
智能图书馆云检索系统设计分析
2020-04-23 09:37林雁
卷宗 2020年6期
林雁

摘 要:当前的图书馆云检索系统存在着各种各样的问题,例如没有及时关注用户的实际需求,还有一个问题就是检索效率非常低,因此,提出了以Hadoop为支撑数据的智能图书馆云检索系统。首先集成Hive,HDFS,MapReduce和Hadoop组件,以设计智能图书馆云检索系统的硬件部分。Hive主要用于图书馆图书关键词的存储和分析。MapReduce主要用于资源的实际统计分析和计算。HDFS主要用于存储相关的操作数据, Hadoop主要用于存储设备的相关管理。通过多组实验数据对系统的性能进行了测试,与其他类似的检索系统相比,效率大大地提高。
关键词:智能图书馆;云检索系统;系统设计;数据检索;性能测试
随着时间的推移,数据量也迅速增加,服务提供商一直在创新技术,还是难以满足读者的实际需求。对于图书馆资源,怎样快速获取信息,学者已经开始从研究国内外的各种信息。本文利用数据挖掘技术开发出智能图书馆云检索系统,为及时有效地获取专业书籍资源提供了有效途径。
1 智能图书馆云检索系统
1.1 智能图书馆云检索系统架构
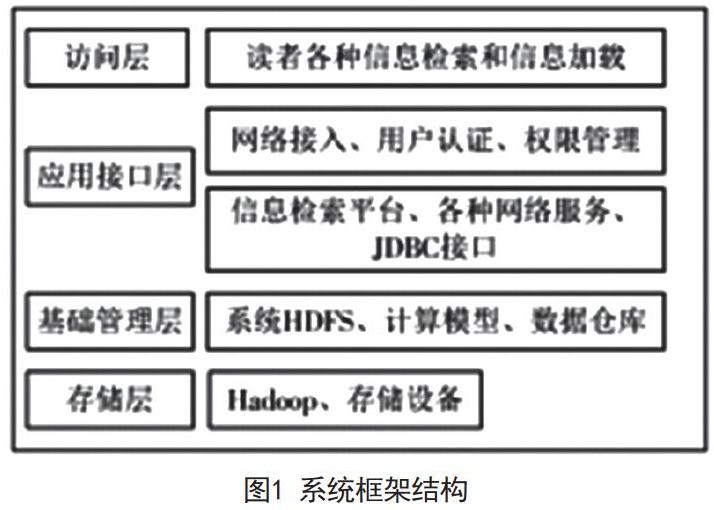
在构建智能图书馆云检索系统的过程中,有必要创建一种适用于智能图书馆信息云检索的分布式检索体系架构。根据图书馆资源检索需要,使用开源云计算平台Hadoop,基于HDFS,MapReduce和Hive的集成,建立智能图书馆云检索架构。智能图书馆云检索系统可分为四个部分:访问层,应用接口层,基本管理层和存储层。具体结构如图1所示。
1)访问层。读者可以登录应用界面,并根据各种信息检索和信息加载提供检索服务。服务器会将新输入的图书实时更新到系统的会员卡信息中。2)应用接口层。它可以根据具体的业务类型提供图书馆资源检索平台3)基本管理层。它是智能图书馆云检索系统云存储的最关键组成部分。数据基础管理层使用HDFS,MapReduce,Hive等技术实现系统相关设备之间的联合工作,并向系统外部提供统一的检索服务。4)存储层。它是系统组成的核心部分,具有重要的功能,所有的存储设备都由系统统一管理。使用开源云计算平台Hadoop来实现云存储设备的虚拟化管理,以及存储设备的故障状态诊断等。
1.2 系统特定组件的分析
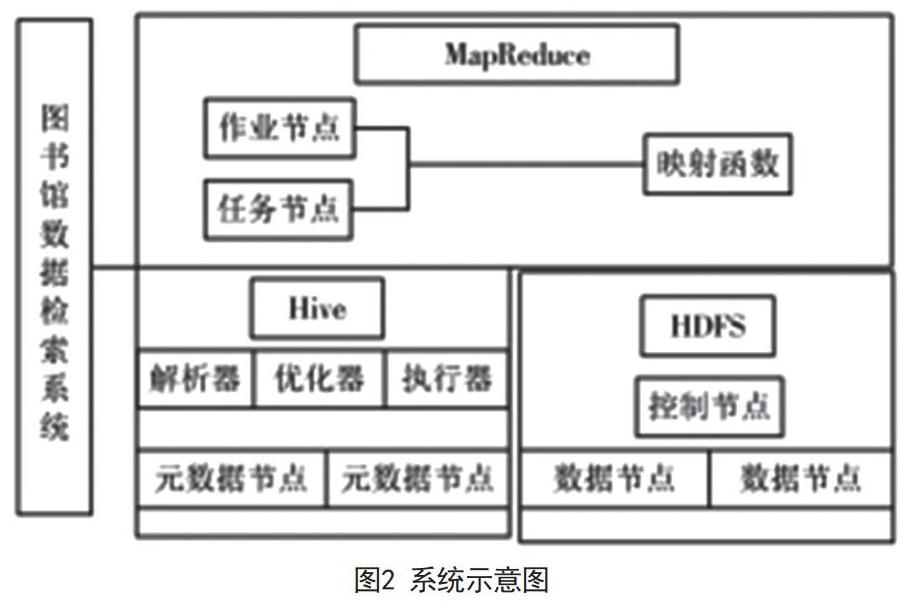
Hive主要用于图书馆图书资源关键词的存储和分析; MapReduce主要用于图书馆图书资源的实际统计分析和计算; HDFS主要用于存储相关操作数据;开源云计算平台Hadoop主要用于与存储设备有关的具体管理图如图2所示。本文设计的智能图书馆云检索系统的HDFS架构如图3所示。1)管理器HDFS体系结构中的控制节点是控制节点,可用于管理名称空间,集中分配以及复制图书馆书文件的存储模块。控制节点将图书馆书文件的元数据存储到存储器中,并且书文件的元数据在数据节点中包含书文件信息和数据节点的信息。2)数据节点是库资源存储的基本组成部分。他们可以以块状形式在本地存储书籍资源,为书籍资源存储元数据,并在给定的周期内将所有现有的图书馆资源块信息传输到控制节点。3)客户主要负责获取HDFS中的图书文件。
