
基于深度学习的实验鼠行为识别关键技术研究①
2020-05-18 13:26徐涌霞
佳木斯大学学报(自然科学版) 2020年2期
徐涌霞
(淮北职业技术学院计算机系,安徽 淮北 235000)
0 引 言
行为的准确量化对理解大脑[1-3]至关重要。目前在神经科学等传统的领域内使用新技术(如深度学习)来进行相关研究卓有成效。通常,新技术的应用有可能揭示正在研究的现象中无法预料的特征,例如在19世纪中叶梅布里奇著名的摄影研究。以往所收集到的数据都是需要人工进行分析的,这是一个费时、费力且容易出错的过程。随着大数据时代的来临,人工进行数据采集的效率极低。而计算机视觉和人工智能相关技术的进步为数据分析提供了新的思路[4-6]。研究利用深度学习这一新兴技术,探讨实验鼠行为的识别问题。
1 深度神经网络及性能指标
首先,探讨动作识别深度神经网络在实验室老鼠行为数据集上的表现。采用老鼠行为短片的数据集进行实验。应用两种不同的输入方案:第一种是不进行预处理的端到端输入;第二种是跟踪信息中基于区域的输入,即动物周围的区域以及光流。在有数据增强和无数据增强的情况下进行训练。然后,探讨深度神经网络在连续视频和不同设置下的性能。使用性能最佳的输入方案评估实验室老鼠的行为视频。
1.1 Multi-Fiber神经网络
使用了多纤维网络(Multi-Fiber网络)[7]作为深度神经网络模型。与现有的深度神经网络相比,多纤维网络在一些重要的行为识别基准数据集上均有较高的识别效率。多纤维网络使用轻量级的网络(即Fiber)的组合来替代复杂的神经网络,从而能在提高识别性能的同时降低计算成本。多路复用器模块用于Fiber模块之间的信息流。
采用的网络由一个3维卷积层(用“conv3d”表示)和四个多纤维模块(用“MFconv”表示)组成。每个MFconv模块包含多个多纤维单元,每个多纤维单元包含四个conv3d层。所有conv3d层输出的结果均进行批标准化并输入到整流线性单位(ReLU)。网络的最后一层是平均池层和完全连接层。
1.2 性能指标
对于行为识别算法,最常用的性能指标是top-1准确率和top-k准确率。但是,正如从连续视频中进行采样一样,这些指标对于具有同等重要类别的不平衡数据集具有误导性。假设主要类别覆盖了80%的样本,并且模型将所有的样本归为该类别。那么这个分类器的总体同意率将是80%。在这种情况下,不仅需要评估模型的准确率,还需要评估模型的精度和召回率。使用平均召回率作为聚合度量。由于考虑了所有类别,所有标记不良的样本均会对平均召回率产生负面影响,因此这里并没有考虑精度。与平均F1-score相比,稀有类别的误报率要比频繁类别的误报率更大。同时,还考虑了交叉设置评估中每个视频的总体一致性。实验鼠的行为并不是离散的,而且行为的改变需要时间。因此,模型是无法获得100%的准确率。在文中所有的实验和评估中,不属于九个类别之一的帧都被排除在评估之外。
2 视频片段的网络模型配置
2.1 数据集
实验使用了一个高质量数据集[8],该数据集由生活在行为观察箱的六只实验鼠的视频组成。视频长度为25.3h,分辨率为720×576像素,每秒25个帧。其中约2.7个h的视频由实验室观察员使用注释软件进行标注。重点研究九种最常见的状态行为类别:喝水、进食、舔毛、跳、休息、无支撑站立、支撑墙站立、嗅探和行走。
