
加权多任务最小二乘双支持向量机
2020-04-29 11:01:46黄成泉朱文文
智能计算机与应用 2020年2期
阮 丽, 黄成泉, 朱文文
(1 贵州民族大学 数据科学与信息工程学院, 贵阳 550025; 2 贵州民族大学 工程技术人才实践训练中心,贵阳 550025)
0 引 言
机器学习中,统计学习理论在解决小样本和非线性的问题上有着出色表现,其中作为典型代表的支持向量机(Support Vector Machine, SVM)[1-2]则因为所具备的优秀的性能,现已广泛地应用在各个领域中。但是,单任务支持向量机在训练样本小、信息量不足和多个数据差异的情况下的性能表现上却仍有一定欠缺。为此,在多任务学习(Mutli-task Learning)[3]的启发下,支持向量机则被成功应用到多任务学习上。研究可知,多任务支持向量机(Mutli-task Support Vector Mahicne, MTLSVM)通过共享数据之间信息来提高分类效果,解决了如上所述单任务向量机存在的问题。如今,MTLSVM已经得到了学界的普遍关注和重视。早期的MTLSVM是研究单类分类的。Yang等人[4]在2010年提出了多任务学习一类分类,为MTLSVM的研究提供了参考。He等人[5]在多任务学习一类分类的基础上提出了多任务-类支持向量机(Multi-task one-class support vector machines, MTOC-SVM),Xue等人[6]在MTOC-SVM的基础上增加新特征,提出了支持向量机的多任务学习新特征。由于求解二次规划问题计算复杂度高,时间成本大,为此Xu等人[7]提出了多任务最小二乘支持向量机(Multi-task least squares support vector machine, MTLSSVM),Li等人[8]根据近端支持向量机[9](Proximal support vector machine, PSVM)提出了多任务近端支持向量机(Multi-task proximal support vector machine, MTPSVM)。这2个模型都降低了计算成本。同样地,由于多任务双支持向量机[10](Multi-task twin support vector machine , DMTSVM)也是一个求解二次规划的问题,其复杂性和计算量都较为可观。因此,Mei等人[11]提出了多任务最小二乘双支持向量机(Multi-task least squares twin support vector machine, MTLSTSVM),能有效提高计算速度。综上研究后发现,在这些算法中,松弛约束项有较大的局限性,为此,本文在传统的MTLSVM的约束上增加一个权重约束,提出加权多任务最小二乘双支持向量机(Weight multi-task least squares twin support vector machine, WMTLSTSVM)。实验结果表明,本文算法在分类上具有良好性能。
1 理论基础
多任务最小二乘双支持向量机(MTLSTSVM)是求解一对线性方程组问题的算法,这里,给出MTLSTSVM的基本理论,MTLSTSVM为本文的算法提供了理论依据。
假设一个二分类任务,X1⊂RN1×d,X2⊂RN2×d代表类1和类-1。其中,X1,X2的每一行对应一个数据样本。X1t表示第t个任务的正类样本,X2t表示第t个任务的负类样本。正负超平面分别是:u=[W1,b1]T、v=[W2,b2]T,第t个任务的正负超平面是:[W1t,b1t]T=(u+ut)、[W2t,b2t]T=(v+vt)。ut和vt为u和v与第t个任务的偏差。MTLSTSVM的目标函数如式(1)、(2)所示:
s.t.-[[X2t,e2t](u+ut)]+ξt=e2t,ξt≥0,
(1)
s.t.[[X1t,e1t](v+vt)]+ηt=e1t,ηt≥0.
(2)
其中,e1,e2,e1t,e2t表示适当维数的列向量;ξt和ηt表示松弛向量;c1,c2,ρ,λ表示非负交换参数。
2 加权多任务最小二乘双支持向量机
2.1 线性加权多任务最小二乘双支持向量机
考虑到MTLSTSVM的松弛约束项有较大的局限性,所以,本文在MTLSTSVM的约束上增加一个权重约束,提出了加权多任务最小二乘双支持向量机。现给出加权多任务最小二乘双支持向量机算法的优化函数如式(3)、(4)所示:
s.t.-[[X2t,e2t](u+ut)]+ξt=e2t,ξt≥0,
(3)
s.t.[[X1t,e1t](v+vt)]+ηt=e1t,ηt≥0.
