
基于自适应注意模型的图像描述
2020-06-17 07:54侯星晨
计算机与现代化 2020年6期
侯星晨,王 锦
(天津职业技术师范大学电子工程学院,天津 300222)
0 引 言
在计算机视觉领域,图像描述任务的目标是输入任意一幅图像,机器能够生成符合人类表达的自然、流畅的语言。这项任务的实现对于人们来说是比较简单和轻松的,但是对于机器而言,它不仅仅需要准确地识别图像中包含的目标,还需要捕获目标之间的动作以及学习描述语句中单词之间的关联信息。因此这项任务的实现融合了计算机视觉和自然语言处理领域。之前的大多数做法是采用卷积神经网络(Convolution Neural Network, CNN)作为编码器来提取图像特征,循环神经网络(Recurrent Neural Network, RNN)作为解码器从而产生描述语句[1-2]。然而这种直接将整个图像转换为一个静态向量的做法,可能会导致生成的描述语句丢失图像中的部分信息。这是因为模型中上下文向量Ct仅依赖于编码端CNN,在产生描述语句的单词时,解码端LSTM网络中的上下文向量Ct保持不变,不依赖于解码器的隐藏状态,这样产生的描述语句缺乏丰富的语义信息。最近借助于注意力机制在机器翻译任务中取得的优异表现,结合注意力机制的编解码框架模型被广泛地应用在图像描述任务中,其核心思想是在解码端LSTM网络中,在生成每一个描述单词时都通过注意力机制关注图像中与之相应的区域[3-6]。此时上下文向量Ct同时依赖于编码器和解码器,这样可以动态地突出图像特征。这种做法确实可以在一定程度上有效地提高描述语句的质量。然而这种方法很少考虑如何确定受注意的图像区域,如图1(a)所示,编码端采用CNN提取图像特征时,最终输出的特征向量都对应一个形状大小相同的图像区域,但是并不是每个图像区域对应的特征向量都对生成描述语句有帮助。此外这种做法是在每个时间步长,解码端LSTM都通过关注与之对应的图像区域来生成描述单词,然而并不是在每一个时间步长都需要通过视觉注意来关注图像特征。对于描述语句中的“a”和“of”等非语义单词并没有与之对应的图像区域,此时不需要引入注意力机制,只依赖语言模型LSTM网络就可以生成。如果模型强行将图像的某个区域和非语义单词相关联,这会导致关注区域分散,在生成语句时模型可能会将关注区域的对象和修饰单词混淆,标注的语句将会出现错乱。