端到端的输入模式是分辨率大小被调整为224×224的灰度视频。在视频片段上训练的端到端模型称为EtoE。除了端到端模式以外,还将区域作为输入。该区域是以实验鼠为中心、分辨率为88×88的运动区域。同时,将光流添加到帧运动信息的第二和第三通道中。文中用Region表示以区域作为模型输入的模型。
2.2 MF网络参数设置
因为EtoE模式和Region模式的输入分辨率不同,因此网络模型的结构略有不同。主要的区别在于:Region分辨率需要较少的空间缩小,因此Region中省略了最大池化层。这两个网络模型拥有约770兆个参数,模型的相关参数如表1和2所示。

表1 EtoE模式的网络参数设置
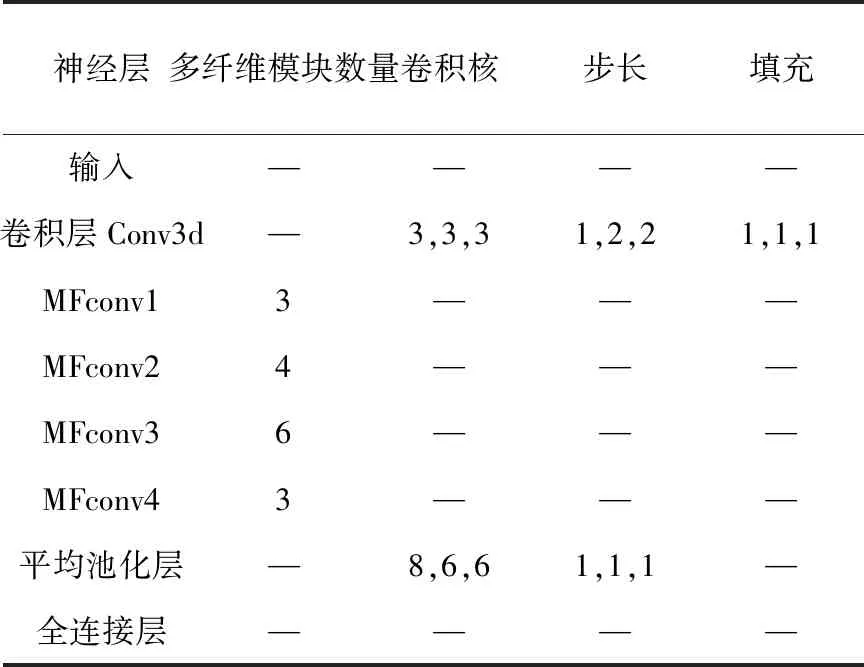
表2 Region模式的网络参数设置
2.3 采 样
对不同的随机训练/测试分组执行四重交叉验证。每重验证中都有2314个训练视频片段和398个测试视频片段。每个片段包含32个连续的帧。片段标签是片段中间点的行为,即第17帧的注释。对于随机选择的片段,片段中间的第14帧和第19帧之间不能出现行为转换。在训练集中,片段的最大重叠为29帧,并且每个片段最多选择四个片段行为回合,每个行为最多400个片段。对于测试集,最大重叠为25帧,每个行为回合最多选择两个片段,每个行为最多50个片段。来自同一行为回合的片段始终以相同的方式组合在一起,因此无论是在训练中还是在测试集中。
2.4 数据增强策略
为了防止过拟合,可以通过随机组合以下的过滤器来增强数据:调整剪切、水平和垂直翻转、反向、旋转、亮度变化等等。此外,使用了两个新的过滤器:视频剪切和动态照度变化。视频剪切是2D剪切的3D版本。这意味着通过使用平均片段值替换随机放置的长方体来向片段添加遮挡。通过向片段添加随机3D高斯来创建动态照明变化。对于Region模型,光流是在随机旋转并反转视频帧之后计算的。不采用调整剪切,并且仅将亮度变化过滤器应用于灰度通道。Region模型不使用动态照明变化过滤器,因为它会影响光流的计算。在数据增强后,对片段进行标准化,使其平均值为0、标准差为1。对每个通道均进行标准化,以避免混合图像和光流信息。
3 连续视频的网络模型配置
3.1 数据集
实验使用交叉设置验证数据集[8],如表3所示。数据集中包含一个来自内部设置数据集的视频以及四个以不同分辨率、光照、背景以及饲养者的视频。视频的帧率和相机视角并未发生变化,所有视频均在恒定光照下进行拍摄,并且动物和背景之间具有良好的对比度。
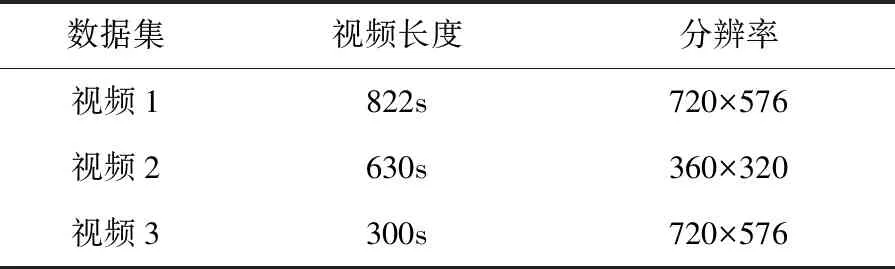
表3 视频数据集参数
3.2 采 样
为了评估模型在实际场景中的鲁棒性,接下来评估在连续视频数据集下模型的性能。上一节实验的数据集是在平衡的片段子集上进行的,而且忽略了行为回合过渡周围。而本节的实验部署在滑动窗口片段(宽32帧,步长1帧)上。与上一节相比,实验的片段包含的数据含糊不清,并且片段集合不平衡。
