
基于共享机制的自适应超启发式算法求解区域化低碳选址—路径问题
2020-06-13 12:52:38冷龙龙赵燕伟张春苗
计算机集成制造系统 2020年5期
冷龙龙,赵燕伟+,张春苗,2
(1.浙江工业大学 特种装备制造与先进加工技术教育部重点实验室,浙江 杭州 310023;2.嘉兴职业技术学院 机电与汽车分院,浙江 嘉兴 314036)
0 引言
在供应链管理和物流系统规划中,选址—路径问题(Location-Routing Problem, LRP)是重要的组合优化问题之一,其在优化物流配送成本与效率、客户满意度和环境问题中发挥着重要作用。作为LRP最热门的变体,低碳LRP(Low-Carbon LRP, LCLRP)[1]综合考虑了CO2等温室气体的车辆路线规划和仓库选址。近年来,考虑环境因素的路线规划和选址分配问题的仿真优化对经济、社会和环境越来越重要,本文针对考虑环境因素的LRP构建数学模型,以降低配送过程中的燃料消耗和CO2等温室气体的排放量,优化配送成本和效率。
道路速度限制在确保公众安全方面发挥着重要作用[2]。大多数城市采用的特定路段限速方式一般可以简化为具有不同速度区域的特殊情况[3],速度区域化可以更加安全有效地调节交通流量,并合理平衡驾驶员和行人的公共道路需求与区域居民的关注点[4]。另外,研究表明通过合理的限速方式设置速度区域有利于减少超车现象、交通拥堵和事故[5]。区域化LCLRP(Regional LCLRP, RLCLRP)的主要特征为客户和仓库位于速度限制不同的嵌套区域,目标是降低物流成本,包括仓库成本、车辆成本和路径成本,路径成本为燃油消耗和CO2排放成本,通过最小化物流成本可以达到降低碳排量的目的。
针对RLCLRP,本文提出一种基于共享机制的自适应超启发式求解算法,即通过共享底层算子的近期性能信息自适应地选择优质合适的底层算子,并提出一种自适应解的接收机制以提高算法的收敛速度和精度。最后通过仿真验证了所提算法的有效性和鲁棒性。本文的主要贡献与创新如下:①从模型层面,首次考虑多车型、同时取送货和区域化速度等实际约束对碳排放的影响,并构建多车型同时取送货的RLCLRP(RLCLRP with Simultaneous Pickup and Delivery and Heterogeneous Fleet, RLCLRPSPDHF)模型;②从算法层面,设计了一种基于共享机制的自适应超启发式求解算法,并提出一种自适应接收机制;③评估车型构成、仓库和客户分布等因素对碳排放和总成本的影响及其比重,为企业提供了应对统筹规划配送决策的管理指导与建议。
1 相关工作回顾
LRP集成了两类经典NP-hard问题,即选址—分配问题(Location-Allocation Problem, LAP)和车辆路径问题(Vehicle Routing Problem, VRP)[6],目前已经成为运筹学管理与城市货物运输网络优化的重要工具和研究热点之一,如物品回收和危险废物管理等[7-8]。LCLRP是以降低物流配送中产生的碳排放等温室气体为目标的LRP问题,同样融合了LAP和污染路径问题(Pollution Routing Problem, PRP)/绿色VRP(Green VRP, GVRP)两类NP-hard问题,这两类问题着重考虑货物运输产生的碳排放量对社会和环境的影响。
为了降低货物运输碳排放量,需要采用评估碳排放量的数学模型,根据模型性质选择合适的碳排放模型的类型,因此提出多种模型估算车辆的燃油消耗并将其最小化。表1所示为10种估算碳排放的模型,包括模型与文献来源,这几种模型涉及道路状况、车辆参数、自然环境和负载状况4类影响碳排放的因素,其中道路状况考虑了道路拥堵情况与道路特征(坡度等),车辆参数主要有车辆的尺寸、自重和发动机参数,自然环境主要是天气状况,此外驾驶员水平和习惯也是一种重要的影响因素。有关估算CO2等温室气体排放的数学模型可参阅文献[9-12]。实际上,考虑所有影响因素来建立车辆的油耗模型十分困难且没有必要[1],本文研究多车型同时取送货与区域化的LCLRP,即考虑多车型、同时取送货和速度区域化等实际约束对碳排放量的影响。
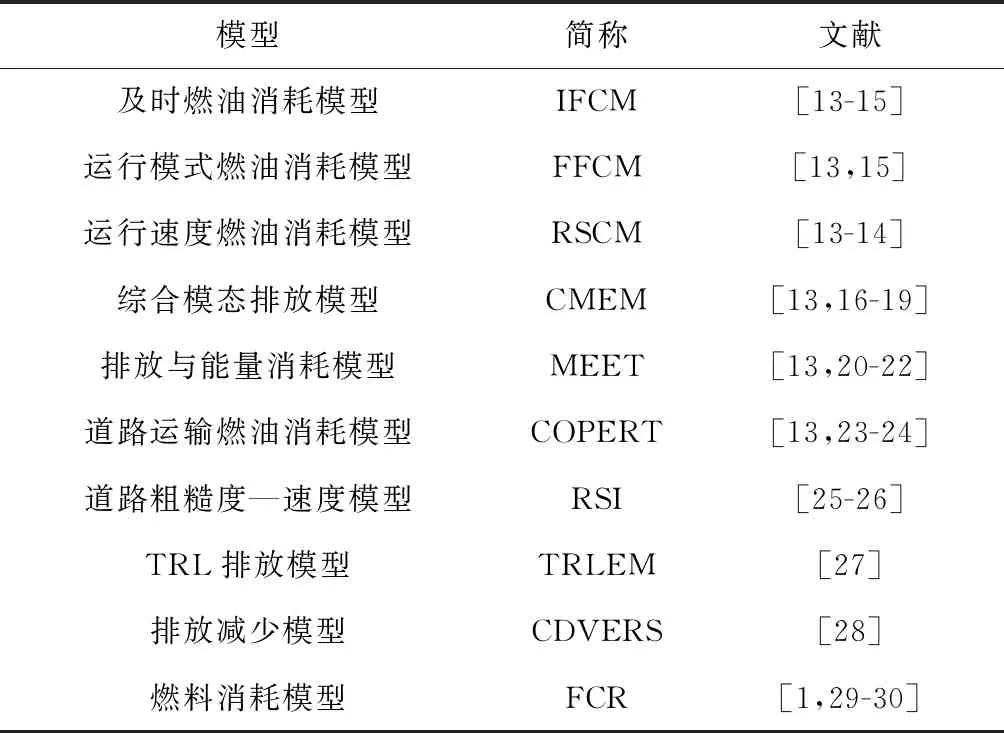
表1 模型种类与来源
在城市物流中,多车型是降低物流成本和提高物流配送效率的重要方式之一[5,31]。近年来,多车型物流配送在PRP和GVRP中逐渐成为减少碳排放的主要形式[32-33]。Koc等[5,34]分析车队规模和构成对成本与碳排放的影响,表明多车型相对于单一车型的物流配送网络存在优势;李进等[19]构建了具有固定车辆数的多车型低碳VRP模型,表明相比单一车型,采用多车型更能提高车辆的容量利用率、降低能耗与碳排放、减少使用车辆数;Pitera等[35]研究了多车型在逆向网络回收物品中的作用,结果同样表明了多车型为降低CO2排放的主要方式;Xiao等[36]考虑两种不同排放模型的重型车辆,分析了多车型与单一车型对CO2等温室气体排放的影响。对车型构成在物流配送成本或CO2等温室气体排放中的应用感兴趣的学者可参阅综述文献[37]。
