
基于卷积神经网络的高速无线局域网分组丢失和错误原因识别方法
2020-06-17 07:53黄庭培蔡丽萍李世宝
计算机与现代化 2020年6期
张 宁,黄庭培,蔡丽萍,李世宝
(1.中国石油大学(华东)海洋与空间信息学院,山东 青岛 266580;2.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580)
0 引 言
近年来,无线局域网快速发展,在众多领域得到广泛应用,比如,工业、军事和民用领域[1]。无线局域网络一般部署在复杂的环境中,它会受到天气、障碍物等因素的影响,例如,在校园、机场和车站中,受到信号衰减或干扰等因素的影响较大。与有线网络相比,802.11n无线网络链路质量比较差,有着较高的误码率,这会导致数据包丢失和错误,使得发送方必须多次重传数据包,这使信道利用率变低,性能下降。为了准确高效地识别数据包丢失和错误原因,使用户有着高质量的体验,802.11n天线链路质量的测量与分析显得尤为重要[2-7]。
已有研究表明,信道衰减和信道冲突是导致数据包丢失和错误的主要原因[8-9]。已有的判断分组发送结果的方法通常是采用竞争信道访问方式的机制来确认的,这种方法不能反映信道的实际情况,这种机制认为在没有收到确认包的情况下,是数据包冲突原因造成的。所以设计高性能的网络协议势在必行,这样才可以高效地识别分组丢失和错误的原因。设计高性能的网络协议对功率控制协议、路由协议和传输层拥塞控制协议等有着重要作用,它也适用于速率自适应方向[10-20]。
目前对分组丢失和错误原因识别的分析研究,存在通信开销大、需要专门定制的硬件支持、需要修改协议等问题。RTS/CTS(Request-To-Send/Clear-To-Send)控制分组会产生大量的开销,造成信道利用率下降[1]。COLLIE[7]分析误码特征时需要接收整个的误码包,使得通信的开销也增大。SoftRate[8]使用的是物理层的错误误码,但是它需要额外的硬件支持。
1 分组接收情况测量分析
实验设计3种不同场景,分别进行大量的分组接收测量实验,并分析接收数据包的RSSI、CSI值在不同实验场景下的统计特征。下面介绍本文采用的实验方法,并分析所观察到的实验结果。
1.1 背景与实验方法
1.1.1 背景
实验使用装有Atheros网卡和Intel5300网卡的电脑,其中,装有Atheros网卡的电脑有2根天线,装有Intel5300网卡的电脑有3根天线。操作系统使用的是Linux系统。电脑工作在ISM 2.4G频段,每个信道宽度为20 MHz,传输速率为52 Mbps。Atheros-CSI-Tool和Linux 80211n CSI Tools提供了RSSI和CSI读数接口。
