
基于兴趣点与导航数据的手机信令数据出行方式识别*
2020-05-27 12:22钟舒琦邓如丰邓红平蔡铭
中山大学学报(自然科学版)(中英文) 2020年3期
钟舒琦,邓如丰,邓红平,蔡铭
(1. 中山大学智能工程学院,广东 广州 510006; 2. 广东省智能交通重点实验室,广东 广州 510006; 3. 佛山市交通运行监测中心,广东 佛山 528000)
交通数据是交通决策的重要依据。近年来,交通数据在交通管理和规划中发挥着日益重要的作用,不仅为交通管理部门提供决策依据,而且为公众出行提供信息服务。以往居民出行调查是获取交通信息的重要来源。但传统居民交通调查的收集及后期的处理需要耗费大量的人力物力,抽样率一般为1%~5%,甚至更低;且一般5至10年进行一次,数据时效性差,难以适应高速发展的城市道路交通。随着大数据的兴起,公交刷卡数据、浮动车GPS数据[1-2]、电警卡口数据以及停车场流水等数据极大地拓展了交通数据的来源。但这些数据的跟随性较差,仅能还原用户的部分出行,无法构建用户的完整出行链,属于“跟车不跟人”的数据。相比之下手机信令数据则属于“跟人不跟车”的数据,基本上每个人的手机都是随时带在身上,不随用户出行过程中交通方式的切换而变化,具有很强的跟随性。
手机目前已经成为广泛使用的移动通信工具,当手机移动或对外通信时,会和附近的基站进行通信,基站会记录通信手机的编号、通信时间、通信类型和基站编号传回后台数据管理中心。由于手机位置信息能够通过基站表示手机用户的位置和时间信息,经过处理,可以判断用户起讫点及到发时间。在经过算法分析后,信令数据还可以识别用户的出行方式,提取用户完整的出行链信息。相比其它交通采集系统来说,基于基站的手机定位交通信息提取分析拥有样本量大、覆盖范围广、采集数据实时性高、采集费用低等优势[3-8]。国内外已经有不少研究将手机信令数据或网络数据用于交通需求估计[9-11]、通勤分析[12-14]、个体出行模式[15-17]、交通小区划分等方面的分析。
在基于手机信令数据的出行方式判断方面,早期研究主要基于先验知识及隶属度函数等方法进行判断,如:冯冲[18]基于先验知识对不同出行方式建立判断函数及权重用于对出行速度、出行距离及出行时间进行计算,判断手机信令用户的出行方式。张博[19]、李耀辉[20]采用基于隶属度函数的出行方式模糊判断的方法对手机信令用户的出行方式进行判断。2010年,Wang等[21]基于谷歌地图导航数据提供的出发地至目的地的时间对不同交通方式进行判断。杜亚朋等[22]在此基础上引入轨迹匹配度,利用DBSCAN算法对手机信令轨迹与导航数据轨迹进行聚类,计算不同出行方式路径的轨迹匹配度,对步行、驾车及公交三种交通方式进行判断。在基于手机信令进行道路交通流量计算方面,周南等[23]在基于手机信令数据获得OD矩阵的基础上,采用传统四阶段法实现交通分布、方式划分及交通分配。Gundlegård等[24]在科特迪瓦城市阿比让基于5万用户的手机信令数据进行交通流量预测,并将交通量分配至相应路网中,但由于手机信令数据定位精度较低且数据稀疏,因此其所采用的最短路径匹配方法局限性较大。