交通拥堵是影响车辆CO2等温室气体排放和燃油转化效率的主要因素之一[28]。由文献[17]可知,在实际行车过程中,当车速低于30 mph时,CO2等温室气体的排放量和燃油消耗量快速非线性增长,即当车速从30 mph下降到12.5 mph或从12.5 mph下降到5 mph时,每英里的CO2等温室气体排放量和燃油消耗量会增加一倍。因此,近年来许多研究人员致力于研究因交通拥堵造成的速度实时性(或行驶时间的不确定性)对成本或CO2排放量的影响,普遍利用速度的分段函数模拟交通拥堵,确保每段的速度为常数[21,36,38-43]。Poothalir等[44]采用三角概率分布函数曲线表征速度的时变性,给出速度变化有利于减少燃油消耗的结论;Koc等[5]采用速度区域化概念表征交通阻塞,每个区域中保持匀速行车。对因交通拥堵影响的速度时变性感兴趣的学者可参阅文献[45]。
然而,以上大部分文献只分析了PRP或GVRP模型中的车队构成、交通拥堵、车辆负载和行车距离对碳排放的影响,仅有文献[1,5]将LAP和PRP(或GVRP)融合,构建LCLRP数学模型。文献[1]和文献[5]的主要区别为:前者仅优化车辆运输过程中的碳排放量,后者将车辆行驶过程中的燃料消耗量折算为路径成本,通过优化物流总成本达到节能减排的目的。文献[1]的主要不足为:①难以评估仓库的固有碳排放,仅人为设定过于主观;②不考虑仓库固有碳排放时会浪费现有资源,增加物流成本。文献[5]的缺陷是通过优化物流成本来降低碳排放而并非碳排放最小化。考虑到仓库的固有碳排放难以评估,采用文献[5]的方法将油耗成本折算为路径成本,通过优化物流成本达到节能减排、提高企业经济效益的目的。本文在文献[5]的基础上进一步展开研究,每个实例速度区域划分的位置和面积随机变化且为嵌套式,区域形状为矩形,每个速度区域的速度亦随机变化,即VZone3~U(60,80),VZone2~U(40,60),VZone1~U(20,40);另外,本文还涉及同时取送货等客户实际需求,以及经典CLRPSPD模型(MTC-2)、最小碳排放量(Minimum Carbon Emission, MCE)、最小距离(Minimum Total Distance, MTD)和最小行驶时间(Minimum Travel Time, MTT)4种RLCLRPSPDHF模型变体。目前,尚未有学者综合研究车队构成、同时取送货、速度区域化、仓库、服务距离和车辆负载等约束对物流成本和CO2等温室气体的影响。
2 模型构建
2.1 碳排放模型
本节主要介绍所采用的燃油消耗与碳排放模型,即综合模态排放模型(Comprehensive Modal Emission Model, CMEM)。目前已有学者将CMEM运用于PRP及其变型[5,13,16-19,34,41]。在多车型CMEM中,采用式(1)估算车型h∈H的车辆燃油消耗率FRh(单位:g/s):
FRh=ξ(khNhVh+Ph/η)/κ。
(1)
式中:ξ为燃料与空气质量比;kh,Nh和Vh分别为车型为h的车辆发动机摩擦系数、转速和排量;η为柴/汽油机的效率;κ为柴/汽油热值;Ph为车型h的发动机输出功率(单位:kW/s),
(2)
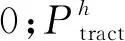
MhgCrcosθ)v/1 000。
(3)
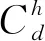
因此,车型为h的车辆以速度v(常数)负载Mh行驶距离d(单位:m)所消耗的油耗Fh(单位:g)为Fh=FRh×t(t为时间,单位:s),即
(4)
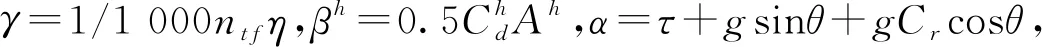
Fh=λ(khNhVhd/v+Mhγαd+βhγdv2)。
(5)
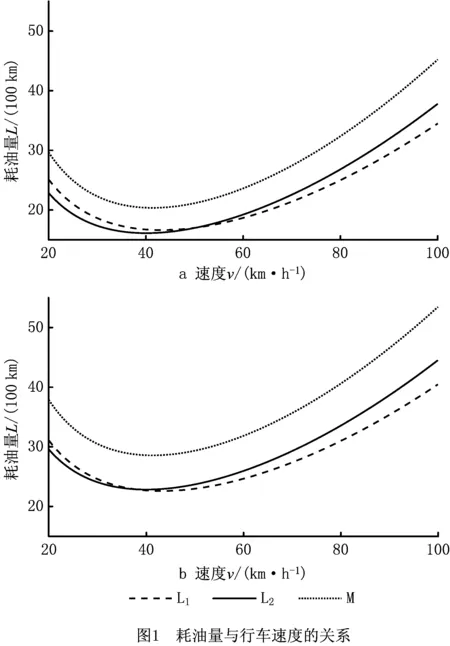
式中:khNhVhd/v为发动机模块,与运行时间成正比;Mhγαd为负载模块,与整车质量和距离成正比;βhγdv2为速度模块,与距离和速度的平方成正比。图1所示为车辆行驶100 km时耗油量与速度的关系图,图1a为不计车辆自重空载时的耗油量与车速的关系,图1b为计入车辆自重空载时的耗油量与车速的关系,其中L1,L2,M为3种车型,车辆自身参数各不相同。由图1可知油耗量与速度的关系呈现U型,并存在最优速度,使得油耗量最小,即vbest=(khNhVh/2βhγ)1/3。另外,车辆的CO2排放量与油耗量呈线性正比关系,即油耗量越大,碳排放量也越大。根据文献[5],汽油转换系数为2.32,即每消耗1L汽油会产生2.32 kg的CO2。
2.2 速度区域化
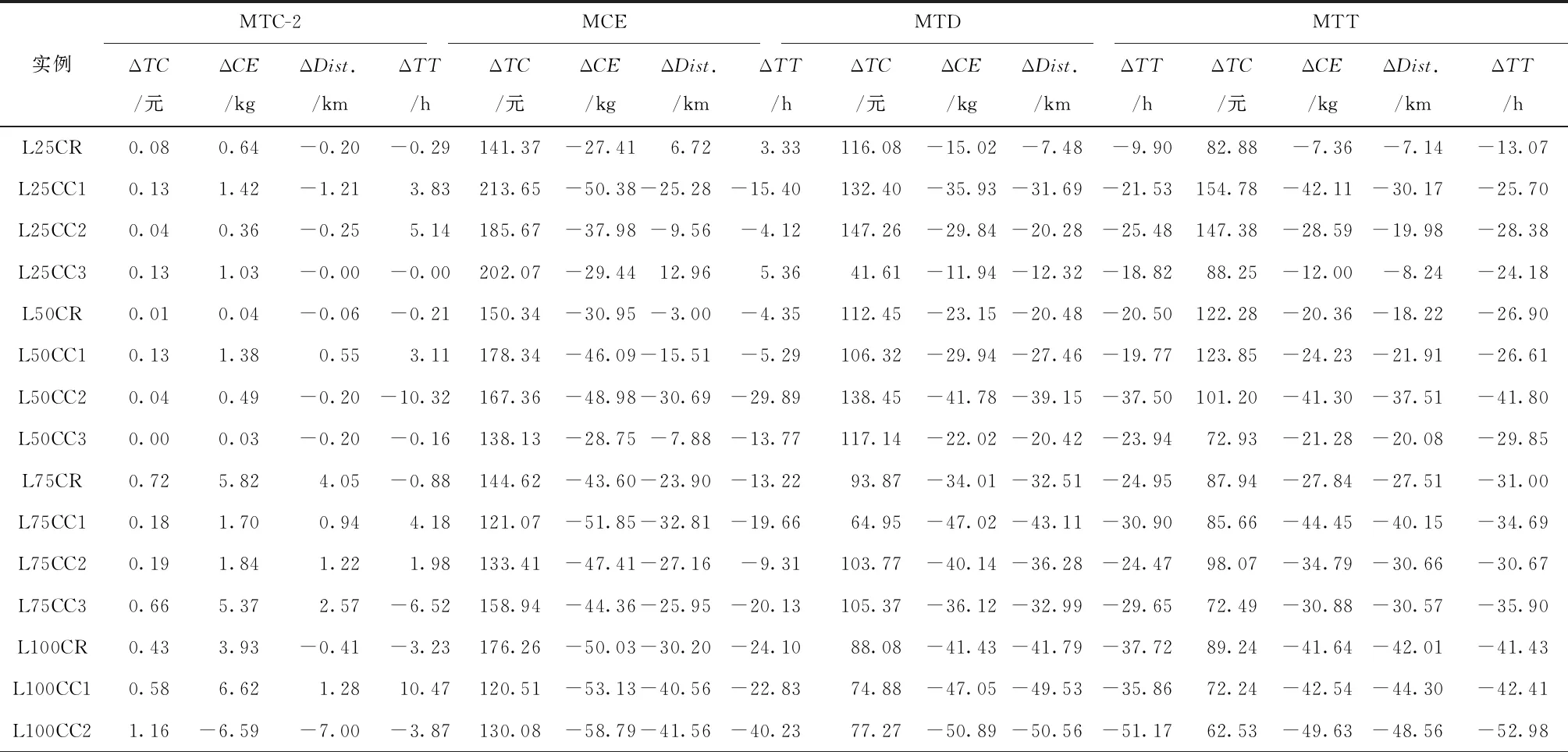
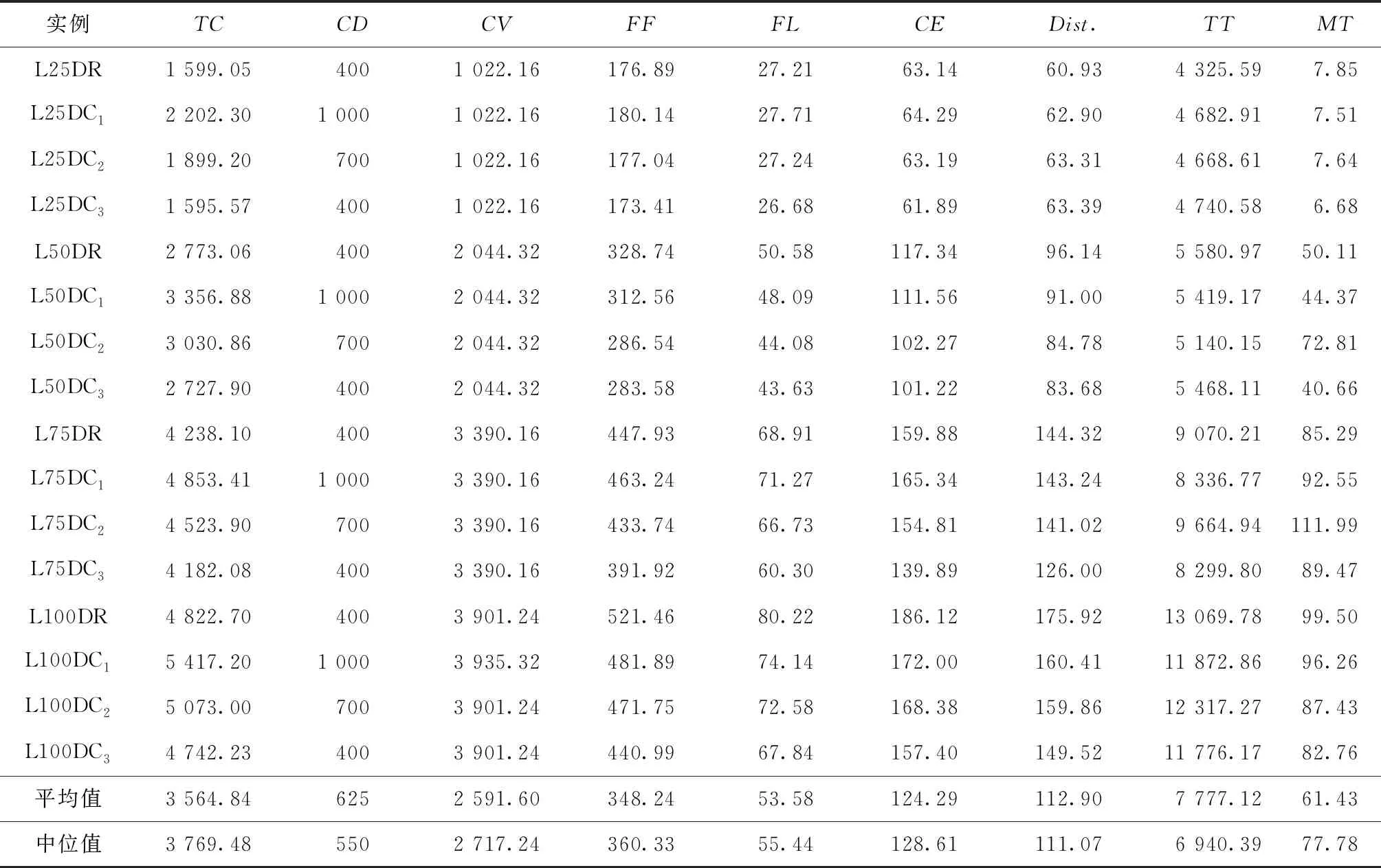
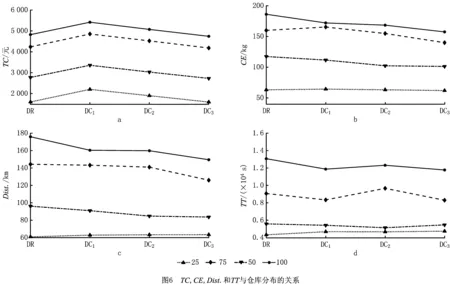
