
基于YOLO算法和RK3399平台的行人检测实时性研究
2020-06-04 12:55胡鹏张光建
数字技术与应用 2020年3期
关键词:实时性
胡鹏 张光建


摘要:为了解决在固定背景下端到端的行人检测难于达到实时性问题,并且结合实际开发板的特性与任务特点,提出了新的骨干特征提取网络,采用YOLO作为检测算法基础结构。所提出的方法以预测速度快为目标,该方法取得了在RK3399开发板上运行效率达11.842fps的良好结果,达到了实时性目的。在实验上从训练、预测两个方面于YOLOv1、v2、v3的其它精简版网络进行了对比。研究表明训练时损失值与网络的复杂性并无明显的相关性,同样的与mAP也无明显相关性,预测时新的特征提取骨干网络能在单类别目标检测任务中在大幅度提高检测速度的同时有较好的预测精度。
关键词:YOLO;RK3399;实时性;固定背景;行人检测
中图分类号:TP391.4 文献标识码:A 文章编号:1007-9416(2020)03-0078-04
0 引言
作为目标检测领域里的一个较为重要的一个分支,固定背景下的行人检测在视频监控等方面得到广泛的应用。经过几十年的不断发展,从人工特征工程到机器学习特征工程,从人工设计模板发展为端到端深度学习,在检测精度上有了很大的提高。同时在当前检测精度尚可的情况下,研究更多的关注点是在有限的条件下拥有更少的计算量,更快的预测速度。
YOLO[1]将检测任务视为回归任务进行处理,在基础骨干网络相同的情况下,有着更快的预测速度。通过借鉴YOLO这一思想,保障了预测的Benchmark速度。但在部署到嵌入式端时(如RK3399平台),发现如若不对骨干特征提取网络进行更改,依旧难于达到实时预测,由此引出本文。
1 行人检测与网络训练
1.1 改进的网络设计
为了能达到实时性目的,并结合实际数据目标特征,对特征提取网络进行大幅度修改。相比于YOLO_v1/2/3的精简版(Tiny)还要精简。取消了上采样层与叠加层,只保留了卷积层和最大池化层。骨干特征提取网络层数缩减到只有8层,远小于YOLO_v1-Tiny的15层,YOLO_v2-Tiny的15层,YOLO_v3-Tiny的20层。
同时,为了衡量网络模型复杂度,从计算量与参数量这两个指标进行评价,如图1所示,本文模型相比于YOLO_v2/3-Tiny分别是后者的~12.4%和~11.7%,甚至相比于YOLO_v1-Tiny而言分别是后者的9.66%和5.86%。骨干特征提取网络的更简单,为在开发板上达到实时性要求打下了良好的基础。
在设计特征提取网络时,考虑到计算量这一条件限制,并没有使用小卷积核将网络加深的方式来获取更大的感受野与更少的参数量[2],而是通过增大卷积核大小与步长的方式,这样做的目的一方面是增加卷积核感受野。另一方面是将特征图尺寸快速降下来,减少后续的计算量。同时,低层特征卷积核个数设计得并不多,原因是根据对数据集的观察,发现小纹理并不丰富。丰富的是高层网络的上下文。期望的是通过最后两次的1x1卷积进行维度整合与达到全链接层的目的[3],使得网络层顶部特征上下文能变得可分(图2)。最后得到35×35×30大小的特征图用于回归预测。
1.2 训练数据集
