
基于朴素贝叶斯的新闻文本分类
2020-05-19 14:57韩洪勇姜锦琨杨超然陈照奇
科技风 2020年14期
韩洪勇 姜锦琨 杨超然 陈照奇
摘 要:随着网络信息时代的到来和新闻数据的不断增加,人们需要对新闻进行分类的难度也不断加大。那么,是否有一种有效的分类新闻信息的方法将新闻进行分类呢?而在文本分类中,有较好的文本分类的算法是朴素贝叶斯算法。本研究以通过网络爬虫的方式爬取某新闻网站的少量新闻数据数据,然后对数据进行简单的数据预处理、中文文本分词等,构建朴素贝叶斯分类器,进而实现对新闻分类的目的。
关键词:朴素贝叶斯;新闻文本;中文文本分类
1 绪论
随着网络的迅速发展和大数据时代的到来,与网络随着而来的新闻数据也大量增加。面对爆炸的数据,需要使用恰当的方法对文本进行分类。文档分类大致需要以下三个要素:文本向量模型表示、文本的特征选择和文本训练分类器。而目前比较流行的分类方法主要有贝叶斯方法、SVM、神经网络、k2最近邻算法等等。
本文采用贝叶斯的分类方法。贝叶斯是一种比较简单、学习效率和预测效率都很高,并且性能又较好的基于概率的一种学习算法。朴素贝叶斯是在贝叶斯定理和特征条件独立的前提下,给定训练数据集,根据特征条件独立学习计算输入输出的联合概率分布,然后这就是构建的基础模型,然后再给定输入数据集x,根据贝叶斯定理求出后验概率最大的输出y。
2 朴素贝叶斯算法描述
一般的朴素贝叶斯分类算法的过程如下:
(1)从网络上获取数据,然后对数据进行分类,并标记。
(2)将分好类的数据进行中文分词。
(3)将数据文本中垃圾词语去除。
(4)将上面整理好的词条组合成特征组,计算词条的频率信息。
(5)通过计算得到的词条的频率信息,计算出词条再各个类别文本的先验概率。
(6)再次输入新的数据文本,进行中文分词,去除垃圾词语,合成特征组。
(7)将新的数据样本的特征词条计算得到的先验概率带入朴素贝叶斯公式当中,计算得到后验概率,那么计算得到的最大概率的那个对应类别就是新闻文本的类别。
3 新闻文本的获取及处理
对于新闻数据的获取途径主要是从新闻官网上进行获取,对于一般的新闻网站,可以采用BeautifulSoup库的方法编写代码爬取页面数据,然后对页面数据中的HTML标签进行去除。而对于较为复杂的、大量的页面新闻,甚至具有反爬取处理的网站,就需要使用scrapy框架和代理池的配合来爬取页面数据。
4 分类器的构建
与英文可以通过非字母的方式进行语句的分割,但是新闻内容中都是中文文本,无法使用这种方式。这里使用第三方的中文分词:jieba。使用jieba将中文的语句进行分割,并标记好各自的类别。
在分词完成之后,会发现有很多垃圾词汇(指与分类无关的词汇,比如:的、是、在等),过多的垃圾词汇会降低文本数据的分类的准确率,这里需要自定义一个去除垃圾词汇的规则来去除垃圾词汇。那么,去除垃圾词汇之后的剩余的所有的分词,将这些分词全部用来训练朴素贝叶斯分类器。除此之外,h还要对训练集中的所有分词进行词频的统计,将词频较高的分词排列在前面。排列完成之后,将分词进行文本向量化。
由于利用朴素贝叶斯分类器进行新闻文本分类时,需要计算各个分词向量的概率,然后将这些概率进行相乘,得到乘积,使用这个乘积来获得这个新闻对应的类别。但是如果这个词向量中有一个的概率是0,那么最后分类的结果也是0,无法完成新闻的分类。本文使用拉普拉斯平滑的方法,将所有词向量的出现的词频数增加1,也就是由之前的最低詞频0变成现在的最低词频1,然后最低分母初始化为2,这样就阻止了出现0的概率。
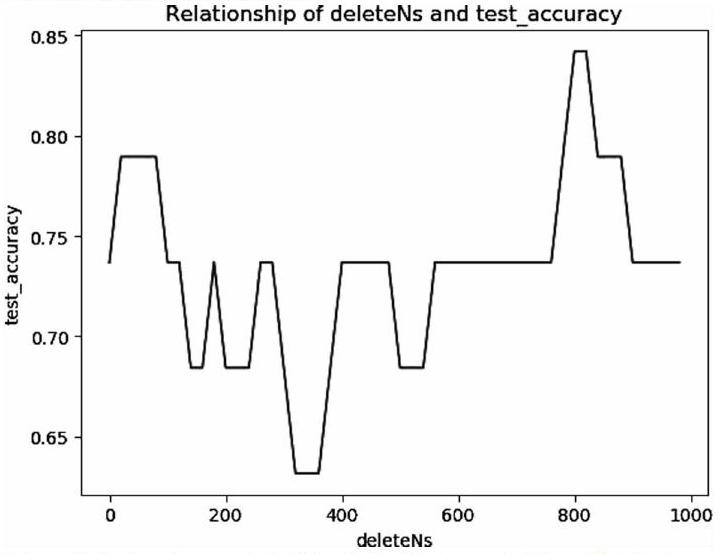
为了更加快速构建文本分类器,本文直接使用sklearn库里面的naive_bayes方法直接构建分类器,采用先验概率为多项式分布的朴素贝叶斯方法来进行构建。在sklearn中我们可以通过观察多次去掉多少个高频词的个数和最终检测率的关系,这里绘制出高频词(deleteNs)和准确率之间的关系来选择本文最终决定删除高频词的个数。
通过观察上图,本文最终选定deleteNS的个数为810,然后使用去掉高频词的个数为810,构建新闻分类的朴素贝叶斯分类器。最终测试的分类精确度为79.368%。
5 问题及改进
朴素贝叶斯算法是由贝叶斯定理发展而来,算法比较简单,对于分类问题有着比较稳定的分类效率。同时,朴素贝叶斯分类器对于小规模的数据分类表现很好,并且适合增量式训练。除此之外,朴素贝叶斯算法对于缺失数据不太敏感,用于文本分类效果较好。理论上来说,朴素贝叶斯分类算法与其他分类算法相比误差较小,但是在实际情况上来看,当属性个数比较多的情况下或者各个属性之间相关性比较大时候,分类效果并不是很好,只有在各个属性之间的相关性较小的情况下,朴素贝叶斯算法才能达到较好的分类效果。对于这种情况,可以通过改进部分属性的关联度,也就是半朴素贝叶斯算法。由于朴素贝叶斯是在假设各个条件相互独立的前提下求出的先验概率,但是在现实情况下先验概率未必准确,所以预测效果可能没有那么好。除此之外,朴素贝叶斯算法对输入数据的形式也有很大的敏感性。
参考文献:
[1]崔哲.基于朴素贝叶斯方法的文本分类研究[D].河北科技大学,2018.
[2]Peter Harrington.Machine Learning in Action[M].人民邮电出版社,2013.
[3]麦好.机器学习实践指南[M].机械工业出版社,2016.
作者简介:韩洪勇(1999-),男,山东青岛人,现于山东科技大学攻读学士学位,目前主要从事于计算机科学与技术的专业研究。
