
基于多准则决策与机器学习的医药企业库存分类研究
2020-05-16 08:59:26刘位龙LIUWeilongYANGShuang
物流科技 2020年4期
刘位龙,杨 爽 LIU Weilong, YANG Shuang
(山东财经大学 管理科学与工程学院,山东 济南250014)
0 引 言
目前医药零售行业的库存管理多数只是按照GSP 标准分开摆放或按单一ABC 分类标准管理。近年来多指标库存分类的研究越来越多,Keskin 等人运用模糊聚类方法进行多规则库存管理[1];吕杏放等人用ABC—CVA 矩阵分类法对药品进行分类[2];Kartal 等人首先使用三种不同的多准则决策技术,然后用机器学习对初始确定的库存项进行分类并验证其可行性[3];Lolli 等人提出了从项目总体中提取样本进行分类,再运用机器学习方法按照分类标准对样本外项目实现分类的方法[4]。对库存分类指标较多且没有明确边界时选用模糊聚类分析会更为合适。机器学习进行分类需要有预分类的样本集,通常训练样本集是不易获得的。
本文运用多准则决策与机器学习相结合的分类方法,不但弥补了单一属性分类的不足,还能在SKU 数目不确定的情况下快速、精准地识别药品类别。
1 基于多准则决策与机器学习方法的分类策略
为了改善传统ABC 分类准则单一的局限性以及快速识别出在库药品的类别,运用基于多准则决策与机器学习相结合的库存分类策略。该策略的三个步骤为:
1.1 分类准则选取及权重确定。根据药品特征、供给及需求特性确定7 个分类准则。正向指标有出库量、出库频次、提前期、价格,表示正向越大越需要重点管理。负向指标有供应商数量、可替代性、产品保质期,表示正向越小越需要重点管理。由于分类准则都是可获得的客观数据,故采用熵权法根据各指标的变异程度来确定权重。
1.2 基于多准则分类的学习集确定。避免FCM 算法把所有指标都认为同等重要的缺陷,采用加权模糊C 均值聚类(WFCM) 算法对抽取样本分类。基于目标函数的WFCM 算法,是将n 个样本划分为c 类,不断修改聚类中心和隶属度矩阵实现样本分类,把隶属度最大的类别作为最终的输出类别。dik为样本xi与第k 类中心vk的加权距离,指标熵权为ws,加权欧式距离为:

库存样本分类后,采用轮廓系数S(i )评价聚类效果[5]。a(i )是药品i 到同类别其他药品的平均距离,b(i )为药品i 到不同类别药品的平均距离,数值越大分类效果越好。

1.3 分类模型的建立。KNN 分类算法指导思想是由邻居推断样本的类别,该算法不用调参训练,易于实现,样本容量较小时比较容易产生误分;朴素贝叶斯分类是求解各个类别出现的概率,概率最大的认为待分类项属于的类别,该算法假设属性值是独立的,在实际情况中是不成立的;BP 神经网络通常适用于大型和不精确的数据集,该算法是通过样本数据的训练,由输出层开始逐层计算各层神经元的输出误差,然后根据误差梯度下降法来调节各层的权值和阈值,使修改后的网络的最终输出能接近期望值;支持向量机在处理样本数量少、非线性等实际问题中发挥重要作用,通过将原始特征空间映射到更高维度的特征空间,使原数据的映像具有线性关系,然后在高维度的特征空间进行学习、分类,本文选取径向基核函数实现非线性分类,多分类可在每两类样本间训练一个分类器的“一对一”多分类算法。
2 实例分析
2.1 实例背景及相关数据获取。S 医药企业是医药零售行业的龙头企业,目前在库药品近3000 种,企业经营规模在不断扩大。按照等距抽样每间隔10 个SKU 抽取一个样本为本文选取要研究的对象,共选取273 条库存项目数据。得到的原始数据如表1 所示:

表1 药品分类指标原始数据
2.2 指标权重确定。熵权法确定各指标权值,标准化处理后的数据见表2:

表2 药品指标的标准化数据
指标的熵值:es= (0.777;0.740;0.947;0.900;0.850;0.919;0.937 );
指标的熵权ws= (0.240;0.279;0.058;0.108;0.161;0.087;0.067 )。
2.3 加权模糊C 均值算法确定训练样本。数据标准化及权重确定后,给定迭代终止条件ε=1e-5,按cmax=2ln(n ),聚类数取值为2≤c≤11。当c=3 时,模糊聚类中心见表3,选取编号1~5 及252~256 的数据列出模糊隶属度矩阵见表4。

表3 c=3 模糊聚类中心

表4 c=3 模糊隶属度矩阵
c=2,4~11 结果不再逐个列出,不同的聚类数采用轮廓系数进行有效性分析得到图1,确定最佳的聚类数目是3。最终的分类数目A 类35 种,占12.82%;B 类93 种,占34.07%;C 类145 种,占53.11%。
2.4 机器学习分类模型的建立
(1) 数据预处理及训练模型。先要对数据处理成相应软件所规定的数据格式。KNN 中K 取5 确定分类精度;朴素贝叶斯对每个类别确定先验概率、每个特征属性计算划分的条件概率来实现训练;BP 神经网络是通过激励函数Logsig 以及梯度下降算法Traingdx 来实现训练;SVM 运用Grid.py 搜索最优惩罚系数c 和径向核函数自带的参数g 来实现模型训练。
(2) 应用模型。从表5 可以看出S 医药企业库存分类结果表明SVM 得到的分类正确率是最高的。图2、图3 为SVM算法的预测精度。训练出的加权SVM 分类模型精度很高,能达到库存分类管理的标准,可以在企业实际管理中运用。
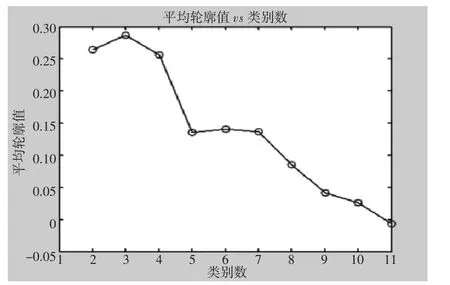
图1 聚类数目的平均轮廓值