1.1.2 实验场景和实验方法
本文在以下3种环境下进行了大量统计实验:实验室(Lab)、长廊(Cor)和地下一层停车场(Park),如图1~图4所示。通过实验测量并分析在信道错误主导和冲突主导的网络环境下接收到分组的RSSI、CSI的统计特征。
1)Lab与Cor。Lab和Cor实验场景中无WiFi信号,但有墙壁作为通信障碍,并有4G信号,主要测试信道衰弱和干扰。
2)Park。Park实验场景中无WiFi信号和4G网络信号,场景空旷,基本无障碍物,该场景下的实验主要测试信道冲突。
实验通过发包数目、通信距离、发包间隔及时间(白天/夜间)和隐藏终端这些参数考虑对实验的影响,每组实验重复10次。
图1 实验室模拟场景
图2 走廊模拟场景

(a) 实验地点1 (b) 实验地点2图3 实验室真实场景
(a) 停车位模拟场景 (b) 停车位实际场景图4 停车位场景
表1给出了实验设计方案。场景Ⅰ是近距离(0.5 m)场景下,一个无线接入点发送,一个客户端接收,另一个发送端进行干扰。场景Ⅱ是长距离场景(5 m)下,一个无线接入点发送,一个客户端接收。场景Ⅲ是近距离场景,2个无线接入点发送,一个客户端接收。

表1 实验设计方案
1.2 分组接收情况测量结果分析
下面分析RSSI、CSI的统计特征。
1.2.1 不同场景不同平台下RSSI和CSI的统计值分析
(a) Intel 5300网卡

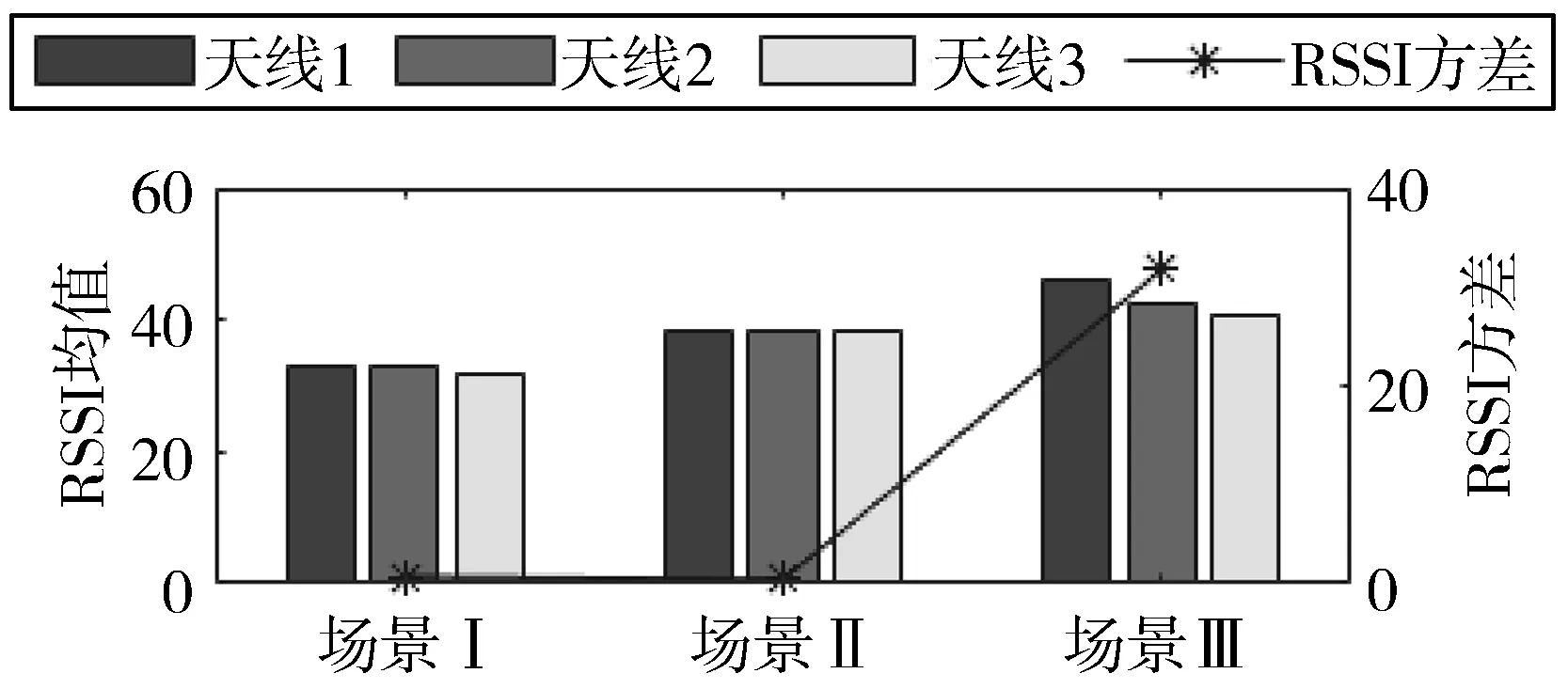
(b) Atheros网卡图5 RSSI在不同场景下的相关值
1)图5给出了在3种不同场景下RSSI均值和方差的统计结果。在多次实验中,上述统计结果更加明显。如图5所示,在所有接收到的分组中,尤其是在场景III中,RSSI均值最大,且方差最大。Park与其他2个场景相比,在冲突环境下,单个RSSI值波动比较明显,且波动幅度大。因此可以利用RSSI来帮助识别丢失和错误的原因。
2)图6与图7是不同网卡在不同场景下测量出的RSSI与CSI值。图6(a)与图7(a)是CSI幅值的累计分布图,从图中可以看出,场景III与场景I和场景II有着明显的区别,为先升,然后趋于平稳,最后再升。这是因为在碰撞场景下,CSI幅值变化明显,从图6(c)与图7(c)可以看出,CSI值的方差变大,由图6(b)与图7(b)得出,CSI平均值变小,这是信道变差的原因。
所以,在不同场景不同平台下,因信道变化差异,CSI与RSSI值变化明显。信道越差,CSI幅值越小,方差越大,RSSI值越大。本文将用CSI幅值和RSSI均值来识别分组丢失和错误的原因。
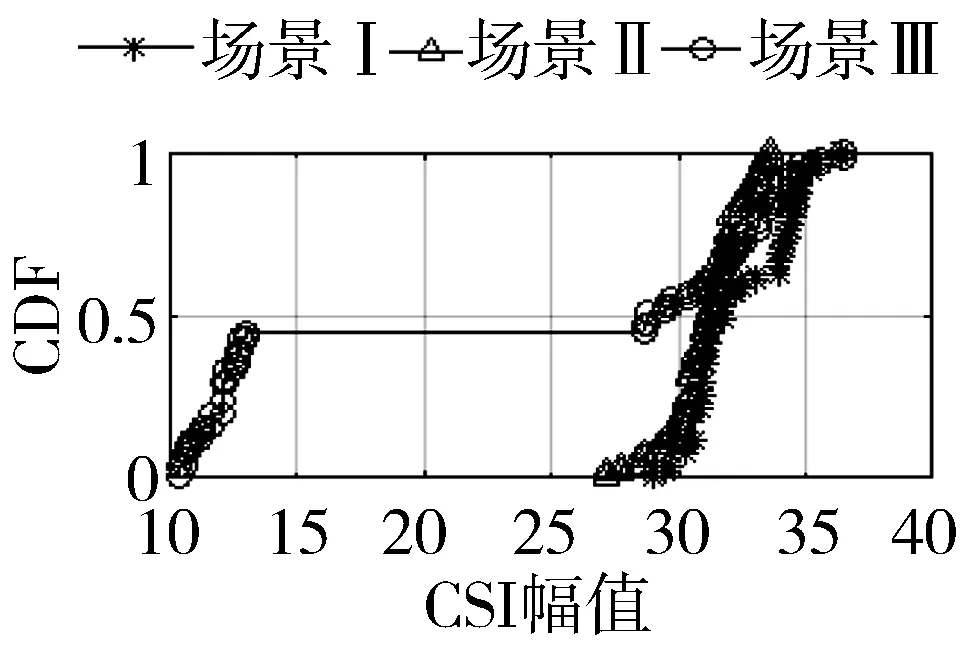
(a) CSI的CDF值
