
基于神经网络的三维重构研究
2020-05-11 11:44郭威强胡立生
微型电脑应用 2020年2期
关键词:神经网络
郭威强 胡立生

摘 要: 从天基安全系统的信息采集与目标识别的角度出发,使用神经网络的方法对目标物的三维重构进行研究。实现了从物体二维图像到三维立体的神经网络结构,该神经网络由特征编码、循环学习、解码三个部分组成,并对网络输出的体素概率模型进行Delaunay三角剖分和Loop细分,最终得到了目标物点集致密、细节良好的重构模型。该方法应用于天基安全智能打击系统,有效减少了对照片数量的要求、减轻运算压力,提高侦察安全性。
关键词: 天基安全智能打击; 神经网络; 三维重构
中图分类号: TP311 文献标志码: A
3D Reconstruction Based on Neural Network
GUO Weiqiang, HU Lisheng
(School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240)
Abstract: In terms of information collection and target recognition of space-based security systems, the method of 3-dimensional reconstruction using neural network is studied. The neural network structure from 2-dimensional images to 3-dimensional object is realized. It consists of three parts: feature coding, loop learning and decoding. The probabilistic model is outputted and the prime methods of optimizing it are Delaunay Triangulation and Loop Subdivision. Finally, a reconstruction model with detailed dense details is obtained. In the space-based security system, this method can effectively reduce the number of photos needed and calculating pressure, and improve the security of reconnaissance.
Key words: Space-based security strike system; Neural networks; 3D reconstruction
0 引言
天基信息系統是指由通信卫星、侦察卫星、导航卫星及相应的地面控制系统组成的,利用外层空间的航天器进行信息获取的系统。随着空间信息日益融入政治、军事、社会和文化,以及空间军事化进程的加速,空间安全已经成为国家安全的重要领域。天基信息系统对于空间安全至关重要。在天基安全智能打击任务中,需要对敌方卫星进行指向性打击,破坏其图像采集模块,对敌方卫星进行快速、有效的识别成为该任务中的关键。
传统的信息采集需要侦察卫星对目标卫星进行环绕飞行,通过采集到的目标卫星的图像信息,判断哪些位置可以成为指向打击目标。在此过程中,需要多角度下的目标图像才可以获悉卫星整体结构,再对目标单元的相对位置进行判断。在此过程中,由于敌方卫星的飞行轨迹等的不确定性,给绕飞飞行的轨迹规划带来了很大的困难性。因此,在此基础上,本文提出利用神经网络完成三维成像任务,在对目标卫星采集较少图像的基础上,实现目标卫星的三维重构。与利用视觉进行三维重构相比,利用神经网络进行三维重构可以大大减少对目标物图像数量的需求,很大程度上将减少设计采集图像路线的繁琐,确保了安全性、隐蔽性,提高了作战时的灵活性。