综上所述,手机信令数据在交通信息获取领域有着巨大的潜力,但目前国内外大部分基于手机信令数据进行交通出行特征的分析都停留在OD矩阵、职住通勤分析等宏观层面。而对基于手机信令数据获取的OD矩阵进行的道路交通流量估计仍采用传统四阶段法、最短距离路径匹配等算法,局限性较大。对于个体出行方式的判断方面,基于导航数据对用户出行模式进行判断相较于基于先验知识和隶属度函数的方法有了一定的效果提升。但由于手机信令定位精度较低,直接请求基站间的导航数据与用户的实际行程仍有较大误差。而用户的出行的起讫点一般均为兴趣点,因此在判断用户的出行方式时应考虑基站覆盖范围内的兴趣点数据,从而获取更为准确的用户出行轨迹及出行方式。本文基于现有手机信令出行方式识别研究,引入兴趣点与路网数据,对用户出发地与目的地基站小区内的兴趣点进行拓扑分析,同时结合导航数据进行轨迹匹配度、时间匹配度及二者权重的计算,综合判断用户的出行方式。
1 原理与方法
手机用户在使用手机进行打接电话、收发短信等操作时,会与附近基站进行通信,基站网络内的手机信令系统会记录设备ID、通信时间、基站网络类型、基站位置区码LAC及小区识别码CI等数据。即使手机用户未操作手机,每隔1 h左右,基站会与手机进行一次“握手”通信,产生“心跳”信令数据。基站的位置区码LAC及小区识别码CI组成的全球小区识别码CGI对应着基站的经纬度坐标。由此可获取手机用户在不同时间的地理位置。
1.1 数据清洗
相比于传统居民出行调查数据,手机信令数据具有样本量大、观测时间长的优势;相比于公交IC卡、出租车GPS以及卡口等交通大数据,手机信令数据拥有跟随性强的优势,即其位置数据不受交通方式变化的影响。但是手机信令数据作为移动通信运营商计费的副产物,存在着定位精度低和数据稀疏的劣势。此外,手机信令数据还存在乒乓切换数据、漂移数据、同时间不同位置点数据等特有的误差数据。这对手机信令数据的清洗提出了更高的要求,需要根据手机信令数据的特点进行针对性的数据清洗,使之适用于后续的数据分析。
1.1.1 关键字段缺失数据处理 手机信令数据的关键字段包括用户ID、时间、经度和纬度字段,根据实际数据内容,经纬度字段也可代替为全球小区识别码CGI或基站位置区码LAC及小区识别码CI。非关键字段包括用户年龄、性别等用户属性字段及事件类型、通话时长等字段。在实际运行中,由于信令系统记录错误或数据库异常等原因,手机信令数据中存在少数缺失或错误的情况,如信令经度与纬度调换、信令时间远超研究范围等记录。对于关键字段缺失的记录,需遍历数据中的所有记录,查找并删除关键字段错误或为空值的记录。
1.1.2 稀疏数据处理 由于手机与基站间的通信有较大的不确定性,用户的信令数据中可能出现某天信令记录量较少或信令记录时间分布不均匀的情况。若某用户某天的信令数据量过少或集中分布于某几个小时,其余时间未产生手机信令数据,则认为该用户当日的手机信令数据无法代表其当日的活动轨迹,应删除该用户当日所有的手机信令数据,以避免后续数据处理过程中认为该用户长期位于某个位置的情况。具体步骤如下:
1)将一天24小时分为48个半小时区间;
2)将每个用户的原始手机信令数据按时间分至各个区间;
3)计算各用户每天的信令数据所分布的区间数量为有效区间数量;
4)筛选有效区间数量大于阈值nsparse的用户数据为有效数据。
1.1.3 同位置点数据合并 当用户长期位于同一个位置时,信令系统会记录多条相同经纬度的记录。在经过稀疏数据的处理后,这些相同位置点的数据就成了冗余数据。且因为人大部分时间都是静止的,每天经过的新的位置点数量有限,大部分手机信令数据都是冗余的数据,约占整体数据量的60%。因此对同一用户同位置点的数据,仅需保留其第一条和最后一条,可极大降低数据的运算量。
