
改进FasterR-CNN算法及其在车辆检测中的应用
2020-06-13 07:11魏子洋赵志宏赵敬娇
应用科学学报 2020年3期
魏子洋, 赵志宏, 赵敬娇
1.石家庄铁道大学信息科学与技术学院,石家庄050043 2.石家庄铁道大学省部共建交通工程结构力学行为与系统安全国家重点实验室,石家庄050043
随着智慧城市的兴起和计算机技术的发展,城市交通规划由传统的人工管理逐步向智能交通过渡.智能交通作为未来新型交通的发展方向,其核心任务之一就是对车辆进行管理,而车辆检测与识别是获取车辆信息并进行车辆管理的关键步骤.
传统的车辆检测方法主要通过知识和模型来刻画运动目标.其中,基于知识的方法是利用车辆的特征信息包括车辆轮廓[1]、车辆的对称性[2]、边缘纹理[3]和背景信息[4]等来检测车辆.单一特征进行车辆检测具有较强的局限性,因此常选择多个特征进行特征融合[5],从而提高检测精度.基于模型的方法则通过建立车辆模板[6]与待检测图像进行匹配,与特征模板相似的区域即被认定为检测结果.基于知识的方法与基于模型的方法也常常被结合起来使用[7],首先利用特征信息找到车辆的大致位置,再利用模型匹配进行精确定位,检测结果较两者单独使用都有提升.但是传统的检测方法具有明显的缺点和依赖性,基于知识的方法过度依赖设计的特征,且一种或几种特征也很难适应所有检测环境.当选择的特征不具通用性时会带来比较大的误差;基于模型的方法则过度依赖所建立的模型,由于车辆的多样性和拍摄角度的变化,一种或几种模型无法适应所有车辆.因此传统方法在背景多变的实际环境下很难取得较高的检测效果.
不同于传统的目标检测算法,基于深度学习的方法直接利用原始数据提取特征,甚至在训练过程中可以学习到许多潜在特征,从而有效地解决了人为设计特征的局限性问题.特别是卷积神经网络(convolutional neural network, CNN)在目标检测领域内的发展,以及R-CNN[8]、Fast R-CNN[9]、Faster R-CNN[10]一系列基于区域的网络模型的出现,使得检测效率和检测精度都得到了大幅度的提升.其中Faster R-CNN 模型将候选区域生成、特征提取、分类和位置精修4 大步统一到一个深度神经网络中,较Fast R-CNN 模型的检测速度提升了10 倍.文献[11]结合膨胀积累、区域放大、局部标注与自适应上下文等策略,将改进的Faster R-CNN 模型专用于空中目标检测;文献[12]则将Faster R-CNN 模型应用于难度更高的面部表情识别中.由此可见,Faster R-CNN 模型已在目标检测领域内得到广泛应用.于是本文尝试采用Faster R-CNN 模型进行车辆检测与车型识别.考虑到车辆的形态学特征,原始模型中锚点设置的3 种比例和3 种尺寸不完全符合车辆的外型特征,若在车辆检测任务中继续应用这9 种锚盒,一方面会造成初始候选框的冗余,另一方面粗糙的初始候选框会增加最终回归时的难度.因此,本文在使用Faster R-CNN 模型用于车辆检测时,利用K-means 聚类算法[13]对锚盒尺寸进行改进,使其产生的初始候选框更加符合车辆的形态学特征,进一步提高了检测精度.
1 Faster R-CNN 模型介绍
基于区域建议的R-CNN 系列模型是深度学习方法在目标检测领域的一个重要发展.R-CNN 模型从根本上解决了传统检测方法的特征选择问题,通过CNN 强大的学习能力提取由浅到深的各层特征,再结合所生成的候选框即可完成检测任务.R-CNN 系列模型有R-CNN、SPP Net、Fast R-CNN 和当下的代表模型Faster R-CNN.其中,R-CNN 使用选择性搜索方法对一幅图像生成了2 000∼3 000 个候选区域,然后对每个候选区域下的图像进行卷积操作提取特征,训练分类器得到物体类别,最后通过边框回归(bounding box regression,BBR)微调候选目标框的大小;Fast R-CNN 虽然仍使用选择性搜索方法搜索候选框,但它是对全图进行卷积操作提取特征,通过ROI 池化对特征图进行归一化,最后将分类和回归联合训练得到最终的候选框;Faster R-CNN 创新性地改善了选择性搜索方法,将搜索候选框的任务也分配给了神经网络,加入一个提取边缘的区域生成网络(region proposal network, RPN)以共享之前的卷积计算.从实现的功能上看,Faster R-CNN 可以看作由RPN 候选框生成模块与Fast R-CNN 检测模块两部分模块组成.Faster R-CNN 网络框架如图1 所示.