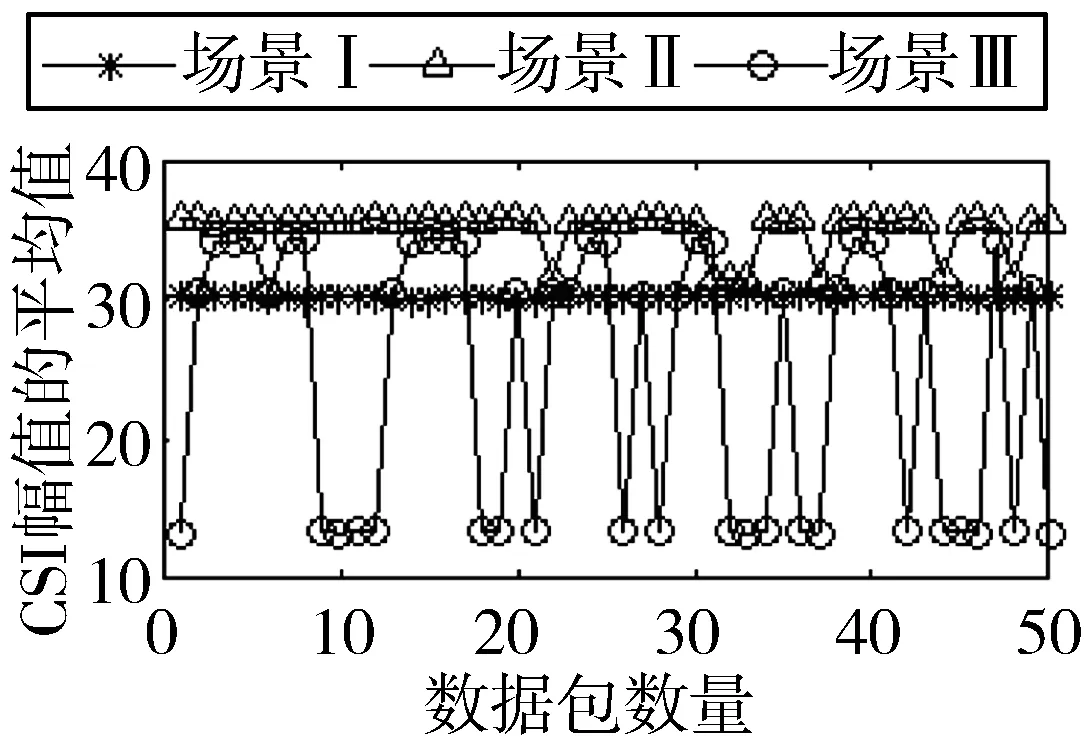
(b) CSI平均值
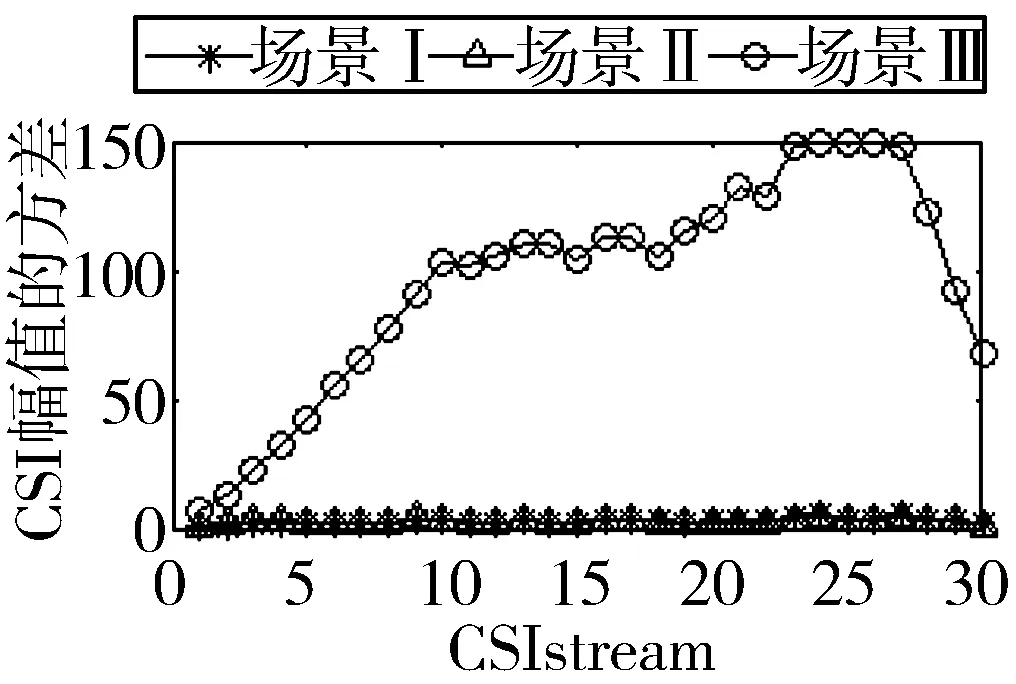
(c) CSI方差
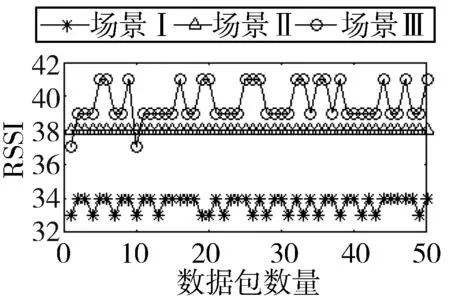
(d) RSSI值
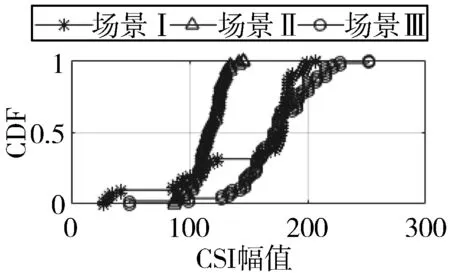
(a) CSI的CDF值
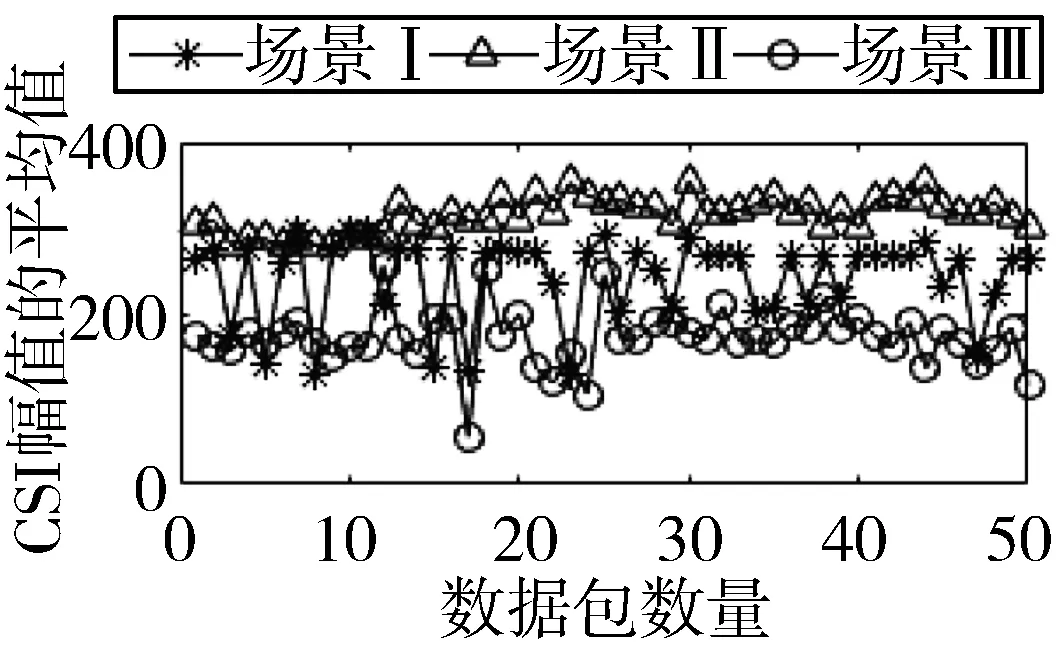
(b) CSI平均值
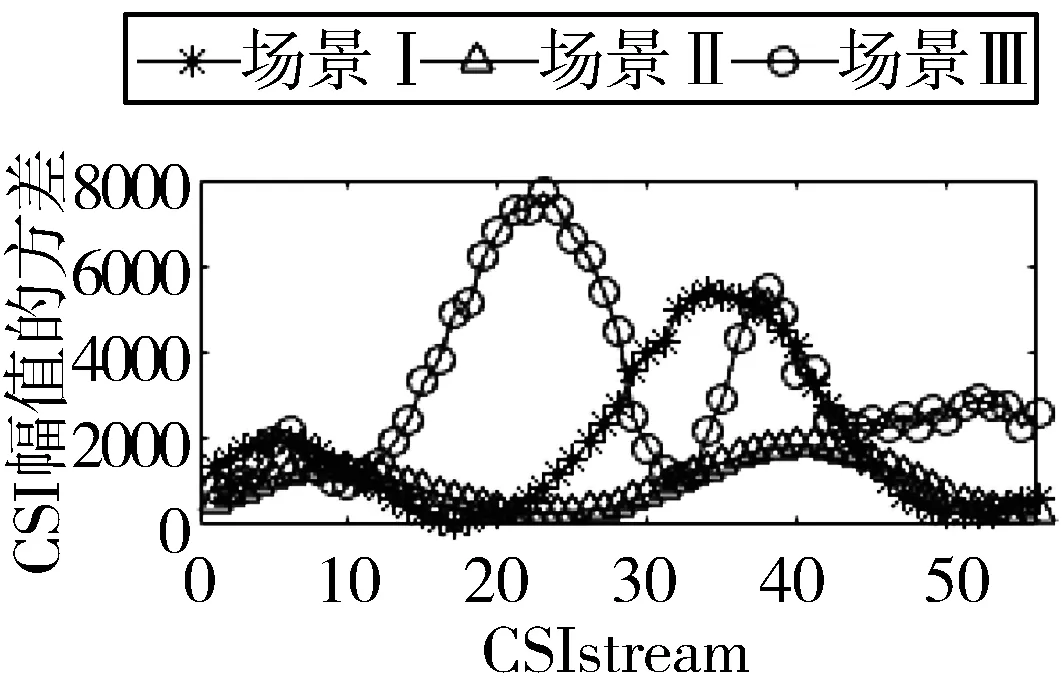
(c) CSI方差
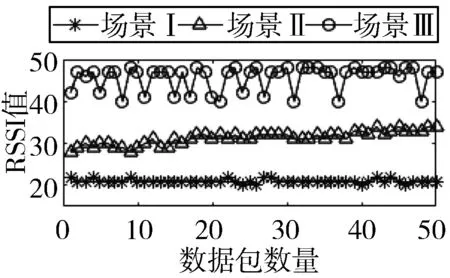
(d) RSSI值
3)图8通过对CSI幅值的分析,显示了发送数据包数量的不同对信道质量的影响。Atheros网卡所测得的数据,选取56个子载波的均值来代表当前CSI的幅值。Intel 5300网卡测得的数据,选取30个子载波的均值代表当前CSI的幅值。图8(a)为Intel 5300所测得的数据,与图8(b)相比,Intel 5300所得到的CSI幅值要小,但是通过分析两者所测得的数据得到的结论相同,即当发送数据包越多,CSI幅值跨度越大。此外,还可以利用方差的方法来分析CSI幅值的变化,可以得出,当数据包数量变多,CSI幅值的方差会相应变大。
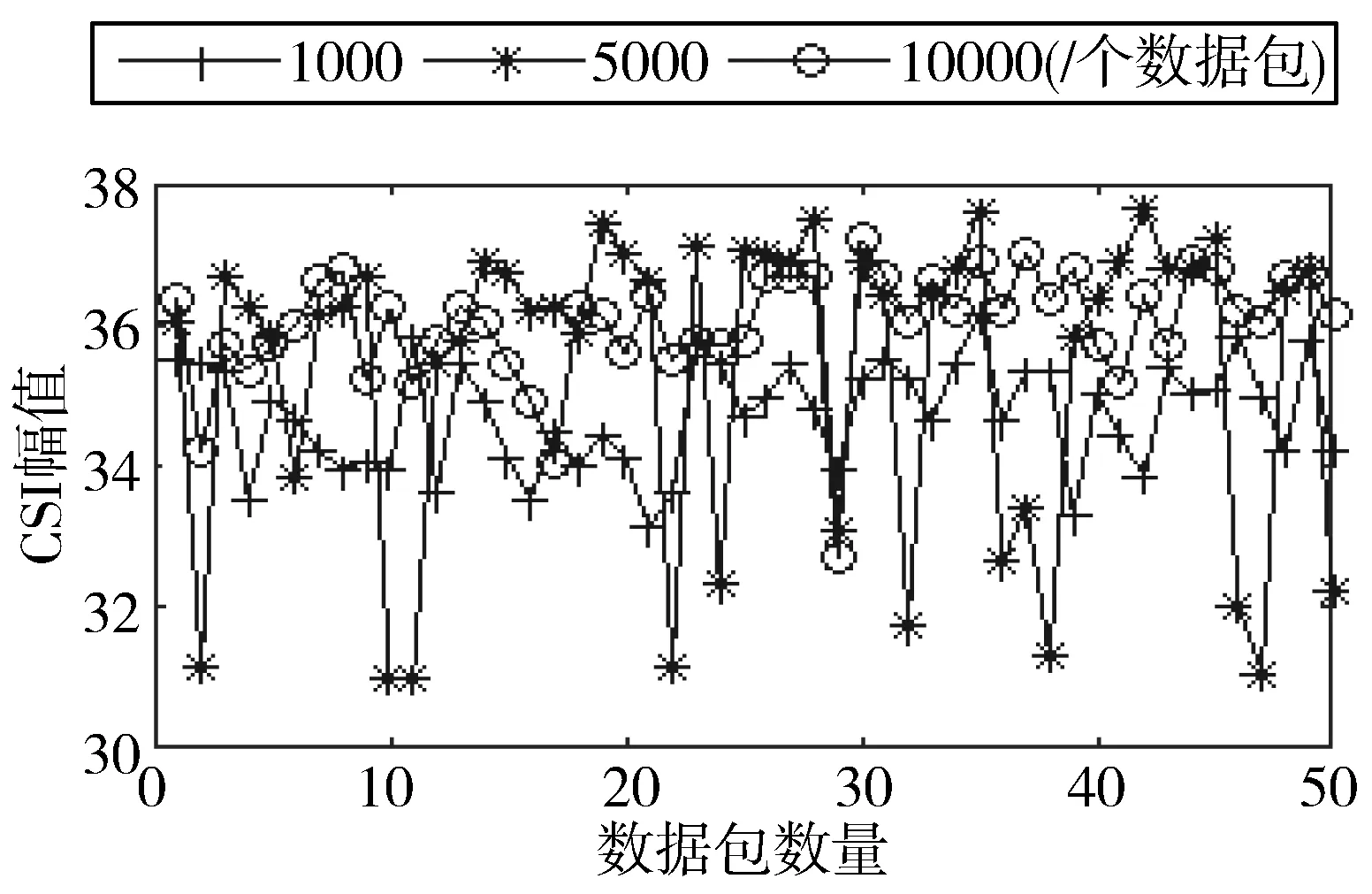
(a) Intel 5300网卡
(b) Atheros 网卡
1.2.2 静止场景中不同参数在不同平台下对天线链路质量的影响
1)由1.2.1节可知,信道质量与平台关系相差较小。图9显示了只修改发包速率的情况下,发包速率对信道质量的影响。实验中通过修改发包间隔来改变发包速率。当增加单位时间内发送数据包的数量,即发包速率变大时,CSI幅值变化幅度变大,信道变得不稳定。所以,在数据包传送过程中,速率越快并不代表信道传输效率越高。

图9 发包速率对信道质量的影响
在速率较低的场景中,所测得的信道比速率高的场景中更稳定,但是获得的信息含量会变少,这意味着选择合适的速率传输对用户的体验有着重要的影响。
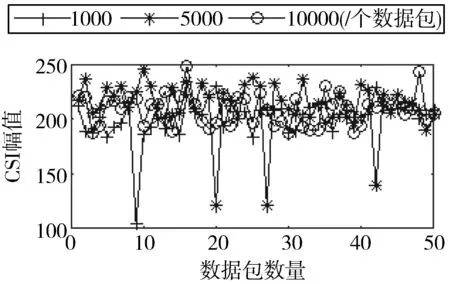
2)图10显示了通信距离对信道质量的影响。当通信距离增大时,CSI幅值从250 dB左右降低到50 dB。当通信距离变大,信道变差,当增大发送功率,CSI幅值会相应增加。不同环境的影响,例如天气、障碍物等不同因素都可能导致信道质量变差。可以看出,随着距离的增大,CSI幅值变小,接收数据包呈降低趋势。