1.1.4 同时间不同位置数据处理 由于手机信令系统原始用途是用于通信及计费等,因此在用户使用手机时,可能在同一时间产生多条信令记录。部分同时间记录甚至并不位于同一位置,这些记录对后续数据处理算法将产生不利影响,应予以剔除。针对同一用户同一时刻多个不同位置点的数据,计算这些位置点与其前后点的平均距离,选择距离最小的记录为该用户该时刻所处的位置,剔除其余记录。
1.1.5 乒乓切换数据处理 当用户处于两个及以上基站小区的交界处时,手机信号往往会被多个基站覆盖且信号强度相近,使得手机在两个或多个基站间来回切换,产生多条信令记录,但实际上手机用户并没有移动或移动距离很短,这种数据称为乒乓切换数据。乒乓切换数据的特点是第i条记录位置与第i+1条记录位置不同,与第i+2条记录位置相同,且乒乓切换通常发生在短时间,因此第i+1条记录的停留时间小于阈值Tpp时,认为第i至i+2条数据为乒乓切换数据,并令i=i+1,对乒乓切换数据进行连续判断,直至不满足以上条件为止。对于一段连续的乒乓切换数据,只保留累计停留时间最长的位置记录,并将其时间设为该段连续乒乓切换数据的第一条记录的时间,剔除其余乒乓切换数据。
1.1.6 漂移数据处理 漂移数据是指用户突然从临近基站切换至远处基站,一段时间后又切回临近基站的情况所产生的数据。漂移数据的特点是短时间发生大位移,因此使用速度阈值vdrift剔除漂移数据。计算各条手机信令记录与下一条记录之间的距离及停留时间,得到每条信令记录对应的速度。
1.2 轨迹点分析
1.2.1 与轨迹点分析相关的定义 轨迹点分析是指识别用户在出行过程中的停留点与移动点。停留点为用户在出行过程中的起讫点,即用户出行的OD点。移动点表示用户在出行过程中所经过的位置,其运动速度可以表征用户在两个停留点之间的出行速度。空间轨迹中的停留点识别是将空间轨迹转化为交通语义轨迹的关键步骤。一次停留为用户在某一区域范围内停留一段时间,一段出行则为用户在两个不同停留点之间的移动。与轨迹点分析相关的定义,有:
1)轨迹点:经过处理后的手机信令数据为带有时间戳的位置点记录,出行轨迹是由多个带有时间戳的定位点组成的集合。
2)停留点:停留点为用户出行中的出发地或目的地,即出行起讫点。交通是一种人或物的空间移动。一般而言,人们出行的目的是为了到达某个目的地并进行相应的活动,因此每一段出行都是由两个或以上的停留点组成。
3)最短停留时间:最短停留时间为用户在出发地或目的地应停留的最短时间。人们出行的目的是为了到达某个目的地并进行相应的活动,因此除了特殊职业如驾驶员、快递员等外,绝大部分用户在到达其目的地后都会在目的地停留一段时间以进行相应的活动。而在手机信令数据中,每个定位点的停留时间是判断其是否为停留点的重要特征。
4)最大活动距离:最大活动距离为用户在出发地或目的地周围活动的最大距离。用户在到达其目的地后,一般会在目的地周围活动。如若用户在目的地活动范围较小,或目的地周围基站数量较少,用户在活动期间可能仅与一个基站通信,即在停留点仅产生一条信令记录。
5)移动点:移动点为用户在停留点之间的定位点。移动点表示用户在出行过程中所经过的位置,其时空特征代表了用户在一段出行过程中的时空特性,如移动点的位置表示用户的出行路径中所经过位置点,移动点的速度表示了用户在两个停留点之间的出行速度。
在手机信令数据中,因为基站的覆盖范围较大,因此用户在目的地附近活动时所产生的位置点较少,但其在停留点的停留时间却不会减少,用户停留点的识别应主要从轨迹点时间特征考虑,结合轨迹点的空间特征作为约束条件,达到分析用户轨迹点的目的。因此,我们针对手机信令数据,提出了一种基于用户最短停留时间和最大活动距离的轨迹点分析方法。
