
基于CNN的农作物病虫害图像识别模型①
2020-06-20 07:31史冰莹李佳琦
计算机系统应用 2020年6期
史冰莹,李佳琦,张 磊,李 健
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
3(生态环境部 南京环境科学研究所,南京 210042)
中国的耕地面积为1432 960 平方公里,排世界第3 位,然而同时中国也是世界上人口最多的国家.截止2018年,中国用全球7%的耕地养活了近20%的人口.作为一个人口大国,保障粮食不仅关系到人民福祉也同时会影响社会安定.据中国统计年鉴,2016年全国农业生产总值达5.93 万亿元,占GDP 的8.0%,而由农业病虫害等灾害造成的直接损失达0.503 万亿元,占农业生产总值的8.48%,可见农作物病虫害对农业影响之巨大.同时在农业生产中,大量农药的使用加剧了对环境的污染.因此对农作物的病虫害进行准确的识别并推荐合适的防治措施,不仅对于农业生产意义重大,对于改善整个社会经济环境也有帮助.随着计算机技术的飞速发展,越来越多学者尝试将图像识别算法运用到病虫害识别过程中.传统的图像识别技术在对图像进行预处理后提取图像的颜色纹理等的特征,基于这些提取的特征值进行线性建模.然而这种传统的图像识别方法,局限性大,对非线性数据的识别成功率很低,因而在农作物病害检测中,其模型的识别成功率非常不理想.随着大数据、机器学习等概念的出现,支持向量机、朴素贝叶斯、BP 神经网络等经典机器学习算法也被用于病虫害识别分类中.然而传统的机器学习算法更适用于小样本的研究实验中,在农业病虫害图像识别的复杂场景和大量数据的情况下,基于卷积神经网络的深度学习模型往往能取得更优的效果.
深度学习的快速发展使图像分类任务的精度得到了很大提升,而卷积神经网络正是深度学习中代表性的算法,具有很强的泛化性,不需要特意设计分类器.因此本文基于卷积神经神经网络的方法构建农作物病虫害图像识别模型.然而由于农作物病虫害图像数据较为稀缺,且对于不同的病虫害图像采集难度不同,这导致了我们的训练样本分布不平衡,如果不加以处理则会影响到模型识别的准确度.因此本文采用迁移学习的方法,利用在大型数据集ImageNet 预训练后的模型进行建模.并且采用数据增强的方法增大样本量,缓和数据不平衡问题同时可以提高模型的泛化性能.同时改进损失函数,采用焦点损失函数(facal loss)[1]代替传统的交叉熵损失函数来解决数据不平衡问题.实验表明,基于Inception-V3 网络以及Resnet 网络建立的病虫害图像识别模型准确率高,并且改进损失函数后病虫害图像识别模型准确度进一步提升,损失明显降低.
1 相关研究
国外的农作物图像病虫害识别的研究大约从20世纪80年代开始.Sasaki 等[2]采用贝叶斯决策的方法,通过光谱反射率之间的区别辨别黄瓜叶片的健康和病斑区域.Vízhányó等[3]提出一种RGB 空间转换方法,通过健康蘑菇和患病蘑菇的颜色点的不同来辨别患病蘑菇.随着机器学习的发展,人们开始尝试将机器学习算法应用于农作物病害图像识别.Sammany 等[4]利用遗传算法改进神经网络,基于改进后的网络建立病虫害识别模型,并对特征向量进行降维,从而提高病虫害识别效率.马来西亚国立大学的Al Bashish 等[5]采用K 均值聚类算法将图像分为4 个簇,分别对每个簇提取其颜色及纹理等特征值后将其输入神经网络进行分类并取得了不错的效果.瑞士洛桑联邦理工学院Mohanty 等[6]利用GoogLeNet 卷积神经网络结构建立病虫害识别模型并取得了不错的效果.