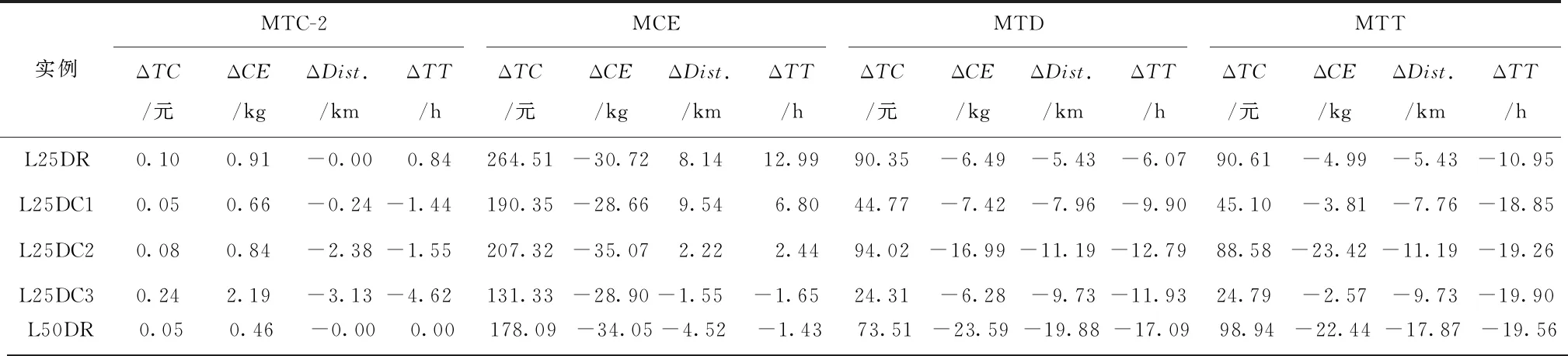
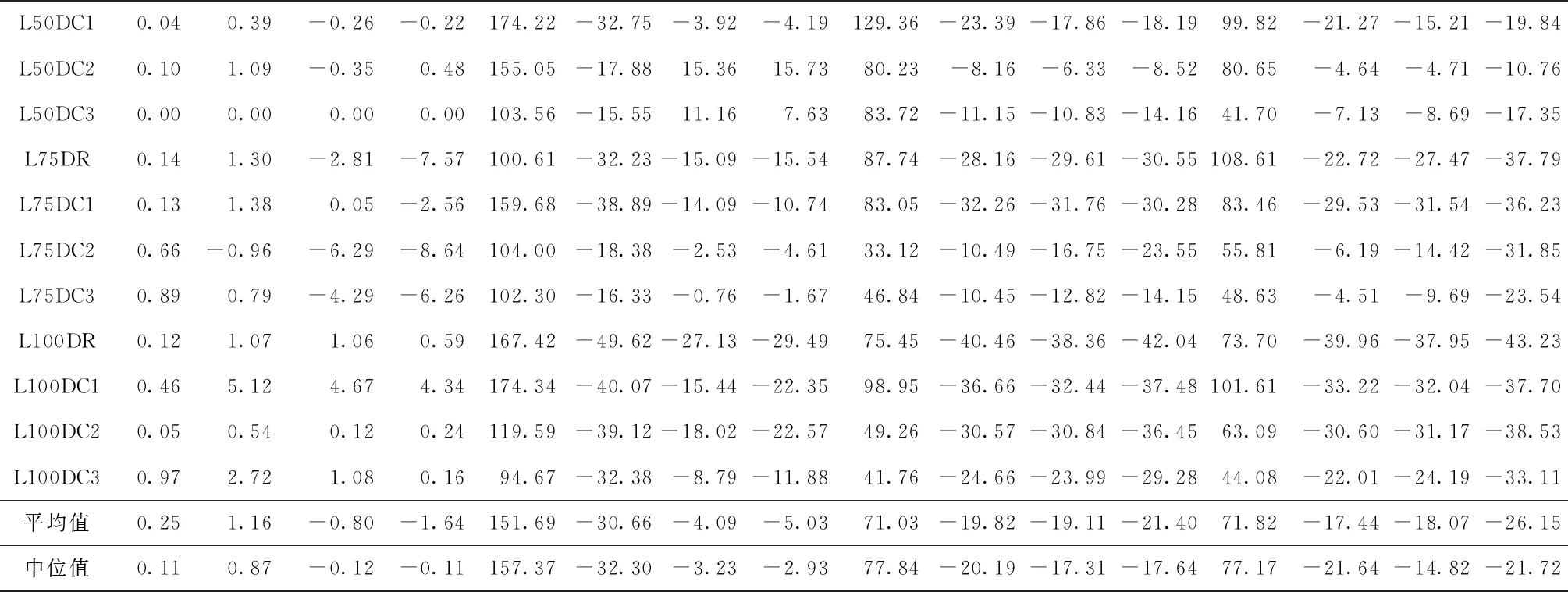
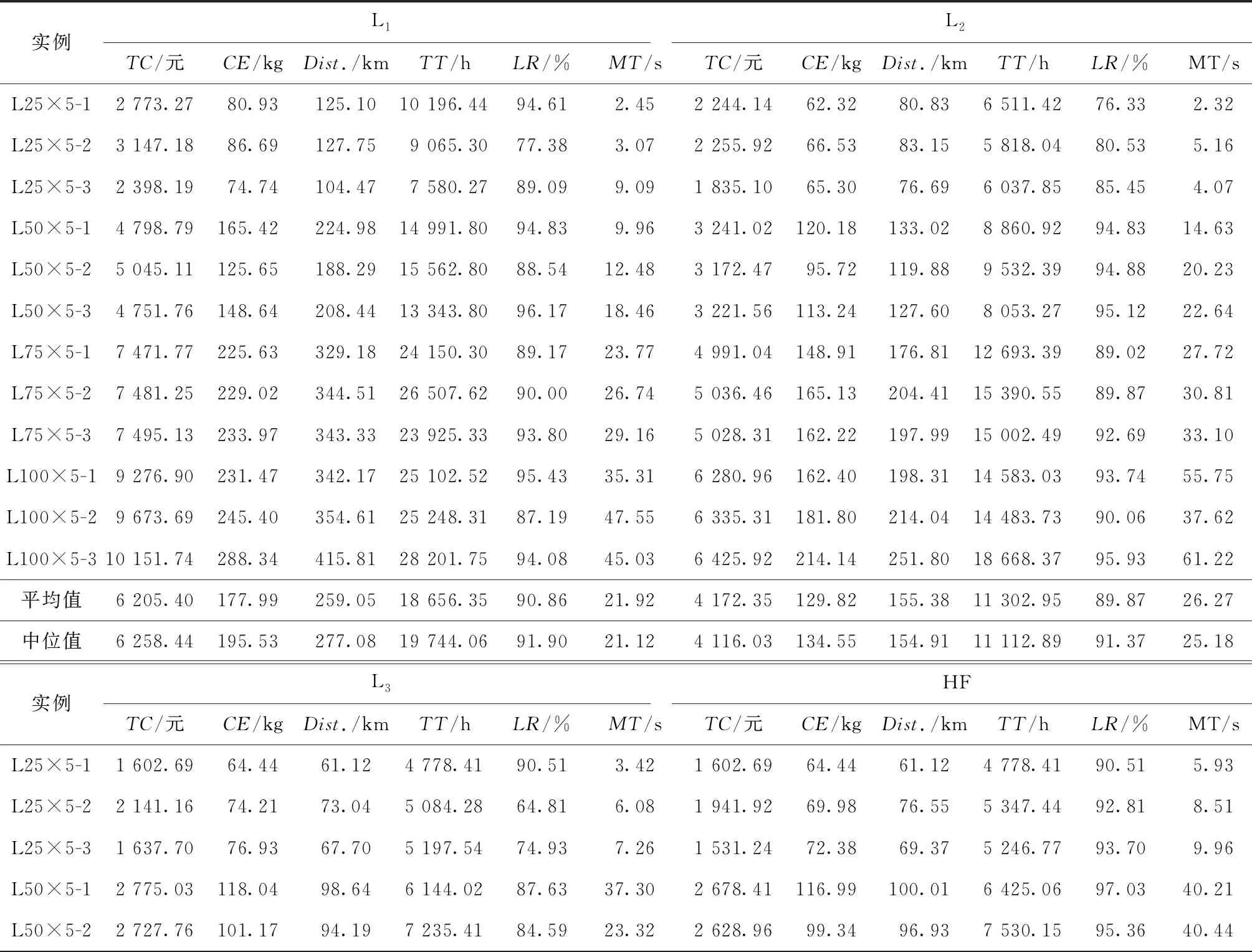
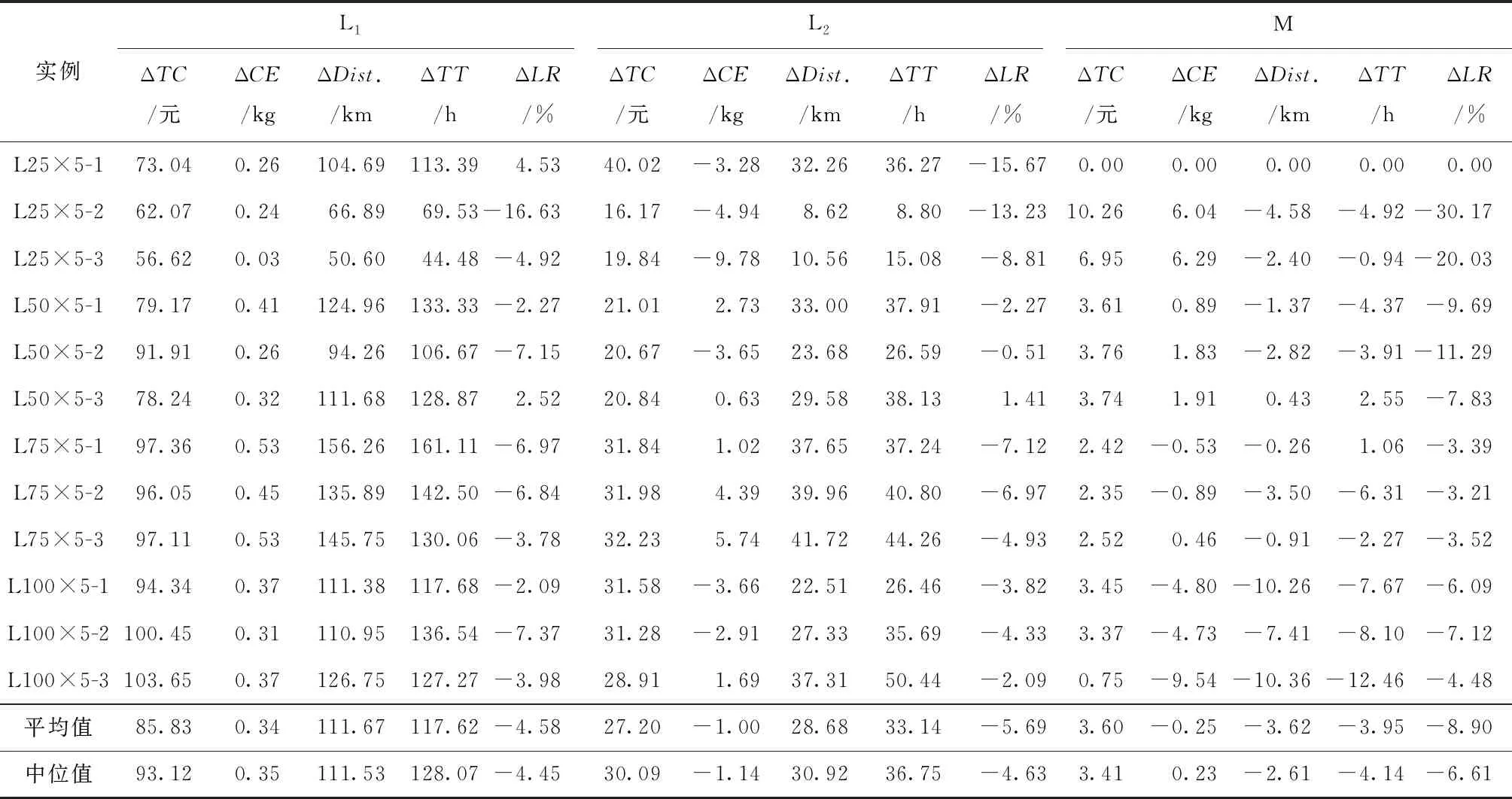
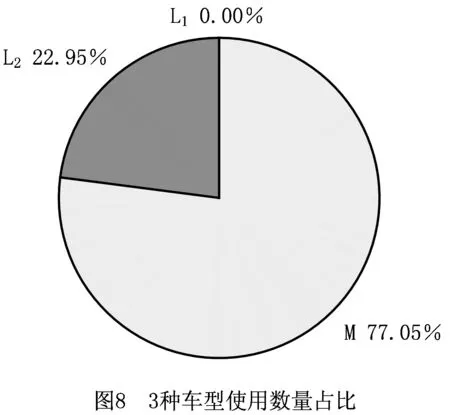
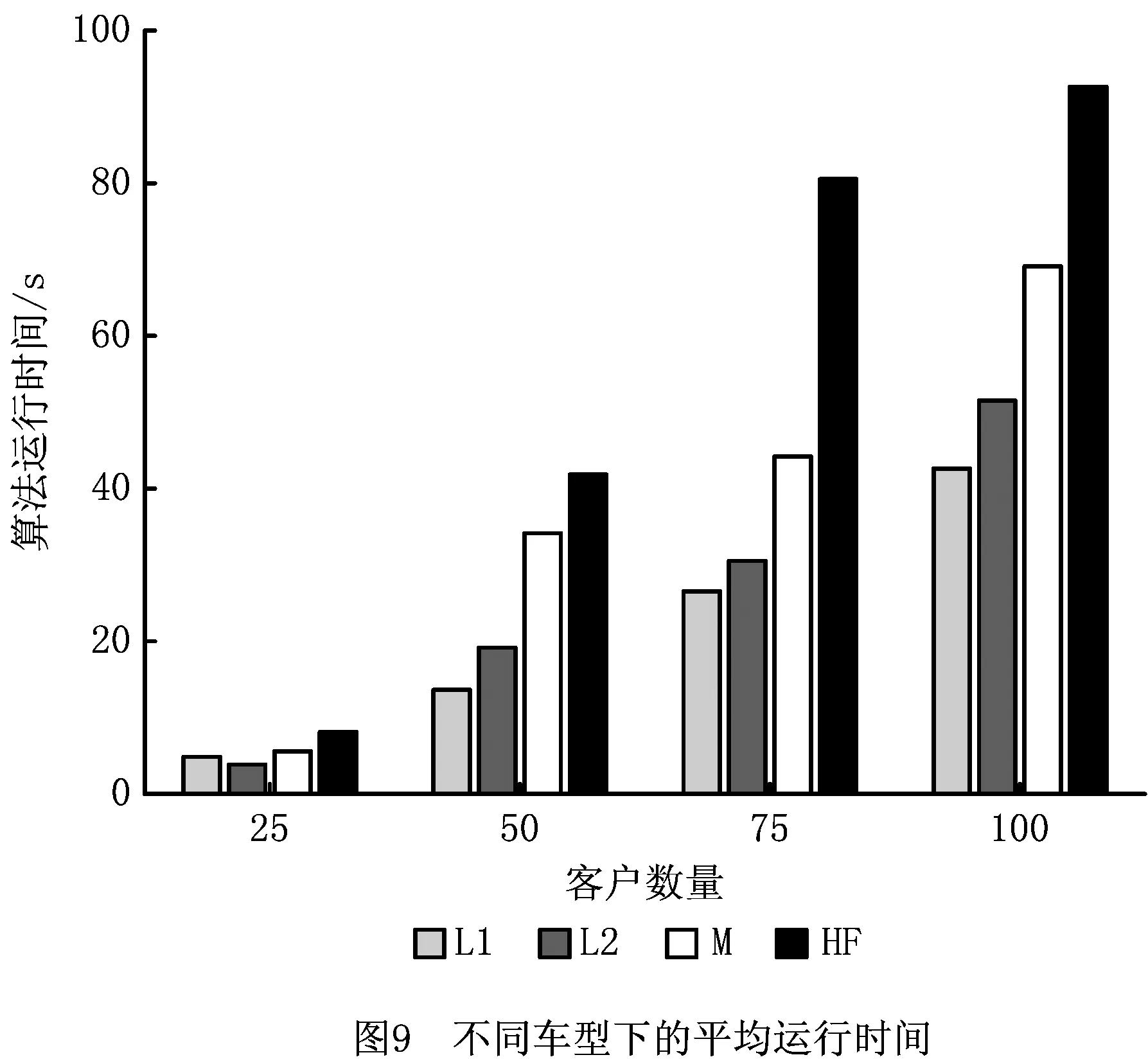
限制速度有利于减缓驾驶、节省燃料、减少CO2等污染气体排放[46]。速度区域化反映了与时间有关的交通拥堵所造成的速度时变性,对其进行研究可有效减缓交通拥堵状况,实现交通的可持续发展。图2所示为速度区域化的一种简单有效的方式,图中将城市分为3个速度区域,Zone 1对应市中心,体现为小巷和狭窄的道路等;Zone 2对应市中心外部区域,包括商业区和大学城等;Zone 3对应郊区,包括农业区和公园等。VZone1,VZone2,VZone3表示各区域的行车速度(固定速度),且VZone1 RLCLRPSPDHF定义为一个完全定向网络G=(V,E),其中:V由M候选仓库和N客户构成,每个客户均有配货和集货需求且地理位置已知,每个候选仓库的容量和位置已知并告知其固定租赁成本;E为边集,由N+M节点之间的距离构成。不同型号的车辆从仓库出发依次服务一系列客户,满足客户的配集货需求后返回原出发点。该模型的目标为确定一系列仓库位置和数量并分配行车路线,使总成本最小,包括仓库与车辆的固定租赁成本和燃油消耗成本。 在建立RLCLRPSPDHF数学模型之前,首先针对RLCLRPSPDHF的实际情况作如下合理假设:①每个客户只能被一个车辆和仓库服务一次;②车辆服务所有客户后必须返回原出发点;③每两个节点间的弧段上的车辆负载不能超过容量限制;④任何时期仓库的负载不能超过其容量限制;⑤不考虑陆续不定发车情况,且每个仓库有足够的车辆服务所有客户;⑥以最高满载率的原则分配车辆。模型中出现的符号变量含义如表2所示。 表2 参数符号含义 根据上述假设条件,构建如下模型: (6) s.t. (7) (8) (9) j∈I,i≠j,h∈H; (10) (11) (12) k∈J,i≠j; (13) (14) (15) (16) (17) Qijh≤CVhxijh,∀i,j∈V,i≠j,h∈H; (18) Qijh≥(qj-pj)xijh,∀i∈V,j∈I,h∈H。 (19) 其中:式(6)为目标函数,包括所租赁车辆和仓库的固定成本与燃油消耗成本,Fijh由式(5)求得;式(7)和式(8)保证每个客户只能被服务一次;式(9)和式(10)表示每个客户只能被一个仓库和车辆服务;式(11)~式(13)确保服务车辆返回原仓库;式(14)为仓库容量约束;式(15)和式(16)分别为车辆出发和返回时的负载量;式(17)为车辆负载量的动态平衡约束;式(18)和式(19)为车辆容量约束。 超启发式(Hyper-Heuristics, HH)算法是由Cowling等[47]于2000年提出的一种新型理论,将其定义为“启发式选择启发式”算法,该算法为组合优化问题的求解提供了一种新思路。后来,Burke等[48]拓展了超启发式算法——启发式选择和启发式生成。在HH框架中,存在底层启发式方法(Low-Level Heuristic, LLH)和高层启发式方法(High-Level Heuristic, HLH)两个相互隔离的领域。前者用于处理与问题领域相关的数据,包括所优化问题的数据信息、底层算子(用于搜索问题空间)和种群信息(染色体和适应度等);后者涵盖了算子的选择策略和解的接收机制两类不同性质的策略,选择策略的目的在于搜索由算子构成的空间并监测算子的历史性能信息,以选择优质合适的算子,接收准则计算劣质子代解的接收概率用于判断是否取代父代解,并控制着算法搜索的方向和收敛速度。另外,在HLH和LLH之间存在信息交换器,用于传输算子选择信息、解的接收信息、解的改进率、算子运行时间和次数,以及当前解连续无法改进的次数等与问题领域无关的信息。 本文从以下4个方面研究RLCLRPSPD和超启发算法。 本文所采用的编码方法如下:将V={v1,v2,…,vK}表征为一个完整的解,其涵盖所有路线;每条行驶路线对应染色体中第i个基因,即vi,每条路线起止于所属仓库,客户访问顺序存储于起止仓库之间,而且每条路线对应一个元胞数组;一个完整的染色体长度是取值为2K+N的非定长自然数列(K为所需车辆数,N为客户规模),同时染色体对应K个子元胞数的集合;为了降低计算复杂度和迅速计算适应度,采用定义“属性行”的方法保存每条行驶路线的各类参数,包括车辆的起始负载、行驶费用(车辆租赁费用和油耗费用等)和车辆类型等,因此在计算适应度时只需调用每条路线的行驶费用并求和,避免了重复计算。图3所示为一个简单实例,图中客户集I∈{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15},仓库集J∈{16,17,18,19},CV∈{70,80,90},车型H={L1,L2,L3}。