1.2.2 轨迹点分析算法 轨迹点分析算法主要包括以下步骤:
1)将所有手机信令数据按用户ID和时间由小到大排序,并增加由0开始的自增序号字段;
2)计算每一个轨迹点与下一个轨迹点间的距离d、停留时间ts和速度v;
3)对于停留时间ts大于等于最短停留时间Tmin的轨迹点,标记为停留点;
4)对于停留时间ts小于最短停留时间Tmin且距离d大于等于最大活动距离Dmax的轨迹点,标记为移动点;
5)对于停留时间ts小于最短停留时间Tmin且距离d小于最大活动距离Dmax的轨迹点,聚合下一个轨迹点进行判断,若聚合轨迹点的累计停留时间大于等于最短停留时间Tmin,则将该聚合点标记为聚合停留点,若聚合轨迹点间的最大距离大于等于最大活动距离Dmax,则将这些聚合点标记为移动点。
1.3 出行链提取
在对手机信令数据进行轨迹点分析后,用户出行的轨迹点被分为移动点与停留点。提取同一用户相邻的停留点,即可得到用户的出行链。用户的出行链表中每一条记录代表一次出行,为了便于对每次出行进行出行方式的判别,出行链表主要包括以下字段:
1)oid:信令记录编号,每一条记录即为一个定位点;
2)isdn:用户编号,唯一标示每个用户;
3)begin_time:出发时间;
4)arrive_time:到达时间;
5)U_turn:标识该次出行的目的地是否为最远点;
6)movepoint:出发地与目的地间的停留点数量;
7)od_distance:出发地到目的地间的距离;
8)travel_time:旅行时间;
9)o_lng:出发地经度;
10)o_lat:出发地纬度;
11)d_lng:目的地经度;
12)d_lat:目的地纬度;
1.3.1 折返出行 出行链中U_turn字段用于标识该次出行的目的地是否为最远点。若一次出行的目的地不是距离出发点最远的轨迹点,则该次出行为折返出行,U_turn字段标记为True,否则为False。实际出行中,存在着不少出发地与目的地相同的出行链,此时应将该次出行划分为两段出行,分为出发地至最远点的出行和最远点至目的地的出行。虽然最远点不一定是用户出行的目的地,但在出行方式的判断中,将最远点作为目的地及出发地请求导航数据是合理的。对于目的地并非最远点的折返出行,需重新计算出发地至最远点和最远点至目的地的出发时间、到达时间、停留点数量、OD距离及旅行时间。
1.3.2 有效出行 一次出行可以定义为由一个出发地向一个目的地移动的交通行为。虽然一次出行是基于特定的出行目的而产生,不应受到出行时间、出行距离等特征的限定。但在交通研究中,短距离或短时间出行大多对城市交通整体的影响有限,因此将其判定为无效出行。我国交通运输部颁布的《城市公共交通分担率调查和统计方法(JT/T1052-2016)》[25]中将出行限定为“全程步行时间5 min或自行车全程距离400 m以上,或者使用其他出行方式的交通活动”。在未知出行方式的情况下,可以认为出行距离400 m以上、或出行时间5 min以上的出行为有效出行。对于折返出行,其出发地至最远点的距离或最远点至目的地的距离大于400 m均可认为此次出行距离大于400 m。
1.4 兴趣点分析
