
结合HED网络和双阈值分割的GMM目标检测算法
2020-06-17 08:09王德忠
计算机与现代化 2020年6期
李 睿,王德忠
(兰州理工大学计算机与通信学院,甘肃 兰州 730000)
0 引 言
运动目标检测是计算机视觉领域中非常重要的研究内容,主要目的是提取出视频序列中的运动目标[1]。经典的目标检测方法有光流法、帧差法、背景建模法[2-3]。光流法是找到图像中每个像素点的速度矢量,通过各个像素点的速度矢量特征对图像进行动态分析,其缺点就是计算量较大、无法保证实时性和实用性[4-5]。帧差法是对时间上连续的2帧或者多帧进行差分运算,通过连续帧图像的相同位置像素点相减后的灰度差的绝对值与设定阈值的比较判断运动目标[6],其最大缺点是检测的目标轮廓不完整、内部含有空洞[7]。背景建模法的基本思想是对图像的背景进行建模,建立的背景模型与当前检测的视频帧进行比较,通过阈值确定前景目标[8]。常用的背景建模方法有:平均背景模型、非参数化背景模型、背景模型、VIBE算法、核密度估计方法、GMM算法[9-11]。
GMM算法是最常用的背景建模方法,可以获得更加理想的检测结果,也是当前目标检测研究的热点[12]。针对GMM算法的不足之处,研究人员对混合高斯模型算法提出了许多改进算法。文献[13]针对模型在背景更新时收敛性差、易受环境噪声、光照突变影响和易产生虚假目标等问题,提出了将帧差法引入GMM算法,快速区分背景区域和运动目标区域,消除虚假目标。文献[14]针对复杂背景下运动目标检测的问题,将视频帧的空间信息引入建模过程中,研究了邻域更新、二维联合直方图信息熵判别,提高了目标检测的准确性和完整性。文献[15]针对传统GMM算法检测耗时长、复杂度高、突发运动和光照敏感等因素的影响,结合GMM算法和六帧差分算法获得前景运动目标的轮廓,并且使用不同更新率自适应环境变化,该算法提高了检测目标的清晰度,有效地解决了噪声对检测结果的影响。