国内的农作物病害图像识别起步较晚,大约从21世纪开始,徐贵力等[7]基于直方图法提取的番茄叶片颜色特征后进行识别,准确率可达70%以上.赵玉霞等[8]采用朴素贝叶斯分类器识别玉米锈病等5 种病害,取得了比较好的效果.田凯[9]基于Fisher 判别法、贝叶斯分类器和支持向量机的方法构建模型识别褐纹病与非褐纹病图像,对比后发现Fisher判别法的平均识别效果最好.李敬[10]基于6 层卷积神经网络建立烟草病害识别模型取得了不错的效果.甘肃农业大学的刘阗宇等[11]采用Faster-RCNN 方法识别葡萄叶片位置,基于卷积神经网络建立模型,该模型对叶片病变识别准确率最高可达75.52%.
通过对上述国内外的相关研究分析,可以了解到大多数研究依然采用传统图像识别的方法与机器学习方法结合从而实现对农作物病害图像的分类,通常要在农作物病害图像的识别之前对病害图像进行预处理、病斑分割和特征提取等几个步骤,并且对于不同的病害图像这个过程往往采用不同的方法实现,没有提出可以针对多种作物不同病害图像处理的方法.与传统图像处理手段相比,深度学习省去了大量预处理的步骤,在缩短了识别时间同时提高了识别准确率以及模型的泛化性能.与传统的建模方法和浅层神经网络模型相比,基于深度卷积神经网络结构的识别模型鲁棒性更强[12],对于外界环境条件要求不高,更适合应用到实际的生产生活中.
2 模型介绍
卷积神经网络(Convolutional Neural Networks,CNN)本质是一个多层感知机,基本组成部分包括输入层、卷积层、激活函数、池化层和全连接层5 部分.局部连接、参数共享是卷积神经网络的两大特点.LeNet-5[13]网络结构是早期卷积神经网络的代表性结构,由Yann LeCun 提出,用于手写数字识别.LenNet-5 共有7 层,包括2 个卷积层、2 个池化层、3 个全连接层,其结构如图1所示.
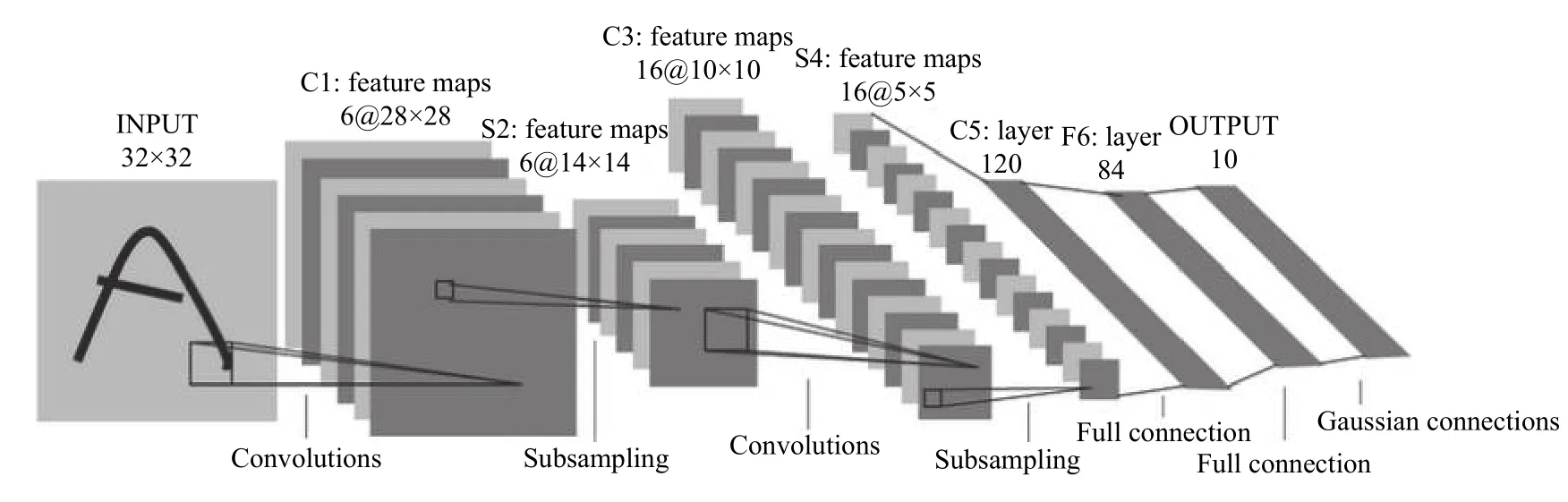
图1 LeNet-5 结构图[13]
随着深度学习的不断发展,卷积神经网络结构也在不断更新,其中Inception 网络以及Resnet 网络是卷积神经网络发展中最具代表性的两类算法.
