
关于大数据系统架构分析及技术发展探讨
2020-06-08 10:26蔡宏
电脑知识与技术 2020年10期
蔡宏

摘要:随着网络中海量的半结构化、非结构性数据的出现,如何有效地对这些海量数据进行处理,成为人们面临的一个重要问题,采用大数据技术能够有效地解决这一问题,针对当前大数据系统架构的主要特征进行分析,探究了大数据系统的生态结构,详细地分析了大数据应用的关键技术,通过对大数据的具体应用进行分析,对提高大数据的应用具有十分重要的意义。
关键词:大数据;系统架构;技术
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2020)10-0001-03
當前,随着web3.0的发展,移动网络、智能设备、传感器、扫描设备等各种智能设备的应用,源源不断的产生大量的、结构性、非结构性的数据,人们的生活与各个层面的数据息息相关,在网络中不仅存在大量的静态数据,还存在大量的动态数据。大数据已经渗透应用到了众多行业,为企业提供决策支持具有十分重要的作用,而且庞大的数据资源对国家的安全具有十分重要的作用,大数据已经成为国家和企业的战略资源,在未来的发展中地位十分突出。
1大数据的内涵及特征
对于大数据的概念,目前还没有一个统一的定义,现有的分许都是从数据规模与软件支持处理数据的角度进行定义与描述的,在一般情况下认为大数据是指数据的大小超出了常规的数据加工工具获取、存储、管理与分析能力的数据集合体,在具体的处理过程中,需要对这些结构化、半结构化与非结构化的数据进行清洗、抽取加工,形成对人们有用的信息。大数据具有如下的几个特征:
1)数据规模大(volume)。一般情况下,大数据都是以半结构化、非结构化的形式存在,数据量比较搭,一般都在数百TR以上。
2)数据多样性(variety)。大数据中的数据主要以图形、图像、视频、音频、流媒体等数据形态存在,数据样式比较多。
3)数据处理时效性(velocity)。大数据只有经过处理之后,才能获取有用的信息,在处理要求数据满足一定的响应性。
4)结果准确性(veracity)。对数据的处理要求保证准确性,否则就会失去意义。
5)深度价值(value)。大数据中蕴含有很多有深度价值的信息,通过数据挖掘分析,探究其中巨大的价值。
2大数据的系统架构分析
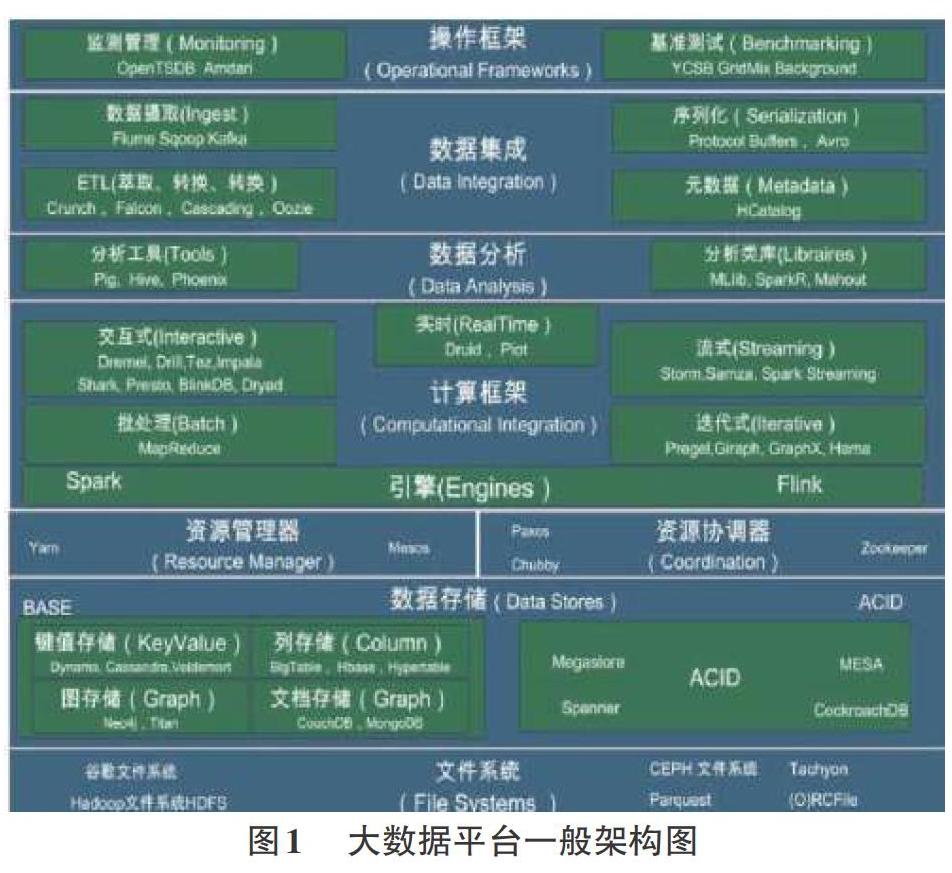
大数据系统是一个复杂的结构,能够为不同的数据提供其生命周期不同阶段的数据处理功能,在不同的应用过程中,大数据系统可以纵向的分为多个不同的数据处理阶段,在横向上可以分为多个不同的层次。在建构大数据系统模型时,需要结合大数据的具体用途进行分类建模,才能满足不同行业的需要,统一数据模型设计主要是根据企业的需求,搭建数据平台模型,由企业的应用需求驱动,大数据平台的建构模型应该自顶而下的过程,主要的建模过程主要包括业务的应用、需求的分析、逻辑模型的建立、生成具有的物理模型等几个过程。首先要确定业务应用与需求,主要是对统一的数据模型提出需求分析,包括数据的功能性与性能等两个方面的应用,即满足数据的内容与范围的需求以及数据查询的需求两个功能,功能性需求主要是保证大数据平台逻辑模型设计中,能够在具体的物理模型中进行落实,在一般情况下可以采用完全集成CIM类、扩充CIM类的属性以及新建类几种方法对数据进行描述。