该图类似于分层树形编码方法[6],即树根为行车路线,每条路线为枝干的构成之一;树叶对应路线的各类属性,包括起止载重量、行驶费用和车辆类型等。 本文的超启发式算法所采用的机制为非种群策略,即单点搜索框架(Single-Point Search Framework, SPSF)。因为SPSF易于陷入局部最优解,所以在算法初始执行阶段从初始种群随机选择任意个体进行优化。初始种群采用随机生成方法构建,首先随机生成客户顺序,利用贪婪法则分配客户,直至车辆容量无法满足下一个客户;然后根据重心原则随机选择所需仓库,并保证符合仓库容量要求,计算每条路线的属性;最后构造完整的车辆路线集。 3.2.1 选择策略设计 在超启发式算法成为许多组合优化领域研究热点的同时,构建了诸多优质的选择策略,包括CF(choice function)[47], FRR-MAB(fitness rate rank based multi-armed bandit)[49]等。本文提出一种新型选择策略——基于共享机制的自适应选择策略(Shared and Self-Adaptive Choice Mechanism, SSACM),其主要有3个特点:①利用滑动窗口(Sliding Windows, SW)存储近期算子性能信息,并将上次迭代中的算子性能有条件地共享至滑动时间窗的其余底层算子;②依靠算子性能表现将底层算子分为精英算子(Elite Heuristics, EH)和劣性算子(Poor Heuristics, PH),根据算子近期阶段性能自适应地选择合适的EH或PH;③针对EH和PH设计不同的性能评估方法。 SW为W×2维矩阵,其第1列储存所使用的算子,第2列储存算子的适应度改进率FIR。如式(20)所示,本文采用先进先出(First-in-First-Out, FIFO)机制排除滑动窗口中算子的早期性能参数,仅记录FIR>0的优质算子,当FIR<0时,立刻清空滑动窗口。 (20) 共享策略将上一次底层算子的FIR共享至滑动窗口内其他的底层算子,方法为按照先后顺序依次按特定比例分配FIR,例如比例为{r1,r2,…,rW},保证满足r1+r2+…+rW=1和r1>r2>…>rW,即与目前阶段越相近,比例越大,所得性能越高,r1为最近使用的底层算子。 采用算子全局历史性能将底层算子分为两类(EH和PH),如式(21)所示。如果算子i的GFIR(i)≥0,则将该算子归类为EH,否则属于PH;如果GFIR<0,则将GFIR按降序排列,取前1/2的底层算子为EH,其余为PH。在算法迭代中,底层算子在不同优化阶段的性能表现可能不一致:当EH中的所有底层算子无法改进当前解时,可认为算法无法跳出局部最优解,此时应尽可能选择PH中的算子;当获得扰动解时(跳出了局部最优解后),立刻采用EH中的算子有利于加快算子搜索过程,因此提出一种自适应选择机制,即PH的选择概率随TQ的增加而增加,TQ为当前解未改进算子的使用次数,NT为底层算子数,如式(22)所示。 (21) (22) 在分配算子信用值时,对EH的内部算子采用FRR-MAB信用值分配方法,即 (23) 3.2.2 接收准则设计 接收准则(Acceptance Criterion, AC)的作用在于计算劣质的子代解cf取代父本pf的概率,用于控制算法的收敛速度和优化精度。在对已有接收准则分类时,所有接收准则均可采用以下公式(求最小化问题)概括: (24) 式中:CF为下一次迭代的当前解;p为控制概率;r为0~1间的随机数。一般地,当cf优于pf时,cf直接取代父本进入下一次迭代,否则利用概率公式(24)计算cf取代pf的概率并做出抉择。另外,大部分接收标准仅利用改进率信息,忽略了算子的阶段性能信息,即算子的优化性能在不同计算阶段表现不一致。本文利用算子的阶段性能信息构建一种简单的自适应接收标准,即采用计数器TQ记录底层算子达到FIR≤0的迭代次数,接收子代解的概率随TQ值的增大而增大,如果所选算子获得了优质解,则重置TQ,即自适应接收(Adaptive Acceptance, AA)机制以概率p=(2TQ/|ξ|)ψ接收劣质解,当TQ≥|ξ|/2时,cf被接收。其中ψ为接收控制参数,用于控制概率p的大小。 底层算子库(Pool of Low-level Operators, PLLO)中为直接搜索问题领域解空间的启发式搜索算子,由领域专家提供。PLLO可视为无法操作的黑箱,其算子可根据优化性质分为变异算子和爬山算子两类。变异算子在搜索过程中提供足够的随机性以防止陷入局部最优解,所采用的机制为微小地扰动当前解,而且不要求获得优质解;爬山算子则严格要求算子具有改进当前解的能力,其能够促使算法快速收敛并提高收敛精度。这两类优化算子在组合优化问题领域中不可或缺,下面为本文构造的6种爬山算子和9种变异算子: (1)爬山算子有线路内部2-Opt(Inside-2Opt)、线路间2-Opt(Inter-2Opt)、线路内交换客户(Inside-Swap)、线路间交换客户(Inter-Swap)、线路内移动客户(Inside-Shift)和线路间移动客户(Inter-Shift)。