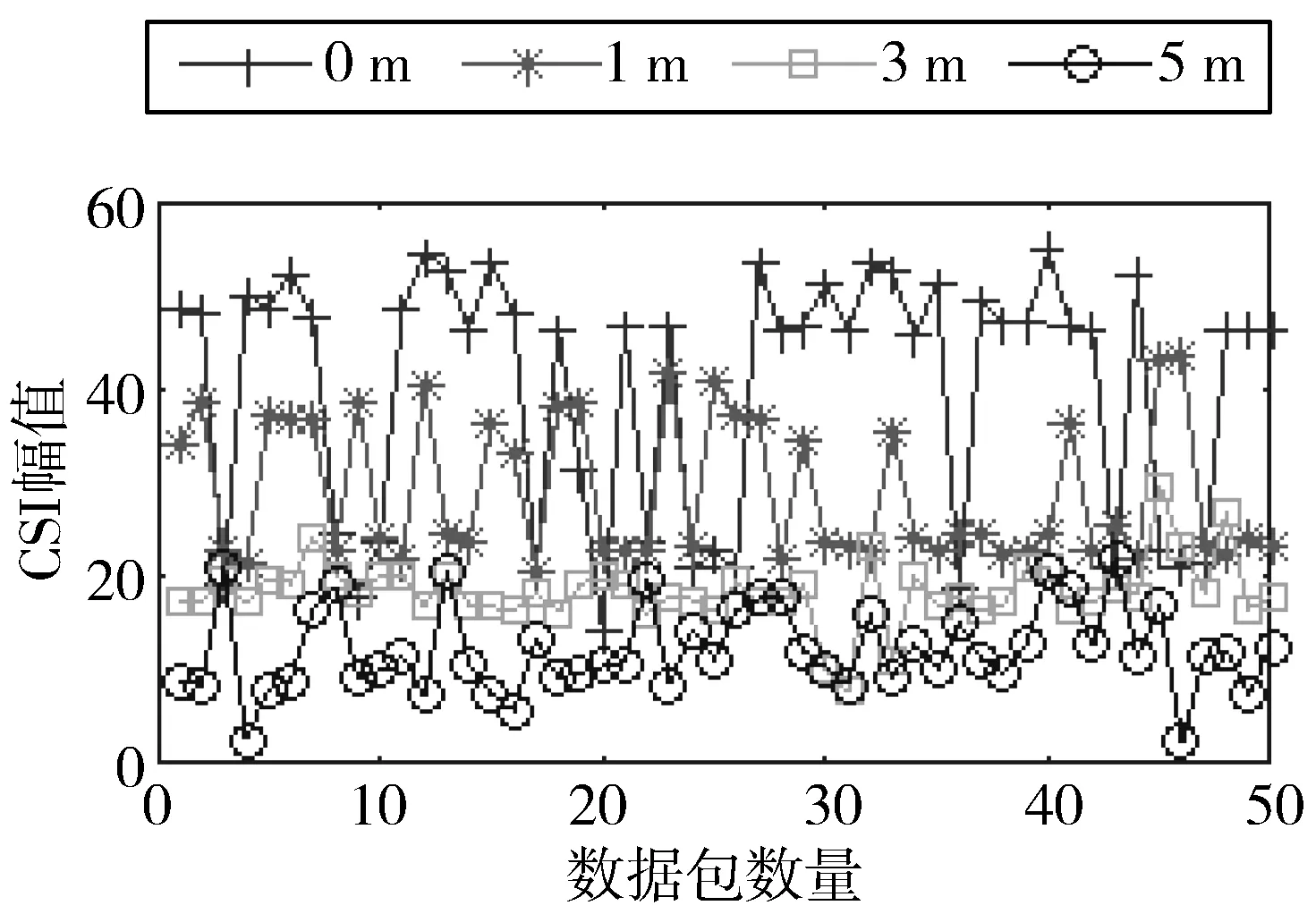
图10 通信距离对CSI幅值的影响
1.2.3 运动场景中不同参数在不同平台下对天线链路质量的影响
图11显示了运动状态下,不同子载波的CSI幅值变化情况。当接收端均匀远离发送端时,CSI幅值也缓慢下降,而静止状态下CSI幅值在一定区域内变化。但在运动状态下,CSI随着时间推移,变得越来越小,直至发送端与接收端断开连接。现实生活中,当人们从一个小区到另一个小区,就涉及基站的选择变换。在适当的位置建立基站就需要得知当前位置的信道状态。所以,运动对链路质量的影响比静止状态下更大。
图11 运动状态下通信距离对信道的影响
通过实验,可以观察到Atheros网卡和Intel 5300网卡所得到的结论相同。由于Atheros网卡所测得的是56个子载波,所测得的CSI幅值比Intel 5300更大一些,所显示出的特性会更加明显。
本文用CSI幅值、方差和RSSI的平均值、方差来识别分组丢失和错误的原因。
2 MPLEC的设计与实现
本章对数据包丢失和错误识别问题进行建模,利用机器学习理论,详细阐述基于监督学习理论的分组丢失和错误原因识别模型,即MPLEC的设计与实现。
2.1 MPLEC概述
MPLEC包括特征提取与样本采集,问题建模、离线训练与检验,以及识别这3个步骤:
1)特征提取与样本采集。首先提取能够代表数据包丢失和错误原因的特征属性。即接收端保存的每一个接收到的数据包,并提取每个数据包的RSSI值和CSI值。本步骤为问题建模、离线训练与检验提供高质量的样本集。
2)问题建模、离线训练与检验。通过监督学习方法对此问题进行建模、离线训练与检验。本文使用RSSI均值和方差以及CSI幅值和方差组成的特征向量作为输入,分组丢失和错误的原因为输出。
3)识别。识别分组丢失和错误的原因。MPLEC识别是在接收方实现的一种分类器。
2.2 特征提取与样本采集
2.2.1 特征提取与输出标记
首先需要提取模型的输入特征向量,采集样本特征值,并标记输出结果。第1章的实验结果表明,接收端接收到数据包的RSSI值和CSI值在不同网络环境下表现出不同的统计特征,因此本文提取RSSI和CSI的相关统计特征作为模型的输入特征向量的属性。特征向量各属性的定义如表2所示,用于将输入特征指派到一个特定的类为输出标记。

表2 输入特征向量属性的定义
本文采用多类(Multi-class Model, MM)MPLEC分类模型。多类MPLEC分类模型将分组丢失和错误的原因进行细粒度的区分,具体标记为干扰、干扰主导、弱链路、弱链路主导、冲突和冲突主导这6种情况。因为在实际网络环境中,信道错误和冲突都存在时,更细粒度地识别分组丢失和错误的原因可以给网络协议提供更准确的决策信息。