以上文献中的算法对GMM算法做出了改进,但是在以下环境中检测结果仍不理想:1)视频存在灯光,运动目标产生影子;2)运动目标较小,距离较远;3)运动目标颜色与背景颜色相似。以上外界因素的影响会导致误检率和漏检率较高。针对GMM算法中的上述问题,本文提出结合改进HED网络和三维OTSU双阈值分割的GMM算法。针对HED网络在目标边缘检测中的问题,提出一种改进的HED网络模型,通过三维OTSU算法对视频帧进行双阈值分割,将视频帧分割为背景、噪声、前景运动目标3个部分,不同区域选取不同模型个数。改进算法提高了检测准确性。
1 GMM算法
GMM算法是基于像素统计信息的概率密度模型[16-17],针对视频帧中的每一个像素点,计算该像素点的平均灰度值μ0和方差σ0,每个像素点定义K个高斯模型。K一般取值为3~5,通过加权和描述像素点的状态。各项表达式如下:
(1)
(2)
(3)
(4)
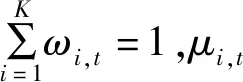
随着检测视频帧的变化,模型参数相应地进行更新,新观测值xt需要与当前存在的k(1kK)个高斯模型进行匹配,当|xt-μi,t-1|2.5σi,t-1,判定该像素点与模型匹配。对于没有匹配成功的模型,均值μ0和方差σ0不变,匹配成功的第i(1ik)个高斯分布,权值ωi,t、均值μ0和方差σ0通过以下公式更新:
ωi,t=(1-α)ωi,t-1+αMi,t
(5)
μi,t=(1-β)μi,t-1+βxt
(6)
(7)
其中,α(0<α<1)为用户自定义的学习率,α的大小决定了背景更新速度和抗噪声性能。β=αη(xt,μi,t,∑i,t)为参数学习率。
参数更新完成后,把K个高斯分布按ρi,t降序排列。选取前B个高斯分布作为背景像素的最佳描述模型。若像素值满足以下公式,则判定像素点为背景点,否则为前景点。其中,T为背景选取的阈值。
(8)
2 HED网络
HED网络是基于VGG网络修改而来,设计了5个侧边输出层,输出层的感受野在不断增大,语义信息也渐渐丰富[18-19],去除了VGG网络的全连接层。去除全连接层的HED网络可以输入任意大小的图片,降低了网络参数数目和计算复杂度,提升了运行效率。在训练过程中,HED网络改进了训练代价函数,由于边缘提取中轮廓线与非轮廓线的像素数有着巨大的差异,使得使用正常的损失函数进行训练会造成模型的不稳定,HED网络对边缘位置损失函数的系数进行了放大,损失函数如下;