局部优化算子每次执行的约束条件为:①改进率FIR≥0;②任意弧段的车辆负载必须小于额定容量;③仓库的负载不能超过额定容量。对线路内部进行局部优化时采用完全优化策略[50],对线路间进行局部优化时采用V-1机制,即随机选定一条路径与其他路线的客户逐一交换优化,可知算子复杂度从V(V-1)/2降低为V-1。 (2)变异算子分为两类,一类针对车辆路线扰动的变异算子,包括Inside-2Opt-M,Inside-Or-Opt,Inter-Shift-M,Inter-Swap-M,Shaw[51],Decompose,Merge。前5种变异算子的策略为随机选取1/4~1/2的路径,随机扰动路径内或路径间的客户;Decompose分解随机选中的路线,并获得两条子路线;Merge随机选择两条路线合并为一条路线。另一类针对仓库选用的编译算子,包括Add-Swap和Relocation。Add-Swap算子将随机选取的1/3~2/3路线分配给一个新的仓库,或关闭一个仓库并将该仓库的所有路线安排到另一仓库,以防止过少的仓库导致过快收敛;Relocation算子将每条车辆路线坍塌于一个Super-Client,然后将仓库插入每条路线中,将获得的最小插入代价作为该仓库与该路线之间的成本,类似于文献[52]。变异算子必须满足仓库和车辆的负载约束。底层算子库中的所有算子必须满足所有约束条件后才能计算适应度,以保证路线的可行性,避免使用修复技术。 算法复杂度用于衡量算法运行的时间性能,分析算法复杂度的关键在于分析运行时间的相对量度。根据超启发式算法的流程框架,超启发式算法迭代一次的复杂度分为高层选择策略复杂度、底层算子执行复杂度、高层解的接收复杂度和精英保留策略复杂度4部分。在采用单点搜索框架的算法中,迭代次数为Tmax、客户数为N、车辆数为K、底层算子数为NL,滑动窗口大小为W,算法迭代一次的复杂度包括高层选择策略复杂度O(HS)、底层算子最大复杂度O(N2)、高层解接收机制最大复杂度O(3)和精英保留策略复杂度O(1),迭代之外有种群初始化复杂度Npop×O(N2)和适应度计算复杂度Npop×O(N2)(Npop为初始种群大小)。因此,算法的总体复杂度为 O(HH)=Npop×O(N2)+Npop×O(N2)+ Tmax×(O(HS)+O(3)+O(N2)+O(1))。 (25) 式中O(HS)包括底层算子性能更新O(1)和性能滑动时间窗更新O(W)。性能时间窗内算子性能共享复杂度为O(W),底层算子分类复杂度为O(NL),自适应概率计算复杂度为O(1),劣性算子性能计算复杂度为O(1),信用值计算复杂度为O(NL),轮盘赌策略复杂度为2×O(NL),因此执行一次选择策略的最大复杂度为 O(HS)=O(3)+2×O(W)+4×O(NL)。 (26) 超启发式算法总体复杂度为 O(HH)=2Npop×O(N2)+Tmax× (O(4NL+2W+7)+O(N2))=2Npop×O(N2)+ Tmax×O(4NL+2W+7)+Tmax×O(N2)。 (27) 根据以上分析可知,所提算法的整体时间复杂度约为Tmax×O(N2),即可忽略高层策略的时间复杂度,所提超启发式算法的总体计算复杂度约为底层算子计算复杂度的总和,和大部分启发式算法为同一个量级,是一种有效的算法。 仿真实验的目的如下:①验证算法的求解准确性与模型的正确性;②验证所提组合策略SSACM-AA的高效性;③分析客户和仓库分布以及车型构成对物流成本与碳排放的影响。根据实验目的,生成如下算例:①实验1随机生成15个小规模算例,客户数N∈{10,15,20}(各5个),仓库数M∈{2,3,5},客户取送货量q,p∈[0,4 000](kg);②实验2采用适用于LRP的Barreto[51]标准实例库以及适用于CLRPSPD的KBAM和YLBAM实例库[53]的W类型实例,N∈[21,150],M∈[5,15];③建立LCLIENT,LDEPOT,LVEHICLE 3类不同性质的实例库,每个实例库中客户数N∈{25,50,75,100}。 在LCLIENT实例库中生成4种不同的客户分布:CC1为60%的客户位于Zone 1;CC2为60%的客户位于Zone 2;CC3为60%的客户位于Zone 3;CR为客户随机分布。仓库随机分布,仓库数量M=5,位于Zone 1,Zone 2,Zone 3,仓库的固定成本分别为1 000元、700元和400元,令每个仓库均能服务所有客户。在LDEPOT实例库中,客户位置随机分布,同样有4种不同的仓库分布:DC1为所有仓库位于Zone 1;DC2为所有仓库位于Zone 2;DC3为所有仓库位于Zone 3;DR为仓库随机分布。仓库参数与实例库LCLIENT相同。在LVEHICLE实例库中,仓库和客户随机分布,共生成15个实例,每个实例由不同车队服务,包括L1,L2,L3和多车型,车辆参数可参阅文献[5]。 