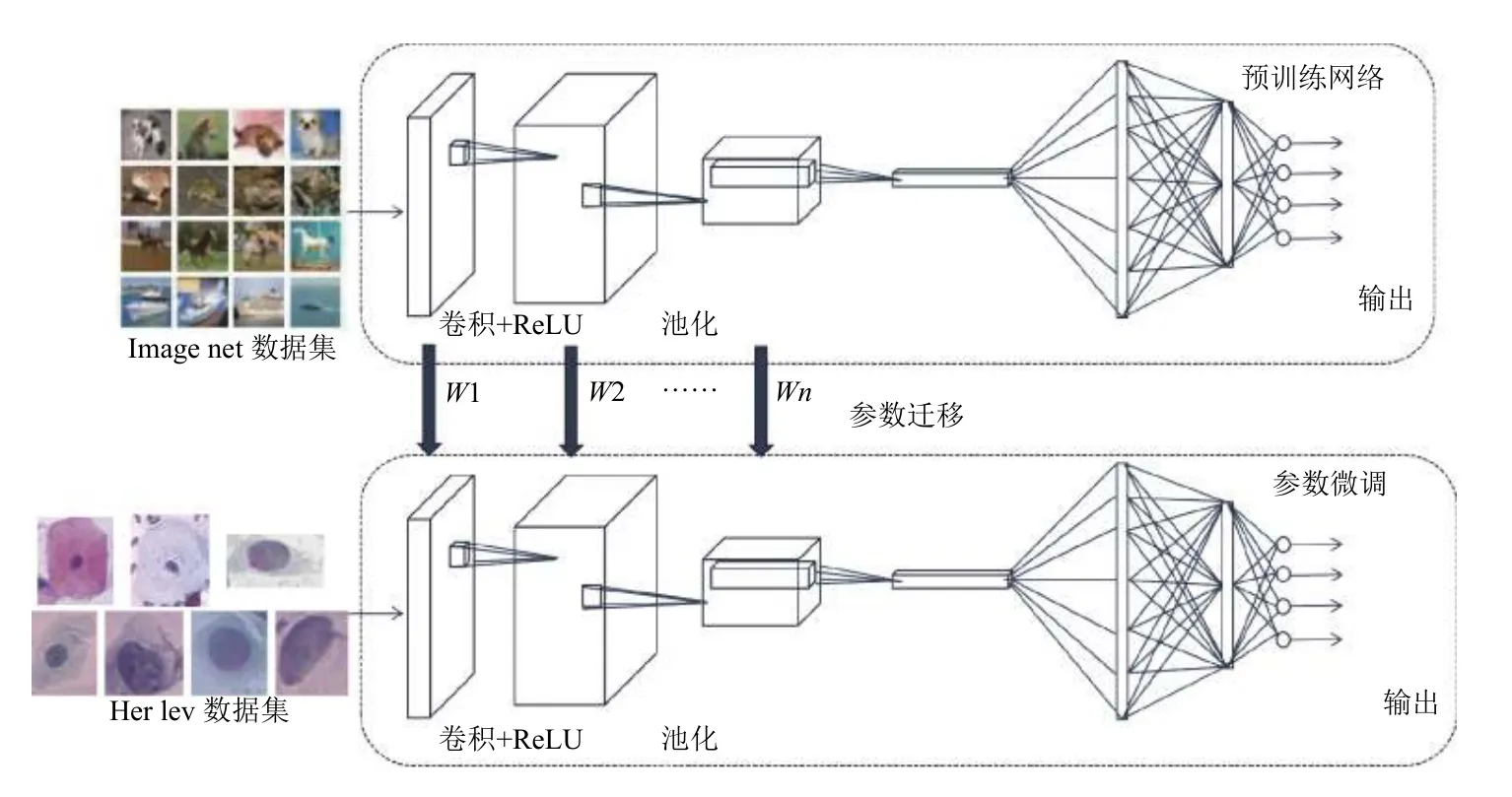
图2 网络训练过程
在模型测试阶段,对于训练好的模型,将测试集输入模型,得出分类准确率.