三维物体重构的核心目标,就是在物体的图像数据的基础上,利用计算机对这些图像数据进行处理分析,结合计算机视觉知识得到真实环境中物体的三维信息,重建物体的三维模型。一般地,三维重建技术可以分为两大类,一种是将激光、声波等介质发射至目标物体,利用物体的回波信息来获得物体深度信息,这种方式被称为主动式三维重建技术;另一种便是被动式三维重建技术,其利用自然光的反射获得相机图像,经过特征匹配等算法从图像中获得物体的三维信息,主要分为如下三类:纹理恢复形状法(Shape From Texture,SFT),阴影恢复形状 (Shape From Shading,SFS),立体视觉法(Multi-View Stereo,MVS)。在二十世纪后期,在U.R.Dhond[1]等学者的推动下,基于双目视觉的三维重构方法在三维重构领域取得了巨大成功。
上述的各种三维重构相关的技术或者研究,都可以被归纳为实现三维重构的传统方法。不少研究深度学习的学者开始从深度学习出发实现三维重构,希望利用神经网络对图片信息的处理优势,避免传统方法对相片数量、质量、运算资源的依赖,提高重构效果。Maxim Tatarchenko[2]等人使用卷积神经网络实现了利用单视角二维图像获得该物体的其他指定视角的图像。Wu[3]等人在获得深度图的基础上,利用深度置信网络来预测三维立体体素出现概率,从而实现三维重构,但是该方法要求获得目标物的深度图,对成像设备要求较高。Vetter[4]等学者利用高质量的面部扫描图像,在大量关键点标注和特征区域分割的前提下,也实现了单张照片重构人脸信息,但是该方法只能获得单一视角下的三维信息,并且对于图像标注要求较高。
在现有研究的基础上,本文使用ShapeNet[5]数据集,旨在用生活中常出现的物体进行方法可行性的探究,在单张照片输入或者少量照片输入的情况下,提取二维图像的特征向量,再利用该特征完成三维立体的重建。之后,对重建出来的三维体素信息进行可视化优化,经过Delaunay三角剖分和Loop细分,得到点集致密的三维物体表面。该过程体现出了利用神经网络进行三维重构方法的可行性。
1 网络介绍
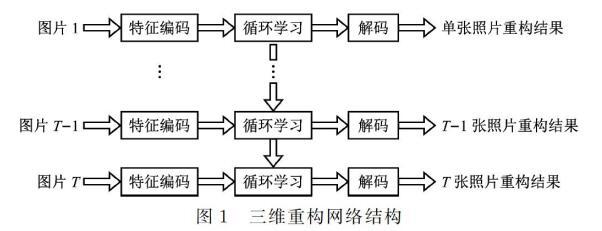
本文所使用的网络结构如图1所示。
包含了特征编码、循环学习、解码三大部分。特征编码部分提取照片中的特征信息,循环学习部分获得多张照片之间的联系,解码部分将循环学习的结果解码为物体的三维结构。
1.1 卷积部分
1962年,Hubel和Wiesel[6]发现初级视觉皮层中的神经元会响应视觉环境中特定的简单特征(尤其是有向的边)。他们对简单细胞(它们只在非常特定的空间位置对它们偏好的方向起最强烈的响应)和复杂细胞(它们的响应有更大的空间不变性)的发现,发展成为了卷积神经网络的两个重要基础:对特定特征的选择性、前馈连接增大空间不变性。模仿人观察物体时的视觉神经元的工作机理,本文首先使用卷积神经网络对物体图像进行处理,利用卷积神经网络局部感知、权值共享的处理方式,对物体图像特征实现抽象化提取。合理有效的特征提取方式是实现三维重构任务的前提与保障。
1.2 循环学习部分
人在观察物体时,通过转换角度,获得多角度的物体视图,从而不断丰富对物体的认知。对于神经网络来说,同样需要获得多张输入图像之间的相互联系。因此本文参考Choy[7]提出的3D-R2N2模型,设计的网络核心部分为3D-LSTM,如图2所示。
传统LSTM单元在每个时刻,可以获取该时刻的输入和上一时刻的记忆细胞的隐藏状态;不同的是,3D-LSTM在获取卷积网络得到的特征向量输入和上一时刻的记忆细胞的隐藏状态的同时,还会获得周围空间的LSTM单元的上一时刻的隐藏状态,这三部分信息都将作为该单元当前时刻的输入信息。
3D-LSTM可以利用其他照片中的区域信息实现该部分重构结果的完善,最终每个单元负责重构一部分三维物体,共同完成物体的重构工作。其运算如下,其中,ft和it分別代表了遗忘门和输入门,因为该网络只需要在最后进行输出,因此相比传统的LSTM,也减少了输出门。st和ht分别代表了神经元状态和隐藏层,同时ht也为输出向量。T(xt)为第t张照片经过第一部分的卷积处理得到的特征向量和周围单元的隐藏状态的组合,矩阵W表示待训练参数。该部分包含有两种激活函数:σ(·)表示Sigmoid函数,tanh·表示双曲正切函数。ft=σ(WfTxt+Ufht-1+bf)
(1)
it=σ(WiTxt+Uiht-1+bi)
(2)