2.1 Inception-V3 模型
Inception 网络[14]是卷积神经网络发展过程中里的重大进展,在此之前传统的卷积神经网络依靠堆叠卷积层来提高性能,然而随着网络层数的加深会导致过拟合现象的出现并且计算量也大大增加.因此Google在2014年提出了Inception-V1 算法,该算法整合不同尺度的卷积核以及池化层形成Inception 模块,利用1×1 的卷积核进行降维,降低了参数量.该算法在ILSVRC 2014 的比赛中取得分类任务的第一名,相比于之前的AlexNet 网络[15]提高准确率的同时大大减少了参数量.Inception-V3 在Inception-V1 的基础上,用一维的1×7 和7×1 的两个卷积核代替原始的7×7 的卷积核.对卷积核进行非对称分解不仅减少了参数规模,并且因为将1 个卷积核拆分成为2 个卷积核这使得网络也可以得到进一步加深.
典型的Inception 模块如图2所示.
2.2 Resnet 模型
随着网络层数的不断增加,网络结构越来越深,结构加深导致的梯度消失问题会使模型的学习愈加艰难.因为当梯度被反向传播到前面时重复相乘会导致梯度变得无限小,此时卷积神经网络的性能不再提升甚至开始下降.针对这个问题,Resnet 算法[16]引入了全等映射的思想,引入了残差学习单元.其基本思想是假定某段神经网络的输入是x,期望输出是H(x),假设我们如果把输入x作为初始输出结果,那么我们需要学习的目标就变成了H(x)-x,即我们不再学习完整的输出H(x)而是学习残差H(x)-x.如图3所示,这就是一个Resnet 的残差学习单元(residual unit).

图2 Inception 模块结构图[14]
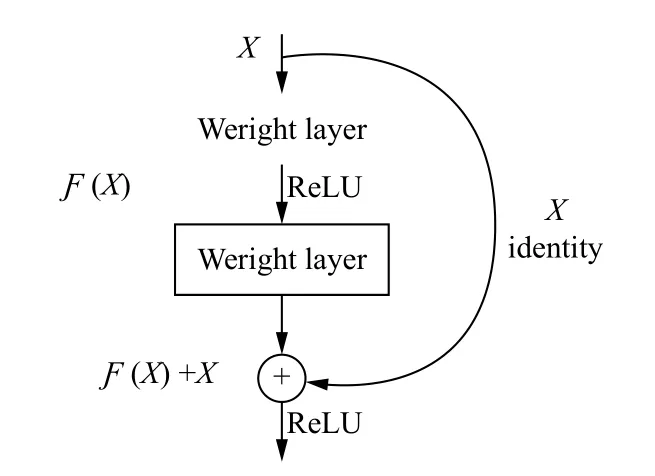
图3 残差结构单元[16]
残差单元有效地解决了在深度网络中的退化问题,并且在不额外增加网络参数和计算量的基础上提升了模型速度和准确度.
Inception-V3 和Resnet 作为近年卷积神经网络的具有代表意义的经典模型,在图像分类领域取得了优异的成绩.因此本文分别以Inception-V3 和Resnet 网络为基础构建农作物病虫害识别模型.
3 数据集介绍
本文数据来自于AI Challenger 比赛,数据集包括10 个物种,27 种病害.按照物种-病害-程度不同共分为61 类.每张图包含一片农作物的叶子,叶子占据图片主要位置.其中训练集验证集分布如图4、图5所示,可以看出训练集与验证集分布相似但不同类别分布差异较大.由于第44 类与45 类在训练数据集中分别只有1 张,在验证集中分别有1 张和0 张,数据严重缺失.因此在后续实验中剔除以下两类数据,最终有59 种数据分类.