表5 各分类模型正确率对比
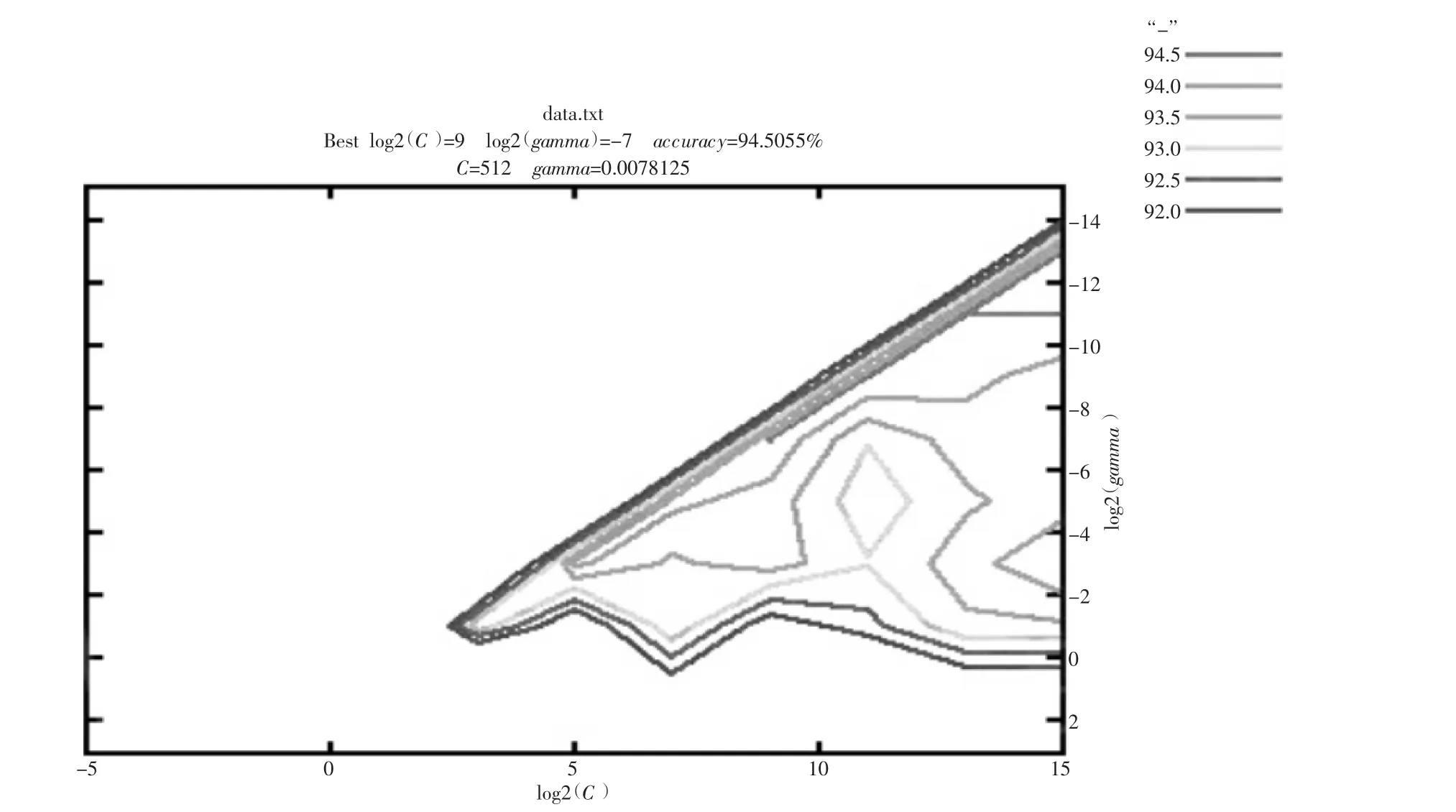
图2 Wdata 数据集训练结果图
3 结 论
本文针对医药零售企业的药品库存分类问题,提出了将多准则决策与机器学习相结合的分类策略。以S 企业的数据进行实证分析,在分类基础上对AB 类采用(R, Q )库存控制策略,C 类采用(T, S )库存控制策略。与企业现有的传统ABC 库存控制策略进行对比,库存周转率由0.89 提高至1.32,库存周转天数由33.57 天降低至22.81 天,表明该分类策略能够增加库存周转、降低库存成本,证明了该分类策略的有效性及合理性。

图3 wdata 数据集训练结果图
猜你喜欢
数学物理学报(2020年1期)2020-04-21 06:00:54
中国房地产业(2016年7期)2016-09-24 08:27:12
系统工程与电子技术(2016年7期)2016-08-21 13:59:02
中国市场(2016年45期)2016-05-17 05:15:23
中国老区建设(2016年5期)2016-02-28 09:32:33
新校长(2016年8期)2016-01-10 06:43:59
浙江共产党员(2015年11期)2015-05-23 12:05:41
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
湖南水利水电(2014年2期)2014-02-27 14:45:24
