
一种自适应PC-Kriging模型的结构可靠性分析方法
2020-05-22 07:24:22于震梁孙志礼张毅博
东北大学学报(自然科学版) 2020年5期
于震梁, 孙志礼, 张毅博, 王 健
(东北大学 机械工程与自动化学院, 辽宁 沈阳 110819)
随着结构可靠性评估和稳健性设计概念在现代工程可靠性分析中的日益深入,可靠性分析方法也得到了广泛发展和进一步研究.由于在实际工程问题中其功能函数往往是隐式的(强非线性或耗时的),采用经典分析技术如一阶可靠度法(FORM)、二阶可靠度法(SORM)[1]、蒙特卡罗模拟法(MCS)在精度和时间成本上往往难以接受.因此,采用代理模型法(如响应面法[2]、人工神经网络[3]、支持向量机[4]、Kriging[5]等)来近似功能函数计算可靠性得到了迅速发展.
Kriging代理模型[6]是一种精确的插值方法且具有随机性,不仅能提供未采样点的预测值,还能对预测方差进行估计.因此,该方法在结构可靠性分析中得到了广泛应用.为了进一步提高模型的计算精度和效率,一些学者对传统的Kriging模型进行了改进研究,如在建立Kriging模型的过程中加入样本点函数值的同时也考虑了其函数值的梯度信息值,这种模型被称为Co-Kriging模型[7]或梯度增强Kriging(gradient-enhanced Kriging,GEK)[8],在此基础上,Han等[9]为进一步提高GEK的计算效率,提出了改进的梯度增强Kriging方法(weighted gradient-enhanced Kriging,WGEK).Schoebi等[10]提出了一种基于多项式混沌展开(polynomial-chaos-expansion,PCE)和Kriging模型相结合的可靠性方法(polynomial-chaos-based Kriging,PC-Kriging).在分析比较复杂工程结构问题时,往往采用试验设计的思想.因此,若干种自适应试验设计(DoE)策略已被构建,如Bichon等[11]通过所提的EFF函数选择距极限状态最近的样本点作为新增训练点.Echard等[12]提出U函数来衡量未测点符号预测错误的概率,并将U值最小的点定义为最佳样本点.
上述这些基于自适应DoE策略的学习函数能够有效地提高Kriging模型的准确性和效率.然而,由文献[13]可知具有不同基函数的Kriging模型的准确性是不同的,使得Kriging模型在高阶的可靠性分析中难以计算.为了解决这类问题,提出了一种基于PC-Kriging和自适应k-means相结合的结构可靠性分析方法(APC-Kriging).首先,PC-Kriging是一种改进的Kriging算法,其回归基函数采用稀疏多项式最优截断集合来近似数值模型全局行为,而用Kriging来处理模型输出的局部变化,在保证精度的同时提高了计算效率.其次,常见的可靠性方法的采集样本点为逐个采集,而本文的自适应k-means聚类分析将空间分成若干个区域,并从每个区域选取一个最佳样本点,从而使多个区域同时达到提高PC-Kriging模型精度的目的,从而再次提升模型的计算效率.
1 PC-Kriging模型
在构造结构功能函数G(x)的近似代理模型时,Kriging将其假定为由确定性g(x)Tβ和随机性z(x)两部分组成,即
G(x)=g(x)Tβ+z(x).
(1)
其中:向量x为包含M个对结构状态(即功能函数)产生影响的基本随机变量的集合;g(x)为模型基函数,即在PC-Kriging模型中改进的部分;β为基函数的系数矢量;z(x)为均值为0的高斯随机过程,其协方差为
Cov[z(xi),z(xj)]=σ2R(xi,xj;θ).
(2)
式中:σ为z(x)的标准差;R(xi,xj;θ)为z(xi)和z(xj)间的带有参数θ的相关系数,通常为应用最广泛的高斯相关函数.
(3)
给定N个训练样本SDoE=[x1,x2,…,xN]及其对应的结构状态值Y=[y1,y2,…,yN],G(x)预测值的无偏估计及其方差为
(4)