兴趣点(point of interest,简称POI)数据是一种代表现实地理实体的点状数据,它可以代表建筑物、商店甚至是占有一定面积的地理存在。人的活动通常与反应城市空间实体的不同类型的兴趣点数据相关,因为人之所以会产生出行是因为目的地有出发地所没有的资源,而这种资源在城市中表征为各种各样的兴趣点。因此在城市出行中凡是带有目的的出行,其出发地和目的地必然是兴趣点。
但实际上大部分手机信令数据的定位为基站位置,即手机信令定位与实际用户所处位置间可能有很大的误差距离,且误差距离受到基站的覆盖范围及周围基站密度的影响。市区的定位精度约为200~500 m,而城郊及乡镇地区定位约为800~1 000 m。在这种情况下,直接进行两个基站间的导航数据请求所获得的结果很有可能与用户实际行程相差较大,且出行距离越短,其出行方式的判断所受影响越大。
图1为某城市路网图,五角星点为基站位置,虚线边框为基站小区的覆盖范围,圆形点为基站小区内的兴趣点。由图可见,基站距各兴趣点的直线距离较短,但基站沿道路至各兴趣点的距离却远远大于直线距离,因此可能会出现基站间的导航路径、时间与实际信令轨迹及出行时间大相径庭的情况。

图1 基站与其覆盖范围内 兴趣点的路网示意图Fig.1 Road map of the base station and points of interest
除了基站的位置外,出行方式的判断中所获取的导航数据需对出发地及目的地基站小区内兴趣点间进行导航数据的请求,然后将兴趣点间及基站位置间的导航结果与信令轨迹匹配、对比,从而获得更高的匹配率。但由于城市内兴趣点数量较多,市区内的兴趣点密集程度过高。若对比两基站小区内所有兴趣点间的导航数据,易产生巨大计算量及网络请求量,因此需要对基站小区内的兴趣点进行路程距离判断,筛选与基站位置路程距离较大的兴趣点。
1.4.1 路网拓扑与基站小区划分 在进行兴趣点分析前,需要将研究区域内的路网进行拓扑连通,主要包括以下步骤:
1)筛选研究区域内的所有道路;
2)将路网基于不同道路的交点打断为路段;
3)设置路段阻抗,一般将路段阻抗简化地设置为路段长度,将单行道逆行方向的路段阻抗设为一个极大值;
4)最后,基于路段阻抗及路网的连接关系,建立研究区域内的路网拓扑连通图。
手机信令数据中的经纬度一般为基站的经纬度,而每个基站有对应的覆盖区域,为了将基站的点转化为具有一定覆盖区域的基站小区,需要对研究区域内的基站进行基站小区划分。主要包括以下步骤:
1)筛选研究区域内的所有基站;
2)根据泰森多边形算法划分所有基站小区,得到矩形voronoi图;
3)基于研究区域的外轮廓对矩形voronoi图进行裁剪,得到研究区域内的基站小区图。
1.4.2 兴趣点分析 在获得研究区域内的基站小区图及路网拓扑连通图后,记基站小区内距离基站的路程距离较远的兴趣点的集合为平行兴趣点。对于每一个基站小区,进行如下步骤:
1)筛选基站小区内的兴趣点,将所有兴趣点映射至与其距离最短的路段的最近端点;
2)计算各兴趣点映射端点至基站的最短路程距离;
3)筛选最短路程距离大于阈值Rmax的兴趣点及其路段端点,记为PF兴趣点;
4)对于每一个PF兴趣点,计算该兴趣点至其它PF兴趣点的路程距离;
5)计算与该兴趣点路程距离大于Rmax的PF兴趣点,记为未覆盖兴趣点,将未覆盖兴趣点的数量记为nu;
6)计算该兴趣点至其它PF兴趣点的路程长度之和,记为len,将nu及len最小的PF兴趣点添加至平行兴趣点集合中;
7)若nu等于零,则完成该基站小区平行兴趣点的计算;否则设该基站小区的PF兴趣点集合为该PF兴趣点的未覆盖兴趣点,并回到步骤4)直至nu等于零。