st=ft⊙st-1+it⊙tanh(WsTxt+Usht-1+bs)
(3)
ht=tanh(st)
(4) 从3D-LSTM单元的运算过程可以看出,每个运算单元既可以获得与周围单元的联系,也可以获得与其他照片中的空间单元的联系。在增加输入照片数量的情况下,该设计可以使得不同视角下的物体结构信息互相补充。相较于传统的点云配准方法,由于网络的设计更加具有普遍性,因此在增加照片数量的情况下,神经网络的快速性得以体现。同时,在单图像输入的情况下,虽然无法获得与其他照片中空间单元的联系,该部分仍可以实现从特征向量到初始立体模型的转变。
1.3 反卷积部分
在神经网络的研究中,反卷积更多的是充当可视化作用。研究者以各层输出的特征图作为反卷积网络的输入,通过反卷积的还原,可以对卷积核的效果有清晰的可视化,以验证显示各层提取到的特征图的正确性。从某种角度来说,卷积神经网络实现了从图像到特征的转换,这个过程是在降维,那么为了获得物体的三维结构,则需要利用反卷积实现升维。
因此,本文利用反卷积网络实现了这一过程。在经过上层网络提供的特征向量之后,反卷积网络对特征向量演变得到的初始的立体模型层层细化,使得立体模型的分辨率不断增加,最后输出三维立体。反卷积解码模块主要由3D卷积层、非线性层以及3D反池化层组成,由LSTM单元输出的隐藏层状态ht通过反卷积各层,形成三维立体V,并且通过进一步的反卷积增加分辨率,直到立体分辨率达到32×32×32时停止反卷积操作。
1.4 损失函数与评价指标
在把LSTM输出的隐藏层状态ht转化为存在三维体素概率模型之后,使用了基于体素单元的softmax,同时使每个体素(i,j,k)的概率值都服从伯努利分布[1-p(i,j,k),p(i,j,k)],其中输入χ=xtt∈{1,…,T}的依赖项被忽略,定义每个输入相对应的真实预测值为y=(i,j,k)∈0,1,定义重构网络的损失为体素交叉熵的和。最终得到的损失函数的计算公式如下,其中i,j,k表示输出三维体素的空间位置。 Lχ,y=∑i,j,kyi,j,klogpi,j,k+
1-yi,j,klog1-pi,j,k
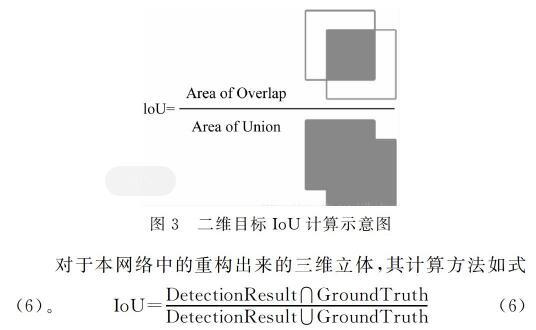
(5) 针对网络输出为三维立体的特点,网络使用了空间IoU(Intersection over Union),即网络输出三维模型与真实物体模型的重合度作为网络的评价指标,该指标有效地体现了重构结果的准确性高低。对于二维图像来说,其表示含义如图3所示。
对于本网络中的重构出来的三维立体,其计算方法如式(6)。
IoU=DetectionResult∩GroundTruthDetectionResult∪GroundTruth
(6)
2 可视化优化及效果
网络最终输出为32×32×32个位置上存在体素的概率值。在此基础上,首先利用设定阈值的方法,得到三维物体的体素模型,利用体素立方体表示的方法对三维物体进行展示。该方法可以基本实现三维物体的展示,但细节表现不足。之后本文进一步使用网格化和细分表示的方法,对表现效果进行了优化。
2.1 体素立方体表示
在经过神经网络之后,可以得到图像中物体的三维体素概率模型,每个体素的概率对应了该位置存在体素单元的可能性,以0.6作为阈值,可以得到离散点构成的三维模型,散点模型如图4所示。
但是点没有体积也没有面积,点与点之间的空隙给人认知物体地来了很大困难,同时没有物体线与面的信息,整个物体的形态无法直观获得。
自然地,在此基础上,得到了体素立方体的表示法。将三维模型离散信息中的体素单元用一个小立方体表示,像搭积木一样将整个模型“搭建”起来,便可以获得如图4中的体素立方体表示。整体来看,网络模型线、面结构清晰,可以获得物体的整体形状。但是用立方体表示,使得模型在线、面表示上多出来很多凹凸部分,尤其是对于曲线型的棱边以及曲面时,用体素立方体表示必定会带来不平整感。
2.2 网格化表示
网格化体素,即将部分点用平面代替,便可以用尽可能少的点来表示模型,在这个过程中,用网格来表现物体外表面,不需要关注内部的体素信息,计算速度得到提升,模型表达得以优化。对于获得的空间体素信息,使用空间Delaunay方法对点进行体素点的三角剖分。得到三角化表示结果,如图5所示。