智能图书馆云检索系统中的MapReduce架构如图4所示。MapReduce架构中的作业节点专注于调度作业的运行,架构中的作业节点和任务节点可以相互转换,执行任务时,它可以分为多个切片。任务节点反映切片数据和映射任务等等。客户端将图书馆信息检索查询的计算任务提交给MapReduce。HDFS可以提供库信息存储功能,主要用于为所有操作节点提供所需的资源。
Hive架构在智能图书馆云检索系统中的具体功能描述如下:1)Hive架构中的解析器主要负责分析和查询有关的信息,并对不同的资源进行语义查询,并根据存储节点中的元素制定相应的计划。2)图书库信息元数据存储节点存储层中所有表和分区的信息都能在云检索系统的HDFS中获取数据。3)执行者负责执行计划,执行引擎在系统组件上执行上述计划。4)节点是接受信息查询的组件。
3 实验结果与分析
模拟实验数据使用多个随机生成的数据。测试环境为WindowsServer2012R2Intel2XeonTMCPUE5?2650@2.30GHz2.30GHz,具有32.0GB的RAM,该环境由Matlab2014a编程实现。为了验证智能图书馆云检索系统的效率,多组实验数据量为GB量级,时间单位为ms。为了准确表示系统检索结果,对时间按照10为底取对数,如图5所示。
从图5可以表明,使用本文的检索系统具有更高的数据检索效率。直接查询图书馆资源时,检索时间将随着数据量的增加而增加,并且总体呈现呈线性趋势。表1显示了500GB库数据的检索时间汇总结果。从表1可以看出,随着图书馆检索范围的扩大,相应的数据检索时间将逐渐增加,主要原因是当图书馆资源检索空间增大时,满足查询条件的图书馆资源数据块也会增加。
当智能图书库云检索系统节点数量减少时,对大小为500GB的图书库资源进行检索的时间统计结果如表2所示。
从表2可以看出,当节点数量增加时,相应的检索时间将随之减少,它们之间呈反比的关系。可以推断,当节点数持续增加时,检索时间大大缩短,数据检索效率得到显着提高。
4 结论
现如今,智能图书馆资源管理方法已逐漸成为热门,相对于一些大数据的快速查询,本文提出了一种基于海量图书库资源的数据挖掘算法,并将其应用于分布式开源框架Hadoop。通过对多组的实验分析并验证了该系统有一定的效果。
参考文献
[1]陈春阳.基于图书馆微信平台的馆配云平台图书数据推送研究[J].出版发行研究,2018(5):44.
[2]鲍玉来,白淑霞,飞龙,等.汉蒙跨语言检索系统设计与实现[J].情报理论与实践,2017,40(4):128-132.
[3]刘爱琴,李永清.基于SOM神经网络的高校图书馆个性化推荐服务系统构建[J].图书馆论坛,2018,38(4):95-102.
猜你喜欢
中国交通信息化(2022年4期)2022-06-17
装备学院学报(2017年3期)2017-07-21
装备学院学报(2017年2期)2017-06-05
计算机工程(2015年8期)2015-07-03