2 实验过程
2.1 数据集介绍
本文采用的宫颈细胞数据集为公开的HerLev 图像集,该图像集是通过数码相机和显微镜在赫列夫大学医院制作的.图像分辨率是0.201 μm/像素.Herlev 的数据集共包含917 幅图像,每幅图像包含一个子宫颈细胞,分为7 类,这7 个类属于两大类别:类1~3 为正常,类4~7 为异常类,每一类的数据情况如表1所示.其中每个类别的确定由两名细胞技术人员和一名医生共同诊断,这样以最大限度地提高诊断的准确性,避免个人主观带来的误差.
图3为宫颈细胞数据集中部分细胞的例子,图3(a)-图3(g)为正常细胞到异常细胞,可以看出,异常细胞相比较正常细胞细胞核明显增大,且颜色变深,核质比明显变大可见,但是相邻种类的细胞变化较小,比如图3(e)与图3(f)外观相似,这对于CNN 来说,要想分辨两类,是有相当大的难度.
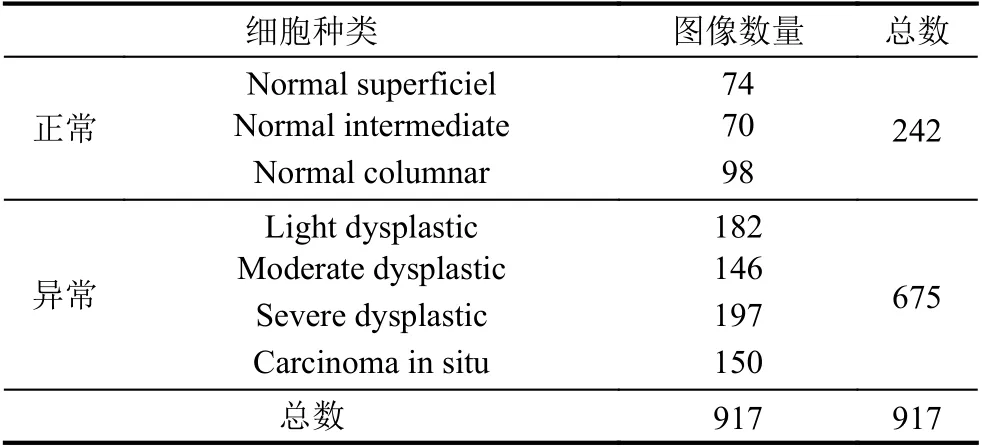
表1 HerLev 数据集介绍
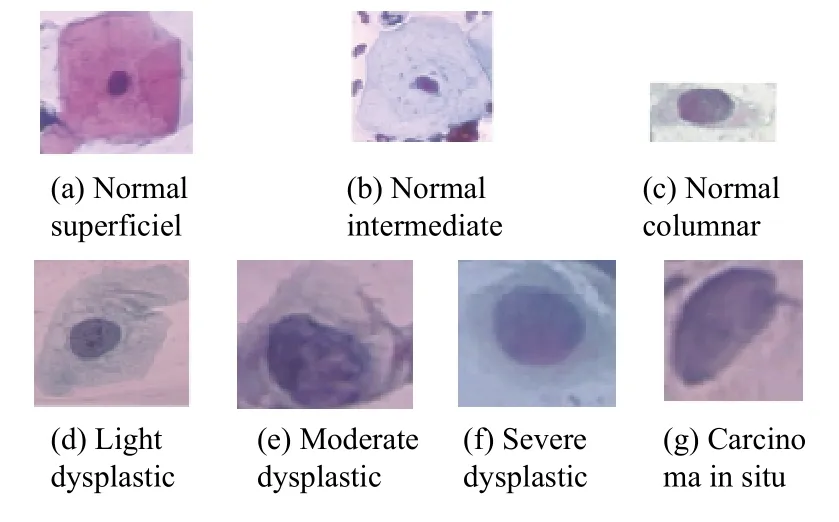
图3 宫颈细胞图像
2.2 数据预处理
(1)提取ROI 区域
由于网络需要统一大小的图片输入尺寸,而HerLev 数据中的尺寸大小不一,且长宽比差均很大.若依照传统方法改变图像尺寸,会导致图像内部特征改变,从而影响分类效果且分类模型不具有普适性,因此本文采取提取ROI 区域的方式进行适应网络尺寸.宫颈细胞不同类别的差距主要来自于细胞核的差异,医生在判别细胞异常与否也是通过对细胞核的分析来确定,因此本文从原始图像中裁剪出固定大小的细胞核区域作为网络输入图像.具体做法为以细胞核质心为中心,裁剪出128×128 大小的图像,如图4所示.