图4 训练集数据分布
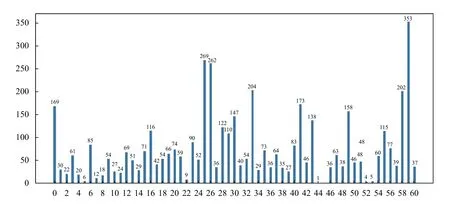
图5 验证集数据分布
数据集包含图片和标注的JSON 文件,JSON 文件中包含每一张图片和对应的分类ID,JSON 文件格式如下所示:

每一个ID 代表一种类型,其对应说明详情如表1所示.
训练集包含31 716 幅农作物病虫害图像,验证集包括4539 张农作物病虫害图片.每张图片包含一片农作物叶片且叶片位于中心主要位置,叶片有不同程度的病变.部分图片展示如图6所示,从左到右依次为苹果健康、苹果黑星病一般、苹果黑星病严重.

表1 部分ID 及其对应说明

图6 部分病虫害图片
4 实验设计
4.1 数据增强
由于数据集本身分布不均,为了增大样本量并且提升模型泛化性能,需要对数据集进行数据增强.数据增强指利用已有的数据进行比如翻转、平移或旋转基于卷积神经网络的农作物病虫害图像识别模型等操作来衍生出更多的数据,这样不仅可以一定程度上缓解数据不平衡问题同时也可以使模型有更好的泛化效果.
数据增强可以分为离线增强和在线增强.离线增强直接对数据集进行处理,常用于数据集较小的时候.而在线增强适用于大型数据集,在模型训练过程中获得batch 数据之后,然后对这个batch 的数据进行增强,如旋转、平移、翻折等相应的变化,该方法相对于离线增强操作更为简洁,且可以使用GPU 优化计算.因此本文在后续工作中将采用在线数据增强的方式.在线增强部分代码如下所示:

在训练过程中获取batch 数据后进行在线增强,具体操作如下:(1)输入尺寸变化为默认值224×224;(2)随机旋转30 度;(3)随机水平翻转;(4)随机垂直翻转;(5)放射变化;(6)转为Tensor 并归一化;(7)标准化.
4.2 优化损失函数
通常在图像分类的时候,我们的损失函数一般为交叉熵损失函数(cross_entropy loss).交叉熵指真实输出(概率)与预测输出(概率)的距离,因此交叉熵的值越小,证明两个概率分布越接近.以二分类为例,二分类交叉熵损失函数公式如下:

其中,y表示真实样本的标签(1 正0 负),正样本是指属于该类别的样本,负样本是指不属于该类别的样本.而y'是经过Sigmoid 激活函数的预测输出(数值在0-1 之间).由此可见当y为正样本即y等于1 时,输出概率越大损失越小.而当y为负样本即y等于0 时,输出概率越小则损失越小.
然而由于在数据集中存在大量简单的负样本,这些样本在迭代过程中产生的损失占据了总损失的大部分,这可能会导致我们偏离正确的优化方向.
为了改善这种情况,He KM 等[16]提出的一种新的损失函数思想,并将其运用到目标检测中,取得了优异的效果,焦点损失函数公式如下:

首先在交叉熵的基础上加上一个因子( 1-y′)γ,用于减少容易分类的样本对于损失的贡献同时增大难以分类的样本对于损失的贡献.例如当γ等于2 时,y真实值等于1,预测值y′为0.95 时,此时(1-0.95)的γ次方就会很小,该样本的损失函数值就变得更小.准确率越高的类衰减的越厉害,这就使得准确率低的困难样本能够占据loss 的大部分,这样模型在训练时就可以更加专注于难以分类的样本.
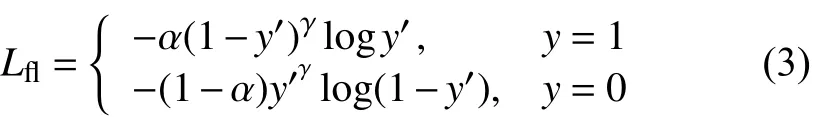
在此基础上,引入平衡因子α,该因子可以用来平衡正负样本本身的数量比例不均即类别不均衡.根据实验表明当α的值取0.25,γ的值取2 时,该组合效果最好.