(9)
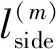
(10)
其中,β=|Y-|/|Y|,1-β=|Y+|/|Y|。|Y-|、|Y+|分别表示边缘和非边缘的像素由侧边输出的响应值,通过逻辑回归函数计算可以得到:
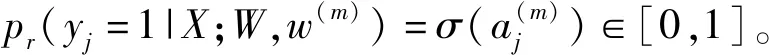
Lfuse(W,w,h)=Dist(Y,Yfuse)
(11)
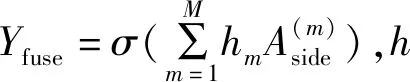
(W,w,h)*=arg min (Lside(W,w)+(W,w,h))
(12)
3 OTSU阈值分割
OTSU阈值分割的核心思想是通过阈值将图像分为前景目标和背景图像[20-21],并计算两者的最大方差为最佳分割阈值[22-23]。假设一幅图像大小为m×n,图像灰度级的取值范围为[0,L-1]。像素点(x,y)的灰度值为h(x,y),在k×k的邻域内该像素点的平均灰度值为f(x,y)。假设h(x,y)=i、f(x,y)=j,qij为像素点(x,y)出现的次数,则qij的联合概率密度为:
(13)
假设D0和D1分别表示背景区域和目标区域,ω0和ω1分别表示D0和D1的概率,μ0和μ1分别表示D0和D1的均值矢量:
(14)
(15)
(16)
(17)
图像的总均值矢量为:
(18)
类间离散度矩阵为:
SB(s,t)=ω0(μ0-μ)T(μ0-μ)+ω0(μ1-μ)T(μ1-μ)
(19)
当Tr(SB(s,t))取最大值时,可获得最佳阈值:
(20)
4 结合HED网络和双阈值分割的GMM算法
HED网络在卷积主干网络上增加多个输出层,在输出层进行深度监督,从而得到不同尺度对应的边缘,由于高层图分辨率过低,很容易丢失目标的部分轮廓信息。过多的池化层导致侧边输出边缘检测结果宽度过大,与低层融合时会引入较多的内部纹理信息,针对这个问题,去掉第4层池化层,针对轮廓信息丢失严重的问题,选取了局部能量函数计算出中心点与边缘点重合时局部能量的最大值。改进的HED网络结构如图1所示。