性能需要主要是从传统的SQL数据库或者OLAP的关键绩效指标来分析大数据平台架构的需求,然后采用机器学习的算法,提高分析挖掘效率。对于功能性需求,可以大数据平台建立的过程中对数据结构进行调整与优化,并采用新型的数据库技术,实现大数据平台信息快速获取的需要,而对于性能性需求,可以在采用一定的样本训练数据的基础上,生成相应的分析图表与目标视图,然后通过ETL重新抽取统一层数据到分析层,生成相应的逻辑模型与物理模型。因此,大数据平台需要包括文件系统、数据存储、引擎功能、计算框架、数据分析、数据集成、操作框架等部分构成,如图1所示。大数据平台主要包括以下几个部分:基础设施层书大数据系统的硬件基础,一般情况下是由云计算技术提供的;计算层主要是多种计算工具与大数据计算框架构成的,包括数据的抽取、ETL、检测管理等技术,将各种非结构化的数据进行处理,将无序化的数据转换成有序的数据序列,便于用户使用;而应用层主要采用多种协议方式实现大数据平台与外部数据的连接接口。图1展示大数据处理平台的关键架构层,在每一个层级中都会涉及相应的技术与关键的工具,它们是大数据平台的开源工具,在大数据技术不断发展的基础上,在这些开源工具的支持下,不断地促进技术革新,另外,通过开源代码,不同地区的工作人员,能够不断地完善大数据处理的生态系统,促进大数据技术的不断发展。
2.1Hadoop生态图
Hadoop是大数据平台基础性的应用平台,它是一个分布式系统基础架构,方便用户在不了解系统底层细节分布的情况下,开发多种分布式程序,从而能够提高集群的高速运算与具体的存储。它主要包括:MapReduce,主要功能是实现分布式数据处理的编程模型,便于用户对各种数据进行模型化处;Zookeeper,它的主要功能是分布式、可用性高的协调服务系统,为用户提供分布式锁类的应用;HBase的功能是分布式存在,满足数据按列存储的方式存储数据库;Pig的功能是保证各种数据流的编程语言与工作运行环境,可以检索各种类型的数据集合。
2.2伯克利数据分析栈
Spark的整个生态系统的核心,称为伯克利数据分析栈(BDAS),目前技术的众多子项目在大数据平台中得到了广泛的应用,它支持结构化的SQL数据查询、分析与数据处理,还提供机器学习的功能系统,MLBase及底层的分布式机器学习库ML-lib,同时,结合大数据生态系统的要求,还提供并行图计算框架GraphX与流计算框架Spark Streaming等功能,整个大数据系统架构中,采样近似计算查询引擎BlinkDB、内存分布式文件系统Tachyon与资源管理框架Mesos等子项目等都分布在不同的层级,这些子项目协同工作,为大数据平台提供了不同的计算范式,对非结构化数据的处理具有十分重要的作用。
3大数据系统架构的关键技术
3.1数据的采集技术
大数据的数据源是多种多样的,而且数据量十分巨大,变化快,如何有效的保证采集数据的安全性与可靠性以及数据的重复问题与质量问题是数据采集的关键。
3.1.1数据的生成
1)埋点。主要原理在应用中,在能够生成数据的上下文中,植入能够生成数据的代码,从而能够获取相应的数据。例如,在前端预先埋好需要的脚本代码,在用户访问相应的网页时,就会将用户的行为记录下来,从而能够获取相应的用户偏好信息。
2)日志收集数据。这种方法比较传统,但是也十分有效,获取的数据也比较真实。例如,将网站部署在Linux服务器上,在用户通过搜索引擎查询到该网页进行访问后,Linux服务器里的日志文件就会有用户登录的日志,如图2所示。
