
基于CNN-LSTM的用户购买行为预测模型
2020-06-16 10:40胡晓丽张会兵董俊超吴冬强
计算机应用与软件 2020年6期
胡晓丽 张会兵 董俊超 吴冬强
1(桂林电子科技大学教学实践部 广西 桂林 541004)
2(桂林电子科技大学广西可信软件重点实验室 广西 桂林 541004)
3(南宁地精科技有限公司 广西 南宁 530000)
0 引 言
网民在电商平台上选购商品的过程中伴随着浏览、收藏、放入购物车等各种在线操作行为。当前,在电商平台上沉淀了海量的用户购物历史数据,深入分析这些数据能够较好预测其购物习惯、偏好或购物意愿。特别地,对用户购买行为进行预测有助于提升用户购物体验,促进电子商务可持续发展[1]。
用户购买行为预测是国内外诸多学者关注的热点[2-6]。文献[3]使用决策树与神经网络方法挖掘用户购物历史行为数据,预测用户是否会购买他们已经添加到购物车里的商品。曾宪宇等[4]针对海量在线消费行为数据准确预测兴趣偏好和购物行为,提出融合了潜在因子和行为序列的效用函数选择模型,与逻辑回归(Logistic Regression,LR)和梯度提升决策树(Gradient Boosting Decision Tree,GBDT)相比,该模型有更好的精确度和有效性。Liu等[5]利用大量的用户浏览、点击、购买等行为数据,通过支持向量机(Support Vector Machine,SVM)对未来网络消费者的购买情况进行预测,得到了满意的结果。祝歆等[6]融合逻辑回归和支持向量机构建了网络购物行为预测模型,取得了比单一模型更好的预测效果。
随着电商平台中行为数据的日益增加,应用传统机器学习算法的特征构造和选择需要花费时间与人力急剧增加,并且不同的电子商务平台中数据的格式和内容有所不同,使得算法的移植性受限。同时,对用户购买行为的独立性假设也与用户购买的实际情况不符,导致其不能准确预测不同时间段的用户购买行为。
为此,提出一种CNN-LSTM神经网络组合模型来预测用户购买行为。首先使用卷积神经网络层CNN从用户历史行为数据中自动抽取高影响力的特征,然后通过长短期记忆神经网络LSTM建立时间序列预测模型[7-9],最后通过全连接层(Fully Connected Layer,FC)输出模型预测结果。以此实现特征自动抽取和基于行为序列的用户购买行为预测。
1 CNN-LSTM购买行为预测模型
1.1 预测模型框架
图1为融合用户属性、商品属性和用户行为特征的预测用户购买行为的CNN-LSTM模型总体架构[8,15]。数据处理和特征构建完成用户历史行为数据清洗,剔除刷单用户、重大促销等不具有一般规律的数据,并采用分段下采样方法进行样本均衡处理;CNN层接收影响用户购买行为的各种特征,如浏览数、购买数、浏览购买转化率等,进行特征选择和特征优化;LSTM依据CNN提取的用户购买行为序列中的重要特征进行用户购买行为预测;全连接层把LSTM单元输出的高维用户购买行为信息压缩为相应的特征向量,实现对用户购买行为的分类表达。

图1 CNN-LSTM用户购买行为预测模型
1.2 在线交互行为样本均衡与特征构建
(1) 在线交互行为样本均衡。用户与商品的在线交互过程中,只有极少部分浏览行为会转化为购买行为,出现购买样本与未购买样本极度不均衡的问题[10]。目前,解决样本不均衡问题的主流方法是上采样和下采样[11]。然而,上采样方法很难适应电子商务中用户-商品交互数据结构复杂、数据量大的特点;下采样方法因为数据倾斜和信息丢失也不适合解决此类问题。为此,设计了如算法1所示的分段下采样方法[11-12]:根据用户购买行为预测样本数据具有时间衰减的特性,将购买用户和未购买用户历史数据样本以天为单位进行分段。针对用户样本中的每个用户找出其三个最近邻用户,若该用户是未购买用户且其三个最近邻用户中有两个以上是购买用户,则删除它;反之,当该样本是购买用户并且其三个最近邻中有两个以上是未购买用户,则去除最近邻中的未购买用户,其余情况均保留原始用户样本。
算法1分段下采样样本均衡算法。
输入:用户原始历史数据(D),数据记录天数(T);
输出:新用户平衡历史数据(D′);
算法流程:
1: D′=D/T
//对原始数据按照数据记录天数进行分段
2: for D(u)∈D′ do
//遍历原始数据中的每个用户
3: D′(u)=RandomChoose(D(u))
//随机选择任意用户数据
4: if D′(u)为购买用户then
5: //判断D′(u)最近邻中是否有两个以上未购买用户
if no-buy=sum(KNN(D′(u)))≥2 then
6: //删除最近邻中的未购买用户
delete(KNN(D′(u))no-buy)
7: else
8: save(D′(u))
//保留新用户数据
9: else
10: if buy=sum(KNN(D′(u)))≥2 then
11: //删除新用户
delete(D′(u))
12: else
13: save(D′(u))
//保留新用户数据
(2) 在线交互行为特征构建。分析京东商城等的交互数据发现:用户行为数据分散在用户属性、商品信息、用户对商品的行为等处[13-14]。原始数据中可用的特征数量极少,直接用于CNN-LSTM模型无法有效预测用户购买行为。为此,运用统计分析构建出如表1所示的用户购买行为预测特征。然后,将该特征输入到CNN-LSTM模型中,CNN自动进行用户历史购买行为的特征提取,可以有效简化传统机器学习中特征提取和特征选择过程[7]。