1.5 出行方式识别
由于手机信令数据定位精度较低且数据稀疏,使用传统GPS数据的出行方式或路径匹配的方法所产生的误差很大。相较于对每个出行轨迹点进行路段匹配后结合出行时间、出行距离、出行速度等进行出行方式识别的方法,手机信令数据更适合利用导航数据进行出行方式识别。因为相比于出行中的移动点,手机信令数据中出行的出发地和目的地可靠性较高,且一般用户出行选择路径的原则主要是时效性和经济性,而这两者在导航数据中均有较好的体现。除此之外,经过兴趣点分析后的出发地及目的地会更贴近用户的实际出发地与目的地,多个出发地与目的地基站小区内的兴趣点间的出行方式和出行路径组合涵盖了用户出行过程中多种可能的选择。手机信令数据的出行方式识别主要包括请求导航数据、权重计算、路径匹配、时间匹配及综合对比五个步骤。
1.5.1 导航数据 获取导航数据是进行出行方式识别的第一步,目前国内几大地图服务网站均提供了导航API接口,支持驾车、公交、步行及骑行四种交通方式的选择,并针对驾车和公交出行提供了不同的出行策略。如驾车出行中有速度优先、距离优先、躲避拥堵、避免收费等策略,公交出行中有少换乘、少步行、不坐地铁、时间短、地铁优先等策略。针对公交出行,部分导航API提供了出发时间的选项用于过滤掉非营运时段内的公交线路,出发地及目的地城市选项用于计算跨城公交线路,由此可以进一步还原手机信令用户出行中的实际情况。值得注意的是国内有三大常用坐标系,分别是WGS84坐标系、GCJ-02坐标系及百度坐标系,在请求导航数据前需指定经纬度的坐标系或将数据的坐标系转换为导航API规定的坐标系。
导航API返回的有效数据主要包括GPS经纬度数据、旅行时间数据及指引信息数据。其中GPS经纬度数据用于与信令轨迹点数据进行路径匹配,旅行时间数据用于与信令数据中的旅行时间进行时间匹配,指引信息则主要包括经过的路段名称或乘坐的公交线路及始末站。
1.5.2 权重计算 出行方式的识别需要综合计算路径匹配度与时间匹配度,但不同的出行中轨迹点和旅行时间的可靠性可能不相同,因此需要对二者进行权重计算,为可靠性更高的匹配度赋予更高的权重,提升出行方式识别的准确性。在实际情况中,相比于旅行时间,出行过程中的轨迹点一般具有更高的可靠性。因为手机并非实时与基站进行通信,两次通信间隔可能长达几十分钟至数小时不等,因此手机信令数据所反应的用户位置具有明显的滞后性。因而根据手机信令数据提取的用户出行链中的旅行时间可能远大于实际的出行时间。而对于信令的轨迹点,在数据清洗阶段已针对位置点的偏移进行相应处理,经过清洗的轨迹点与用户的实际位置不会产生很大偏差,因此路径匹配度一般具有较高的权重。
路径匹配度和时间匹配度的权重计算主要受到移动点数量与出行距离的比值、旅行时间与导航数据的出行时间的关系的影响,且符合以下原则:
1)当旅行时间小于导航所有出行方式中最短旅行时间的50%或高于所有出行方式中最长旅行时间的50%时,该次出行的旅行时间无效;
2)记出发地基站小区与目的地基站小区直线距离所跨基站小区数量为最大移动点数量;
3)当旅行时间无效且移动点数量大于零时,路径匹配度的权重为100%,时间匹配度的权重为0%;
4)当旅行时间无效且移动点数量等于零时,本次出行无法判断其出行方式,令路径匹配度和时间匹配度的权重均为0;
5)当旅行时间有效且移动点数量大于零时,路径匹配度权重与时间匹配度权重的计算如式(1)所示:
Wt=1-Wr
Wp∈[0.5,1)
(1)
式中,Wr和Wt分别为路径匹配度和时间匹配度权重,n为移动点数量,N为最大移动点数量,Wp为路径匹配度的优先权重。
1.5.3 路径匹配与时间匹配 由于导航数据返回的GPS轨迹点较为密集,因此若用户实际采用的交通方式和线路与之相同或相似时,出行过程中移动点的基站小区中应均有导航数据的GPS轨迹点。但在实际出行中由于建筑物遮挡或基站高程与手机高程相差过大等原因,手机信令数据的定位点可能落在实际基站小区的相邻基站小区内。路径匹配度Mr的计算如式(2)所示:
(2)
式中,nf为基站小区内有导航轨迹点的移动点数量,nh为基站小区内无导航轨迹点但与该基站小区直接相邻的基站小区内有导航轨迹点的移动点数量,kf为导航轨迹点落在直接相邻的基站小区内的折损系数,n为该次出行的移动点数量。
时间匹配度Mt的计算如式(3)所示:
(3)
式中,t为导航数据的旅行时间,T为信令数据的旅行时间。
1.5.4 综合对比 对于每一次出行,对导航数据返回的所有出行方式的所有路线进行路径匹配度和时间匹配度的计算,并根据该次出行的OD距离、移动点数量、最大移动点数量、旅行时间等计算路径匹配度和时间匹配度的权重,根据式(4)计算各出行方式及线路的综合得分S,选取得分最高的出行方式及相应的出行线路作为该次出行的出行方式及出行线路。
S=WrMr+WtMt
(4)
式中,Mr和Mt分别为路径匹配度和时间匹配度。若某次出行方式的判断中出现以下情况,认为该次出行的方式无法判断:
1)根据有效出行的定义属于无效出行的出行;
2)根据权重计算原则,旅行时间无效且移动点数量等于零的出行;
3)综合对比中得分最高的出行方式及路线的得分为零的出行;
4)综合对比中得分最高的出行方式及路线有多个且出行方式不相同的出行。
对于折返出行,若出发地至最远点或最远点至目的地中的一段出行方式无法判断,另一段出行方式可以判断,则认为该次出行的方式为可判断的出行方式;若出发地至最远点和最远点至目的地的出行方式均可判断,但二者不相同,则认为该次出行采用组合出行的交通方式。
2 实例分析
2.1 数据描述
本文测试数据源于个体志愿者采集,在志愿者的手机内安装自主开发的基站采集App,获取手机所连接基站的基站位置区码lac及小区识别码cid,并通过基站API将lac与cid转为经纬度坐标。志愿者将记录其出行链,包括出发地、目的地、出行时间、出行方式等,并在出行过程中保持基站采集App的后台运行。原始手机信令数据如表1所示,主要字段包括信令记录编号id、用户编号isdn、信令产生时间time、移动国家码mcc、移动网络码mnc、基站位置区码lac、小区识别码cid、经度lng和纬度lat。

表1 原始手机信令数据示意表Table 1 Original mobile phone data
2.2 数据清洗与轨迹点分析
首先对原始手机信令数据进行清洗。在稀疏数据处理中,对于有效区间数量的阈值选取,部分用户存在夜晚睡觉时关闭手机的习惯,这部分用户在夜晚存在着约8 h的数据空缺。因此本研究所选取的阈值nsparse为16,即某个用户某天的原始手机信令数据在一天24 h内的分布需大于8 h,加上部分用户夜间关机时空缺的8 h,相当于一个用户需在一天内有2/3的时间产生手机信令数据,该用户该日的数据为有效数据,否则为稀疏数据,需予以删除。在乒乓切换数据处理中,停留时间阈值Tpp本研究中取为1 min。在漂移数据处理中,考虑到信令数据包括在高速公路上行驶的轨迹,速度阈值vdrift取为120 km/h。在轨迹点分析中,最短停留时间Tmin取为60 min,最大活动距离Dmax取为1 km。