图1 Faster R-CNN 网络框架Figure 1 Network framework of Faster R-CNN
1.1 Fast R-CNN 部分
Fast R-CNN 部分主要包括特征提取、ROI 池化以及全连接层的分类和回归等处理.共享卷积层使用VGG16 或者ResNet[14]等常见的CNN 模型进行卷积和池化得到特征图,该特征图将共享给后续的RPN 和全连接层.经RPN 网络输出的区域大小和形状各不相同,但后续全连接层的输入尺寸必须是固定的.早期的R-CNN 和Fast R-CNN 通过对区域进行拉伸和裁剪得到固定尺寸,这种方法的缺点是破坏了图像的完整结构和原始形状信息.但ROI 层的改进则解决了这一问题,ROI 池化[15]将可变尺寸固定到同一长度,且不存在变形问题.经过归一化的特征图在其中一个全连接层通过softmax 进行具体类别的分类,另一个全连接层则进行边框回归以获取更高精度的回归框,最终输出检测结果.
1.2 RPN 部分
Faster R-CNN 最大的创新在于提出了一种有效生成目标候选框的方法,其本质就是用RPN 来提取检测区域,同时RPN 网络和整个检测网络共享全图卷积特征来缩短计算时间.RPN 网络流程图[10],如图2 所示.
输入图片经过共享卷积层得到Feature map,通过滑动窗口得到一个256 维长度的特征,然后对每个特征向量进行2 次全连接操作,一次得到2 个分数用来区分前景和背景,另外一次得到4 个坐标值表示初始候选框相较正确标注框的偏移量.其中,每个滑窗的中心点称为一个锚点,每一个锚点对应3 种比例(1:1, 1:2, 2:1)和3 种尺寸(1282, 2562, 5122)的锚盒,这样经过每一次滑动都会产生9 个固定的区域建议.特征图的大小是16×16,进入RPN 阶段后首先经过一个3×3 的卷积,得到一个256×16×16 的特征图,也可以看作16×16 个256 维特征向量,然后经过2 次1×1 的卷积,分别得到1 个18×16×16 的特征图和1 个36×16×16 的特征图.前者的特征图包含2 个分数,后者的特征图包含4 个坐标值,结合预先定义的锚点便可以得到候选框.
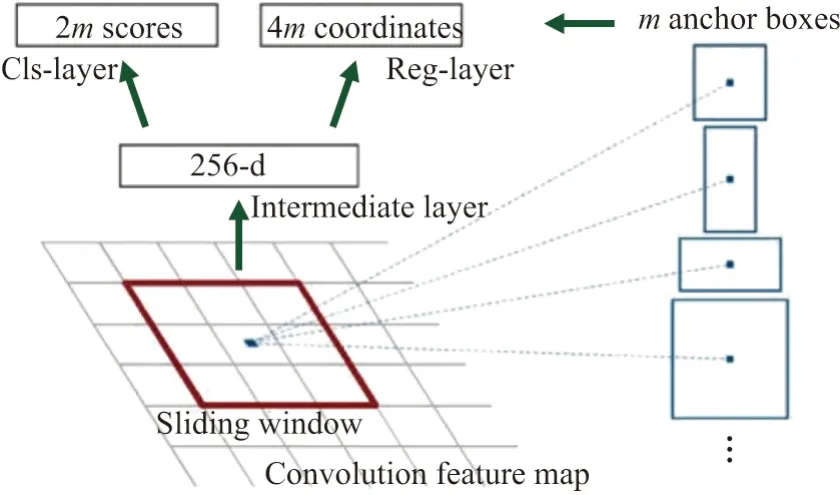
图2 RPN 网络流程图Figure 2 Network flow chart of RPN
2 改进的Faster R-CNN 算法
Faster R-CNN 中的RPN 网络解决了候选框的生成问题,但是RPN 中锚点设置的3 种比例和3 种尺寸适应外型相差较大的目标检测,在处理特征相近的检测目标时往往会产生误差较大的初始候选框.为了得到符合车辆形态学特征的初始候选框,可以利用K-means 算法对锚盒尺寸进行聚类.具体步骤如下:
步骤1对数据集中所有检测车辆进行手工标记,提取每一标注框对应的宽高值;
步骤2按照欧氏距离把相似度高的数据聚类为同一簇,则聚类中心的分布就代表了数据集中绝大多数车辆宽度和高度及其比值的分布;
步骤3按照K值对应的聚类中心坐标值修改原锚盒尺寸和比例,然后分别进行训练与测试,根据检测准确率即可确定车辆检测任务中更理想的锚盒尺寸和比例值.