(2)图像集扩充
由于网络训练需要大量的数据集,且每一类的样本量要均衡.宫颈数据集共917 张,分为7 类,最少的一类有70 张,最多的一类有198 张.需要扩充数据集的量,并且解决不同类别样本量不均衡的问题.由于宫颈细胞具有旋转不变性,本文通过平移旋转的方式对数据集进行扩充,将正常细胞数据量扩充为之前的20 倍,异常细胞扩充为之前的10 倍,并按照网络的输入要求进行边缘填充.扩充操作如图5所示.

图4 ROI 区域选取
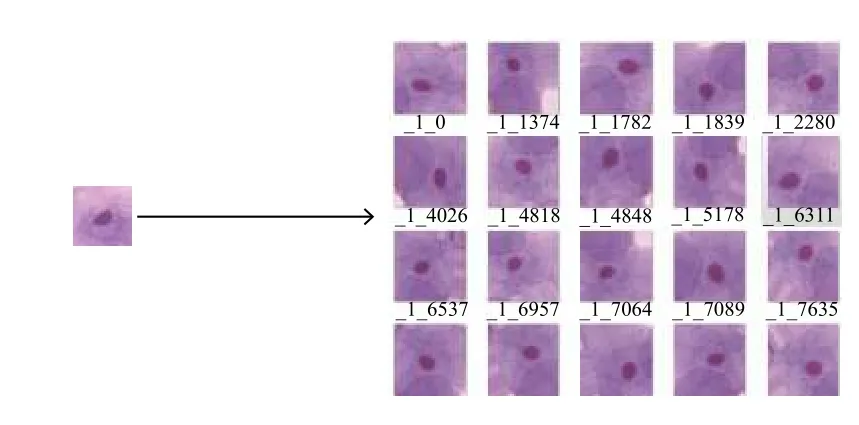
图5 图像集扩充
2.3 网络设计
由于宫颈细胞数据量较小,直接训练网络花费时间较长且效果不理想,本文采用迁移学习的方法,使用ImageNet 进行网络预训练.迁移学习指的是采用现有的或者已有的知识去解释或者学习另一相关领域的知识,其目标是完成知识在相关领域之间的迁移.迁移学习基本原理如图6所示.
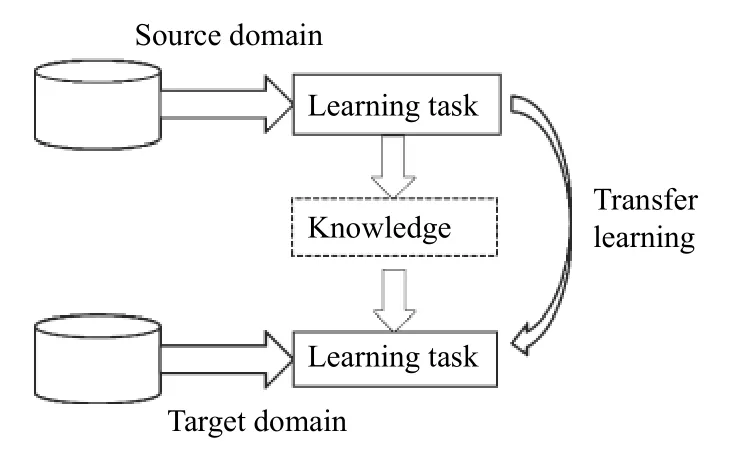
图6 迁移学习过程
对于卷积神经网络而言,一般在如下情况下益采用迁移学习的方法.(1)新的数据集较小且与旧数据集差距大;(2)新数据集较大且与旧数据集相似.本文情况符合第一种,即宫颈细胞的数据集较小,因此在网络的训练过程中,可以先利用其他大型数据集对网络进行预训练,以获得网络的初始化参数.迁移学习使用预训练深度神经网络作为学习新任务的起点,由之前的随机初始化变为预训练网络参数作为初始化,只需要对网络进行较少的训练,或者只用微调剩余网络层,这样很大程度上降低了网络训练的时长.因此,迁移学习不仅增强了网络对小数据集的学习能力,还可以加快网络的收敛速度.
