
铁塔航拍图像中鸟巢的YOLOv3识别研究
2020-06-11 07:46钟映春孙思语罗志勇熊勇良何惠清
广东工业大学学报 2020年3期
钟映春,孙思语,吕 帅,罗志勇,熊勇良,何惠清
(1. 广东工业大学 自动化学院,广东 广州 510006;2. 广州市树根互联技术有限公司,广东 广州 510308;3. 广州优飞科技有限公司,广东 广州 510830;4. 国家电网江西省萍乡供电公司,江西 萍乡 330000)
电力铁塔是电力架空输电线路的主要支撑金具[1]。如果铁塔、架空输电线路上存在鸟巢、风筝等异物会严重影响架空输电线的安全[2-3]。为此,架空输电线路需要进行定期巡检。采用多旋翼无人机巡检是当前架空输电线路巡检的重要方式之一[4-5]。无人机在巡检过程中会针对电力铁塔进行专门拍照成像,而后通过人工检测或者模式识别的方式检测铁塔航拍图像中是否存在鸟巢、风筝等异物。无人机拍摄的电力铁塔图像数量大,采用人工检测方法效率低下,为此有必要研究自动识别铁塔航拍图像中鸟巢等异物的方法。
在从图像中检测识别鸟巢的研究中,Wu等[6]提出采用条纹方向直方图和条纹长度直方图描述鸟巢的特征,并将其用于高铁架空输电线接触网系统中鸟巢的检测识别。实验表明,该方法的识别精度在35%~40%范围内。由于识别精度不高,难以在实践中使用。徐晶等[7]将巡检图像分为若干图像子块,分析各个图像子块中不同方向的线段密度,从而判决某个图像子块是否属于铁塔区域;而后,在包含铁塔区域的图像子块内,搜索符合鸟巢样本的HSV(Hue Saturation Value)颜色特征量的连通区域,作为候选的鸟巢区域;再分析候选鸟巢区域的形状特征参数:描述鸟巢粗糙度的灰度方差特征量,描述鸟巢纹理的惯性矩特征量等,并以这两个特征作为鸟巢识别的依据,判断图像中是否包含鸟巢。实验表明,检测精度在87.5%左右,识别精度较好,但是对于纹理特征不明显的鸟巢,其识别精度有限。Lei等[8]采用Fast R-CNN方法识别无人机航拍图像中的绝缘子缺陷和鸟巢。结果表明,平均检测精度可以达到97.6%,但是每张图像的识别时间长达201 ms。这种检测方法虽然精度较好,但是识别效率偏低,且权重参数规模未知,难以应用于无人机巡检过程中的实时检测。
在无人机巡检电力输电线路的过程中,会产生大量的铁塔航拍图像。为了能够自动检测铁塔航拍图像中的鸟巢,并着眼于未来无人机在巡检过程中能够实时识别特定的目标物,本文改进了经典的YOLOv3(You Only Look Once-Version 3,YOLOv3)算法,并试图在平均识别精度、识别效率和权重参数规模3个方面取得平衡。首先,本文设计了铁塔航拍图像中鸟巢识别的总体架构;其次,本文构建了用于训练和测试的铁塔图像数据集;第三,本文分别从预测框的宽高损失函数、预测类别不平衡损失函数和神经网络结构等3个方面对经典YOLOv3算法进行改进;最后进行了改进算法的测试和对比实验。
1 总体架构设计
本文设计的铁塔航拍图像中鸟巢识别的总体架构如图1所示,包括构建图像数据集、构建识别算法和结果分析等主要过程。

图 1 铁塔航拍图像中鸟巢识别的架构Fig.1 Structure of bird’s nest detection in aerial image of transmission tower
构建数据集主要是进行图像尺寸归一化、图像扩增和图像标注。构建识别算法中对经典YOLOv3算法中预测框的宽高损失函数、预测类别不平衡的损失函数、神经网络结构3个方面分别进行改进及对比实验。最后用平均精度值和F1评价指标对改进前后的算法性能进行评估。
2 构建图像数据集