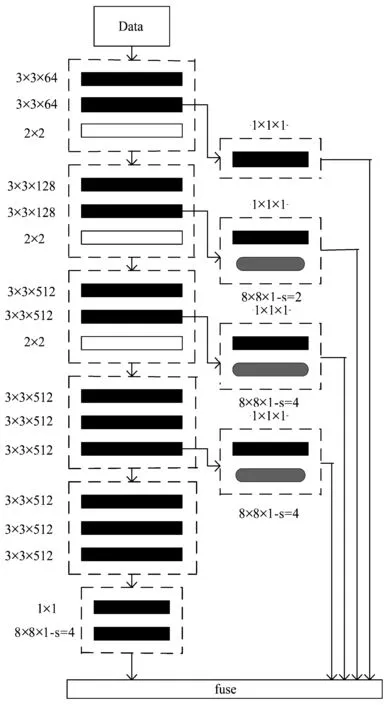
图1 改进的HED网络结构
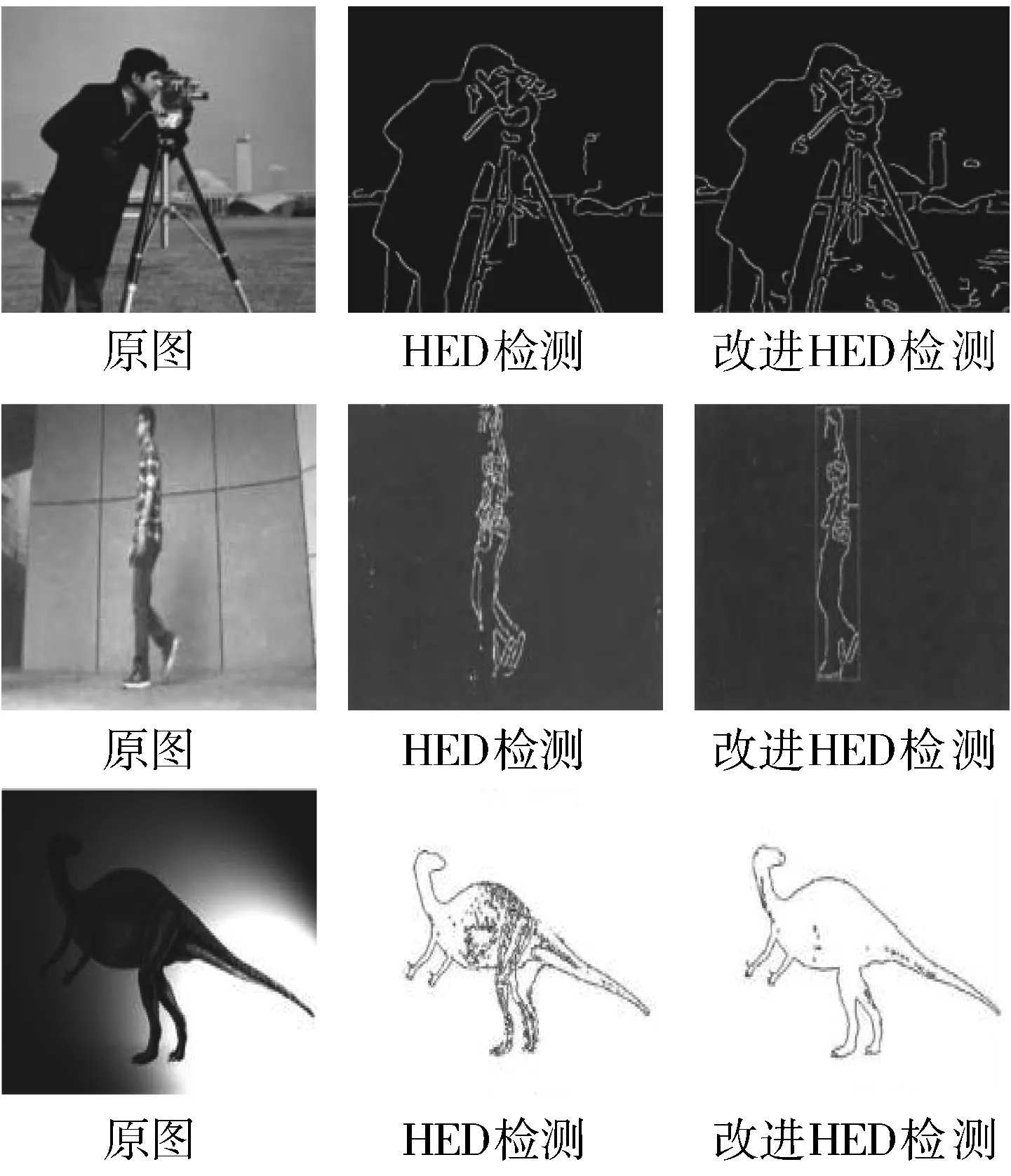
图2 边缘检测对比图
减少了池化层使得降采样次数也降低了,侧边输出层的图像分辨率更高,通过局部能量函数的最大值快速准确地确定边缘位置,解决了HED网络在边缘检测中轮廓模糊的问题,从而得到了更好的检测效果。边缘检测图如图2所示。
在传统二维OTSU算法中,只考虑了背景和运动目标的概率,将噪声和边缘的概率之和近似为0,忽略了噪声和边缘的影响。然而,噪声是影响图像分割的关键因素,如果不能对噪声进行有效的分割和抑制,就会出现将背景检测为前景运动目标的现象。根据背景、噪声、运动目标将视频帧H分为3个部分。其中,背景图像为X、噪声为Y、前景运动目标为Z。视频每一帧图像大小为m×n,灰度级为L,其中某一像素点(x,y)的灰度值为h(x,y),在k×k的邻域内该像素点的平均灰度值为f(x,y),灰度中值为g(x,y),灰度取值均为0~L-1。以h(x,y)、f(x,y)和g(x,y)组成的三元组(i,j,k)出现的概率为pi,j,k。各项定义如下:
H=X+Y+Z
(21)
(22)
(23)
(24)
其中,qi,j,k(0i,j,kL-1)代表频数。
背景X、噪声Y和运动目标Z发生的概率分别为pX、pY、pZ,定义为:
(25)
(26)
(27)
三者的均值矢量为:
μX=(μXi,μXj,μXk)T
(28)
μY=(μYi,μYj,μYk)T
(29)
μZ=(μZi,μZj,μZk)T
(30)
总体均值为μT=(μTi,μTj,μTk)T:
(31)
背景X与噪声Y、噪声Y与运动目标Z之间的类间离差定义为:
S1=pX[(μX-μT)(μX-μT)T]+pY[(μY-μT)(μY-μT)T]
(32)
S2=pY[(μY-μT)(μY-μT)T]+pZ[(μZ-μT)(μZ-μT)T]
(33)
trS1=pX[(μXi-μTi)2+(μXj-μTj)2+(μXk-μTk)2]+
pY[(μYi-μTi)2+(μYj-μTj)2+(μYk-μTk)2]
(34)