作为大数据搜索系统,网站日志占的份额最大,用户的登录行为可以通过日常保证,采用这种方式不需要在网站上预算埋点,就能够查询到和用户的各种行为。
3.2数据的传输技术
大数据平台主要采用的分布式存储系统,在分布式系统的构件之间可,需要进行相互之间的信息传递,才能实现功能的耦合,系统中的消息队列是数据信息在不同系统之间进行传递的容器与中间件,其功能是保证数据传输的可靠性,常见的消息队列有如下:
1)Flume系统
Flume系统具有安全性、可靠性,是一种能够对分布式的海量日志数据进行采集、聚合与传输的系统,一般情况下,在每台网络的服务器上部署Flume Agent系统,就能够实时的收集网站日志数据,并将其转存到HDFS上。以便于能够及时地获取相关数据。
2)Kafka系统
Kafka系统是Linkedln开源的信息系统,是一种基于发布、订阅消息系统的分布式管理系统,它具有实时的数据处理能力、高高吞吐率、能够支持消息的分区发布、保证消息能够按照顺序进行传输。在数据收集的过程中,数据在各个应用者处产生,通过Kafka汇集处理,将应用者需求的消息推送出去,在Kafka管理中,消费者读取到的队列的位置的相关信息,由Kaf-ka交各个消费者各自保存,降低了系统的数据存储压力,而其他管理信息存放在ZooKeeper中,从而提高了Kafka系统数据存储效率。
另外,在大数据业务处理的过程中,还有MySQL,Oracle,SqlServer等多种类型的数据库,也可以采用Sqoop工具将数据同步到HDFS上,在使用Sqoop工具时,需要采用MapReduce来执行数据的处理,并且还需Hadoop集群的每台机器都能访问业务数据库,才能有的完成各种数据的处理,需要在不同的、异构的数据库之间采用高速的数据交换工具。
3.3大数据存储技术
3.3.1大数据存储的文件系统
1)分布式文件管理系统
在数据进入到大数据系统进行清洗、转化时,都需要将数据存储到一个合适的持久化层中,HDFS的开源实现功能,能够将大数据环境下的数据仓库、数据平台等融合在一起,提高分布式文件存储的效率。
HDFS架构主要由NameNode负责管理、处理、存储分布式数据系统中的元数据,运用DataNode负责分布式数据库中的数据块的实际存储和读写操作,在大数据平台的客户端,利用NameNo-de联系获取用户的元数据文件,而实际上的DataNode直接负责整个系统通信完成工作。
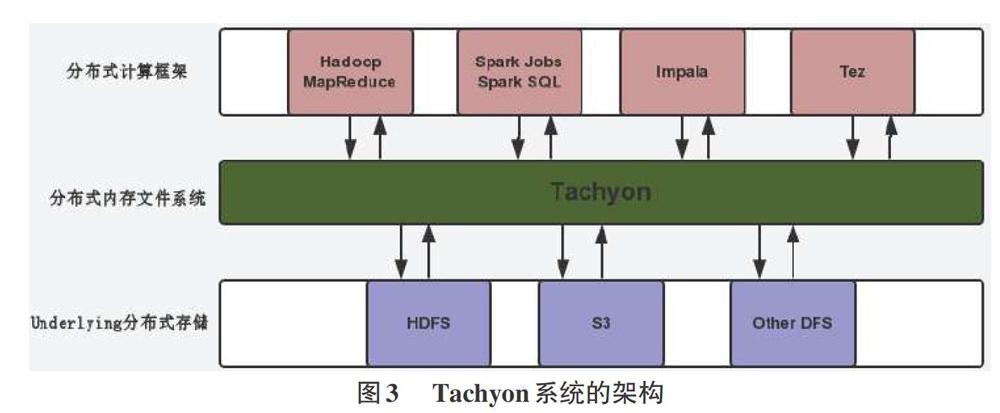
2)分布式内存文件系统
Tachyon是分布式内存文件系统之一,在大数据平台的处理中,应用十分广泛,它可以实现网络中的数据在多节点的内存中的分布式存储与管理,它的具体架构如图3所示。
Tachyon系部在底层部署了分布式文件管理系统与分布式存储系统,采用的是基于磁盘管理的方式与分布式计算框架。这样,在大数据处理系统中,可以直接从系统的内存中访问数据,而不是在磁盘中访问数据,大大提高系统的工作效率。
3)大数据的数据库技术
大数据在互联网应用,需要对网络的数据进行实时处理,以期望得到挖掘有效的系统数据,在基础的数据库管理中主要采用的是SQL数据库系统、NOSQL数据库系统两种类型。在关系数据库中,不同的数据模式需要采用不同的设计方法,他们是有严格的基于数据模型的设计方法,在NOSQL數据库的设计中,需要综合考虑各个键值的存储方法、文档存储的方法、列式存储、图形、视频、半结构话、非结构化数据等存储模型,这样就产生不同的物流存储结构,也就有种不同的建模方式,可以说,采用NOSQL数据库,可以快速地对大数据的数据模型进行设计。