表1 用户购买行为预测特征
1.3 CNN-LSTM组合的购买行为预测
CNN由接收用户历史行为特征的输入层、对接LSTM输入层的输出层以及多个隐藏层组成。其中,隐藏层包括卷积层和池化层,如图2所示。

图2 CNN-LSTM模型中CNN层
(1)

用户行为特性经过卷积操作后,传入池化层中进一步减少参数数量,压缩数据维度,减少过拟合。用式(2)的最大池化方法筛选出对用户购买行为影响最大的特征信息,实现用户购买行为预测。
(2)
式中:T为池化区域的步长;R是池化尺寸。
LSTM接收CNN提取的重要特征向量序列,通过遗忘门、输入门和输出门改变细胞状态,更新以前隐藏状态的内存单元来保持用户历史购买行为信息持续存在,更准确地预测了用户购物行为[16-17]。LSTM单元结构如图3所示。

图3 LSTM单元结构图
门控单元中的各个门和记忆细胞的表达式如下:
外部输入门单元表达式:
(3)
遗忘门单元表达式:
(4)
细胞内部状态更新表达式:
(5)
输出门单元表达式:
(6)

CN-LSTM模型的最后一层为全连接,该层将LSTM单元输出的高维用户历史购买行为信息压缩为一个特征向量hI={h1,h2,…,hn},进行用户-商品对的分类,预测用户是否会购买某种商品,其函数表达式如下:
(7)

基于CNN-LSTM模型的用户购买行为预测算法如算法2所示。
算法2基于CNN-LSTM模型的用户购买行为预测算法。
输入:用户属性数据(U)、商品属性数据(M)和用户对商品的行为数据(B);
输出:用户-商品对(U-M),是否购买(buy)(1:表示购买,0:表示未购买);
算法流程:
1: read date={U,M,B}
//读取输入数据,构建用户行为特征
//构建用户行为特征
3: //根据样本均衡算法进行用户购买行为数据样本均衡
U*=choose(U)
4: //设置卷积核数量为32,卷积尺寸3,根据式(1)进行卷积操作,得到特征向量矩阵
Cu=ReLU(Convolution(32,3,3))
5: //设置池化层尺寸为2,根据式(2)进行池化操作,特征
//降维得到新特征向量Cu*
Cu*=MaxPooling(3,3)(Cu)
6: //根据式(3)到式(6)进行LSTM层训练,得到特征向
//量矩阵Lu*
Lu*=LSTM(output=128,activation=′tanh′)(Cu*)
7: buy=softmax(Lu*)
//根据式(7)进行用户购买行为分类
2 实 验
2.1 数据集
本文选用天池大赛中阿里巴巴移动电商平台数据集进行测试,包括11月18日到12月18日的2 084 859条用户历史购买行为数据:包含用户标识、商品标识等6个字段,19 972个用户,1 054种类的422 858件商品,对12月19日用户对商品的购买行为进行预测[14]。其中,行为信息有浏览、收藏、加购物车、购买四种方式。对清洗后的数据字段进行组合优化,删除用户行为时间、商品位置与用户位置字段,增加购买浏览转化率、购买收藏转化率、购买加购转换率三个与用户购买行为密切相关的3个字段,优化后的数据字段如表2所示。