trS2=pY[(μYi-μTi)2+(μYj-μTj)2+(μYk-μTk)2]+
pZ[(μZi-μTi)2+(μZj-μTj)2+(μZk-μTk)2]
(35)
最优阈值为trS1和trS2取得最大值,trS1为背景X与噪声Y分割的最佳阈值,trS2为噪声Y和运动目标Z分割的最佳阈值。定义如下:
(36)
(37)
基于此,提出了结合改进的HED网络和三维OTSU双阈值分割的GMM算法。改进的HED网络结合局部能量对视频帧进行边缘检测,能够有效地抑制边缘断裂和毛刺,引入双阈值作为判断背景、噪声和运动目标3个部分的条件,根据不同的分割类型调整高斯分布的个数。将两者检测的结果融合后进行形态学“与”处理,从而最终得到检测结果。模型流程图如图3所示。
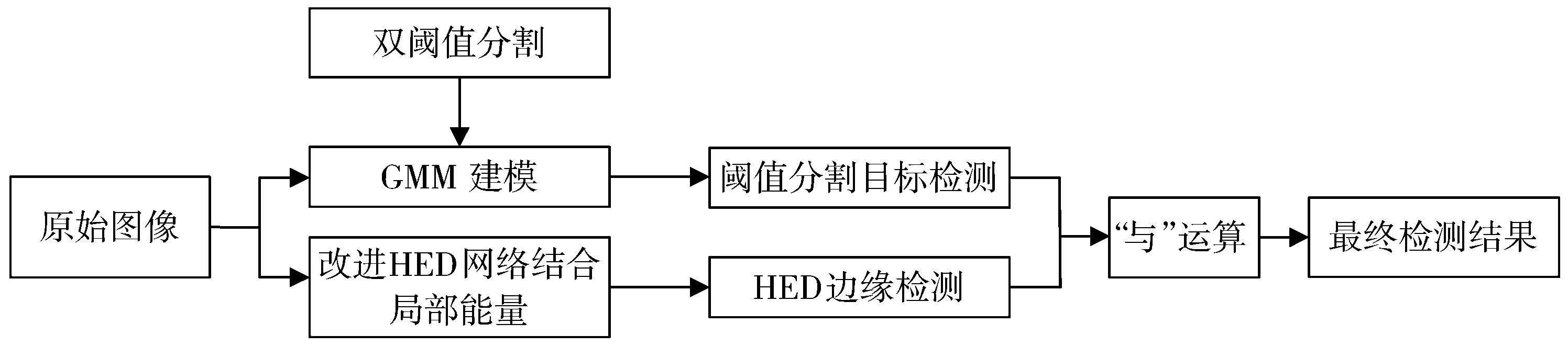
图3 模型流程图
算法描述如下:
步骤1模型初建时,计算出视频前N帧的像素点的平均值以及方差,并且对视频帧中的每一个像素点构造出K个高斯模型。
步骤2计算某一像素点的灰度值、平均灰度值、灰度中值。通过二维OTSU双阈值分割确定背景与噪声最佳的分割阈值、噪声和运动目标的最佳分割阈值,通过分割阈值确定出检测序列中每一个像素点所需要的高斯模型个数,对已经建立的高斯背景模型进行更新。
步骤3改进的HED网络结合局部能量对视频帧进行运动目标的边缘检测,提取了包含高层语义信息的显著性边缘,引入局部能量能够有效地抑制边缘断裂和毛刺,消除细毛刺对边缘检测结果的影响。
步骤4通过双阈值分割的GMM检测结果和HED网络的边缘检测进行“与”运算,得到比较完整的运动目标。经过填充处理完善后得到最终检测结果。
5 实验及结果
实验环境:Windows7 Inter(R) core(TM) i3 CPU M380@2.53 GHz、内存为2 GB的PC,编程软件为:Matlab(2015b),本文算法中参数学习率为β=0.0062,高斯模型的最大个数为K=5。

图4 视频1检测结果对比
在视频1中,目标由静止到缓慢移动的过程中,运动过程受到室内灯光和光滑平面对光线反射的影响。通过图4所示的对比结果可以看出,文献中的算法较GMM算法检测效果较好,但是检测结果中均出现空洞,目标检测不完整的现象,本文算法检测的目标更完整,漏检率更低。