基于焦点损失函数的思想,将该解决思路用于本文的病虫害识别多分类模型中,用焦点损失函数代替原有的传统交叉熵损失函数(cross_entropy loss).实验证明对损失函数进行优化后的模型准确率得到了进一步提升.
4.3 实验流程
基于上述数据集建立农作物病虫害分类模型,训练集包含31 716 幅农作物病虫害图像,验证集包括4539 张农作物病虫害图片.选取Inception-V3,resnet18,resnet34,resnet50 等4 类代表性深度学习网络结构进行训练.训练方式采用迁移学习的方式,利用已在大型数据集ImageNet 进行预训练后的模型,冻结前几层的权重,根据该数据集修改全连接层的输出,重新以本文农作物病虫害数据集为基础进行训练,最终得到基于农作物病虫害图像的识别模型.流程如图7所示.
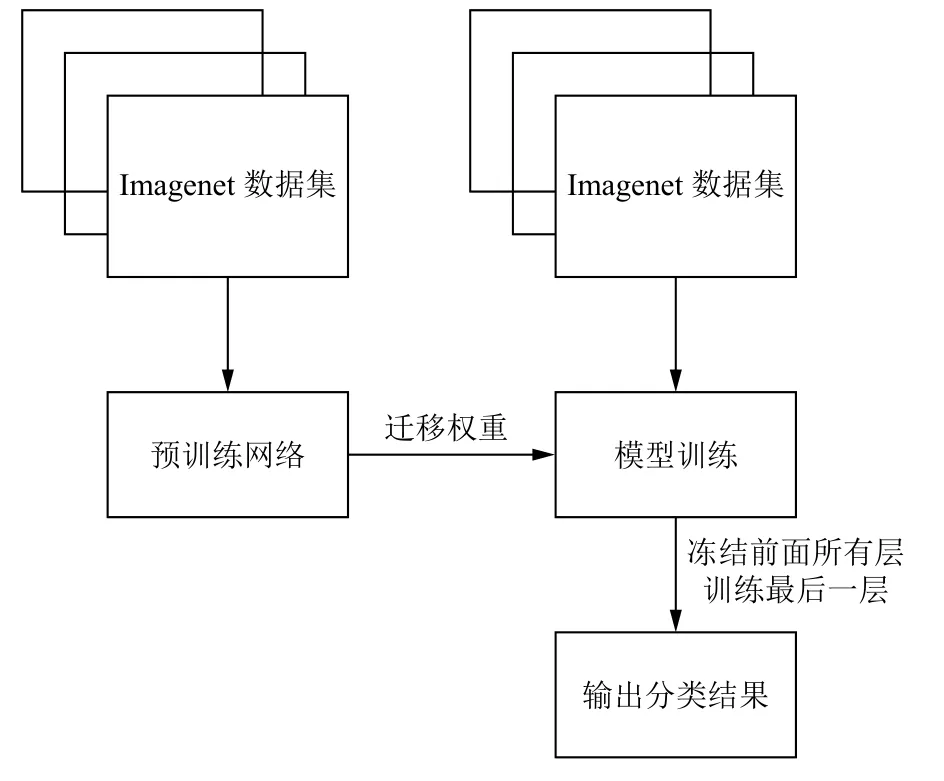
图7 病虫害识别模型学习流程
4.4 实验设置
本文采用深度学习框架Pytorch,图片输入大小为224×224,batch size 设置为128,epochs 设置为40,由于模型进行迁移学习只需要微调因此初始学习率设置为0.001 即可.在后续过程中对学习率采用等间隔调节的策略,每十轮迭代后学习率调整为当前学习率为0.1 倍.
对于优化算法而言,Adam 优化算法既考虑了Momentum 优化算法动量累计梯度的思路,又结合了RMSProp 优化算法在加速收敛速度的同时减小波幅的优点,因此本文在后续训练过程中选择Adam 优化器.
模型训练过程中的迭代详情如图8所示.
(1)加载已在Imagenet 上进行好预训练的模型,固定前几层的权重并将全连接层的输出改为本文病虫害数据集类别数59.
(2)按照上文的参数设置初始化网络.