(5)
式中:
u(x)=GTR-1r(x)-g(x),
R=(R(xi,xj;θ))N×N,
G=[g(x1),…,g(xN)]T.
其中,参数向量θ需采用极大似然估计获取.
PC-Kriging采用多项式混沌展开替代传统Kriging模型的回归基函数来增强预测模型的全局近似精度,并利用Kriging模型来捕捉预测模型局部特征的能力.采用最小角回归(LAR)构建回归基函数的最优多项式数量集,同时用Akaike信息准则(AIC)来确定最优的截断集合.
(6)
式中,fXi(x)为x的第i个边缘概率密度函数.
一个完备的Hilbert空间L2(R,f)的标准正交基(f表示x的联合概率密度函数)是
其中,α=[α1,α2,…,αM]是一个自然数的M维向量.这里,满足总项数|α|=α1+α2+…+αM不超过给定阈值T0的项将被保留作为Kriging模型基函数的候选项.基函数的候选项ΑM,T0可表示为
AM,T0={α∈NM,|α|≤T0},AM,T0中项数的数量可由P表示:
(7)
然后,考虑基函数的所有候选项的“完备”设计矩阵:
GM,T0=[ψα0,ψα2,…,ψαP-1],
ψαi=[ψαi(x1),ψαi(x2),…,ψαi(xN)]T.
式中:αi∈A(i=0,1,…,P-1);xnSDoE(n=1,2,…,N).
根据式(7),如果将ΑM,T0中的所有候选函数用作Kriging模型的基函数,则函数调用的次数将随着T0的增加而急剧增加.为了避免这类问题,在构造稀疏多项式Kriging模型的基函数时,采用LAR[14]理论定义了函数的基函数集个数,并用AIC[15]准则来确定哪一个是最佳的.最后,保留中间的候选项以确保Kriging模型的准确性,同时大大减少函数调用的数量(即保留对模型贡献更多的候选项).选择Kriging模型基函数的主要步骤:
步骤1 设置相关参数值,即保留多项式T0的最大阶次和基函数pmax的最多项数,本文设T0=3,pmax=0.5card(SDoE).H=min{P,pmax}.
步骤2 初始化所有候选项中的系数aαi=0 (i=0,1,…,P-1).根据LAR理论,初始化后的剩余项等于结构响应Y.
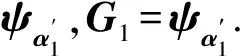

步骤5h=h+1.共同移动a朝向当前残差为Gh-1的联合最小二乘系数,直到向量ψαh与当前残差Gk-1具有相同的相关系数.
步骤6 重复步骤5,直到满足h=H.
步骤7 计算Gh(h=1,…,H)的AIC值:
AICh=Nln(SSEh)+2h.
其中,
SSEh=[Gh(GhTGh)-1GhY-Y]T×
[Gh(GhTGh)-1GhY-Y].
步骤8 找到最小的AICh(h=1,…,H),p=argminh{AICh;h=1,…,H},对于SDoE和Y,PC-Kriging模型的最优基函数为
(8)
2 自适应PC-Kriging方法
构造完近似代理模型后,结构的失效概率可通过式(9)近似计算:
从以上几组中医最为常见的英译解析中可以看出,翻译的方式方法不是单一的,而是音译与意译,直译与辅译相结合的。中医英译是中医走向世界的一道重要关口,是一项严谨、艰苦并富有挑战性的工程,要求译者既精通英语、又要熟悉传统的中医学理论及西医理论,力求译文客观、严密、准确、简洁,既符合英语的思维习惯又表达中医的丰富思想,在中西方文化鸿沟中建起一座桥梁。
(9)
2.1 自适应PC-Kriging方法
所提出的k-means聚类分析自适应策略选取样本点方法步骤:
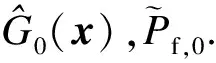
Ω0={(x0,i,y0,i),i=1,2,…,M0},
X0={x0,1,x0,2,…,x0,M0}.
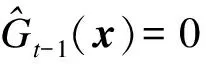
(10)
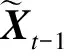
(11)
其中,i=1,2,…,k.
步骤4 调整集合St-1中各点位置.定义距离D0,如式(12)所示.假设在集合St-1中如果任意两个样本点之间的距离小于D0时可视为是不能接受的,此时需要将集合St-1中个别点位置进行调整.
(12)
式中e为给定常数.



2.2 收敛条件
收敛条件采用文献[16]中的学习停止条件,其基本思想为随着迭代过程进行,符号预测错误的样本点数占总失效样本点数的比重很小时,失效概率估计值满足精度要求,学习过程停止,其表达式为

(13)

