
柑橘黄龙病检测的近红外光谱集成建模方法
2020-06-07 09:34贺胜晖李灵巧刘振丙杨辉华
分析科学学报 2020年2期
贺胜晖, 李灵巧,2, 刘 彤, 刘振丙, 杨辉华*,2
(1.桂林电子科技大学,广西桂林 541004;2.北京邮电大学,北京 100876;3.广州讯动网络科技有限公司,广东广州 510000)
黄龙病(Huanglongbing,HLB)已经严重威胁世界柑橘产业发展,目前少有治疗手段,唯有砍伐以控制疾病蔓延。因此,研发一种快速无损高准确率的黄龙病检测方法,对于柑橘产业的发展具有重要意义。近年来已有学者对利用光谱分析技术进行柑橘黄龙病检测研究。Sankara等[1,2]将逐步回归方法结合簇类独立分类模型,判断柑橘叶片是否患病的正确率为88.9%。李修华等[3]分析了健康叶片样本和黄龙病叶片样本间的光谱差异。马淏等[4]利用Fisher线性判别分析构建分类模型,正确率为90%。Mariani等[5]利用傅里叶红外衰减全反射技术检测黄龙病,正确率为93%。Roberto等[6]采集了116叶片的拉曼光谱并对引起光谱变化的生物原因进行研究,利用主成分线性判别分析对是否患病进行检测,其正确率为89.2%。刘燕德等[7,8]利用近红外光谱拼接可见光谱对黄龙病检测进行研究,基于偏最小二乘判别分析探讨了光谱处理方法对检测结果的影响,其正确率为92.8%。以上方法都是使用单一的特征提取算法和分类模型,只能提取部分有效光谱信息,使得在面对果树品种差异时,算法的鲁棒性不足。集成学习可以将多个不同的黄龙病检测模型组合,利用基模型间的差异性来提高模型的泛化能力,提高柑橘黄龙病检测算法的鲁棒性和检测率。
本文在特征层和决策层均利用集成学习方法融合了多个算法。在特征层,将谱回归核判别分析(Spectral Regression Kernel Discriminant Analysis,SRKDA)[9]和主成分分析(Principal Component Analysis,PCA)并行融合,加强关键特征并提高特征的鲁棒性;在决策层,利用Stacking策略将偏最小二乘线性判别分析(Partial