(3)加载病虫害图像数据并进行数据增强后输入卷积神经网络.
(4)通过该模型得到的预测类别与输入图片的实际类别进行对比,计算损失.
(5)误差反向传播对网络的每个权重求偏导计算梯度乘以学习率进行更新.
(6)在验证集上进行识别得到该模型的正确率.

图8 训练迭代流程
4.5 实验结果分析
本次实验选择Inception-V3,resnet18,resnet34,resnet50 等4 类代表性卷积网络神经结构,分别进行迁移学习并在此基础上对原有的损失函数进行优化,建立的病虫害识别模型准确率如图9所示.可以看出这4 类模型收敛后准确率相差甚微,且准确率均在86%以上.

图9 不同模型top1 准确率曲线变化
分别将原始模型以及优化后的模型进行对比,训练过程准确率曲线如图10所示,我们可以看出在Inception-V3,resnet18,resnet34,resnet50 等4 种经典网络结构下,优化后的模型在前期和后期都取得了更优的结果,收敛后4 类模型的准确率均得到了有效提升.
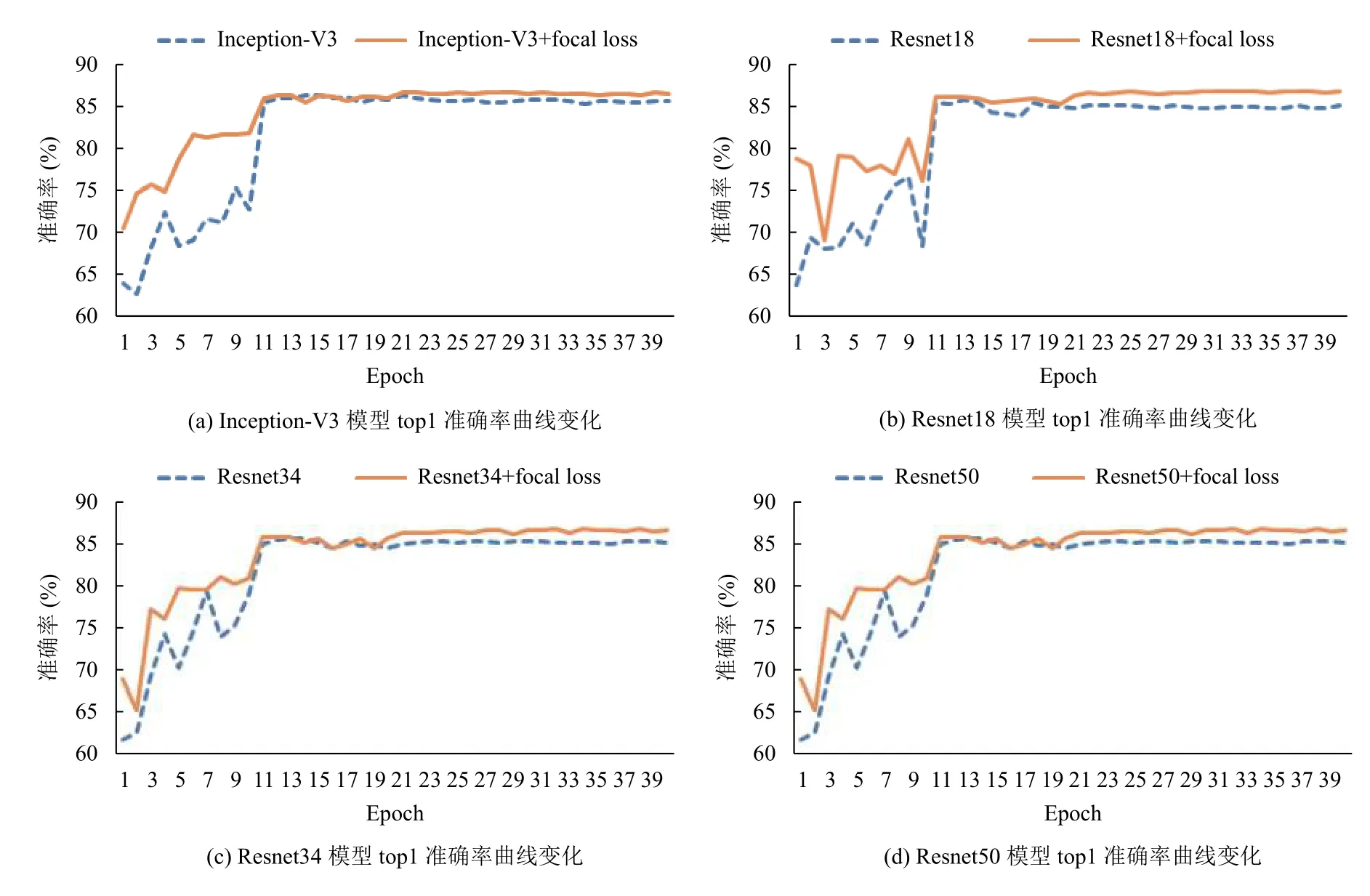
图10 模型对比top1 准确率曲线变化
最终实验结果如表2所示,可以看出不论是原始模型还是优化后的模型对农作物病虫害图片识别的准确率都在85%以上,证明了卷积神经网络在病虫害识别中可行性以及有效性.