为了生成更丰富、更符合人类表达的图像描述语句,本文引入一种自适应注意力机制的图像描述模型。在编码端采用Faster R-CNN[7]和ResNet101 CNN[8]将图像中的一些显著区域提取出来,每个区域都对应一个相同维度的特征向量,如图1(b)所示。在解码端采用一种新的空间注意模型来提取空间图像特征,然后在LSTM网络中引入视觉监督向量,最后设计一个监督门可以自动控制是依赖于视觉信号,还是仅依赖于语言模型。

(a) CNN提取图像特征示例

(b) Faster R-CNN提取图像特征示例
1 相关工作
图像描述在自动导航与人机交互等领域有许多重要的应用,图像描述任务中也设计了许多不同的模型。这些方法大体上可以分为基于模板的方法和基于编码解码框架的神经网络方法。
基于模板的方法,首先人为构造大量留有空白部分的句法模板,然后通过提取图像特征获取目标、目标的属性以及目标之间的动作,再将它们嵌入到一个固定的句法模板中,从而生成某一图像的描述语句。Farhadi等人[9]提出了一个包含物体、动作、场景的多模态空间,采用图像中的物体、动作、场景这3个语义元素来构成描述语句的模板。后来Li等人[10-11]在此方法的基础上,将图像中检测出的物体间关联信息也作为一种语义元素来构成描述语句的模板,最后生成了语义信息更加丰富的描述语句。这种基于语义模板的词填充方法在一定程度上保证了描述语句的语法和语义的正确性,但是生成的描述语句大多是模板中的固定句式,不能产生丰富的描述语句,尤其对于场景较为复杂的图像,生成的描述语句不能充分地表达图像内容。
编解码框架的神经网络模型的灵感来自于机器翻译中序列到序列的成功[12-14],其观点认为图像描述类似于将图像翻译成文本。Kiros等人[15]最早提出了一种多模态对数双线性模型来生成描述语句。Vinyals等人[2]创造性地采用LSTM网络替代了普通的RNN网络,其模型结构成为了编解码框架的主流模型。上述的这些方法都是将CNN网络中最后一个全连接层的输出作为图像的全局特征。
近年来,注意机制被引入到基于编解码器框架的神经网络模型中。Xu等人[5]在图像描述模型中加入了一种注意机制,在最初生成相应的单词时就开始学习潜在的语义对齐。文献[15-17]利用高级概念或属性标签,将它们视为一种语义注意力机制,将其输入到解码端LSTM网络中,以增强图像描述效果。
2 图像描述模型
2.1 自底向上的注意力模型