SMSAHH-AA采用MATLAB 2015b并行编程,计算机环境为Intel(R)Core(TM)CPU i7-6700K@4.00GHz, 8 GB RAM, Windows 10。终止条件为算子的最大使用次数Tmax=min(10×(M+N+K)2,104);每次独立运行(20次)的个体为初始种群中的随机个体(Npop=10);滑动窗口大小W=4;性能分配比例为r1~U(0.4,0.6),r2=0.5(1-r1),r3=0.3(1-r1),r4=0.2(1-r1);权衡因子C=0.5[54];接收控制参数ψ=2。 为了验证所提模型的正确性与算法求解的准确性,采用小规模实例进行初步实验。本节对SMSAHH-AA和CPLEX取得的最优解(1次独立运行)进行比较,结果如表3所示。其中:第1列的实例名称为LN×M-No.,N与M分别表示客户数和仓库数,No.表示相同规模下的序号;TC为总成本,Gap为两个TC之间的百分比差距,SD为5次独立运行总成本的标准差,MT为5次独立运行的平均运行时间。结果表明,所提算法能够在合理的计算时间内求得最优解,因此本文所提模型正确,而且算法求得最优解的准确性较高。然而,小规模实例并不能判断本文算法的高效性,实验2采用适用于CLRP和CLRPSPD的Barreto标准实例来检验SMSAHH-AA的高效性。 表3 小规模实例结果 续表3 为了验证SSACM-AA的高效性,采用SMSAHH-AA求解CLRP/CLRPSPD标准算例,实验结果如表4所示。其中:BKS为已知最好解;BF,MF,SD,MT分别为求得的最好解、平均解、标准差和平均运行时间;Gap表示BF和BKS的百分比差距;黑体字表示数字等于BKS,黑斜体表示新的最好解。本节设置Tmax=min(5×(M+N+K)2,80 000)。 从表4可知,SSACM-AA获得了所有CLRP算例的最优解和11个CLRPSPD算例的最优解(占所有测试问题的84.38%),仅未获得CLRPSPD中D88×8和C100×10的最优解,同时获得了3个新的最好解,最大改进率为6.6‰,足以验证所提算法求解LRP/LRPSPD的有效性,可以推断本文的SMSAHH-AA能实时准确地监控底层算子的性能信息并选择合适的底层算子,从而验证了算法的高效性。 表4 求解Barreto算例CLRP和CLRPSPD的结果 续表4 (1)客户分布对成本与碳排放的影响 表5所示为SMSAHH-AA采用LCLIENT算例的计算结果,其中:TC为物流成本,包括车辆与仓库固定租赁成本和燃油成本;CD为启用的仓库费用;CV为车辆费用;FF为燃油费用;FL为燃油量;CE为碳排放量;Dist.为车辆行驶距离;TT为车辆行驶时间;MT为算法的运行时间。 表5 LCLIENT算例结果 由表5可知,相比于Zone1和Zone2,客户分布方式为CR与CC3有利于减少物流成本,其中CC1相对于CR和CC3类可减少3.1%TC,CC2相对于CR和CC3类减少2.4%TC。同一规模的实例中,客户的其他数据完全相同,包括取货量和送货量,因此除了100CR和100CC3,其他实例的车辆费用几乎相同。类似地,燃油费用、燃油量和碳排放量与客户分布密切相关,相比于CC1和CC2,客户坐落于CC3能有效降低燃油费用、燃油量和碳排放量,其中CC1相对CR和CC3可平均减少22%碳排放量,CC2相对CR和CC3可平均减少16%碳排放量,但100CC2所得碳排放量却分别大于100CR和100CC3的0.2%和9%的碳排放量,究其原因为车队构成和行驶速度对物流成本和碳排放有一定影响,Dist.的情况与此类似。车辆行驶时间与客户分布关系不明显,但从平均TT大小可知CC2和CC3算例均小于CR和CC1,原因是Zone 2和Zone 3的车辆可以较高速度行驶。以上9种数据均表明9种决策变量随客户数量的增加而增加。 图5的目的为分析各费用在物流成本中所占比例,其中ICD(%)为仓库费用比重,ICV(%)为车辆费用比重,IFF(%)为燃油费用比重。由图可知ICD随N的增大而减小,ICV随N的增大而增大,且逐渐增大至80%以上,然而IFF受客户数量的影响不明显,平均约为11%。图5a和图5b表明在相同客户数量下,ICD和ICV在CC1和CC2下比在CR和CC3下略大;ICD随客户分布的变化很小,可忽略不计,ICV在CR和CC3下约降低了1.67%和1.59%。由图5c可知,当N<100时,CR和CC3下的IFF大于CC1和CC2的IFF;当N=100时,CC2下的IFF大于CR和CC3下的IFF。 为了验证所提模型的有效性,采用SMSAHH-AA对MTC-2,MCE,MTD和MTT模型求解,对比结果如表6所示,其中ΔTC,ΔCE,ΔDist.,ΔTT分别为物流成本、碳排放量、行驶距离和行驶时间的变化量。相对于MTC-2模型,所提模型能够有效降低3‰的物流成本和1.68%的碳排放量;相对于MTC,所提模型可降低43%的碳排放量,但增加了156%的物流成本;相比于MTD模型,所提模型能够有效减少99.46%的物流成本,但会增加碳排放、运输距离和运输时间;相比于MTT,所提模型可有效减少88.75%的物流成本,但同样会增加碳排放、运输距离和运输时间。