由于本文使用的预训练网络模型为VGG16 模型,所以改进的网络参数大部分与VGG16 网络参数一致,VGG16 由13 个卷积层,5 个池化层,2 个全连接层以及1 个Softmax 层.本文设计的网络卷积层同VGG16网络卷积层相同,卷积层参数如表2所示.

表2 VGG16 卷积层参数
由于越靠近最终的Softmax 分类层,网络的特征跟原始数据集越相关,所以在迁移网络参数的时候,只复用卷积层的参数,并根据具体应用数据集进行更改全连接层以及Softmax 层参数.
在VGG16 网络中全连接层神经元个数分别为4096-4096-1000,全连接层FC1 的权重参数量为7×7×512×4096=102 760 448,FC2 的权重参数量为4096×4096=16 777 216,Softmax 层的权重参数量为4096×1000=4096 000.参数量以及相应的计算量显然是非常大的,这是因为ImageNet 数据集中总共有14 197 122幅图像,总共分为21 841 个类别.相比较宫颈细胞分类是一个非常大的数据集,所以全连接层的神经元个数相对较多,如果采用原始VGG16 的全连接层神经元个数来实现宫颈细胞的分类,参数量过大,容易造成过拟合,只对训练集产生较好的分类效果,因此为了适应本文的应用,需要对网络进行修改,本文在相同学习率,相同迭代次数的情况下,改变全连接层神经元个数,分别取2048,1024,512,256 作为全连接层参数值.通过对比测试集准确率来选择最优的全连接层参数设置.结果如图7所示.
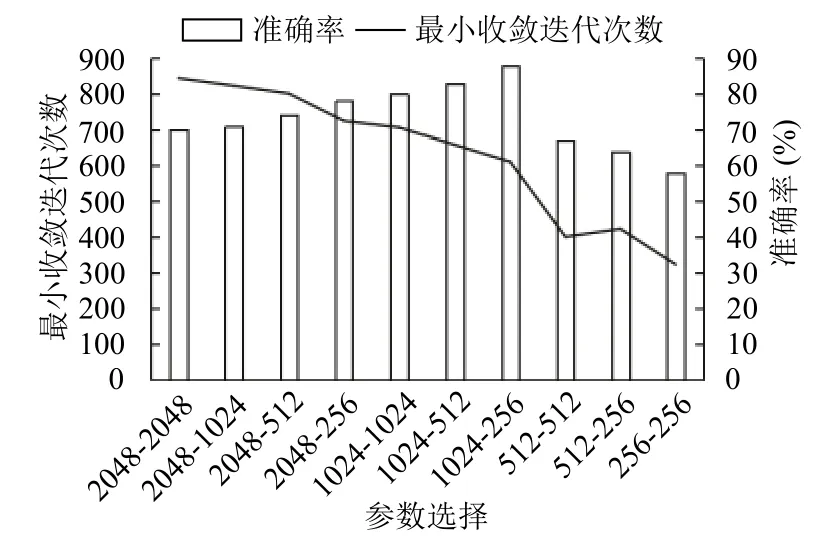
图7 全连接层参数选择
经过实验发现,减少全连接层神经元个数不仅加快了网络的收敛速度,并且在一定程度上提高了宫颈细胞的分类准确率.本文通过实验对比,发现全连接层参数为1024-256 时,分类准确率最高.因此,将VGG16的全连接层神经元个数改为1024-256.
Softmax 层的参数取决于数据集的类别数,原始VGG16 网络是用来处理1000 类的数据,而本文主要用于宫颈细胞二分类和七分类,故进行二分类时将Softmax层神经元个数改为2,进行七分类时将Softmax 层改为7.
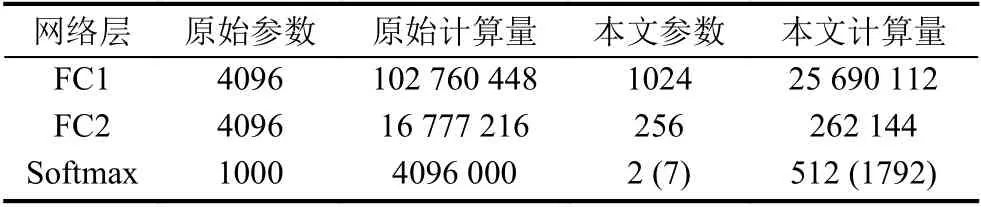
表3 参数计算量对比
2.4 网络优化
为了提高模型的泛化能力,加快收敛速度,本文在已有的模型损失函数中加入正则化,公式如下:
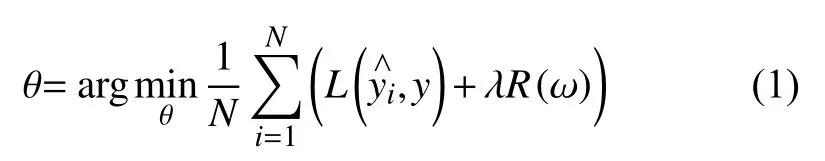
式中,R(ω)为正则化项,w为模型系数组成的向量,一般有L1 正则化和L2 正则化.