Least Squares Linear Discriminant Analysis,PLSLDA)、决策树(Decision Tree,DT)和支持向量机(Support Vector Machines,SVM)融合。检验基于3个品种的柑橘叶片近红外光谱数据,实验表明本文算法在6个判别指标中均取得较优结果,分类性能明显优于单特征提取单分类器方法和多特征提取单分类器方法。
1 黄龙病集成检测算法
本文所提出的柑橘黄龙病检测检测算法如图1所示,该算法主要由多特征提取算法和2层网络的集成分类器组成。(1)多特征提取:利用SRKDA和PCA并行融合的特征提取算(法对光谱进行特征提取,获取特征向量。(2)集成分类器第一层网络:将特征向量分别传入3个基模型:PLSLDA、SVM、DT,进行交叉检验,获取重构后的训练集特征矩阵和测试集特征矩阵。交叉检验折数通过实验确定为3折,其详细信息表述于模型构造部分。SVM选择高斯核函数,通过网格寻优,SVM的核函数参数c=4,gamma=1.2;DT采用C4.5算法,叶子节点所包含的最小样本数为13。(3)集成分类器第二层网络:将重构后的特征矩阵传入第一层网络中最优的分类器:PLSLDA,获取最终结果。
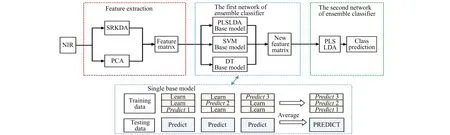
图1 黄龙病检测算法流程图Fig.1 Flow chart of Huanglongbing detection algorithm
2 实验部分
2.1 数据采集
砂糖橘(Sugar Orange)叶片于2017年3月在贺州采集,沃柑(Fertile Orange)和橙(Navel Orange)叶片于2017年12月在柳州采集。每棵果树采集3片叶片,主要采集树木冠层叶片并涵盖多种类型的黄化特征,如斑驳、花叶、黄化、革质化等。将每棵树上采集的叶片随机分为2部分,其中2片送至广西柑橘研究院使用荧光定量聚合酶链式反应(Fluorescence Quantitative Polymerase Chain Reaction,FQ-PCR)确定柑橘叶片是否染病,剩余1片用于近红外光谱采集[10]。