Faster R-CNN在目标检测和目标定位任务中表现非常出色,其核心思想是从候选区域中选取出与检测的目标物体重合度最高的区域[7]。Faster R-CNN通常分为2个阶段来检测目标,第一阶段首先通过区域建议网络(Region Proposal Network, RPN)生成目标候选区域,然后对每个得分区域采用贪婪非极大值抑制方法,选取前N个超过交并比阈值(Intersection-over-Union, IoU)的候选区域输入至感兴趣区(Region Of Interest, ROI)的池化层。在第二阶段ROI池化层将每个候选区域映射为固定长度的特征向量,然后将特征向量输入一个全连接网络,从而输出预测对象类别和边界框偏移量。
本文采用Faster R-CNN和ResNet101来提取图像特征,具体方法是:首先对Faster R-CNN网络输出的对象类采用贪婪非极大值抑制方法,然后挑选出检测率超过置信度的区域来组成图像特征V={v1, …,vk},vi∈Rd。其中,vi表示被挑选出的第i个区域的均值池化后的卷积特征,图像特征向量的维数d均为2048。
2.2 空间注意力模型
给定空间图像特征V∈Rd×k和LSTM网络的隐藏层状态ht∈Rd,将其通过一个单层神经网络和一个softmax函数,生成k个区域的注意分布权重:
(1)
αt=softmax(zt)
(2)
其中,I表示一个全1矩阵,I∈Rk。Wv、Wg和Wh是需要训练的网络参数,Wv∈Rk×d和Wg∈Rk×d,Wh∈Rk。αt表示图像特征的关注权重,其区间在[0,1],αt∈Rk。根据注意分布可以得到上下文向量Ct:
(3)
其中,αti表示图像中第i个区域的注意力分布权重,vti表示图像中第i个区域的图像特征。
与文献[5]做法不同,文献[5]首先是由图像特征V和前一个时刻的隐藏状态ht-1得到的上下文向量Ct,然后再根据当前时刻的隐藏状态ht、上下文向量Ct和当前时刻的输入xt来生成下一个单词,其结构如图2(a)所示,其中MLP表示单层的神经网络,Atten表示注意力神经网络。本文对其模型作出部分改变,其结构如图2(b)所示。首先通过当前时刻的输入xt和前一个时刻的隐藏状态ht-1得到当前时刻的隐藏状态ht,然后再根据当前时刻的隐藏状态ht和图像特征V生成上下文向量Ct,利用ResNet网络的优异性能,可以将生成的上下文向量Ct看作是当前隐含状态ht的视觉残差信息,这样可以降低隐藏层对于预测下一个单词时产生的不确定性,同时也可以补充当前隐含状态对下一个单词预测的信息量。
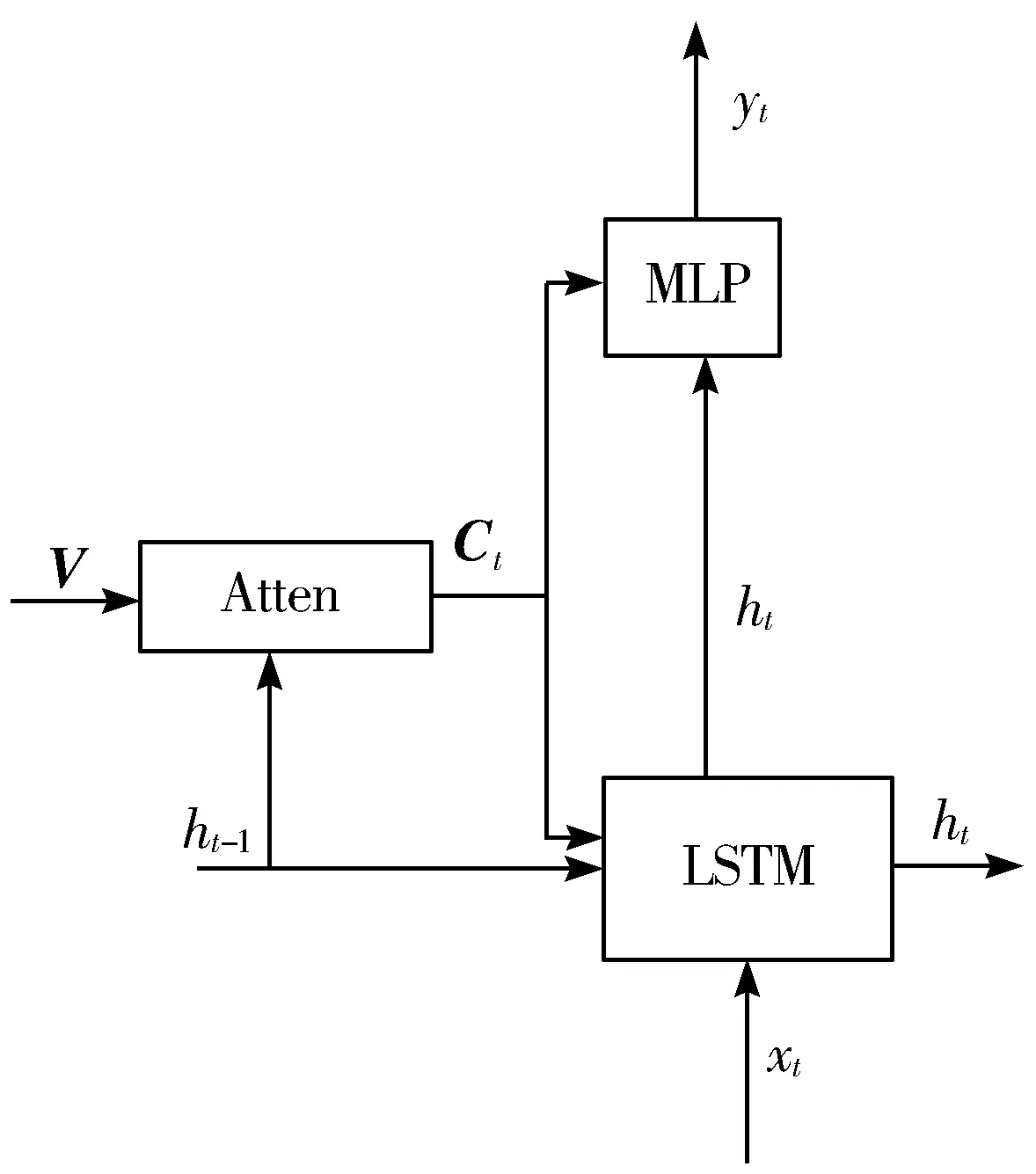
(a) 软注意模型