(1)L1 正则化
L1 正则化是指正则化项为模型系数w的L1 范数,如式(2)所示.由于正则项在零点不可微,因此权重因子趋近于零,这就使一些对分类结果贡献较低的特征所对应的系数为0.所以使用L1 正则化可以对模型进行特征选择.

(2)L2 正则化
L2 正则化是指正则化项为模型系数w的L2 范数,如式(3)所示.L2 正则化中模型系数为二次方,因此与L1 不同,L2 使系数的取值趋于平滑.由于引入L2 正则化使的loss 最小时,模型参数也是最小的,从而降低了模型的复杂度,降低了模型出现过拟合的可能性.
1.2.2 细胞形态学检查 抽取骨髓液制涂片,快速干燥后进行瑞氏染色,根据需要进行特殊细胞化学染色,包括过氧化物酶、碱性磷酸酶、特异性酯酶、非特异性酯酶及糖原染色等,进行形态学分型。

2.5 分类评价
对于卷积神经网络对宫颈细胞分类的有效性进行评价是非常有必要的,在分类任务中常用的评价指标有以下几项:准确率(Accuracy,Acc),精确率(Precision,P),召回率(Recall,R)和F1-score.以TP,FN,FP,TN分别表示分类过程中的值,以二分类为例,具体如表4所示.

表4 混淆矩阵
准确率的定义对于给定的测试数据集,分类器正确分类的样本数与总样本数N总之比,即测试集中分类正确的宫颈细胞个数占总测试集的百分比.
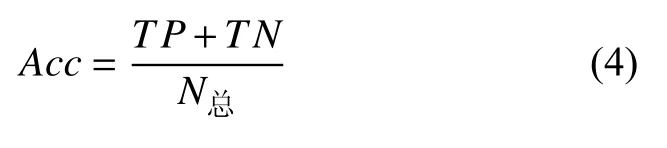
精确率指的是正类分类正确的个数与分类器检索到的正类总数之比.该值体现了分类器是否分类正确.

召回率指的是正类分类正确的个数与实际正类别总数之比.该值体现了分类器分类是否完全,所以召回率也叫做查全率.

F1-score指的是精确值和召回率的调和均值,一般情况下,要求精确率和召回率都要比较高,但是实际情况中,精确率高的时候,召回率就低,F1 值就是评价精确率和召回率的调和参数
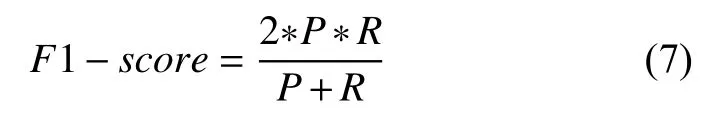
在医学领域,准确率是诊断疾病的重要评价指标,但是相比较于准确率,误识别率更是所要关注的,即将异常细胞分类为正常细胞的概率.
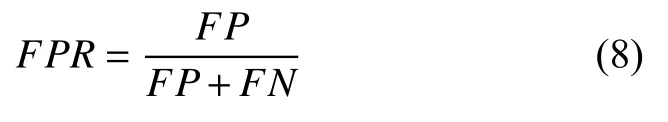
上述介绍了二分类过程中各个评价指标值的计算方法,在多分类中采用混淆矩阵的表示方法来计算各个指标的值.可以将多分类的计算看作是当前类和其他类,从而转换成二分类进行计算.多分类的准确率如下:

3 结果分析
本文通过对HerLev 数据集的预处理将图像集扩充至11 590 张,将扩充后的数据集以6:2:2 的比列划分为训练集,验证集,测试集.其中训练集为6954 张,验证集和测试集分别为2318.采用VGG-16 卷积神经网络卷积层对宫颈图像进行特征提取,采用全连接层进行宫颈图像分类.训练过程中,设置mini-batch 为32,训练集共6954 张,故一个epoch 的迭代次数iteration值至少为218 次,epoch 值设置为1000.学习率Lr 初始值为0.0001,然后随着迭代次数的增加,减小学习率.学习率按照如下公式进行递减:

式中,lr0为学习率初始值,Lr为不同epoch 对应的学习率值.