图2 叶片采集光谱点Fig.2 Spectral points collected on leaf
本文使用便携MEMS近红外光谱仪(NGD,广东讯动)采集光谱数据,测定范围为950~1 650 nm,分辨率14 nm,波长重复性0.5 nm,波长准确性1 nm。对每片叶片采集3个点,其位置如图2所示。按照柑橘黄龙病PCR检测的国家标准[11],CT值大于35为健康,小于30为患病,在30~35之间需要重新检测。由于CT值在30~35间的样本状态模糊,且数量低于样本总量的5%,为保证实验结果的准确性,将该部分样本舍弃。
2.2 模型构造
实验中使用的叶片数量如表1所示,将样品按照7∶3比例随机划分成训练集和测试集。由于叶片上的病菌浓度分布不均,导致生物内部元素的差异,进而对光谱产生影响。为尽可能检测出患病样本,首先分别判定单个叶片上采集的3条光谱是否患病,然后将存在患病光谱的叶片上所有光谱点判定为患病。

表1 模型搭建中使用叶片的具体数量
本实验需要确定交叉检验折数、PCA和SRKDA集成模型的特征提取维度,3个品种的结果相似,因此仅以砂糖橘样本为例进行说明。由图3可见,交叉检验折数对实验结果影响较小,各分类指标保持稳定,分类指标曲线呈现直线趋势。为减少计算量,实验采用3折交叉检验。结果表明,对于PCA方法,在维度高于23时,各指标趋于稳定;对于SRKDA方法,在维度达44时,各指标达到最优。因此,在实验中分别使用PCA和SRKDA将样本维度降至32和44。
3 结果与讨论
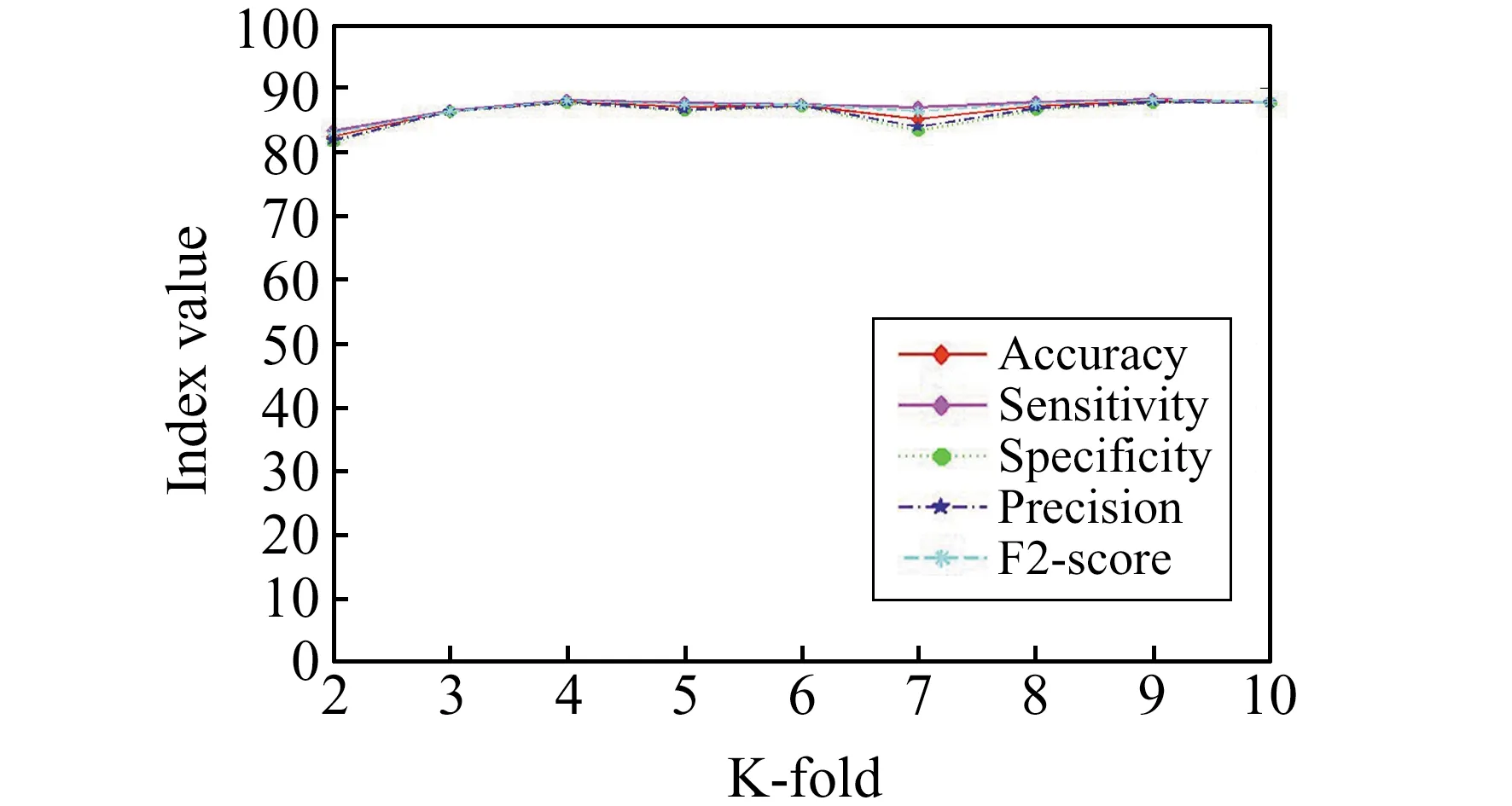
图3 交叉检验折数对分类结果的影响Fig.3 The effect of the number of folds in cross-validation checking folds on classification results