2.2.2 样本采集
离线训练与检验需要采集大量的样本数据。本文在3种不同的环境下进行大量的实验,采集了超过20 GB的原始数据。在Lab和Cor场景下主要测量了信道错误主导环境下节点接收数据的情况。在Park场景下主要测量了冲突干扰和信道错误都存在的环境下和802.11网络干扰主导环境下节点接收数据的情况。
2.3 问题建模、离线训练与检验
2.3.1 问题建模
特征向量和样本集由2.2节提供,本节对数据包丢失和错误的原因识别问题进行建模,利用监督学习方法设计并实现MPLEC多分类模型。MPLEC分类模型中输入为表2给出的4个特征属性组成的特征向量,其中CSI幅值为3×3×56×n,n为数据包个数,数据可以当作n幅图像进行输入,输出为引起分组丢失和错误的原因。本文用X表示输入特征向量,即有:
X=[mean(RSSI), var(RSSI), mean(CSI), var(CSI)]T
所有特征属性的值都是离散的。本文对RSSI均值、方差以及CSI幅值、方差进行预处理、归一化处理,使得它们的取值范围为[0,1]。卷积层的激活函数为ReLU函数[21],x代表RSSI均值、方差或CSI幅值、方差,其表达式如下:
ReLU(x)=max(x,0)
利用Lp进行池化[20]:
其中,u、v为一种索引方式,x为RSSI的均值、方差或CSI幅值、方差,如CSI(1,1)代表第1根天线的第1个子载波值,为一个具体数值,属于特征向量X,n代表样本数量;P代表池化层数,当P=1时,Lp池化为均匀池化。
本文使用5个卷积层、3个池化层和3个全连接层。输入为1000×50组数据,训练集为90万幅图像,过拟合问题利用Dropout策略来缓解,利用ReLU激活函数来使收敛速度加快,并使用GPU提高训练速度。
用Y表示MPLEC分类器的输出,对于多类MPLEC分类模型,定义:

2.3.2 离线训练与检验
为了在无线局域网上运行MPLEC识别算法,在选择机器学习方法时需考虑以下因素:
1)样本集建立开销。在MPLEC分类模型中,要减少部署所造成的开销,而且需要减少收集样本所需要的时间开销。如果条件不能满足的话,MPLEC分类模型所降低的开销会与这些开销相抵,MPLEC分类模型带来收益会降低或者无收益。
2)MPLEC识别算法的计算和存储开销。为了减少硬件的内存占用,需要将算法复杂度降低,当计算和存储开销降低时,MPLEC分类模型才有意义。
基于上述因素的考虑,本文使用卷积神经网络(Convolutional Neural Networks, CNN)[20-22]对MPLEC分类模型进行离线训练和检验。