对宫颈细胞图像分别进行七分类和二分类,二分类结果如表5所示.
由表5可以看出:二分类的准确率较高,且正常细胞与异常细胞的准确率大致相同,召回率异常细胞比正常细胞更高,这说明网络对异常细胞的分类更为准确,即有较少的异常案例被分类为正常细胞.这也为神经网络能够进行细胞检测提供了依据,但是在临床上,对异常细胞的检测要更高,异常细胞的召回率要尽量接近1,所以卷积神经网络识别宫颈细胞目前只能作为辅助决策手段,不能完全代替医生.宫颈细胞的二分类混淆矩阵如图8所示.
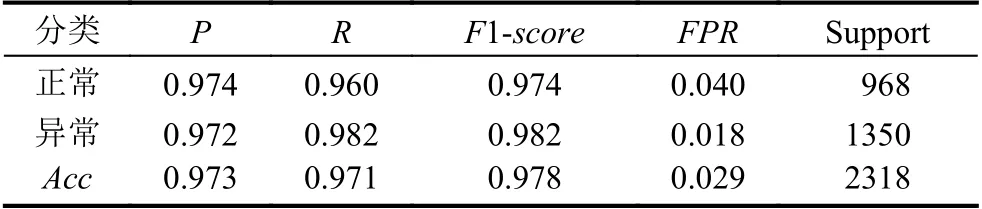
表5 宫颈细胞二分类结果
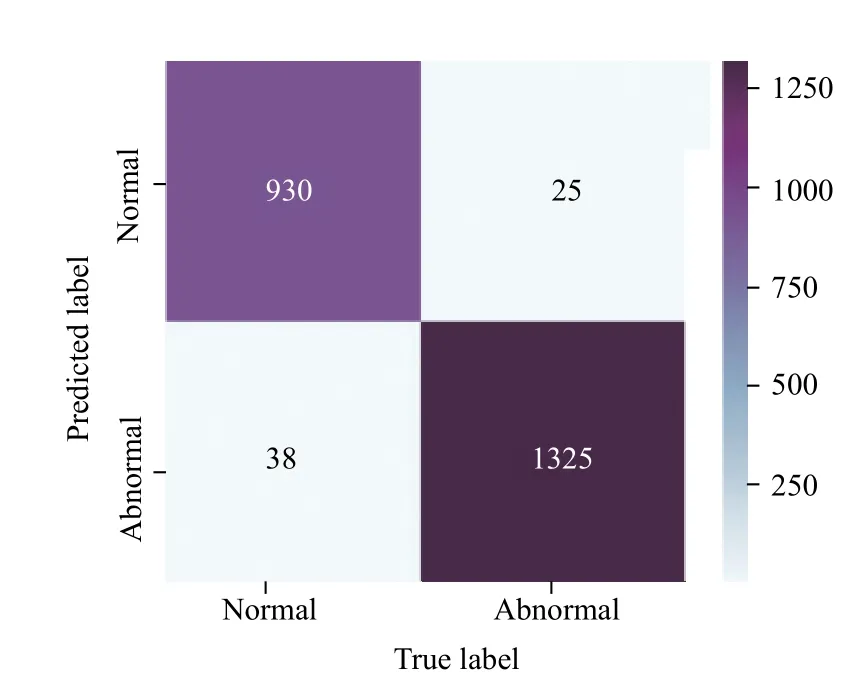
图8 二分类混淆矩阵
由图8可以看出:正常细胞中有38 张误分类为异常细胞,异常细胞中有25 张图片被分类为正常细胞,相对于测试集图片的数量,分类错误的图像是很少的,尤其是异常细胞的图像,这也说明卷积神经网络在宫颈细胞分类中的优越性,但是仍需医生进行二次筛选,以达到误识别率最低,所以需要对正常宫颈细胞以及异常宫颈细胞进行更细致的划分,以达到最佳辅助决策的效果.