视频2中有多个运动目标,而且运动目标是快速地通过监控区域,在运动的过程中,运动目标受到太阳光照的影响,在路面上形成影子。通过图5中实验结果对比发现,GMM算法在检测过程中,不能有效地抑制影子的干扰,还将车辆中的玻璃部分检测为背景。相比于GMM算法,文献中的算法更好地抑制了误检现象,但是更容易受到地面运动目标影子的干扰,目标检测的误检率较高。通过本文算法的检测结果发现,不仅有效地检测出了运动目标,并且抑制了阴影的干扰,降低了误检率。
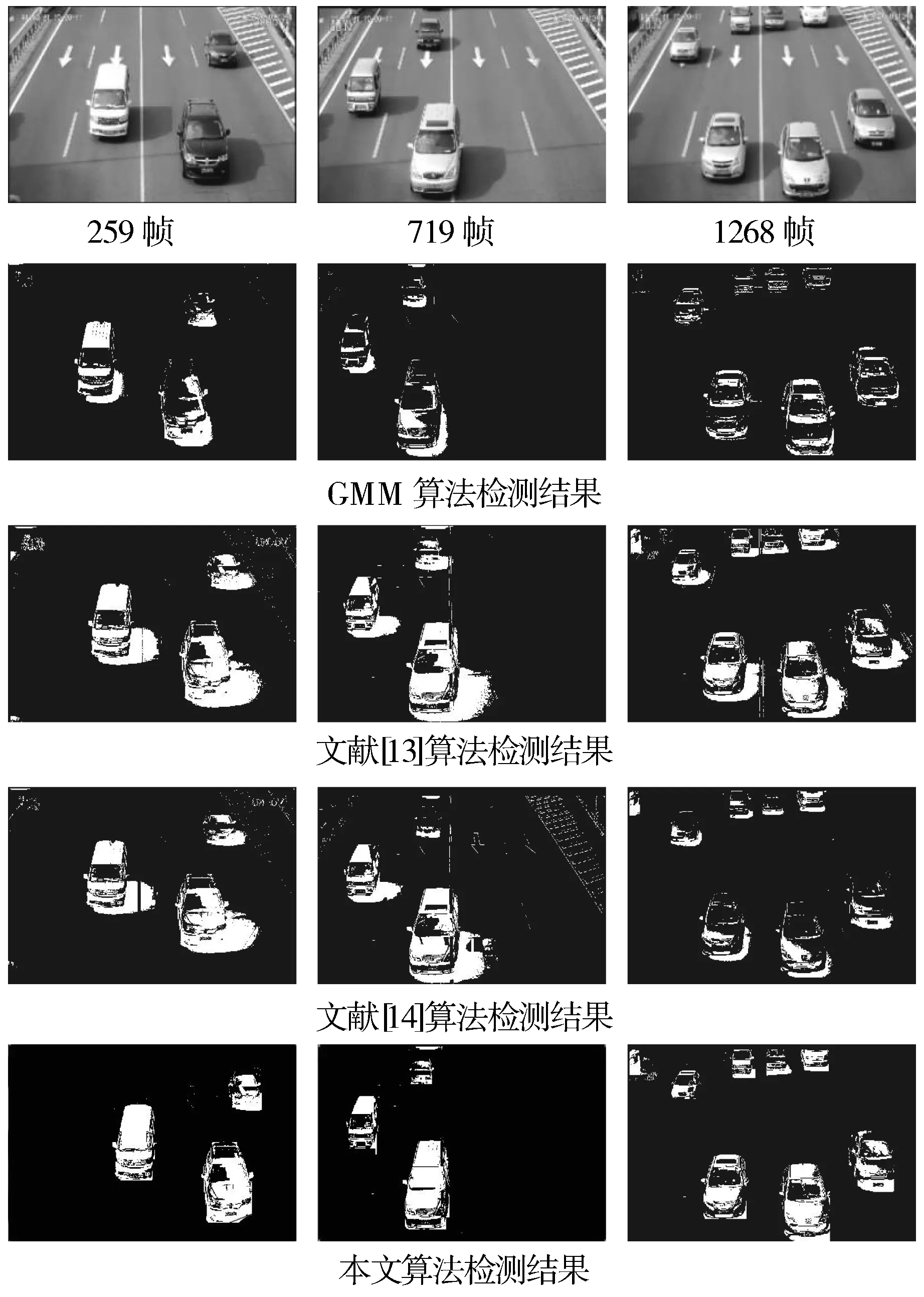
图5 视频2检测结果对比
视频3序列是从上方拍摄的,由于拍摄高度较高,视频中的运动目标较小,视频的第100帧和第215帧是单独一个人行走时截取的,第383帧是2个人握手时截取的视频画面。原视频中显示2个人的胳膊不明显。通过图6中视频序列的对比结果可以发现,第100帧画面中行人的衬衣的颜色和地面颜色相似,GMM算法和文献中的算法将运动目标误检为背景,GMM算法对行人的胳膊没有有效地检测出来。文献[13]和文献[14]中的算法虽然检测出来胳膊,但是检测的轮廓不完整,漏检率较高。本文算法有效地分割了目标和背景,抑制了颜色相似的干扰,在行人行走和2个人握手时,完整地检测出运动目标的胳膊,提高了检测的准确率。

图6 视频3检测结果对比

图7 视频4检测结果对比
视频4中,运动目标(人)缓慢运动,截取第242帧、457帧、749帧分别用混合高斯模型算法、文献[13]算法和[文献]14算法与本文算法进行检测比较。通过图7中视频序列的对比结果来看,GMM算法只检测出运动目标颜色和背景颜色相差较大时的目标轮廓,而完全漏检了目标的整个下半部分。文献[13]算法和文献[14]算法虽然完全检测出了目标轮廓,但是受到目标与运动背景颜色相似的影响较大,检测结果出现空洞。本文算法完整地检测出运动目标的轮廓,基本没有受到颜色相似的干扰。
评价本文算法的标准有很多,为了直观地进行分析,本文对检测结果进行量化处理,采用衡量目标检测的性能指标:检测耗时、识别率DR和误检率FAR。表达式如下:
(38)
(39)
其中,TP为检测出的属于真实前景的像素数,FN和FP分别为未检测出的和错误检测出的前景像素数。对每一帧图像进行多次检测后,不同算法在不同视频上的各项平均指标如表1所示。
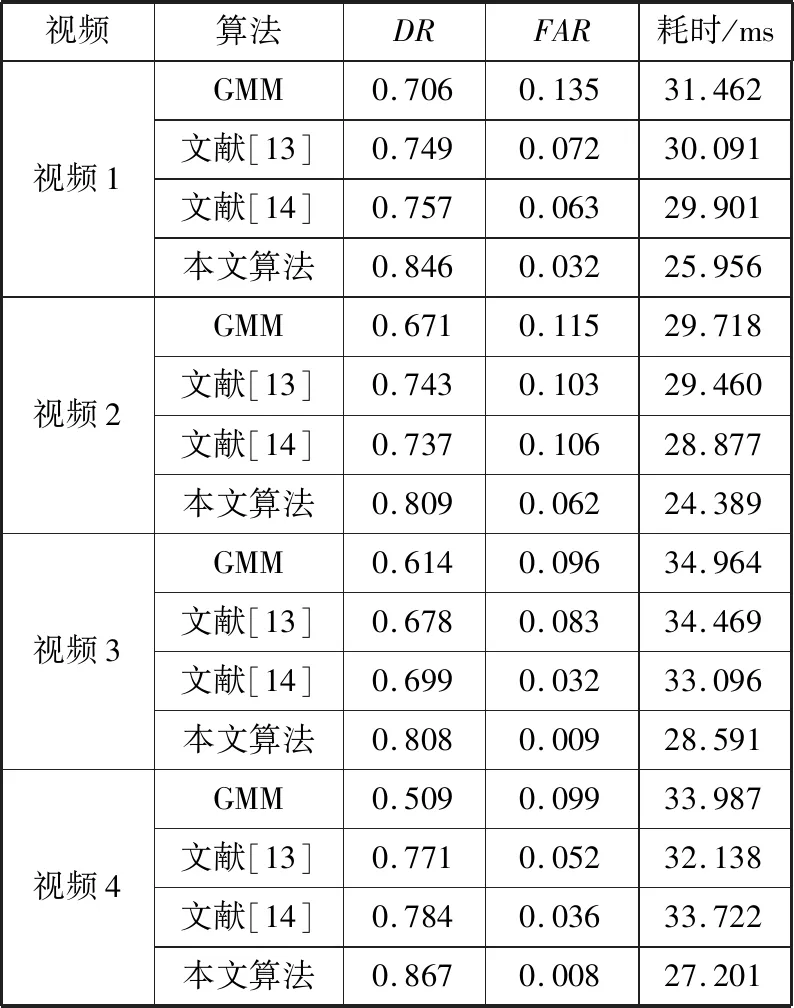
表1 不同算法检测性能指标
6 结束语
从表1可以发现,在选取的每一个视频的每一帧中,相比于GMM算法、文献[13]算法、文献[14]算法,本文算法的识别率、误检率均有所改进,检测耗时更低。本文算法比GMM算法和文献[13-14]中的算法更加有效的原因在于:
1)传统GMM算法在描述每一个像素点状态时均采用3~5个高斯模型,变化较大的区域应该需要较多的高斯分布描述,而变化较小的区域需要较少的高斯分布个数,GMM算法中固定的模型个数不仅浪费了计算机运算资源还导致算法实时性较差。通过改进三维OTSU双阈值分割有效地抑制了噪声干扰,根据不同的变化区域阈值选取不同的高斯模型个数,缩短了算法的检测时间,提高了实时性。
2)改进的HED网络结合局部能量边缘检测有效地检测出运动目标的边缘,能够准确地识别小目标运动状态,抑制了由于颜色相似引起的漏检现象。改进算法有效地解决了GMM算法中常出现的问题,提高了检测准确率、降低了检测耗时。
3)三维OTSU进行双阈值分割,克服了GMM算法单阈值分割无法抑制背景噪声的干扰;解决了背景与前景运动目标误检问题;克服了检测轮廓不完整、检测出现空洞的问题。
接下来的工作重点是算法如何克服摄像头拍摄时受到恶劣天气和摄像机抖动等因素的影响,在恶劣环境下提高算法鲁棒性、实时性、检测准确率,同时降低算法复杂度、误检率和漏检率。
猜你喜欢
汽车工程师(2021年12期)2022-01-17
现代电子技术(2021年1期)2021-01-17
当代陕西(2020年14期)2021-01-08
奥秘(创新大赛)(2020年7期)2020-07-27
制造技术与机床(2019年9期)2019-09-10
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