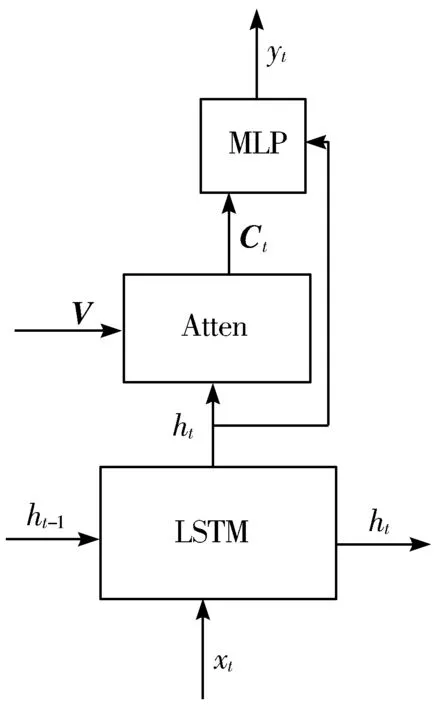
(b) 空间注意模型
2.3 自适应注意力模型
本文在LSTM网络中设计了一个视觉监督部分,这部分用来储存已经生成的文本信息。当生成非语义单词时,可以通过视觉监督部分直接生成,而不需要再关注图像特征信息。如图3所示,将视觉监督向量st和图像特征共同构成LSTM网络的隐藏层状态ht,具体过程可以表示为:
gt=σ(Wxxt+Whht-1)
(4)
st=gt⊙tanh(mt)
(5)
xt=West
(6)
其中,Wx和Wh是需要学习的参数,xt表示在第t时刻LSTM网络的输入单词,gt表示记忆单元mt中的候选状态,⊙表示向量元素乘积,σ表示sigmoid激活函数。其中We表示词嵌入矩阵。采用one-hot编码的单词st∈(s0, …,sN-1),其维度与给定词汇表的维度相同。
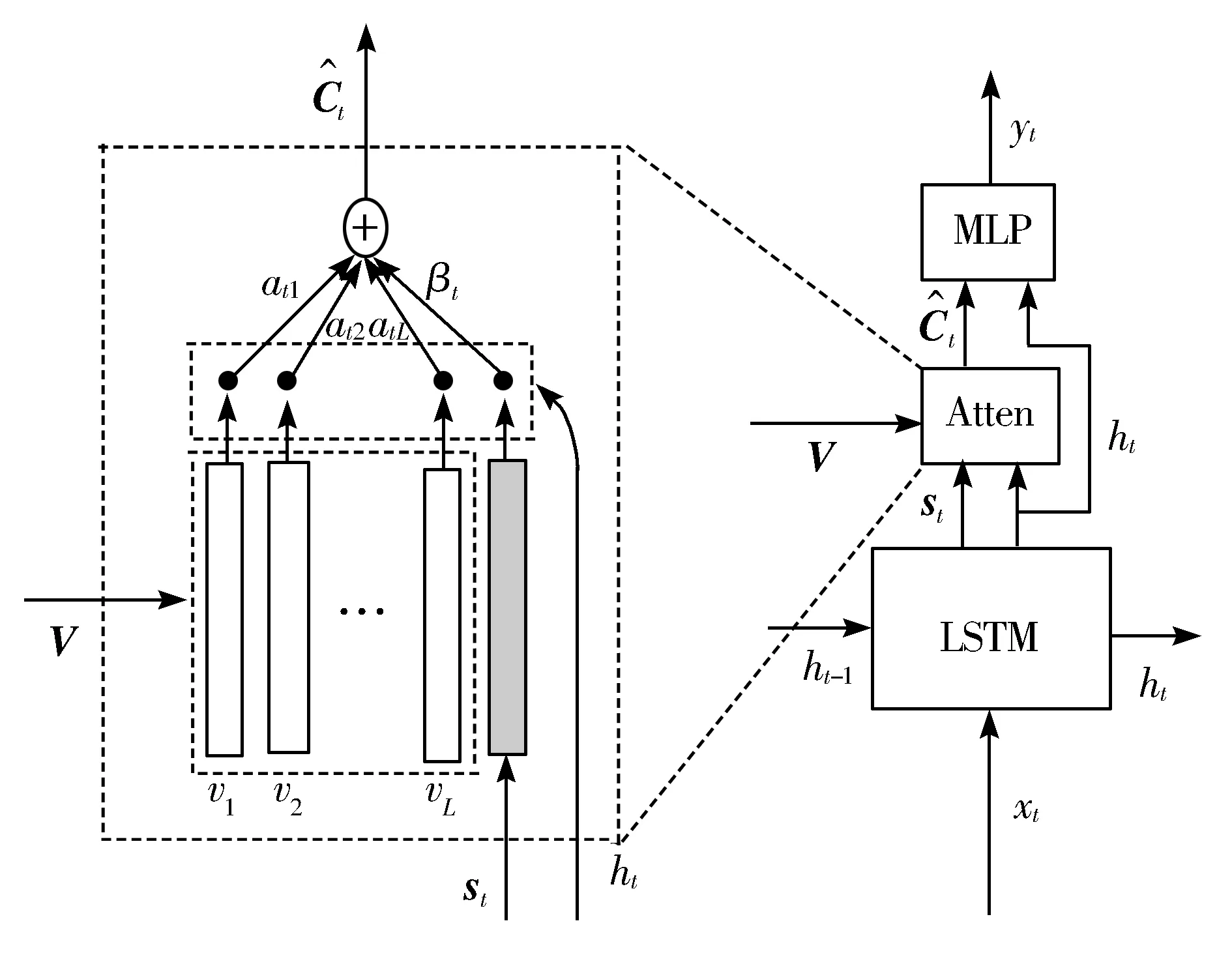
图3 模型中生成第t个单词yt时的示例
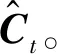
(7)
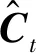
为了更加具体地确定参数βt的取值,将视觉监督向量st也加入到注意力模块,从而可以得到βt的值。
(8)
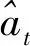
(9)
(10)
其中,Wp是网络需要学习的参数。
3 实验和结果
3.1 数据集
1)Visual Genome数据集。
本文使用Visual Genome[18]数据集来训练自底向上注意力模型。Visual Genome数据集包含大约10.8万幅图像,每幅都密集标注了图像中包含的目标物体以及物体的属性。为了更好地训练自底向上注意力模型,在训练过程中只使用了对象类和属性数据。预先保留5000幅图像用于验证,另外5000幅用于测试,剩余98000幅用于训练模型。
由于图像上的目标物体和属性都是由字符串形式组成,而不是已经分好的类,因此需要对数据中的一部分数据进行过滤,选择2000个对象类和500个属性类,删除一部分在初始实验中检测效果较差的抽象物体,最终得到包含1600个对象类和400个属性类的训练集。值得一提的是在数据集中不会删除或合并重叠类(例如person、man、guy)和具有单复数的类(例如dog、dogs)。
2)Microsoft-COCO[19]和Flickr30k[20]数据集。