宫颈细胞八分类的混淆矩阵结果如图9所示,通过对混淆矩阵计算得到七分类各个评价指标的结果,如表6所示.
通过图9以及表6可以看出:前两类的分类准确率相对其他类较高,分别为0.966 和0.964 且未将这两类正常细胞错误分类为异常细胞,两类细胞的召回率分别为0.966 和0.964,也是这7 类细胞中最高的.而第4,5,6 类异常细胞的分类准确率较低,分别为0.834,0.836 和0.798,但是,错误分类多存在于相邻两类之间,因此可以可以人工对第4 类细胞进行筛选从而将异常细胞的误判率降到最低.
将本文卷积神经网络分类的方法,同其他人工提取数据特征再通过设计分类器分类的算法相比较,得出的结果如表7所示.

图9 七分类混淆矩阵
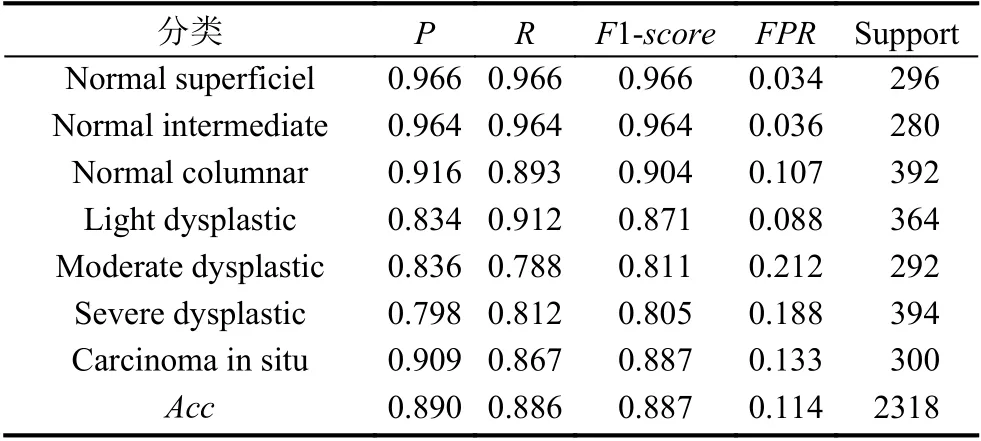
表6 宫颈细胞七分类结果

表7 不同方法分类对比结果
从对比结果可以看出,本文方法在细胞二分类的准确率相对较高,高出目前最好的提升树分类器算法XGBoost,AdaBoost,Bagging 等,这些算法均为目前机器学习领域最为常用的分类算法,在数据的分类表现优异.这是因为采用数据特征对细胞进行分类,其结果会受图像分割准确率的影响,且分类特征为人工选取,不具有代表性,而本文通过卷积神经网络自动提取细胞图像的分类特征,不受人工主观影响,所以本文方法在二分类的准确率相对较高.在七分类的准确率对比结果中可以看出:本文方法的提升较大,这是因为原始数据集中每个类别的数据量不均衡,在数据分类中解决这类数据偏斜的问题,往往需要对数据进行过采样,欠采样或者调整预测概率的阈值,这样模型变得复杂,且不易得到稳定的分类模型.本文在数据集预处理阶段,基于细胞图像翻转不变性,对图像进行平移翻转操作扩充了数据集,解决了样本量不平衡的问题,但是召回率仍相对较低,这也是之后仍需改进的地方.
4 结论与展望
本文通过卷积神经网络对宫颈细胞图像进行自动分类,在预处理阶段通过图像裁剪,图像集扩充解决了样本分布不平衡的问题,并使用迁移学习初始化网络参数,加快收敛,最后对网络进行优化,加入L1 正则化进行特征的筛选,简化网络,并加入L2 正则化来避免过拟合.实验结果表明:使用卷积神经网络对细胞图像进行分类可以得到较好的准确率,分类准确率相比较人工提取特征分类器效果较好,且分类结果不受分割图像准确率的影响,模型分类效率高,在一定程度上帮助医生进行医疗决策,减少用人成本,提高诊断准确率.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中国典型病例大全(2022年7期)2022-04-22
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
家庭百事通·健康一点通(2016年7期)2016-08-04