本文所使用的图像数据集,是无人机在巡检国家电网江西省某供电公司输电线路的过程中实际拍摄的图像。由于获取的图像来自于不同无人机上不同类型和厂家的摄像头,且拍摄角度和图像尺度不同,为了能够完成识别检测,将所有图像像素归一化[9]为416×416。
2.1 图像扩增
由于铁塔航拍原始图像共有3 380张,总体数量不多,为了尽量减小在训练过程中产生的过拟合,本文采用了图像扩增技术[10],主要包括:
(1) 按照一定的比例放大或者缩小原始图像。
(2) 随机旋转原始图像。
(3) 随机移动原始图像,改变图像内容的位置。
(4) 在原始图像中适当增加噪声,如椒盐噪声和高斯噪声。
经过扩增后共得到图像13 316张,按照3∶1的比例分为训练集与测试集,故一共有9 986张训练集图像,3 330张测试集图像,训练集与测试集的图像是原始图像数据集随机分配的。任意挑选一张铁塔图像及其变换图像如图2所示。

图 2 图像扩增示例Fig.2 An example of increasing the number of images
2.2 图像标注
本文使用LabelImg软件作为标注工件,对图像数据集中鸟巢的类别和位置进行标注[11]。
3 构建识别算法
3.1 经典的YOLOv3算法
经典的YOLOv3算法的核心是一个端到端的卷积神经网络算法(Convolution Neural Network,CNN)[12]。该算法含有卷积层、残差层和3个尺度的特征交互层,采用1×1卷积块进行降维,后面是3×3卷积层,初始卷积层和残差层从图形中提取特征,3个尺度的特征交互层负责预测输出目标的概率以及坐标参数。
经典的YOLOv3算法具有以下几个主要特点:(1) 该算法采用一个CNN网络来实现检测,并采用一种单管道策略训练与测试,故而训练和识别速度比其他CNN算法的效率更高。(2) 该算法是对整张图片做卷积,3个尺度的特征交互层起到了凝聚注意力的作用,使得其在检测目标有相对更大的视野,不容易对背景进行误判。(3) 该算法的泛化能力比其他CNN算法更强,在做迁移学习时,鲁棒性更高。
3.2 改进的YOLOv3算法
在将经典的YOLOv3算法用于识别电力铁塔航拍图像中的鸟巢时,存在识别率不够理想、识别效率不高、权重参数规模过大等不足。为此本文对YOLOv3算法进行以下改进。
3.2.1 改进预测框的宽高损失函数
原始的YOLOv3算法中采用二元交叉熵损失函数(Binary Cross-entropy Loss),主要由预测框的中心点坐标损失、预测框的宽高损失、预测类别不平衡损失及预测框的置信度等4个部分组成。其中,预测框的宽高损失函数为
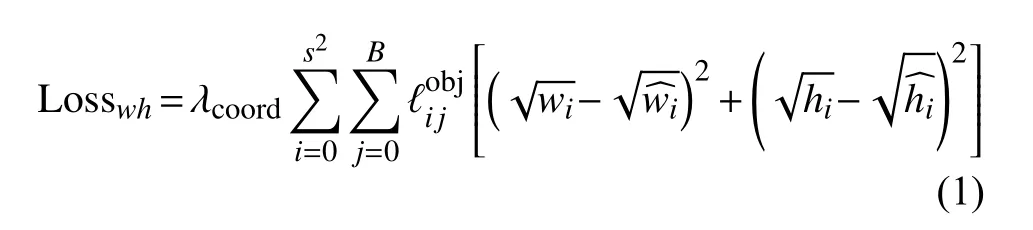
该函数计算了每个网格单元 (i=0,1,···,S2)的每一个候选边界框( j=0,1,···,B)与真实目标边界框的宽高误差总和。其中,λcoord是 一个常数。主要是判断第 i 个单元格中第 j个边界框是否含有这个目标,如果负责预测这个目标则为1,不负责则为0。wi为第i 个预测框宽度。为真实目标边界框宽度。hi为第i 个预测框高度。为真实目标边界框高度。
分析电力铁塔航拍图像可见,由于无人机拍摄的角度和拍摄距离各不相同,使得在铁塔航拍图像中鸟巢的尺度有大有小,相差很大。此外,在整个图像数据集中,小尺寸的鸟巢数目远远多于大尺寸的鸟巢数目。若沿用经典算法中的损失函数,将严重影响识别精度。为此,本文用类似于归一化的思想对预测框的宽高损失函数进行改进,以缓解图像中物体大小不一的情况[13]。改进后的预测框宽高损失函数为


3.2.2 改进预测类别不平衡损失函数