2.1 K-means 算法
K-means 聚类算法属于无监督算法[16],在数据标签信息未知的情况下,直接对未标记样本进行距离相似度的判断.该算法定义两个对象之间的距离与其相似度成反比,距离越近则相似度越高,因此其目的是使输出的簇具有簇内差异尽可能小、簇间差异尽可能大的特点.K-means 算法描述如下所示:
步骤1输入样本数据.设定分类数K,第1 次随机生成K个初始聚类中心点.
步骤2根据现存的聚类中心点将数据划分为K个簇.对数据中任意一个样本点,计算其到各聚类中心点的距离,该样本归属于距其距离最短的中心点所在的类.距离计算函数为

式中,K为聚类数,n为样本总数,xi为样本点,uj为聚类中心点.
步骤3更新聚类中心.所有样本点分类完成之后,按照均值法计算每个簇的平均值,以此作为新的聚类中心点.
步骤4迭代法重复步骤2 和3,直到聚类中心不再变化.
2.2 锚盒尺寸聚类算法
原始Faster R-CNN 模型用于检测20 类物体,包含人、车、飞机、动物等,其检测目标形态各异且差异明显.面对车辆检测任务及具体车型的车辆识别时,除复杂的背景环境所带来的的干扰以外,轿车与SUV、SUV 与小客车、大客车与货车的相似度已经非常高,此时若仍采用原始锚盒尺寸不但很难得到较为准确的初始候选框,而且大大增加了生成候选框的无关计算量.为了充分利用车辆的形态学特征,同时对训练集进行二次利用,提出一种结合K-means 聚类的锚盒尺寸确定方案.
步骤1利用LabelImg 工具对数据集进行手工标注,每幅图片中的每一个车辆目标都被唯一的标注框所确定,所有标注框的信息都在所属图片对应的XML 配置文件中.XML 中的信息如下.

步骤2提取XML 文件中每一个标注框左下角与右上角的坐标点,坐标值相减的差值即为标注框的宽度和高度,记录差值作二维向量(w,h).
步骤3所有标注框的(w,h)作为K-means 聚类输入,考虑到原始Faster R-CNN 设定的3 种比例和尺寸以及本文需检测4 种车型,分别选择K为3、4、5 进行聚类,初步评价聚类结果,舍弃聚类效果不明显的K值及其对应的聚类中心点坐标.
步骤4以包含聚类中心点坐标值的宽高值及其比例设置新的锚盒尺寸值和比例,代替原始锚盒的3 种尺寸1282、2562、5122以及3 种比例1:2、1:1、2:1.
步骤5使用同一训练集对原模型及锚盒修改后的模型分别进行训练,在同一测试集下进行车辆检测,准确率最高的模型所对应的锚盒设定值即为更适合车辆检测任务的锚盒尺寸.
3 实 验
3.1 实验数据
本文实验数据来自不同高速路段摄像头抓拍下的分辨率为1 069×500 的车辆图像共2 000 幅,包括轿车、SUV、客车和货车4 种车型,每幅图像内均包含多个车辆目标,典型数据集图像如图3 所示.

图3 车辆检测数据集典型图片Figure 3 Representative picture of vehicle detection data set
3.2 聚类实验
计算XML 文件中所有标注框坐标的差值得二维向量,以此作为K-means 聚类的输入.在聚类算法中K值的选取对聚类结果会产生很大的影响,因为本文检测识别的车型共4 类,结合原始模型锚点设置的3 种比例和尺寸,故分别选择K为3、4、5 进行聚类实验,聚类结果如图4 所示.