本文使用MS-COCO 2014和Flickr30K数据集评估图像描述模型。MS-COCO 2014数据集包含大约123000幅图像,Flickr30K包含大约31000幅图片,每幅图像都对应着5句人工标注的描述语句。本文分别选5000幅图像作为验证集和测试集,剩余的图像作为训练集来训练图像描述模型。遵循标准做法,首先对文本做一些预处理,将描述语句的单词全部转化为小写形式并在空格处标记,删除出现频次小于5的单词,最终生成一个包含10000个单词的词汇表。
3.2 模型训练与参数设定
1)自底向上注意机制模型训练。
本文对RPN和Fast R-CNN这2个模块都采用单独训练的方式,这是因为在训练过程将前一个网络的输出作为后一个网络的输入,直接采用反向传播算法进行端到端训练是不可行的。在训练Fast R-CNN网络时需要固定的候选框,如果候选框是动态变化的,可能导致Fast R-CNN网络参数不会收敛。
本文采用交替训练(Alternating Training)的方法对Faster R-CNN和ResNet101进行训练,具体训练过程为:首先利用在ImageNet上预训练的ResNet101模型初始化Faster R-CNN,独立训练RPN网络;其次使用上一步训练好的RPN网络产生的候选框,将其作为初始值来训练检测网络Fast R-CNN;然后使用上一步训练好的Fast R-CNN网络参数来初始化一个新的RPN网络,此时保持RPN网络和Fast R-CNN网络中卷积层参数不变,只是微调RPN网络中其他层的参数,从而实现2个模块共享卷积层特征;最后保持训练好的共享卷积层参数不更新,微调Fast R-CNN网络中其他网络层的参数,这样就可以得到训练好的自底向上注意力模型。
本文采用自适应学习率算法训练网络参数。在模型中设置IoU阈值为0.7,为了选择突出的图像区域,类别检测的置信度阈值设置为0.2。根据每幅图像的复杂度不同,每幅图像提取的区域特征个数是动态的,最大数值设置为100。
2)图像描述模型训练。
在实验中,使用一个单层的LSTM,隐藏单元为512。使用Adam算法优化网络模型,设置LSTM网络的学习率为5e-4,设置CNN网络学习率为1e-5。动量衰减为0.8,重量衰减为0.99。训练批大小设置为80,并进行最多50代的训练,如果验证成功,则提前停止。对MS-COCO和Flickr30K数据集的标注进行采样时使用的波束大小为3。
3.3 实验结果及分析