(4)
其中,e1,e2,e1t,e2t表示适当维数的列向量;ξt和ηt表示松弛向量;W表示权重参数;c1,c2,ρ,λ表示非负交换参数。
先给出算法求解过程,首先引入拉格朗日乘子,将约束条件代入算法。则可以得到式(3)的拉格朗日函数如式(5)所示:
(5)
计算式(5)的KKT条件:
(6)
解式(6)可得:
[X1,e1]T[X1,e1][w1,b1]T+[X2,e2]Tα=0,
(7)
令E=[X1,e1],F=[X2,e2],则有:
ETE[w1,b1]T+FTα=0,
(8)
可得:
[w1,b1]T=-(ETE)-1FTα,
(9)
同理可得:
(10)
代回式(3)的约束项可得:
(11)
令A=F(ETE)-1FT,Bt=Ft(EtTEt)-1,B=blkdiag(B1,B2,…,Bt),代回式(11), 求解式(11)中的α可以得到正超平面如式(12)所示:
(12)
根据L1的方法,可解β,算法(5)的拉格朗日函数式如(13)所示:
(13)
求解L2可以得到β,即:
(14)
这里,第t个任务的决策函数可根据式(15)得到:
(15)
2.2 非线性加权多任务最小二乘双支持向量机
对于加权多任务最小二乘双支持向量机非线性的情况,可通过内核函数来解决。核函数定义为:
M=(K(E,ZT)e),Mt=(K(Et,ZT)et),
N=(K(F,ZT)e),Nt=(K(Ft,ZT)et),
这里,K(.)为特定的一个核函数,ZT=(ET1,…,ETt,FT1,…,FTt)为全部任务的训练样本。非线性的优化函数如式(16)、(17)所示:
s.t.-[[K(Ft,ZT),e2t](u+ut)]+ξt=e2t,ξt≥0,
(16)
s.t.[[K(Et,ZT),e1t](v+vt)]+ηt=e1t,ηt≥0,
(17)
其中,ξt、ηt是松弛变量,c1、c2是非负交换参数。第t个任务的决策函数可根据式(18)得到:
(18)
3 实验结果分析
实验选取UCI数据库的3个数据集(http://www.ics.uci.edu):Monk, Autistic Spectrum Disorder Screening Data for Adult(ASD), Dermatology。最优参数来自网格搜索法的结果,实验的平均分类准确率结果是通过3次交叉验证来获取。参数c,ξ,ρ的范围为{2i|i=-3,-2,-1,…,8},权重参数范围是[0,1],这里,2个算法模型的参数视为相等的。核函数为径向基函数(RBF)。实验中数据的基本信息见表1。
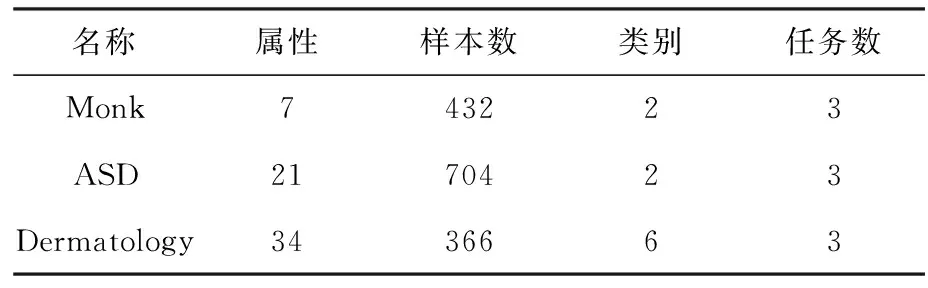
表1 数据集信息
3个数据集在3个模型上的平均分类准确率见表2。通过分析发现,本文算法WMTLSTSVM与MTLSTSVM和LSTSVM相比有更好的分类性能,这充分说明了,给松弛项增加一个权重约束,通过实验把原松弛变量约束项中的1转变为范围[0,1]中的一个常数,能有效地提高分类精度、降低训练时间,从而得到一个更好的结果。

表2 3个数据集上的平均分类准确率结果
4 结束语
本文提出的加权多任务最小二乘双支持向量机,解决了传统多任务支持向量机松弛约束项局限大的问题,引入权重参数来约束松弛变量,得到了一个更好的分类效果,通过实验分析发现,本文的算法能有效地提高分类效果,减少了训练时间,这也证明了本文算法的有效性。
猜你喜欢
加油站服务指南(2021年4期)2021-07-21 02:29:22
当代陕西(2020年17期)2020-10-28 08:18:18
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
人生十六七(2015年6期)2015-02-28 13:08:38
计算机工程(2014年6期)2014-02-28 01:26:17