分析原始的电力铁塔航拍图像可见,平均一张航拍图像包含1.6个鸟巢,图像中的大部分内容是背景物体。背景物体过多,就会在总损失函数L oss中占据主导地位,而目标物体鸟巢在总损失函数 Loss中的占比较小。这种情况称为预测类别的不平衡。为了减小这种类别之间的不平衡,本文在原始的二元交叉熵损失函数的基础上,结合Focal Loss算法的思路,重新定义预测类别不平衡的损失函数,以改进原来的类别不平衡问题[14]。
在经典的二元交叉熵损失函数中,各个训练样本交叉熵的直接求和可以得到分类的损失函数LossCE:
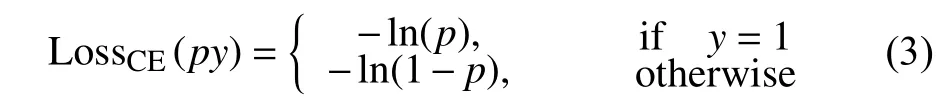
因为在铁塔图像中检测识别鸟巢是一个二分类问题,即将图像中的目标物确定为是鸟巢或者不是鸟巢物体,所以在公式中只有两种情况。式(3)中, p表示候选框内目标物属于鸟巢的概率。y表示目标物的标签Label,y 的取值为{+1,-1}。y =1表示目标物为鸟巢,y =-1表示目标物为其他物体。当候选框内目标物属于鸟巢,也就是y =1时,则该候选框内目标物预测为1的概率值越小,损失就越大。
为了表示简单,用 pt表示候选框中目标物属于鸟巢的概率,公式(3)可以写成
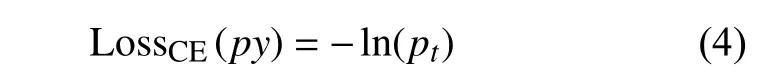
为了减小类别之间的不平衡,本文改进损失函数为

式(5)中,专注参数 γ可以通过减少易分类样本的权重,相对增加难分类样本的权重,从而使得模型在训练时更专注于难分类的样本。 αt是本文定义的权重系数。通过该系数可以调整正负样本的权重,还可以控制难易分类样本的权重。
3.2.3 改进神经网络结构
针对经典YOLOv3算法的神经网络结构,本文从以下两个方面进行改进:
(1) 因为采用了多尺度特征交互层融合检测算法,经典YOLOv3算法对尺度比较小的目标物体的识别率相比于CNN有显著提高。经典的YOLOv3算法所得最大特征图像素达到52×52。由于鸟巢在本文的图像数据集中属于尺度比较小的目标物体且频繁出现,为了进一步提高鸟巢的识别率,本文通过修改特征金字塔网络的连接层数,使其最大特征图达到像素104×104,从而在识别小目标方面具备比原有算法更好的效果。
(2) 经典的YOLOv3算法采用了ResNet神经网络的思想。研究表明,在权重参数规模和识别率方面,当前主流的DenseNet神经网络具有比ResNet神经网络更优的性能[15]。为了提高YOLOv3算法的性能,本文根据DenseNet神经网络的思路对经典的YOLOv3算法进行改进。
根据DenseNet神经网络的思想,对原神经网络结构改造时,为了加强对比性,也将输入的图像像素设为416×416。保留ResNet神经网络的前3层,后面加入类似于DenseNet神经网络的结构。与原ResNet神经网络不同的是,为了使最终输出的特征图像素变为13×13,将原ResNet神经网络的第2层中的平均池化改为最大池化,并将分类层去掉,而且在最后加上3个尺度的特征交互层。
改进后的YOLOv3算法的神经结构,如图3所示。
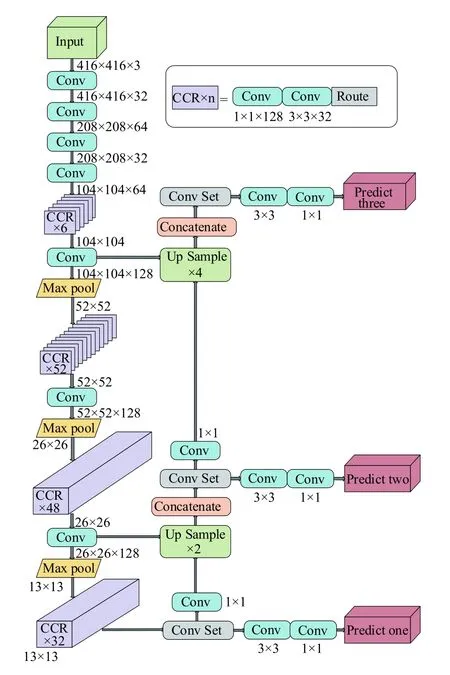
图 3 改进神经网络结构的YOLOv3Fig.3 Improved neural network of YOLOv3
4 实验过程与结果分析
4.1 实验环境
实验的硬件环境为:采用i7-6700KCPU,32G内存,NVIDIA公司的GTX1070系列GPU卡,显存为8G,有1 920个CUDA内核,内存带宽256 GB/s。
实验的软件环境为:操作系统为Windows10,编程环境为VS2015,darknet,CUDA9.0,cuDNN7.0。在数据集扩增阶段以及实验结果分析也用到Keras深度学习框架。
4.2 评价指标