在交叉设置实验中,仅考虑端到端模式。将在整个均衡片段数据集(一共有2712个片段)上训练的EtoE模型应用于测试视频的滑动窗口片段。然后在上一节的数据集中的所有滑动窗口片段上对模型进行了重新训练,其中帧宽为32,步长为4。将这个新模型称为enEtoE。滑动窗口片段集具有52,560个片段,并且数据不平衡。为了解决训练过程中的不平衡问题,使用了加权随机抽样。在每个时期内,频率较低的行为都会更频繁地呈现给模型。由于应用了随机数据增强,网络可以看到不同版本的剪辑。
4 实验评估
实验环境的配置如下所示:处理器为英特尔至强Xeon E5-1603 v4 3.5GHz,内存为 32 GB,显卡为NVIDIA Titan X,显存12 GB,操作系统为Ubuntu 18.04,深度学习的框架为PyTorch,采用高级语言Python 3.7进行算法实现。
4.1 视频片段实验结果
图1展示了有数据增强和没有数据增强的分类结果。具有数据增强的端到端输入模式具有75%的平均召回率的最佳结果。表4展示了每种行为的召回率。图2是进行数据增强后的影响。
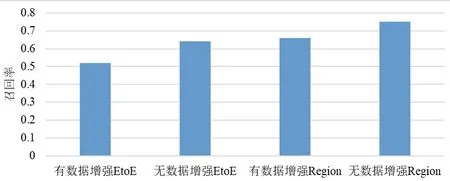
图1 有/无数据增强下EtoE和Region模式的召回率
表4 各种行为的召回率
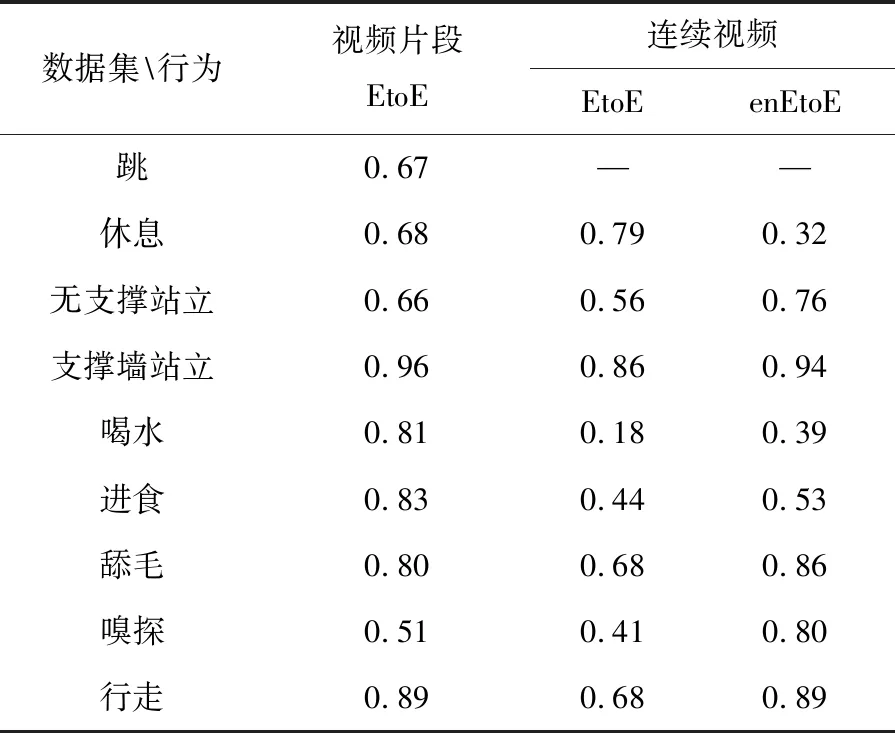
数据集行为视频片段EtoE连续视频EtoEenEtoE跳0.67——休息0.680.790.32无支撑站立0.660.560.76支撑墙站立0.960.860.94喝水0.810.180.39进食0.830.440.53舔毛0.800.680.86嗅探0.510.410.80行走0.890.680.89

图2 数据增强对召回率的影响
4.2 连续视频实验结果
首先,评估了端到端模型在连续视频数据集上的性能。在表4中,与EtoE相比,enEtoE模型在除休息以外的其他行为上都具有更好的性能。接下来,在不同设置下的视频集上评估了enEtoE模型。表5列出了每个视频数据集的总体一致性。与人工分类(即RBR)相比,enEtoE具有更好的总体一致性。
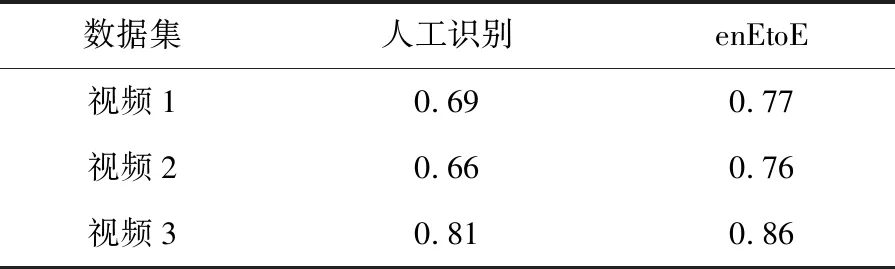
表5 视频的总体一致性
5 结 论
研究探讨实验鼠行为识别的问题,将深度神经网络(即多纤维网络)应用于实验鼠的行为识别。在不同的输入模式、不同的数据增强方案下进行了大量的实验。与人工分类相比,在进行数据增强后,具有端到端输入模式的多纤维网络有着更好的分类性能。未来的工作集中于进一步优化多纤维网络的结构,实现自动化的实时实验鼠行为识别。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
妇女生活(2019年9期)2019-09-24
电子制作(2019年24期)2019-02-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
饮食与健康·下旬刊(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
发明与创新·大科技(2016年1期)2016-02-01