卷积神经网络是一种包含卷积计算且具有深度结构的前馈神经网络。在卷积层,一个特性只由一个神经元所决定,连接数据窗的权重是固定的。卷积神经网络能直接学习输入与输出的映射关系,而且不需要给出它们之间所存在的数学关系式,只要有大量的数据进行训练,输入与输出之间的映射关系就会更强。
卷积神经网络采用原始图像作为输入,可以有效地从大量样本中学习到相应的特征,避免了复杂的特征提取过程,降低了网络模型的复杂度,减少了权值的数量。
本文在Matlab平台上对数据进行分类。首先对数据进行归一化处理,减少算法的复杂度。然后利用CNN对数据进行6种分类。本文采用数据挖掘领域常用的K-折交叉确认(K-fold Cross-Validation)对样本集进行训练和检验,用来减少因数据过拟合和存储空间过大所造成的后果,这里取k=10[23-24]。
2.4 分类结果分析
2.4.1 性能指标
本节比较分析MPLEC在准确率和开销方面的性能。
1)准确率。TP为样本中错误总数,TS为成功识别的样本数,TE为未成功识别或判断错误的样本数。准确识别的样本数量与样本总数的比值定义为:
2)开销。基于卷积神经网络的MPLEC分类器识别的计算和存储开销小,这是由它的算法复杂度造成的。
2.4.2 结果分析
1)数据包数量。
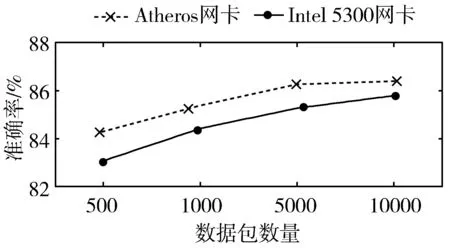
图12 数据包数量对分类准确率的影响
图12显示了发送的数据包数量对MPLEC分类器准确率的影响。可以发现,当数据包数量为10000时,准确率高达86.4%。当数据包数量为500时,准确率为84.3%。结果表明,数据包数量对分类器的性能影响不大。然而,分类器的性能随着数据包数量的减少而下降,因为数据包数量越少,在复杂的网络环境(如干扰冲突或移动障碍)中丢失的数据包越多。实验表明,在相同的网络配置环境下,分组数据包数量越少,分组接收到的RSSI值越小,CSI幅度变化越大,但其精度较高,因此MPLEC可以很好地进行分类。
在采集样本时,由部署或运行过程中所造成的时间开销小,易于在实际应用中实现。
2)时间间隔。
表3为时间间隔对MPLEC分类器性能的影响。可以看到,随着时间间隔的增加,即数据包传输速度降低,当发送5000个数据包时,MPLEC的分类精度变大,从84.35%提高到85.89%。当发送数据包时间间隔增大,即降低数据包发送速率时,降低了数据包出错的概率,降低了数据包丢失或其他情况引起错误的概率,从而更好地识别数据包出错的原因。它们的精度在83.44%以上,因此MPLEC可以区分数据包丢失和错误的原因。
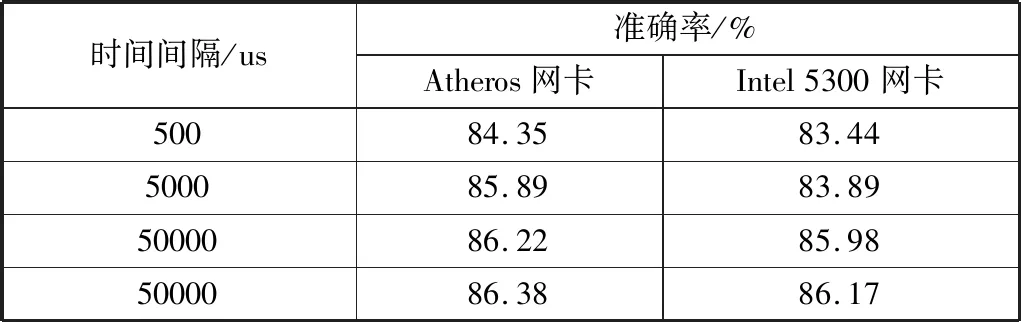
表3 时间间隔对分类准确率的影响
3)通信距离。