3.4大数据分析技术
3.4.1互联网用户画像模型
用户画像画像模型就是通过网络收集与分析消费者的个性化特征与社会属性的主要数据,如生活习惯、消费习惯、群体特征等,提取特征数据,形成对用户的特征的一个个维度,并详细的数据进行表征,如位置、职业、性别、爱好、学历等,通过画像的方式对用户的特征进行信息化标签,采用这种用户画像技术可以筛选用户,进而能够提高信息推送的精确度,另外一方面还可以作为数据挖掘中的用户维度特征下一步挖掘,从而能够提高网络数据挖掘的效率,用户画像可以完美地对一个用户的个性化特征进行表征,是当前企业大数据应用的最基本的方式。
3.4.2机器学习的分析方法
1)机器学习的技术工具
在大数据机器学习语言中,常用的语言有R语言与Python工具包,在传统的小数据量的数据分析、挖掘的工具有MAT-LAB、SAS、Spass等数据分析工具,而R、Python属于开源性的数据挖掘工具,Python是一门多功能性的操作语言,在数据统计的过程中,主要采用的第三方工具包来实现的,Numpy封装了基础的矩阵和向量的操作,使得Pvthon语言在操作方面具有很强的优势,而Scipy则在Numpy的基础上,可以使用多种开发的功能,统计多种分布与算法,并能够提供可视化的处理功能,使得机器学习的功能变得比较简单。Ma-hout与SparkML是Python语言中常用的数据功能,在其中都包括了分布式环境下数据运行的机器学习的算法,在具体的处理过程中,采用Spark的优势,将内存计算和适合迭代型计算结合在一起,能够提高机器学习的性能。
2)大数据下的联机分析处理
目前,常用的大数据联机处理的技术有高性能的OLAP、ROLAP与HOLAP技术,它们都是基于多维数据结构的立体建模方式,然后通过大量的预聚合计算,从而能够实现多维数据支持,并支持以下钻、上卷、切片、切块、旋转等操作,从而能够有效地降低各种数据的处理与优化。但是所在技术的发展,ROLAP能够与多种数据库联系在一起,处理数据比较方便、快捷,成为当前大数据下的联机分析处理的关键技术。
3)基于大数据技术OLAP
常见的基于大数据技术OLAP技术主要包括Hive系统、Im-pala系统、Spark SQL技术等,Hive能够把HiveQL查询进行处理,并将其转换成MapReduce作业,然后在Hadoop集群上执行,数据运行的安全可靠,Impala系统使用LLVM技术,可以将系统中的查询编译成汇编指令,这样能够方便数据快速的执行,无须对SQL的查询指令进行处理与翻译,提高数据的处理效率。Spark SQL技术在执行数据查询的过程中,主要是通过内存进行存储与传输,不需要将数据保存在系统的硬盘上,提高了系统的执行效率。
4结束语
综上分析,大数据技术在社会各行业中得到了广泛的应用,在不同的应用环境中,大数据对数据处理的方法基本相同,都需要对结构性、半结构化、非结构化的数据进行综合处理,通过对大数据的内涵与优势进行分析,探究了大数据的系统架构模型,详细地分析了大数据系统应用中的关键技术,大数据系统构建需要结合具体的应用情况,选择合适的技术才能够满足系统开发的要求。