本文实验数据集图片来源于固定的双目网络摄像头,先拍摄成双目视频,然后解帧而成。单个摄像头的分辨率为320×240。俯视角度或高角度下拍摄得到,标注框标定结果为头与肩位置(人工筛选剔除有伞遮挡情况的目标标注框)。经过标注处理,得到最终的数据集共包含了6280张图片(图3),随机划分为训练集5000张,测试集1000张,验证集280张。在训练之前,先利用K-means对训练集里标注对象框的宽高尺寸进行聚类分析,得到标注框宽高相对图片宽高比结果为:(0.7236,1.0382),(1.0214,1.1645),(0.9048,1.5255),(1.2038,1.3900),(1.1960,1.8314),作为Anchor参数输入,Anchor与标注框的平均IoU为85.03%。
1.3 训练过程
整个实验与对比试验训练过程在Intel Core i7-7700k+ NVIDIA RTX2080ti硬件条件下完成。由于完全自定义骨干特征提取网络、预训练模型并不一定有明显促进效果[4]、以及对比试验公平性等原因,均没有在ImageNet等数据集上进行预训练以及使用预训练模型。在训练策略上,为了防止过拟合,均启用了饱和度、曝光、色调的随机调整来进行数据增强,权重衰减正则项值为0.0005。为了避免陷入局部最优的情况,动量值为0.9。采用了多分布策略学习率。Batch大小均为64。
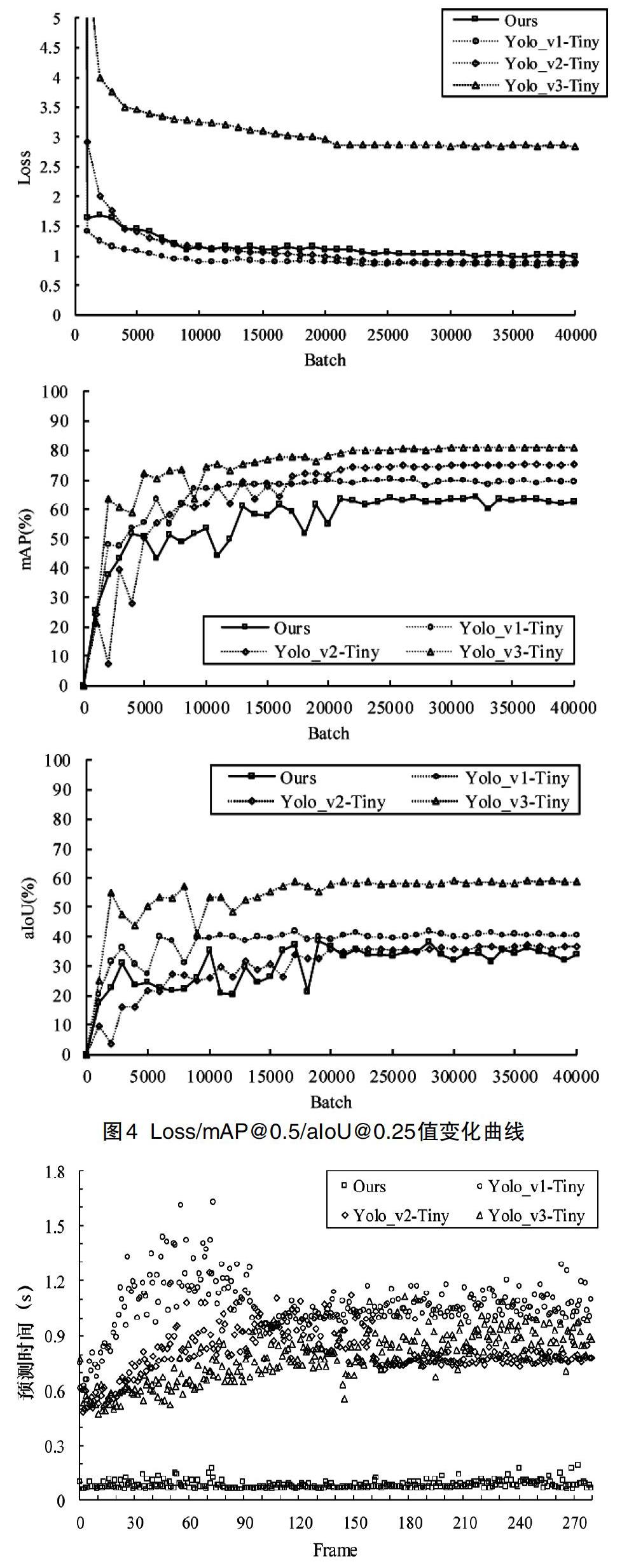
为了降低训练的偶然因素,本文将整个训练过程重复了5次,相同绘制节点数据值取的是5次训练算数平均值。所有网络模型训练实验Loss在2000批之前迅速降低且之后趋于收敛。每个网络模型最大训练次数为40000次终止,没有设置提前终止条件。每1000个Batch保存一次模型,得到40个网络模型,并在测试集内进行测试。在计算mAP时,选择IoU的阈值为0.5,预测结果mAP值总体趋势均为先快速上升,然后振荡缓慢上升,在25000个Batch过后相对稳定。在计算aIoU时,选取的置信度阈值为0.25,得到平均交并比预测结果,值在25000个Batch后相对稳定,而前期均有不同程度的振荡过程(图4)。
设计的模型损失收敛值与YOLO_v1-Tiny,YOLO_v2-Tiny基本持平。值得注意的是YOLO_v3-Tiny的收敛值则有将近3倍之多,而在测试集上在25000批之后趋于稳定的测试值来看,无论是IoU阈值为0.5时的mAP值还是置信度阈值为0.25时的aIoU值,YOLO_v3-Tiny均为最佳。并且从曲线图也可以发现在25000批之后平均损失值最小的是YOLO_v1-Tiny,但mAP与aIoU表现均不是最优。可以看出损失收敛值与测试集上得到的mAP与aIoU值没有明显的相关性。证明在目標检测任务中损失值并不一定是越小越好。
猜你喜欢
高技术通讯(2021年3期)2021-06-09
电测与仪表(2017年24期)2017-12-19
北京航空航天大学学报(2017年12期)2017-04-23
科技资讯(2016年28期)2017-02-28
航天控制(2016年6期)2016-07-20
铁路通信信号工程技术(2014年5期)2014-02-28