且与传统图像处理以及机器学习的方法相比,基于卷积神经网络建立的识别模型前期并不需要繁杂的图像预处理步骤,数据增强也可以通过训练过程中在线完成,模型建立过程更加简洁.通过对比实验结果可以发现在Inception-V3,resnet18,resnet34,resnet50 等4 种经典网络结构下,对损失函数进行进一步优化后的农作物病虫害识别模型的准确率都得到了有效的提升.
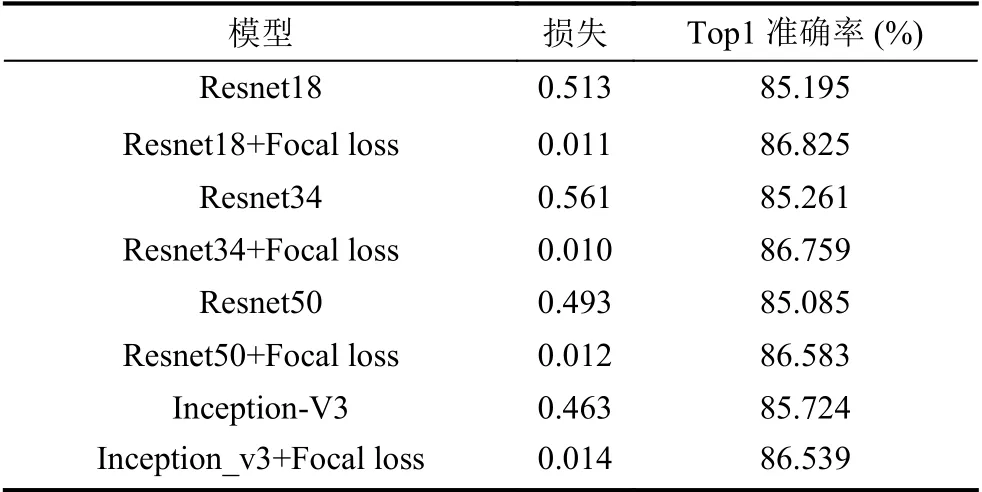
表2 准确率对比
5 总结与展望
本文通过迁移学习的方法,将卷积神经网络算法应用于农作物病虫害识别中,基于不同的代表性网络结构建立了农作物病虫害识别模型,其准确率均达到85%以上,证明了将卷积神经网络应用于病虫害识别是可行并且有效的.并且在对损失函数进行优化后的新的模型的准确率可以提升到86.5%以上.通过该农作物病虫害模型我们可以快速识别不同病虫害,并且可以根据程度不同采取合适措施,喷洒不同剂量的农药,实现农业现代化的同时减轻农药对环境的污染.
然而农作物病虫害种类远超本文数据集中所示的种类,想要应用于实际生产中我们仍然需要更大更全面的数据集进行模型训练.然而农作物病虫害数据收集困难,人工标注成本极其高昂.因此如何获得更全面的数据集且如何对获得的数据集进行准确标注是我们未来研究的重点内容.
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