因此,忽略仓库和车辆固定费用的模型(MCE,MTD,MTT)会获得较低的碳排放量、车辆行驶距离和行驶时间,但会增加物流成本(如果无法忽略仓库和车辆固定费用),相比于模型MTC-2,所提模型能有效减少物流成本和碳排放量。综上所述,所提模型既能提高物流企业的经济效益,又可实现可持续发展,验证了模型的有效性。 表6 4种模型与MTC的对比 续表6 (2)仓库分布对成本与碳排放的影响 表7所示为求解LDEPOT算例的结果。可知,DR和DC3下的物流成本总小于DC1和DC2,DR相比DC1和DC2分别降低了17%和9%的物流成本,但分别增加了2%和7%的碳排放量与3%和6%的车辆行驶距离,DC3相比DC1和DC2分别降低了18%和10%的物流成本、9%和5%的碳排放量以及7%和5%的车辆行驶距离,说明位于Zone 3的仓库不仅有利于降低物流成本,还有利于降低CO2排放量和运行距离,因此在选择或建立仓库时,Zone 3既有利于近期利益(郊区地皮价格较低),又有利于长期利益(降低物流成本和碳排放量),属于最优选择。 表7 LDEPOT算例结果 图6所示为TC,CE,Dist.,TT与仓库的分布关系,可知DC3更有利于降低物流成本、碳排放量和车辆行驶距离,DR在降低物流成本上仅次于RC3,但是在碳排放量、行驶距离和时间方面比其他3类要高,车辆行驶时间几乎不受仓库分布的影响。 图7所示为ICD,ICV,IFF随N和仓库分布(DR→DC1→DC2→DC3)变化的趋势图。由图可知仓库费用占比随N的增大而减小,但呈现放缓趋势;车辆费用比重随N的增大而增大,且逐渐增大至80%以上,但同样呈现放缓趋势;油耗费用占比与N的关系不明显。仓库分布对ICD,ICV,IFF影响巨大,图7a表明DC2和DC1的ICD大于DR与DC2的ICD,原因是仓库费用不同;图7b表明ICV也与仓库坐落位置相关,越靠近Zone 1的ICV越小,DR和DC3的ICV最大;图7c表明DC3下的IFF最大,其次为DR(在N=75时反而最小),DC1下的IFF最小。以上现象表明,仓库因坐落位置不同而导致费用不同时,对ICD,ICV,IFF产生的影响较大。 为了验证模型在该算例库上的有效性,采用SMSAHH-AA求解MTC-2,MCE,MTD,MTT模型,对比结果如表8所示。相对于MTC-2模型,所提模型能有效降低2.5‰的物流成本和1.16%的碳排放量;MCE模型为最小化碳排放量,相对于MTC可降低30.66%的碳排放量,但增加了151.697%的物流成本;MTD模型有利于降低ΔCE,ΔDist.,ΔTT,但增加了71.03%的物流成本;MTT模型有利于降低26.15%的车辆行驶时间,但增加了71.8%的物流成本。同上所述,忽略仓库和车辆固定费用的模型(MCE,MTD,MTT)往往会获得较低的碳排放量、行驶距离和时间,但会增加物流成本(如果无法忽略仓库和车辆固定费用),相比于模型MTC-2,所提模型能有效减少物流成本与碳排放量。 表8 4种模型与MTC的对比 续表8 (3)车队构成对成本与碳排放的影响 在LVEHICLE数据库中,共有12个算例,客户数N∈{25,50,75,100}。每个实例有4种变形,表现为不同的车队构成,包括L1,L2,L3,HF(多车型)。表9所示为计算结果,其中LR为平均满载率(%)。表10所示为使用HF求解结果的变化量,其中ΔX为相对HF的X值的百分比差距(%)。 表9 不同车型构成的算例结果 续表9 表10 与多车型实例数据的对比结果 从表9可知,相对于单独使用L1,L2,M,使用HF的实例的总成本平均降低85.83%,27.20%,3.60%,中位值分别为93.12%,30.09%,3.41%,均值与中位值相差不大;相对L1,L2,使用HF的实例可平均减少111.67%,28.68%的车辆行驶距离,但相对于单独使用M类车辆增加了3.62%的车辆行驶距离;相对于单独使用L1,使用HF的实例平均减少0.34%的碳排放量;相对于单独使用L2与L3,使用HF的实例分别增加了1%和0.25%的碳排放量。从满载率而言,使用HF的实例的LR和中位值分别以95.23%和95.6%位于第一,验证了文献[15]关于多车型在提高车辆容量利用率方面的结论。然而,由于本文将车辆的油耗量折算为车辆路径成本加上车辆和配送中心的固定租赁成本,从而相比于单一车辆,使用HF的路径安排并不能在所有算例上减少碳排放量(如L2和M求解的CE和ΔCE),然而采用HF的统筹规划(选址和路径优化)比单一车型可以进一步降低物流成本,更符合实际配送的要求。 图8所示为采用HF时各类车辆使用次数的饼状图。可见,虽然L1相对M更能节能减排(如图1),但是所有实例并未采用L1(占比为0%),而将M作为RLCLRPSPDHF模型最常用的车型(占比为77.05%),比使用L2车型的数量多(L2占比为22.95%),原因是车辆的容量、自重及费用对车型选择的影响。