本文采用BLEU[21]、METEOR[22]、ROUGE[23]和CIDEr[24]共4种评价机制,它们的分值越高表示生成描述语句的质量越好。表1展示了本文模型与其他模型在MS-COCO数据集上的评估分数,表2展示了本文模型与其他模型在Flickr30K数据集上的评估分数,其中Human表示人工标注的描述语句的得分,“-”表示未在文献中找到其数据。从表中的结果来看,本文的生成描述语句模型与文献[3]中Adaptive模型相比,评估分数的提升幅度见表1、表2。同时与其他模型相比,本文模型在4种评价标准中均取得最优分数,生成描述语句的质量有大幅度提升。图4给出了本文模型生成描述语句的示例,值得一提的是,图4(c)生成描述语句中的“together”一词很好地表现了目标之间的空间关系,展现了模型的良好性能。
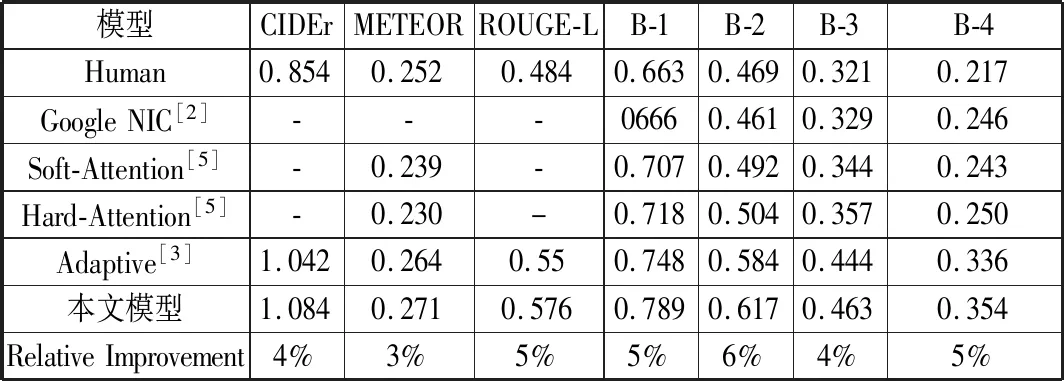
表1 本文模型在MS-COCO数据集上的评估分数
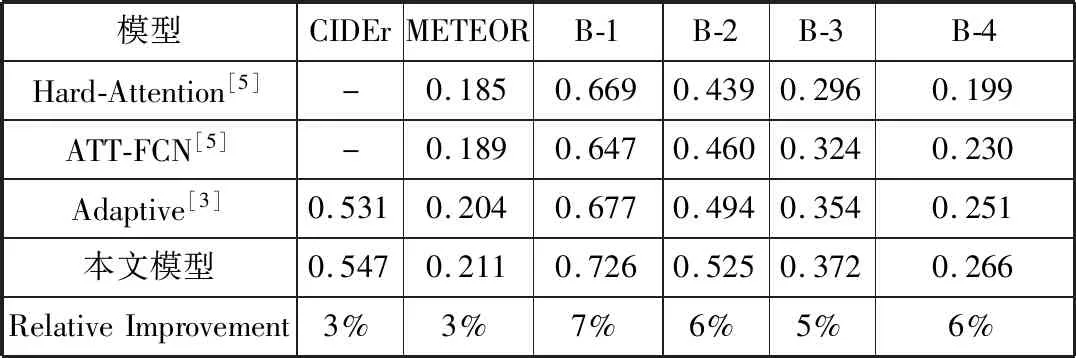
表2 本文模型在Flickr30K数据集上的评估分数

(a) Two men playing frisbee in a dark field.

(b) A brown sheep standing in a field of grass.
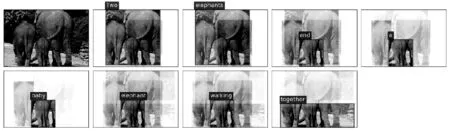
(c) Two elephants and a baby elephant walking together.
4 结束语
本文介绍了一种自适应注意的图像描述模型,在编码部分采用Faster R-CNN提取图像中的显著特征,在解码部分通过扩展LSTM网络结构产生一个视觉监督向量,从而实现了能够自适应注意不同的信息来预测下一个描述单词。最后在MS-COCO数据集和Flickr30K数据集上进行验证,实验结果表明,本文模型可以有效提高描述语句的质量。本文模型不仅可以应用在图像描述任务,还可以应用到机器问答来实现人机交互。下一步的工作是如何将最近提出的具有优异表现性能的对抗网络引入图像描述任务,借助强化学习的方法来优化模型训练。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
新世纪智能(语文备考)(2020年4期)2020-07-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