图13给出了距离对MPLEC分类器性能的影响。可以看出,当通信距离为3 m,使用Atheros网卡时,MPLEC的准确率为84.3%,距离为8 m时,准确率为86.4%。Intel 5300网卡也是一样的,正确率先高后低,大约84%。通过分析可知,当距离为最低和最高时,它们所处的实验场景更加清晰。当距离适中时,识别率较小。距离会使信道成为弱信道,而MPLEC只能识别这种分类。距离越远,越容易识别。
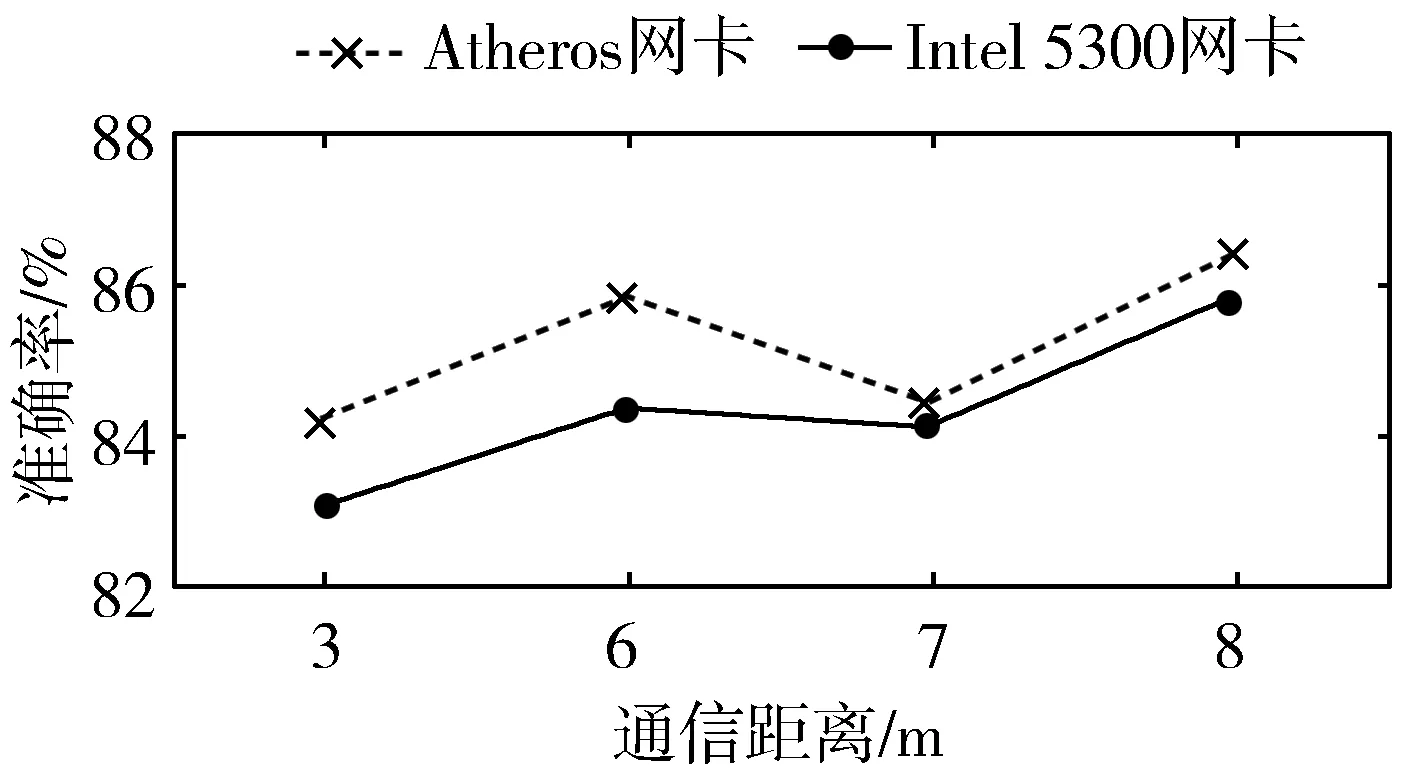
图13 通信距离对分类准确率的影响
3 MPLEC在CSMA/CA协议中的应用
本章将MPLEC分类结果应用到CSMA/CA协议中去,以验证MPLEC的识别性能。
3.1 CSMA/CA协议
在802.11无线局域网协议中,无线传输信号的性质决定了无线信道接收与发送信号时,无线网络中存在隐蔽站与暴露站的问题,使用CSMA/CA(载波监听多路访问/冲突避免)协议来完成无线局域网下的冲突检测和避免[22]。在CSMA/CA协议中,首先需要检测信道是否有使用,如果检测出信道空闲,则等待一段随机时间后,才送出数据。由于每个设备采用的随机时间不同,所以可以减少冲突的机会。如果接收端正确收到此帧,则经过一段时间间隔后,向发送端发送确认帧ACK。发送端收到ACK帧,确定数据正确传输,在经历一段时间间隔后,会出现一段空闲时间。为了避免冲突产生,使用到退避算法。
CSMA/CA协议只能避免数据帧的冲突,不能避免控制帧的冲突。与传统退避算法相比,采用深度学习可以降低网络模型的复杂度,利用CSI值和RSSI值来进行模型构建,可以更细粒度地区分丢包原因,减少控制帧的冲突,来提高重传率、时间利用率。
3.2 基于MPLEC的CSMA/CA协议
算法1给出了基于MPLEC的CSMA/CA协议的伪代码。其中Time Utilization为时间利用率,为实际传输时间除以总的时间,Retran_num为重传次数,New Packet Resending为数据包重传率。当信道出现衰落和冲突时,MPLEC识别模型对重传时间进行调整,与退避算法的结合,能够有效降低MPLEC错误识别的影响。
算法1基于MPLEC的CSMA/CA协议算法
输入:MPLEC的识别结果
输出:Time Utilization,New Packet Resending
1 Number of Nodes←100, PacketSize←1040,I←1,Retran_num←0。
2 发送数据,且检测到信道空闲,在等待时间DIFS后,就发送整个数据帧。
3 如果信道不是空闲状态,启动MPLEC识别模块。
4 若是信道碰撞、碰撞主导、干扰或干扰主导引起的分组丢失或错误,站点执行CSMA/CA协议的退避算法,记录当前模拟器时间。
5 当退避计时器时间减少到0时,站点发送整个的帧并等待确认,Retran_num的值加1。