另外,由MT值可见车辆容量对算法运行时间的影响,即随着车辆容量的增加,算法的计算时间呈多项式增加,如图9所示,该结论尚未在任何文献中提及。 根据以上分析,可从算法层面得出以下结论:①所提算法求解小规模实例的准确性高;②SMSAHH-AA能够在合理的计算时间内求得优质解,具有有效性和鲁棒性;③算法的时间性能与车辆容量正相关,即车辆容量越大,运行时间越长。从RLCLRPSPDHF问题领域层面可知:①客户集中在Zone 1和Zone 2有利于减少物流成本和碳排放量,原因可能是Zone 3地理跨度大,而且VZone3~U(60 80)相比于VZone2~U(40,60)和VZone1~U(20,40)偏离vbest=(khNhVh/2βhγ)1/3(约在41 km/h)更严重;②由于位于Zone 1和Zone 2的仓库租赁成本高,DC3更有利于降低物流成本、碳排放量和车辆行驶距离,DR在降低物流成本方面仅次于RC3,在碳排放量、行驶距离和时间方面相比其他3类高;③采用多车型统筹规划比单一车型统筹规划更能降低总成本和提高车辆容量利用率,但无法保证能够降低碳排放量和车辆行驶距离;④总成本、能耗和碳排放量与服务距离和时间存在较高的相关性,降低成本、节约能耗和降低碳排放会在一定程度上增加服务距离与行驶时间;⑤RLCLRPSPDHF模型的统筹规划比多车型MTC-2统筹规划能更多地降低物流成本和碳排放量,但会增加服务距离和行驶时间,相比于其他3类,MTC能最大地降低物流成本,但会略微增加碳排放量、服务距离和行驶时间。因此,以上结论可在广大物流企业(尤其第三方物流)提高经济效益和低碳环保的形势下,为政府部门制定节能减排政策提供参考和借鉴。 同时考虑多车型、取送货和速度限制等实际约束对碳排放影响的LCLRP研究对物流企业降低物流成本、保护生态环境具有重要的现实和理论意义,对可持续发展和节能减排的政策具有重要的支撑作用。本文将以上影响碳排放的因素考虑到LCLRP中,构建了三维指数混合规划模型。由于该模型为NP-hard问题,设计了基于共享机制的自适应超启发式求解算法,即将上一次迭代底层算子的性能条件共享至滑动窗口内其他底层算子,认为个体改进是滑动窗口内其余算子共同优化的结果;在底层黑箱的作用下,由于无法得知算子的特性和种类,通过全局性能表现将其分为精英算子和劣质算子,各司其职;利用上次扰动时的最优解与当前最优解之间的改进率表征劣质算子的性能;利用算法底层算子的当前阶段性能指数,即无法改进当前解的次数(TQ)自适应选择精英算子和劣质算子,充分利用两类算子的特性;采用FRR-MAB信用值分配策略选择准确合适的算子。最后通过3组实验充分论证了本文方法的有效性。 由于优化物流总成本并不意味着减少服务距离和碳排放,下一步侧重于设计多目标超启发式算法求解Pareto解集以供决策者选择。另外,所提模型考虑了物流的经济效益和环境效益,尚未涉及客户对物流配送的满意度,因此下一步可在速度区域化假设的基础上考虑客户时间窗要求。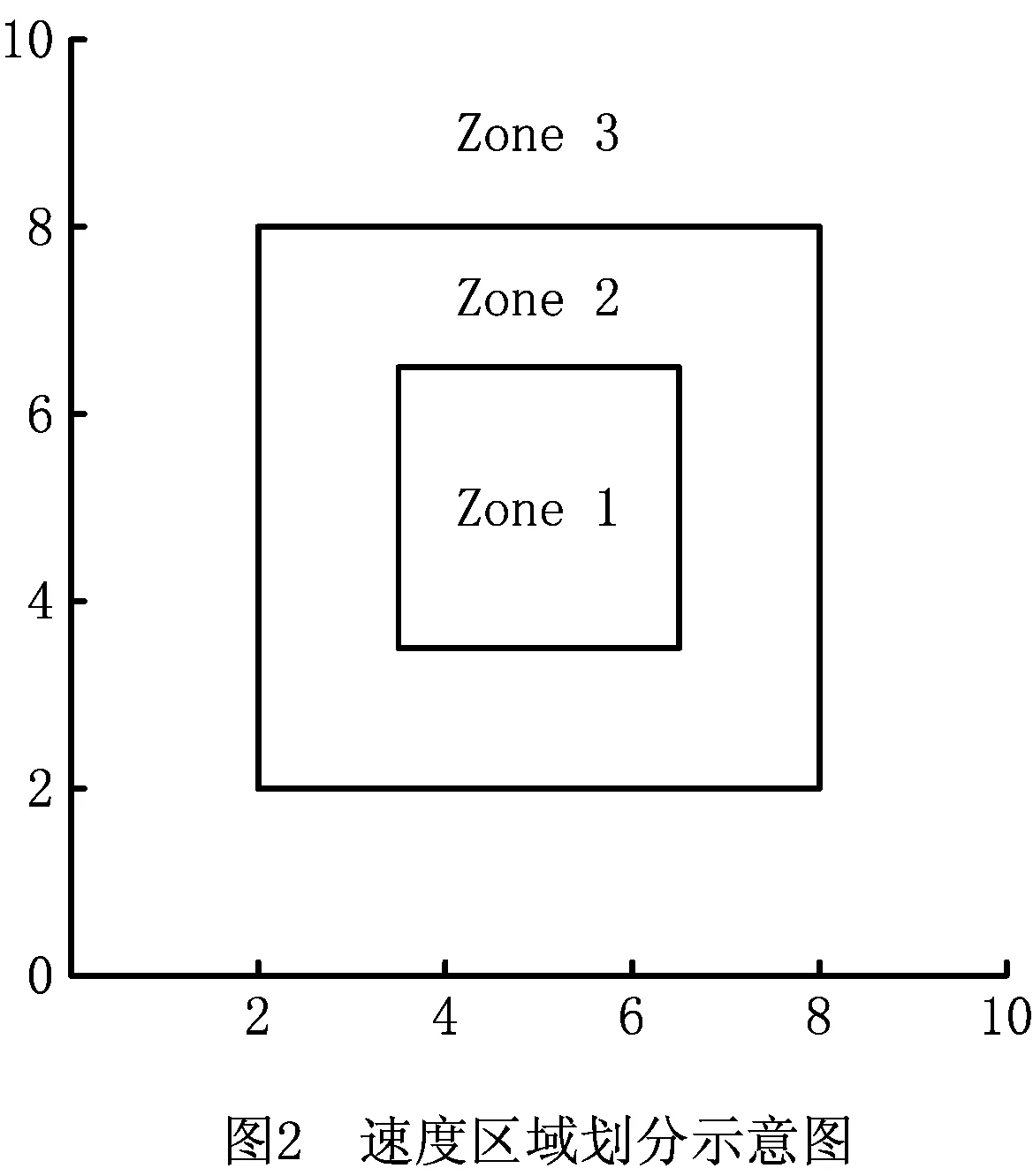
2.3 模型构建

3 算法设计
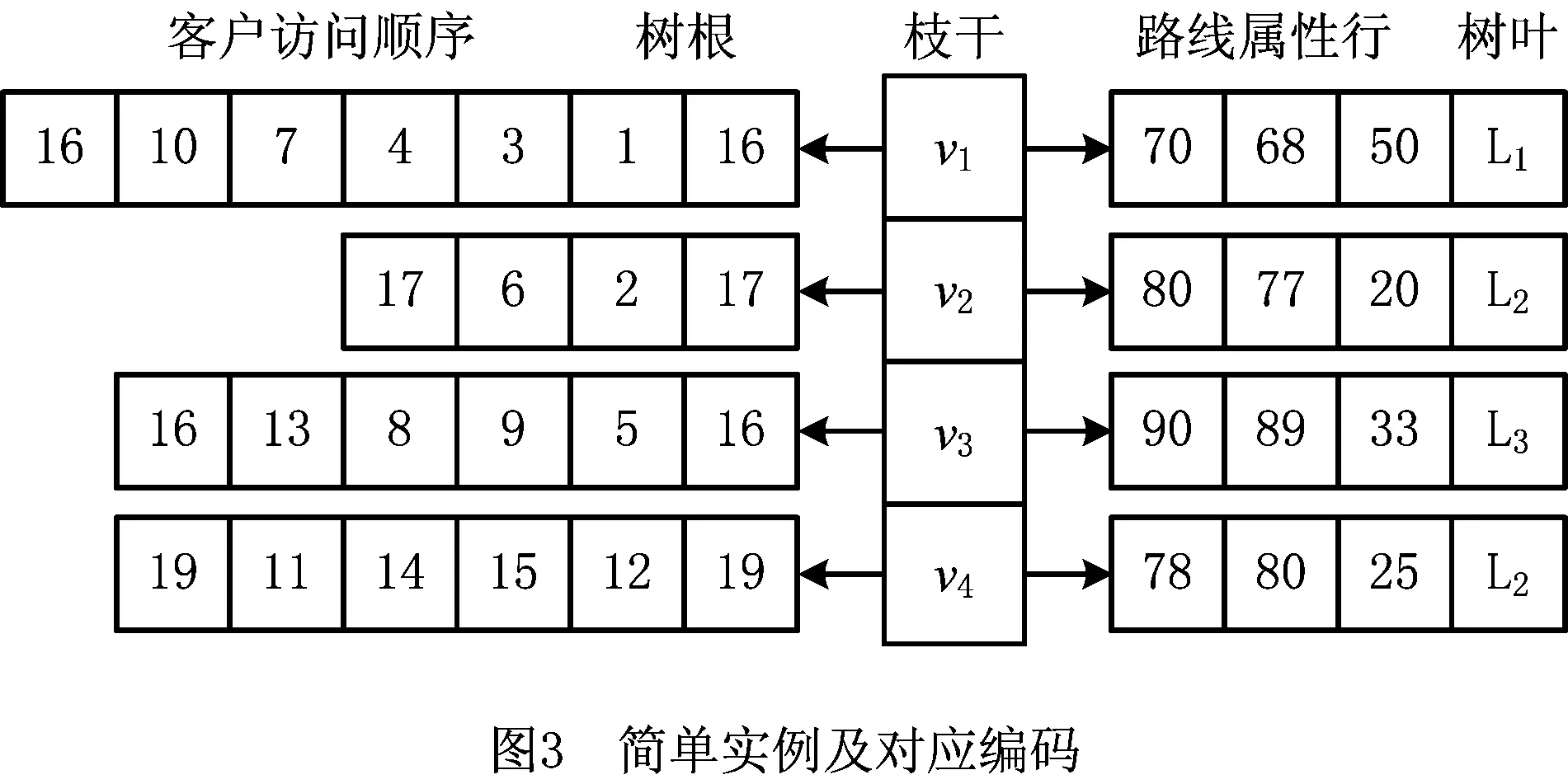
3.1 解的编码与初始种群的产生
3.2 高层策略的构造
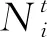
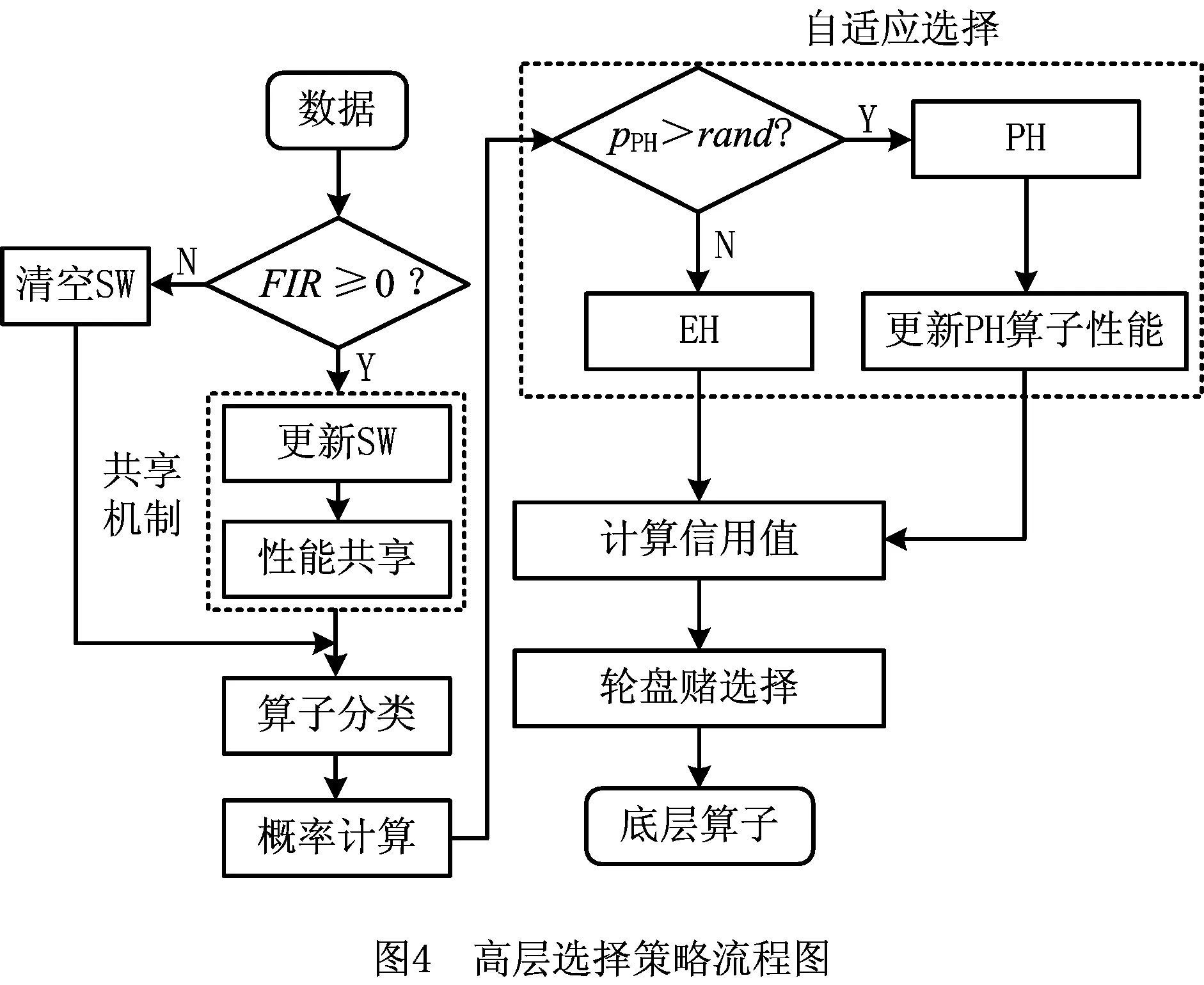
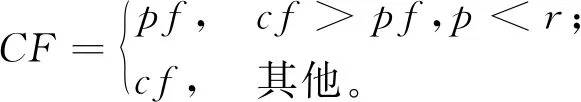
3.3 底层算子设计
3.4 算法复杂度分析
4 仿真实验与比较分析
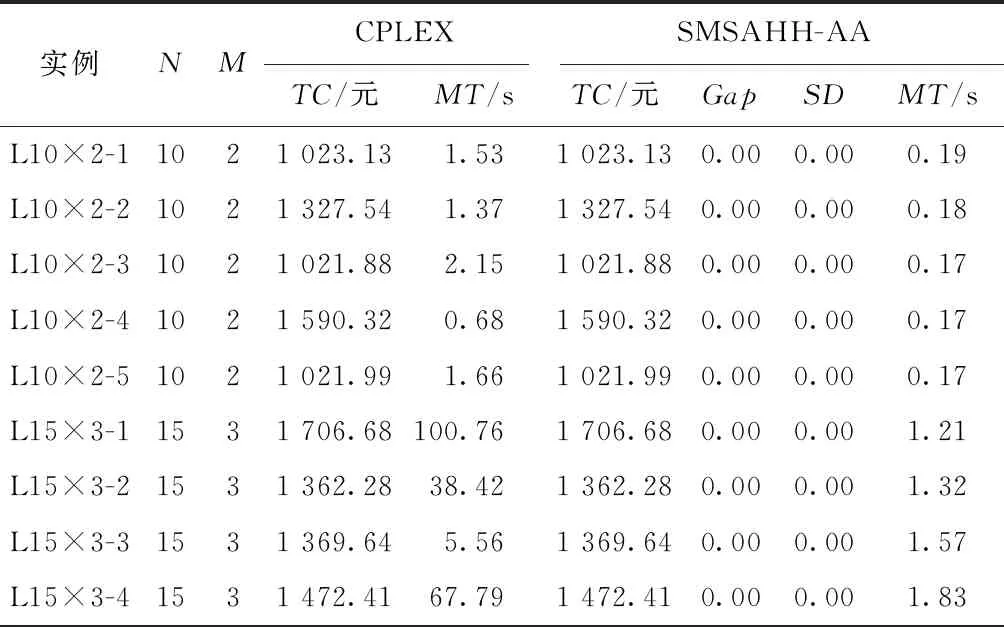
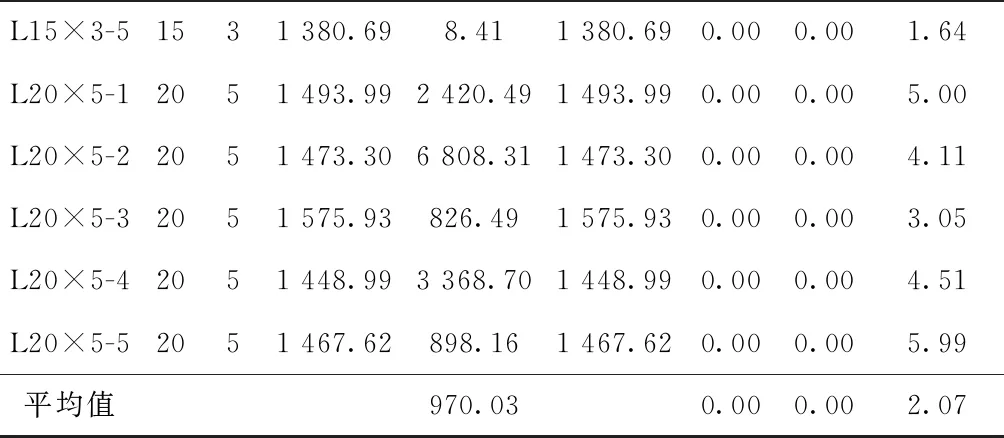
4.1 验证模型的正确性和算法求解的准确性
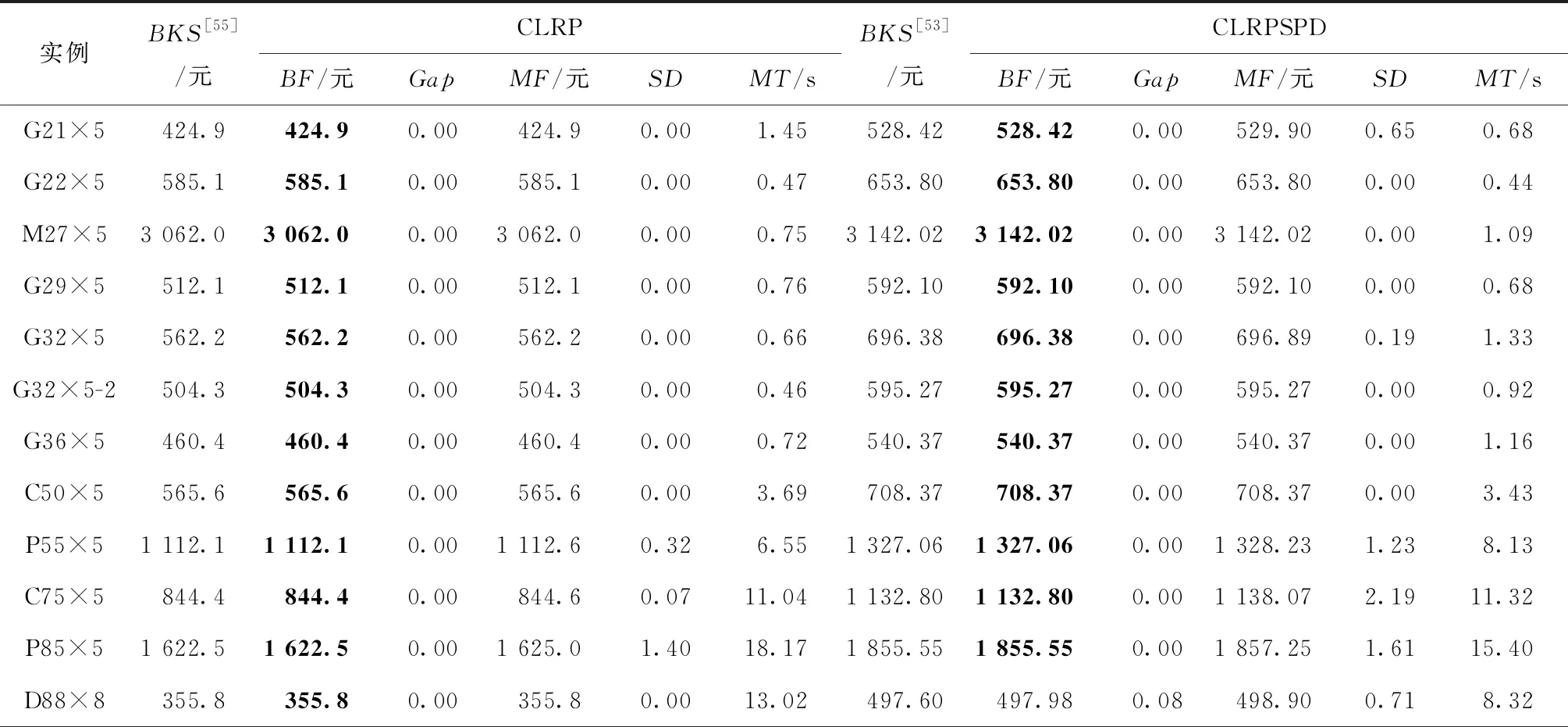
4.2 SSACM-AA高效性分析

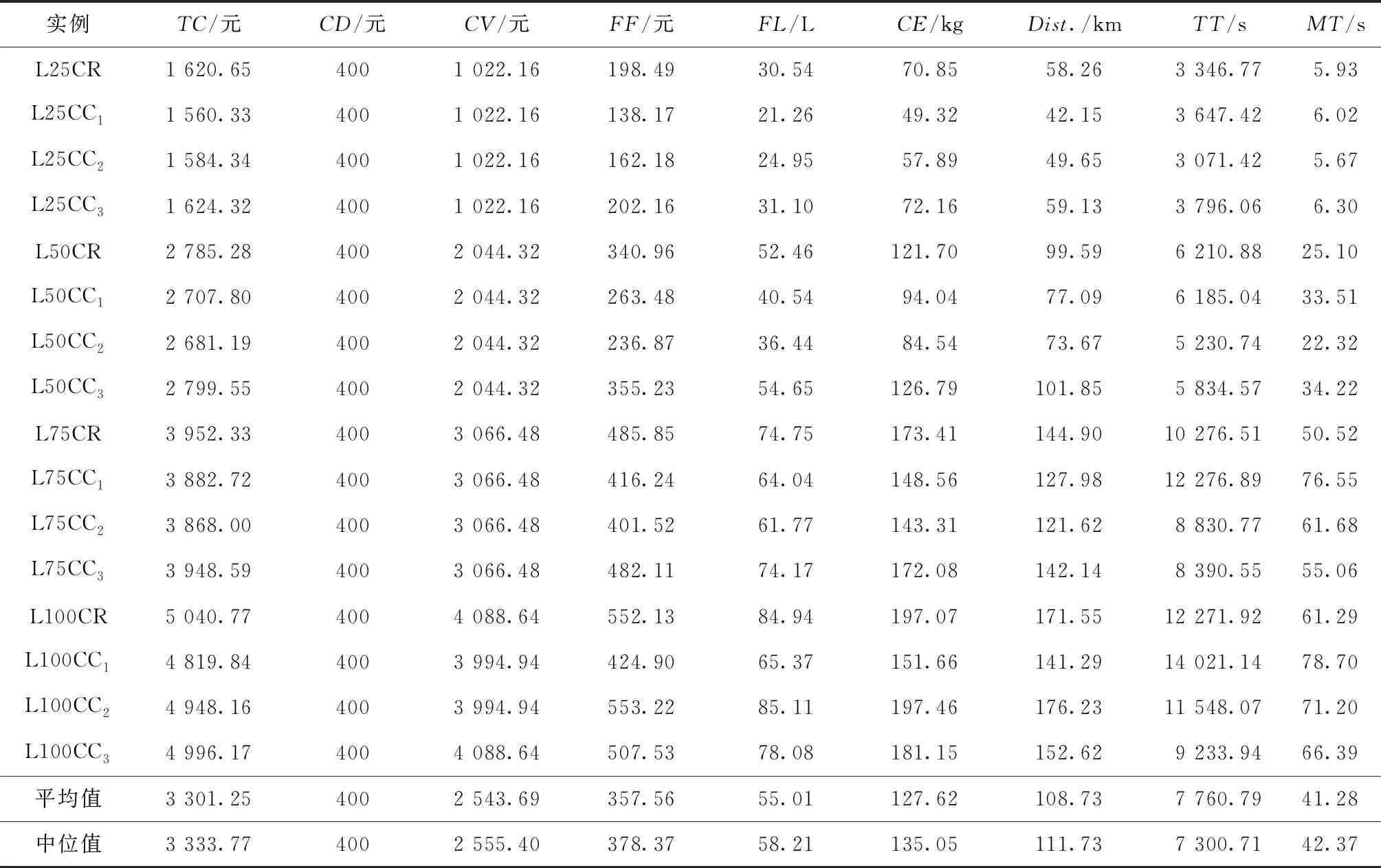
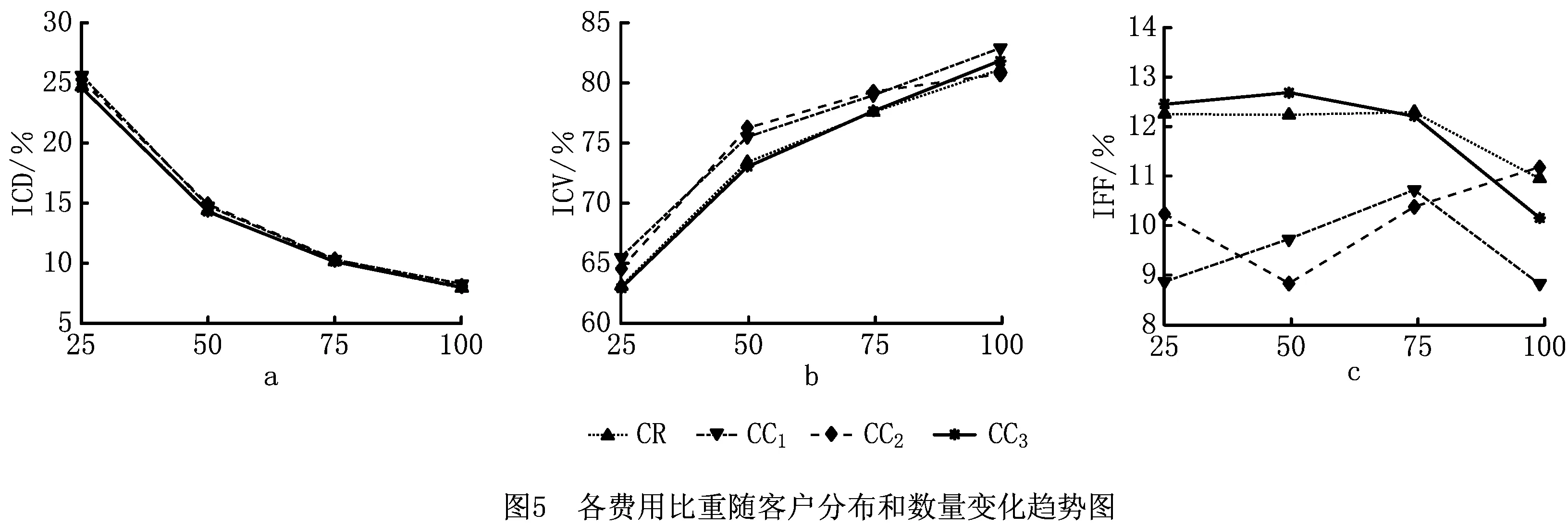
4.3 模型的有效性分析



5 结束语
猜你喜欢
小猕猴智力画刊(2022年11期)2022-11-28 02:49:08
数学物理学报(2021年2期)2021-06-09 08:54:26
小天使·一年级语数英综合(2020年11期)2020-12-16 02:57:22
应用数学(2020年2期)2020-06-24 06:02:44
学生天地(2020年34期)2020-06-09 05:50:40
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
数学物理学报(2016年3期)2016-12-01 05:36:27
火控雷达技术(2016年3期)2016-02-06 02:30:28