K-means 根据数据间的相似度进行聚类,通过把相似度较高的点划分到同一个簇中,得出的聚类中心就可以表示数据的分布.仅从聚类结果分析,K为3、4、5 划分的簇均表现出簇内差异较小,簇间差异明显的特征,因此不能简单地直接舍弃某一K值.为了验证不同K值对检测结果的影响,保留3 种聚类结果,依据每一K值下的聚类中心坐标修改原锚盒初始值,训练测试并与原Faster R-CNN 检测结果进行对比.
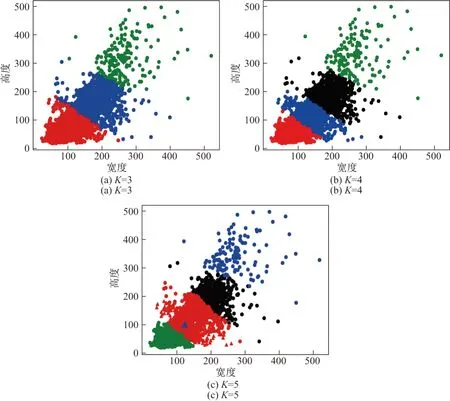
图4 不同K 值的聚类结果Figure 4 Clustering results with different K
模型A:K= 3 得到的聚类中心点所代表的尺寸集中在702∼3202之间,高度与宽度比值在0.75∼1.19 之间,故设定模型A的锚盒尺寸为562、1282、2562、5122,比值为0.75、1.00、1.25.
模型B:K= 4 得到的聚类中心点所代表的尺寸集中在602∼3302之间,高度与宽度比值在0.69∼1.21 之间,故设定模型B的锚盒尺寸为562、1282、2562、5122,比值为0.50、0.75、1.00、1.25.
模型C:K= 5 得到的聚类中心点所代表的尺寸集中在562∼3502之间,高度与宽度比值在0.68∼1.32 之间,故设定模型C的锚盒尺寸为562、1282、2562、5122,比值为0.50、0.75、1.00、1.25、1.50.
不同K值的聚类中心点坐标如表1 所示.
3.3 检测结果
为了提高训练效率,使用经过ImageNet 数据集预训练好的VGG-16 模型作为初始模型.网络模型的训练和测试均基于深度学习框架tensorflow 完成,实验环境为戴尔(DELL)Precision T7920 塔式图形工作站,主频2.1G,64G 内存,显卡为P5000.
首先使用原始Faster R-CNN 模型进行训练和测试.训练超参数设置如下:总训练次数为6 000,batch size 为128,初始学习率Rl=0.001,学习率下降值为0.1,经NMS 后RPN 候选框的数目为300.原始模型的检测结果如表2 所示.
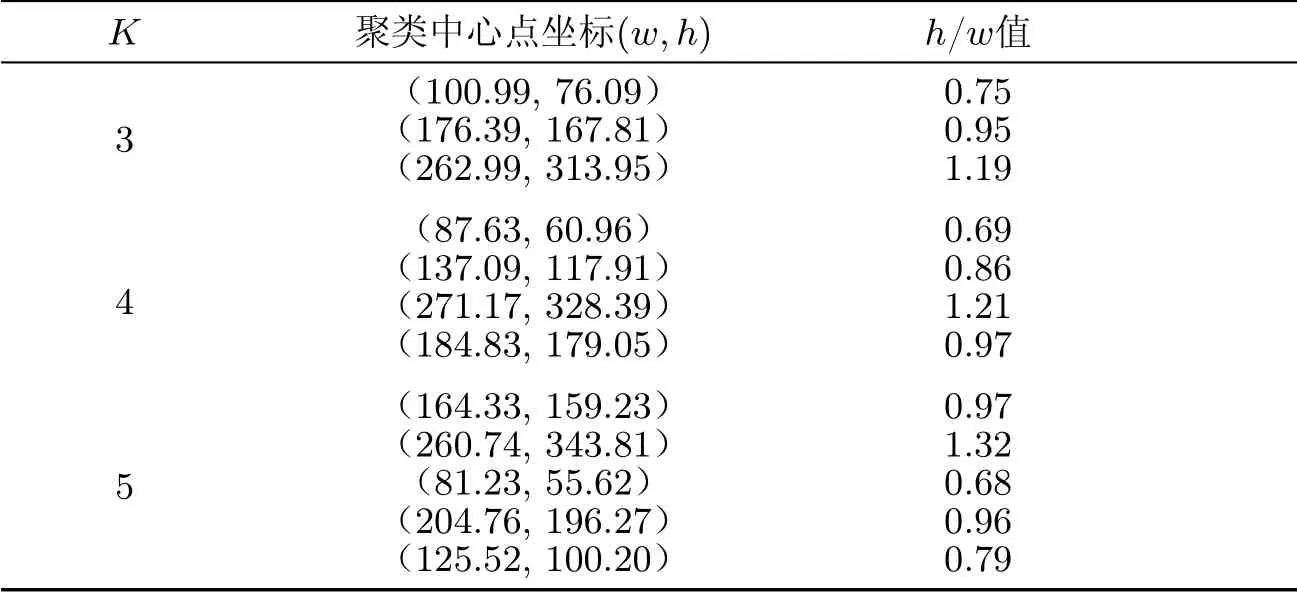
表1 不同K 值聚类中心点坐标Table 1 Cluster center point coordinates under different K

表2 原始Faster R-CNN 模型检测结果Table 2 Test results of original Faster R-CNN model
由表2 可知,原始模型的检测准确率为83.42%.客车的检测准确率最高,货车的检测准确率最低.漏检和误检总数为122,其中漏检数目占误检和漏检总数的81.15%,漏检比例最高的为货车和轿车,且大多数漏检目标为遮挡程度较高的车辆;误检数目占误检和漏检总数的18.85%,误检车型集中在SUV 和货车之间.
为了验证锚盒尺寸修改后的检测效果,按照控制变量法的要求保持测试集和超参数的设置不变,修改锚盒尺寸和比例后得到的模型A、B和C的检测结果如表3 所示.