6 若是弱链路或弱链路主导引起的分组丢失或错误,站点直接重新发送数据帧,Retran_num的值加1。
7 发送站若收到确认,则数据帧被目的站正确收到。这时如果要发送第二帧,就要从上面的步骤2开始,执行CSMA/CA协议的退避算法,随机选定一段退避时间。
8 如果在规定时间内没有收到确认帧ACK,就必须重传此帧,直到收到确认为止,或者经过若干次的重传失败后放弃发送,确定当前模拟器时间。
9 返回Time Utilization和Retran_num的值。
3.3 性能分析
时间利用率为实际传输时间除以总用时,即:
图14给出了基于MPLEC识别算法和传统退避算法的CSMA/CA协议在不同节点下传输成功的时间利用率。如图所示,本文基于MPLEC算法的CSMA/CA协议比传统退避算法的要好,最好情况下时间利用率能从92.8%提高到96.07%。这是因为当已知信道由于衰落造成错误,可以直接重传,而不需再次使用退避算法,只有当信道在碰撞场景下,使用退避算法才可以更好地发挥其长处。当节点数增多时,时间利用率会下降,因为发送数据帧会选择更合适的节点进行发送,造成时间延误。
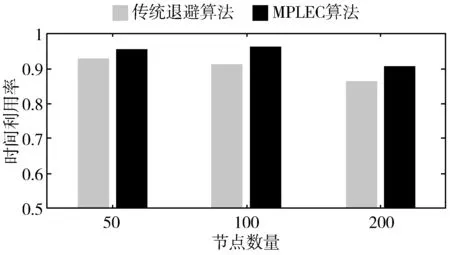
图14 时间利用率
图15为使用不同算法下CSMA/CA协议的数据包重传率。由图可知,基于MPLEC算法的CSMA/CA协议比传统退避算法的重传率要低。这是因为MPLEC识别模型对信道冲突和衰落进行了细分,给出导致当前分组和错误的主导因素,运用适合自己的算法,可以减少重传率。
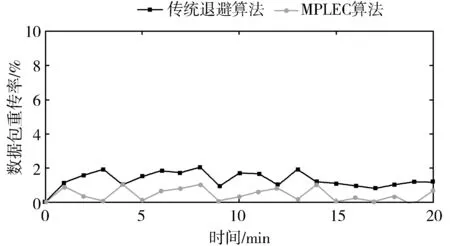
图15 数据包重传率
4 结束语
测试结果表明,多类MPLEC分类算法具有分类准确率高、开销小的特点。随着本算法的应用,能够提高分组丢失和错误原因识别的准确率,从而进一步提升链路层的传输效率。通过CSMA/CA协议验证了MPLEC识别方法的性能,实验结果表明,与现有方法[25]相比,使用MPLEC算法,提高了重传成功率和时间利用率。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
民用飞机设计与研究(2020年4期)2021-01-21
网络安全和信息化(2020年3期)2020-04-20
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
网络安全和信息化(2019年1期)2019-02-15
物联网技术(2018年8期)2018-12-06
初中生世界·九年级(2017年10期)2017-11-08
电脑爱好者(2015年15期)2015-09-10