之后,为了优化最终结果,对网格进行Loop细分。Loop细分由Loop在1987年提出,是一种面向三角形网格的细分方法。其采用面分裂的方式,在三角形网格的每条边上插入点,然后各点连接,形成了小三角形。从数量上进行统计,每进行一次细分,网格中的三角形数量都会变为原来的4倍。
如图5中的Loop细分结果,可以看出经过Loop细分之后,三维物体表面的点信息得到了大量扩充,在大量点信息的基础上,可以构建出丰富的面,由细致的三角形网格组成的三维立体,除了在平面、棱角处有着很好的重构精度外,在曲面的恢复,棱角的转折处也有着很好表现。
3 总结
從整体来看,本文利用神经网络实现了在单张图片输入情况下的三维重构任务,并且针对网络输出的三维体素概率模型进行可视化优化,效果良好。用ShapeNet中的测试集对本文网络进行测试,该测试集包含有13类物体共8 725个模型,最终实现了在单张照片输入输入情况下,IoU可以达到60.1%,再增加输入图象数的时,重构精度也有明显提升。
在目前研究的基础上发现,在单照片输入或少照片输入的情况下,可以有效地实现目标物体的三维重构。与传统的目标物信息获取方式相比,该方式对输入照片的数量、角度要求低,同时也有效降低了运算压力。由此可见,利用神经网络进行三维重构在天基信息系统的目标检测问题中有着巨大优势,但是就具体卫星的类型、目标原件的位置等问题仍有不少难点,将继续进行进一步研究。
参考文献
[1] U R Dhond, J K Aggarval. Struct from Stereo—A Review[J]. IEEE Transactionson Systems, Man, and Cybemeties,1989,19(6): 1489-1510.
[2] Tatarchenko M, Dosovitskiy A, Brox T. Multi-view 3D Models from Single Images with a Convolutional Network[J]. Knowledge & Information Systems, 2015, 38(1):231-257.
[3] Z Wu, S Song, A. Khosla, et al. 3d shapenets: A deep representation for volumetric shapes[C]. In CVPR, pages 1912-1920, 2015.
[4] Blanz V. A morphable model for the synthesis of 3D faces[J]. Acm Siggraph, 2002: 187-194.
[5] Chang A X, Funkhouser T, Guibas L, et al. ShapeNet: An Information-Rich 3D Model Repository[J]. Computer Science, 2015, 4(6): 113-119.
[6] Choy Christopher B, Xu Danfei, Gwak Jun Young. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction[J]. 2016, 3(2): 628-644.
[7] Hubel D H, Wiesel T N. Early exploration of the visual cortex[J]. Neuron, 1998, 20(3):401.
(收稿日期: 2019.01.23)
作者简介:郭威强(1994-),男,硕士研究生,研究方向:基于神经网络的三维重构研究。
胡立生(1970-),男,教授,博士,研究方向:过程控制、控制性能评估与故障诊断等。文章编号:1007-757X(2020)02-0082-04
猜你喜欢
客联(2022年3期)2022-05-31
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2021年2期)2021-11-10
西部交通科技(2021年9期)2021-01-11
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