表2 测试数据字段
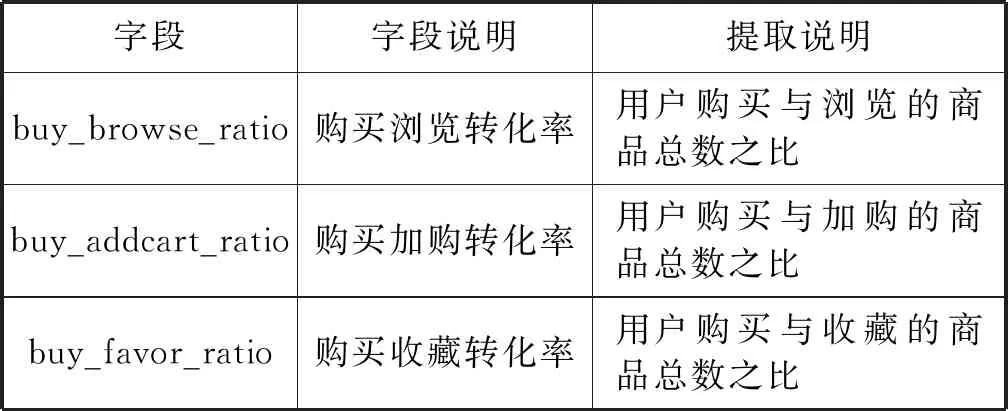
续表2
2.2 评估指标
这里采用精确率P、召回率R和F1值三个指标来评估预测模型性能。根据样例真实类别与CNN-LSTM预测类别组合划分为真正例(TP)、假正例(FP)、真负例(TN)、假负例(FN)四种类型,混淆矩阵如表3所示。预测结果在主对角线上取值越大,副对角线上取值越小的模型越好。将混淆矩阵数字化后即为精确率P、召回率R和F1值,计算公式分别为:
(8)
(9)
(10)
2.3 实验结果与分析
(1) CNN-LSTM模型验证。为了验证CNN-LSTM模型的性能,我们将CNN-LSTM模型与5种基线模型进行比较。参数设置如表4和表5所示。

表4 机器学习算法参数设置

续表4
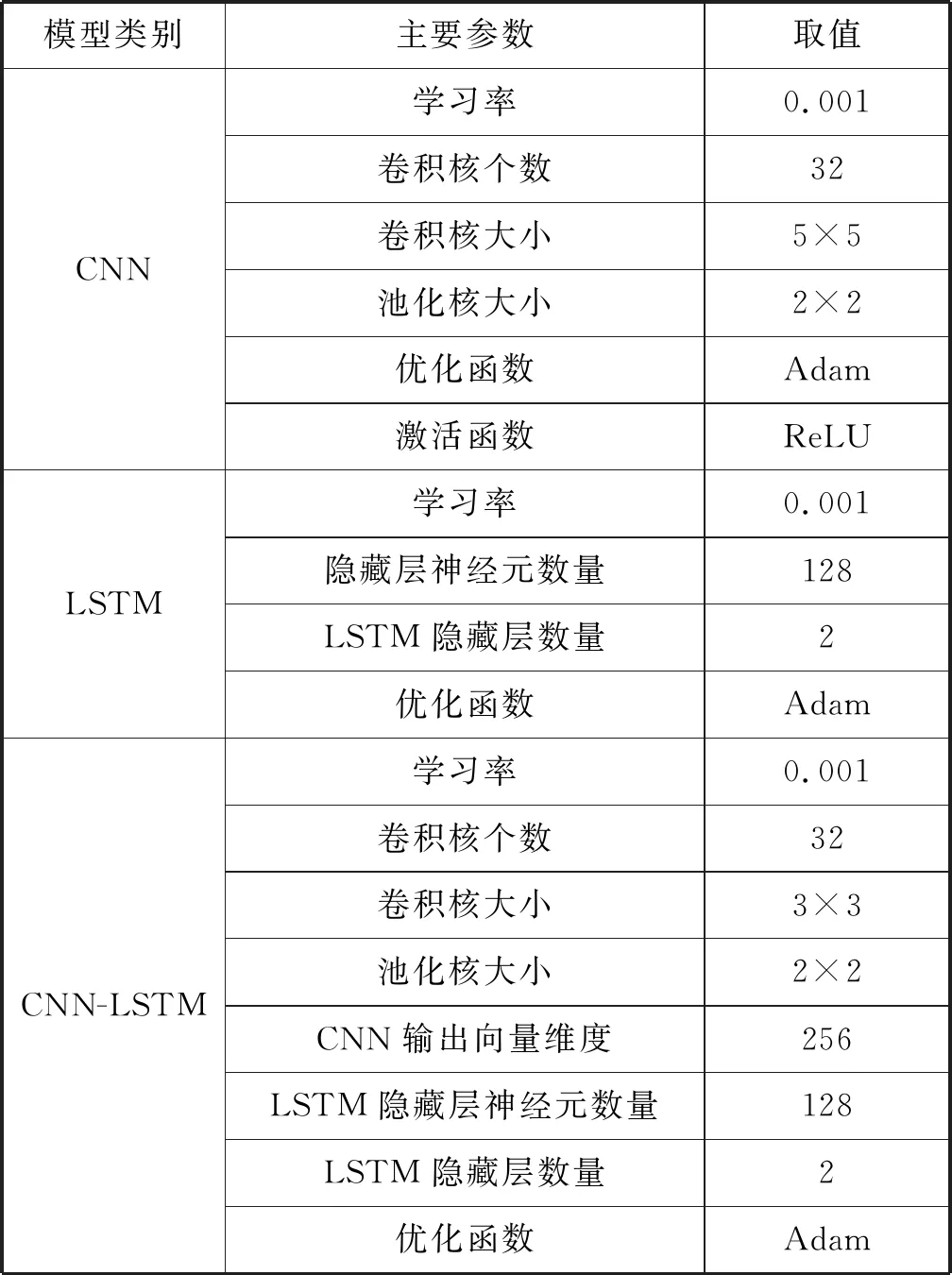
表5 神经网络参数设置
为了保证实验数据的准确和客观,将每个模型在同一训练和测试数据集上分别运行10次,求得精确率、召回率和F1值的平均值作为模型最终结果,所得结果如表6所示。