本文采用平均精度值(Mean Average Precision,Map)、F1指标对改进前后的算法性能进行评价[16]。
其中,Map值的含义为:针对每一个不同的召回率(Recall,R)值(在0到1之间每隔0.1取一个点,共11个点),选取其大于等于这些R值时的查准率(Precision,P)最大值,然后计算查准召回值PR(Precision Recall,PR)[17]曲线下面积最大值为平均查准值AP(Average Precision,AP),然后计算所有类别AP的平均值就是检测到目标的平均精度值Map。
此外,本文采用F1指标进行算法性能评价。
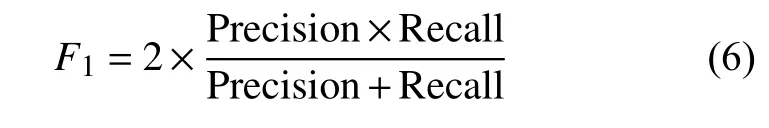
F1指标综合表达了召回率R和查准率P相互促进又相互制约的关系,可以在二者之间进行平衡。F1值越高,物体识别算法就越好。
所有实验均是从数据集中随机选取9 986张图像作为训练集,其余3 330张图像作为测试集。迭代次数为30 000次,采用分布策略的学习率和随机多尺度训练方式。在实验过程中,仅改变算法相关的参数,而其他参数都保持不变。
设计进行3组实验。实验1:在经典的YOLOv3算法基础上,改进预测框的宽高损失函数;实验2:在实验1的改进基础上,叠加预测类别不平衡损失函数的改进;实验3:在实验2的改进基础上,叠加神经网络结构的改进。
4.3 实验1的结果分析
采用图像数据集对经典的YOLOv3算法和预测框的宽高损失函数改进后的YOLOv3算法进行训练和测试,相应的损失函数Loss曲线以及Map曲线如图4所示。在图4中,蓝色曲线为经典的YOLOv3算法结果,绿色曲线为实验1结果,由图4可见:

图 4 实验结果Fig.4 Results of experiment
(1) 训练迭代次数达到30 000次,原始YOLOv3算法和预测框的宽高损失函数改进后的YOLOv3算法均趋向收敛,Map值达到稳态。
(2) 对比蓝、绿两条Map曲线,算法改进前的Map值波动幅度较大,准确率略低;而改进后的Map值波动幅度减小,准确率整体上升1%~3%,且迭代约17 000次开始就进入稳态,稳定在89%左右。
由此可见,改进预测框的宽高损失函数后,YOLOv3算法的识别精度与鲁棒性得到一定程度的改善。
4.4 实验2的结果分析
在实验1的基础上,叠加进行预测类别不平衡损失函数的改进实验,相应的损失函数Loss曲线以及Map曲线如图4中黄色曲线所示。
在实验中,设置式(5)中的参数α为0.5,γ为2,此时的识别效果较好,由图4可见:
(1) 实验2的改进算法损失函数趋向收敛,且Map值在大约迭代11 000次就进入稳态,早于经典算法和预测框的宽高损失函数改进的算法。
(2) 改进预测类别不平衡损失函数后的算法的Map值稳定达到89%左右,迭代后期整体高于经典算法和实验1改进的算法。
由此可见,预测类别不平衡损失函数改进后,YOLOv3算法的识别精度和训练时间得到一定程度的改善,且改善效果比实验1效果更好。
4.5 实验3的结果分析
在实验2的基础上,叠加进行神经网络结构的改进实验,实验结果如图4中红色曲线所示,由图4可见:
(1) 改进神经网络结构后的算法损失函数趋向收敛,且Map值在大约9 000次迭代准确率逐渐上升,22 000次迭代进入稳态。
(2) 神经网络结构后的算法的Map值稳定达到97%左右,明显高于经典算法和其他改进算法。
由此可见,神经网络结构改进后,YOLOv3算法的性能得到显著改善。
4.6 实验结果汇总与分析
实验1至实验3获得的实验结果如表1所示。

表 1 实验结果汇总Table 1 Summary of experimental results