(14)
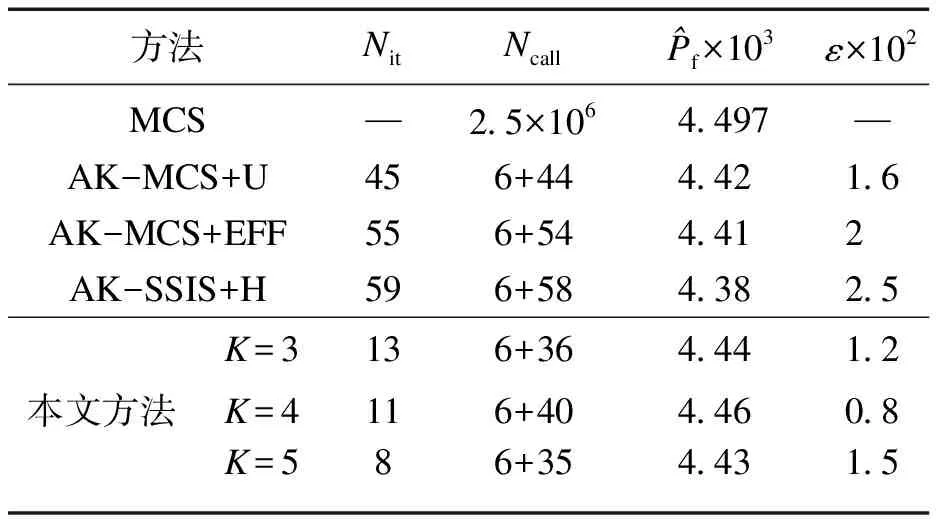
式中,用NU 选取文献[12]中具有多个设计点的状态函数,其表达式为 其中,x1,x2为服从标准正态N(0,1)的独立同分布随机变量. 适当抽取构建初始PC-Kriging模型时所需样本点数,设N0=6.为取得分布较为均匀的初始样本点,采用拉丁超立方抽样(Latin hypercube sampling, LHS)在[-5, 5]区域内抽取初始样本点.通过Matlab中的工具箱根据所提算法建立PC-Kriging预测模型,并通过主动学习,更新样本空间DoE,并不断提高模型精度,重复该过程,直到满足迭代停止条件,结果见图1、表1.其中,Nit表示迭代次数,Ncall为调用样本点数,ε为失效概率估计值与标准值的相对误差,失效概率标准值由MCS方法计算得到. 通过图1和表1的结果对比,可以发现在Ncall项所提方法需要最少的样本点就可以达到足够高精度,而通过对Nit项,因为应用到聚类分析,使得在满足精度的要求下迭代次数得到大幅度的降低,从而提高计算效率. 选用文献[17]悬臂式圆柱筒结构(图2),它是一个拥有9个随机变量的高维非线性的工程结构实例,该结构的9个输入随机变量分别为t,d,L1,L2,F1,F2,P,T,S.其分布特征如表2所示. 表1 二维算例结果对比 表2 随机变量的分布特征 图2中悬臂式圆筒结构受到外力F1,F2,P和扭矩T的作用,其功能函数表示为屈服强度S和最大应力σmax的差: g(x)=S-σmax. 其中:σmax表示在原点处筒上表面所受的最大等效应力;σx为正应力;τzx为扭应力. 首先,采用Nataf变换将上述随机变量映射到标准正态空间,并在[-5,5]9立方体内抽取N0=11个拉丁超立方随机样本点,再应用所提算法评估悬臂式圆柱筒的可靠性.所提算法与其他现有算法所得失效概率估计值随迭代次数的变化趋势如图3所示,其中横坐标为迭代次数Nit,纵坐标为失效概率估计值的对数形式.此外,表3列举了本文算法与其他方法所得结果.通过比较,不难发现本文算法相较于其他方法在效率和精度方面更具优势. 表3 九维算例结果对比 1) 本文提出了一种新的改进Kriging基函数与k-means聚类分析相结合的可靠性分析方法.使得PC-Kriging方法在基函数回归方面具有更大的灵活性.结合k-means聚类分析方法的自适应策略在每次迭代时添加多个新增样本点来提高计算效率. 2) 通过与两个算例中MCS抽样计算的结果对比可知,所提出的算法与MCS模拟较为接近,从而验证了本文所提算法计算精度的正确性. 3)通过对比的可靠性分析结果可以发现,所提方法相对于AK-MCS+U和AK-MCS+EFF将迭代次数降低同时提高了估计精度,说明所提方法具有更快的效率以及更高的精度. 4) 所提方法亦可适用于解决功能函数为隐式多维非线性问题,这为解决实际工程中的可靠性评估问题提供了重要的参考价值.3 算 例
3.1 算例1
3.2 算例2

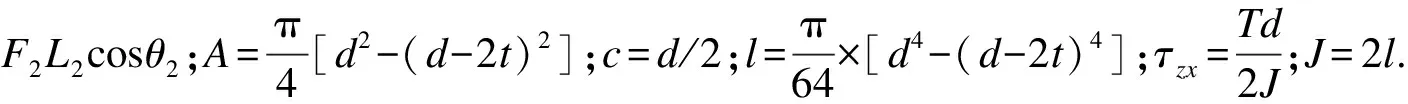

4 结 论
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
上海质量(2019年8期)2019-11-16 08:47:46
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子制作(2018年11期)2018-08-04 03:25:38
电子制作(2017年2期)2017-05-17 03:55:06
数学学习与研究(2017年3期)2017-03-09 18:12:42
测绘科学与工程(2016年5期)2016-04-17 06:51:15
中国老区建设(2016年1期)2016-02-28 09:32:00
电测与仪表(2015年6期)2015-04-09 12:01:18
电子设计工程(2015年3期)2015-02-27 12:03:45