表3 不同模型的检测准确率Table 3 Detection accuracy of different models %
分析表3 可知,模型A检测的总准确率为82.95%,较标准模型下降0.47%.其中,轿车准确率上升3.22%,货车准确率上升6.10%,SUV 准确率下降8.23%,客车准确率下降4.97%.模型A正确检测出更多数量的轿车和货车,但不足以弥补SUV 和客车检测准确率的下降,总体上表现不如原模型,与模型C相比下降3.59%.
模型B检测的总准确率为83.09%,较标准模型下降0.33%.其中,轿车准确率上升0.91%,货车准确率上升9.76%,SUV 准确率下降9.01%,客车准确率下降1.11%.模型B同样正确检测出更多数量的轿车和货车,但不足以弥补SUV 和客车检测准确率的下降,总体上表现和模型A相近,与模型C相比下降3.45%.
模型C检测的总准确率为86.54%,较标准模型提高3.12%.其中,货车检测准确率提升最多,达12.20%,其余车型的检测准确率也有上升.模型C的检测准确率比模型A提高3.59%,比模型B提高3.45%.因此模型C及其锚盒设定值在车辆检测任务中的表现更优异.

图5 模型C 与原始Faster R-CNN 检测结果对比图Figure 5 Comparison between model C and original Faster R-CNN
每次检测实验,置信度的设置均为0.8,即至少有80%的概率认定框内的物体为检测目标才会标注出来,图5 为模型C与原始Faster R-CNN 模型检测结果对比图.从图(a)和(b)中可以看出,被背景遮挡程度较高的车辆目标未被检测出来,原因之一可能是置信度大于0.6但不足以达到0.8,原因之二可能是遮挡程度太大导致根本检测不出来.改进后的模型不但将遮挡目标检测出来,而且对该车的检测框预测较为准确;从图(c)和(d)中可以看出,多车位置重叠导致其一被遮挡的也未被检测出来,这主要是由于两个目标车辆位置相近且特征相似造成的干扰.改进后的模型检测出遮挡车辆,可见锚盒修改后的检测效果更好.
4 结 语
针对车辆检测任务,本文提出了一种结合K-means 聚类算法的Faster R-CNN 改进模型.通过对车辆标注框的宽高值进行K-means 聚类,按照聚类中心点坐标值设置新的锚盒尺寸和锚盒比例,所生成的初始候选框将更加符合车辆的外型特征,从而减少无关候选框的生成及候选框在回归精修时的计算量.实验结果表明,该算法达到86.54%的检测精度,相比原始Faster R-CNN 模型,有效改善了漏检和误检问题.在后续研究中,可考虑对回归算法进行改进,进一步提高车辆检测的精度和准确率.
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
计算机技术与发展(2020年2期)2020-04-15
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年4期)2019-09-10
火力与指挥控制(2018年3期)2018-04-19
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