2.3 结果分析
对所有手机信令数据的轨迹点分析结果进行出行链提取,共获得了193次有效出行,运用上述出行方式识别算法进行出行方式判断,并采用查全率、查准率、F1值和正确率对算法的识别精度进行评价,193次有效出行的识别结果如表2所示。其中,对于折返出行、出发地至最远点或最远点至目的地二者之一判断正确记为0.5,二者均判断正确记为1。
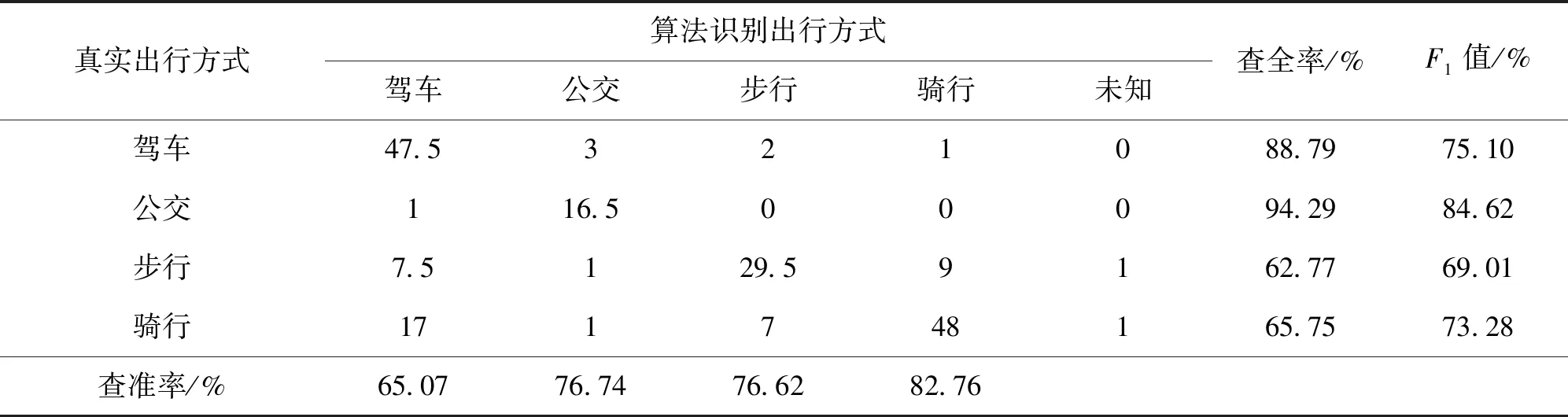
表2 出行方式识别结果Table 2 Result of trip mode recognition
由表2可见,在驾车、公交、步行和骑行四种出行方式中,公交出行的查全率和F1值最高,二者均达到了80%以上。驾车出行次之,其查全率和F1值均达到了75%以上。步行与骑行的查全率和查准率比较低,因为步行和骑行作为慢行交通,出行距离较短,因此在出行过程中产生的信令记录较少,导致其正确率较低。四种交通方式的整体准确率为73.32%。
在相同情况下,本研究在未进行兴趣点分析情况下对手机信令数据进行了出行方式的识别。结果发现,未进行兴趣点分析的基于导航数据的出行方式识别整体准确率为62.44%,本文提出的基于兴趣点和导航数据的出行方式识别的精度提升超过10%。两种方法的查全率与查准率对比如图2所示。由图2可见,经过兴趣点分析后,几乎所有出行方式的查全率与查准率均得到提升,仅公交出行识别的查准率出现下降,算法总体准确率提升明显。
3 总 结
手机信令数据具有样本量大、采集成本低、跟随性强等优势,基于手机信令数据的居民出行特征的有效获取将极大地提升交通信息获取效率,降低交通数据采集成本。本文针对手机信令数据,设计了一套用户出行特征提取方法,包括数据清洗、轨迹点分析、出行链提取、兴趣点分析与出行方式识别五个部分。基于兴趣点、路网数据与导航数据将用户的出行方式划分为驾车、公交、步行与骑行四种模式,并计算不同出行方式及路线的路径匹配度、时间匹配度以及二者的权重,综合判断用户的出行方式。并自主开发设计了基站采集App,同时记录手机信令数据与用户的实际出行,获取了193次有效出行的真实数据。利用本研究所提出的算法进行了出行方式的识别,得到四种出行方式的整体正确率为73.32%,相比于仅使用导航数据的方法,获得了超过10%的正确率提升。

图2 两种出行方式识别算法的查全率、查准率对比图Fig.2 Comparison of two different mode recognition algorithms’ recall and precision
猜你喜欢
悦游 Condé Nast Traveler(2022年2期)2022-02-18
小天使·三年级语数英综合(2021年4期)2021-06-15
通信技术(2020年2期)2020-03-26
恋爱婚姻家庭·青春(2019年9期)2019-12-10
中国交通信息化(2019年2期)2019-03-25
小猕猴学习画刊·下半月(2018年9期)2018-05-14
消费导刊(2017年24期)2018-01-31
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
互联网天地(2016年2期)2016-05-04