本实验采用6个指标对模型进行评价:正确率(Accuracy)、灵敏度(Sensitive)、特异性(Specificity)、精度(Precision)和F2得分(F2-score)。设置单特征提取单分类器方法:主成分支持向量机(P-SVM)、主成分偏最小二乘线性判别分析(P-PLSLDA)、谱回归偏最小二乘线性判别分析(K-PLSLDA),以及多特征提取单分类器方法:谱回归主成分偏最小二乘线性判别分析(KP-PLSLDA)为对比方法。实验结果取10次测试结果的均值,如表2所示。分析表2中数据可以得到以下结果:(1)柑橘品种间的内部差异会对检测模型和特征提取算法产生明显影响;(2)多特征提取模型结合可以扩大差异,明显增强模型的泛化能力,提高分类模型性能;(3)多分类器模型对比单分类器,分类性能明显提升而且受柑橘品种间的内部差异更小,模型鲁棒性明显提升。
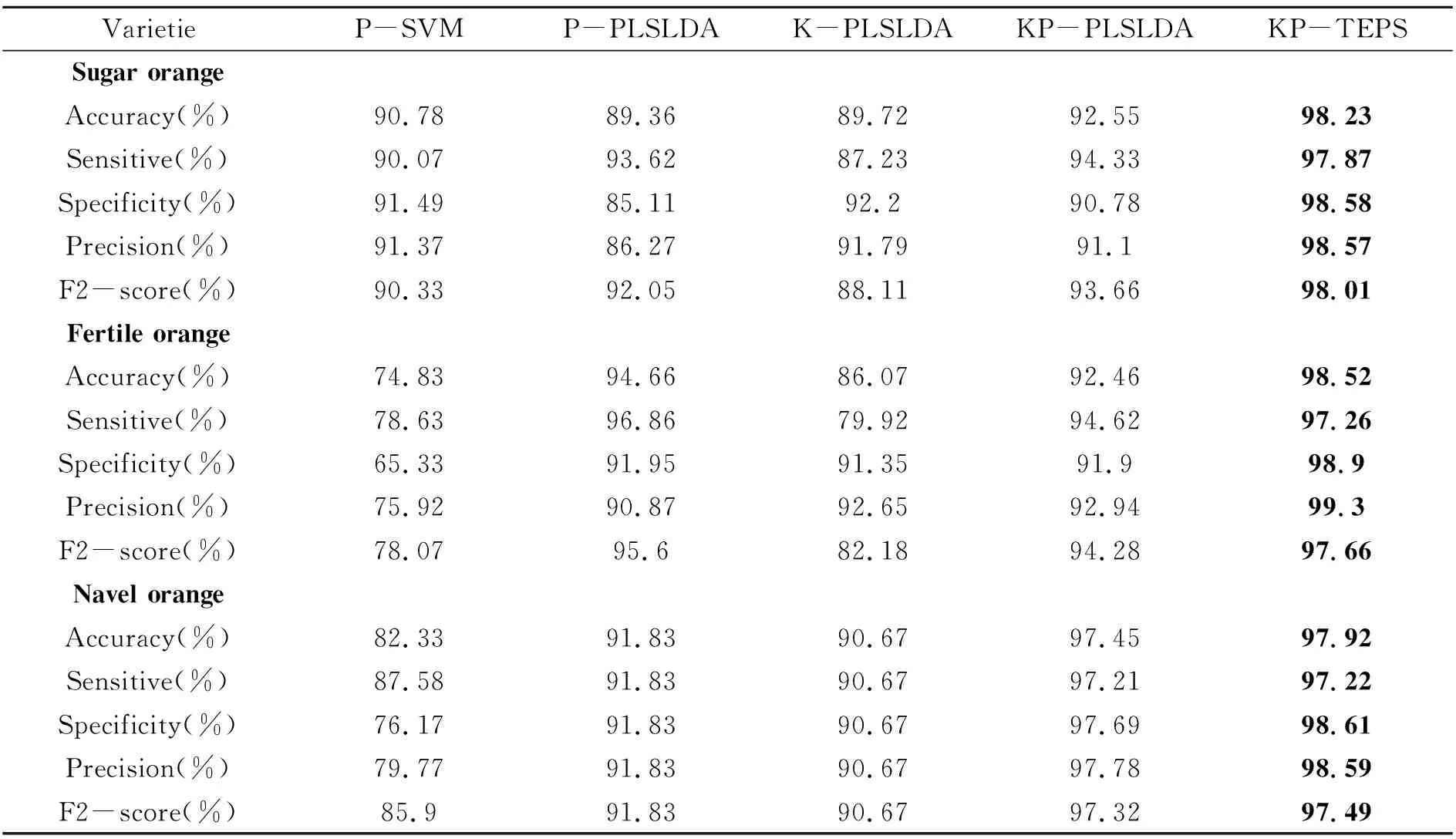
表2 分类模型在3个数据集上的实验结果
4 结论
为提高柑橘黄龙病检测算法的鲁棒性和检测率,提出了一种集成多特征提取多分类器的黄龙病检测算法。检验基于3个柑橘品种的近红外光谱数据,实验结果表明,集成分类模型在6项指标中均表现优异,证明集成多特征提取和多分类器能够利用输出差异获得比单特征提取和单分类器更优的检测结果,说明了多特征提取多分类器的优越性和集成学习的强泛化能力,为柑橘黄龙病检测工作提供一种新方法。
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
电子制作(2019年15期)2019-08-27
文苑(2018年22期)2018-11-15
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中国老区建设(2016年3期)2017-01-15
陕西画报(2016年1期)2016-12-01
浙江柑橘(2016年4期)2016-03-11
浙江柑橘(2016年2期)2016-03-11