表6 六种用户购买行为预测模型精确率、召回率和F1值对比
从表6中的实验结果可以看出,基于CNN-LSTM模型的F1值在训练集和测试集中均高于其余基准模型,其原因主要为该模型集成了CNN在网络特性提取、特征选择方面和LSTM记忆机制处理时序模型方面的优势。XGBoost模型的F1值优于CNN模型,低于LSTM模型的F1值,主要原因为XGBoost是一种集成很多弱分类器的强分类器,在很多数据挖掘相关比赛中的表现多次优于神经网络。此外,LSTM模型的表现优于CNN和XGBoost模型的主要原因与本次的实验数据选择密切相关,本次采用的数据集是用户购买行为一个月的历史数据,属于标准的时序数据,LSTM模型较其余基准模型更适合时序数据的分析和预测。
从表6中可见,6种模型在训练数据集上的F1值均优于其在测试数据集上的F1值。主要原因是模型仅仅在测试数据集寻找购买行为的样本,其中有部分在12月19日购买的用户为新进用户,在训练集中的11月18日到12月18日(除11月11日外)一个月时间之内没有该用户购买历史记录,模型预测将其预测为未购买用户,导致模型预测结果的召回率降低,F1值也随之下降。
为了更直观地验证CNN-LSTM模型的稳定性,将六种模型的10次训练数据集的F1值画出折线图分析波动幅度,如图4所示。

图4 六种模型F1值变化曲线
可以看出,CNN-LSTM模型与支持向量、随机森林和CNN模型在预测效果上有明显优势。LSTM和XGBoost模型偶尔一次的F1值会优于CNN-LSTM模型,然而LSTM和XGBoost模型的F1值跟随实验次数波动较大对于整体效果而言,CNN-LSTM模型处于高F1值的区间小幅度波动,模型稳定性较好。
(2) “分段下采样”样本均衡算法验证。图5为6种模型样本均衡前后的F1值对比结果,可以看出,经过分段下采样样本均衡算法的六种模型的F1值均有不同程度的提升。其中支持向量机、随机森林、XGBoost、CNN、LSTM这5种模型的F1值提升比较明显。实验结果表明,使用分段下采样的样本均衡算法对样本不均衡的用户行为历史数据进行均衡处理,对提升用户购买行为的预测准确率有一定作用。

图5 六种模型样本均衡前后F1值对比
3 结 语
本文基于CNN-LSTM模型对用户购买行为进行预测,与现有的购买行为预测模型相比,简化了特征选择过程,提高了模型准确性和稳定性。分段下采样样本均衡算法有效解决了电商平台中购买样本与未购买样本极度不均衡的问题,提升了CNN-LSTM模型预测的准确率。然而,目前的模型尚未考虑用户性别、年龄、商品评论以及“双十一”“六一八”重大促销活动等信息对用户购买行为的影响。在后续研究中,我们将构建一种能够包含更多上述信息的用户购买行为预测模型,使其预测更精准、实用。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
小学生学习指导(低年级)(2018年11期)2018-12-03
领导决策信息(2018年16期)2018-09-27
中学生数理化(高中版.高一使用)(2018年1期)2018-02-10
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
理科考试研究·高中(2016年10期)2017-01-17