(1) 改进预测框的宽高损失函数主要是针对大小目标的误差对整体损失代价不一样提出的,经过归一化的标记框的宽和高,能使大小目标的影响保持一致,就能检测更多的小目标,Map最大值可以提高1.5%,F1值提高0.03。由于归一化后的损失函数计算量较小,训练时间比原始算法缩短2 h。权重参数规模与经典算法一样。
(2) 改进预测类别不平衡损失函数后,Map曲线相对来说波动小一点,鲁棒性更好,比经典算法更快达到稳定的精度。这是因为算法加强了对鸟巢目标的训练,从而适当提高了精确率。与经典算法相比,Map最大值可以提高2.2%,F1值提高0.04。但是,由于改进了损失函数,训练时间达到75 h。然而,由于忽略了部分背景的影响,识别时间减小3~4 ms。权重参数规模与经典算法一样。
(3) 对YOLOv3算法中的神经网络结构进行改进,可以在不降低识别精度情况下缩减权重参数规模,以便将来在无人机上实时检测识别鸟巢。实验结果证明,神经网络结构改进后,Map值提高10.5%,F1值提高了0.08,识别时间为40 ms,权重参数规模减小了41.7%。由此可见,相比经典算法和其他改进算法,虽然神经网络结构改进使得识别时间略有增加,但是也可以达到25帧/s 的识别效率。更重要的是在权重参数规模大幅度减小的同时,Map值得到了明显提高。这为在无人机巡检过程中实时识别奠定基础。
将所有的改进措施融合到一个算法中进行鸟巢识别,并与改进前的算法识别对比,任意挑选一组识别结果如图5所示。

图 5 算法改进前后的鸟巢识别结果对比Fig.5 Results comparison of bird’s nest recognition of original and improved YOLO V3
对比图5(a)和(b)可见,经典的YOLOv3算法只能识别1处鸟巢,见图5(a)中1处标注有nest字符的方框。改进后的算法可以识别出2处鸟巢,见图5(b)中2处标注有nest字符的方框。改进算法的识别结果与人工识别结果相同。
5 结论
针对经典YOLOv3算法在识别电力铁塔航拍图像中的鸟巢过程中,存在识别精度欠佳、识别效率不高、权重参数规模过大等不足,本文分别从3个方面提出了改进措施:预测框的宽高损失函数的改进、预测类别不平衡损失函数的改进和神经网络结构的改进。实验结果表明:(1) 改进预测框的宽高损失函数可以适当提高识别的Map值和F1值,训练时间略有减少,识别效率略有提高,权重参数规模保持不变;(2) 改进预测类别不平衡损失函数可以适当提高识别的Map值和F1值,训练时间略有增加,识别效率有明显提高,权重参数规模保持不变;(3) 改进神经网络结构可以明显提高识别的准确性,并且可以显著减小权重参数规模,代价是训练时间会增加一些,但是识别效率可以满足实时性要求。由此可见本文提出的改进措施切实有效,可以在提高识别精度和保持识别效率的同时,显著减小权重参数规模;对于YOLOv3而言,改进其神经网络结构的效果明显好于其他改进措施。这可能是今后此算法改进的主要方向之一。本文的探索为将来在无人机巡检过程中实时识别目标物奠定了重要基础。
猜你喜欢
中国化肥信息(2022年3期)2023-01-05
时代邮刊·下半月(2020年9期)2020-09-23
阅读与作文(小学低年级版)(2020年2期)2020-05-25
学苑创造·A版(2020年4期)2020-04-24
小学生学习指导(低年级)(2018年9期)2018-09-26
金桥(2018年6期)2018-09-22
小星星·阅读100分(高年级)(2018年5期)2018-06-12
小学生优秀作文(低年级)(2018年6期)2018-05-19
作文通讯·高中版(2017年6期)2017-07-10
移动通信(2014年17期)2014-10-16
