
美国自然语言处理技术专利情报分析及启示
——基于1999—2018年专利数据
2020-04-21 06:03:14刘媛
科技管理研究 2020年6期
刘 媛
(重庆大学法学院,重庆 400044)
自然语言是人类语言集团在一定条件下自然形成和使用的口头和书面语言,表现为一些自然形成的语词指号体系,是语词指号和语词意义的统一体[1]。自然语言处理(natural language processing,NLP)技术就是机器理解和运用人类语言的能力[2],它是一门融合了语言学、计算机科学、数学的科学。1949年,美国科学家Weaver[3]写就了《翻译备忘录》(Translation Memorandum),标志着现代机器翻译概念的正式形成。当前,全球正处在人工智能(AI)第三次浪潮之中,自然语言处理作为人工智能的核心技术之一,帮助我们实现人与机器快速准确的信息传递,为人工智能与其他产业的深度融合提供了重要支撑。它广泛应用于无人驾驶、智能家居、机器翻译等领域,是风险投资和科学研究的热门领域,具有极高的产业价值。美国是在自然语言处理领域拥有巨大优势的技术强国,在中美贸易摩擦的背景下,对美国相关专利数据进行分析,可以全面了解该国在此领域的专利竞争态势,为中国制定产业和技术发展战略、企业研发决策提供参考。
1 材料与方法
1.1 材料来源
当前,国内外对于中美人工智能技术实力的判断大相径庭。清华大学的研究报告提出中国超过美国,成为人工智能领域技术起源第一大国,专利技术布局程度位居榜首[4];《乌镇指数:全球人工智能发展报告2017》中提到,在自然语言处理技术专利申请数量方面,中国自2004年起就超越美国,随后逐年拉开距离[5];而牛津大学的学者则认为,中国目前的人工智能实力实际仅约为美国的一半[6];韩国学者甚至声称,尽管近来有很多论文紧张地指出中国大陆在AI领域的力量,但认为中国大陆依然是相对不重要的AI技术来源地区,中国台湾比中国大陆拥有更多的AI专利[7]。而之所以会得出不同结论,关键原因在于研究者们采用了不同的检索和分析方式。现有专利分析文献大多数没有公开检索式,这导致同行无法对数据进行监督和查证,研究成为自说自话。
考虑到自然语言处理技术涉及到《国际专利分类表》(International Patent Classification,IPC)中的多个类别,同时,为了最大范围地进行精确检索,参考现有文献,本文检索条件采用关键词检索,关键词位于标题和摘要中,检索式为:(((((languag* OR linguist* OR sentenc*) AND ((sentenc* OR lexic*) OR(analy* OR semantic*)))) OR (((languag* OR linguist*OR sentenc*) AND ((dialog* OR talk OR conversation)OR (model* OR manage* OR recoding* OR history*OR DB OR (Data and base)))) OR (((voice* OR speech*OR acoustic* OR sound* OR audio* OR phonetic*) and(((natural* AND language*)) OR (inference* OR detect*OR recogni* OR cogniti* OR interface OR capture*))))OR (((voice* OR speech* OR dialogu* OR conversat*OR speaking* OR language*) OR (combine OR unite OR join OR synthe*)) AND corpus*)) OR (((languag* OR linguist* OR sentenc*) and (morpheme* OR morpholog*)AND (process* OR analy* OR parsing* OR analy* OR assay)))))[7];专利类型限定为发明,发明专利授权日的时间限定在1999年1月1日至2018年12月31日,检索时间为2019年1月8日。为避免重复统计,对具有同一优先权文件的专利进行简单同族合并。因为美国专利申请自申请日起18个月自动公布,或者根据申请人要求在18个月以内公布,还有一些特殊情况不公布,所以近18个月的专利数据不能完全呈现客观情况,仅供参考。
1.2 分析方法
本文通过IncoPat专利数据库进行检索,获得1999—2018年美国自然语言处理领域(以下简称样本)专利数据,运用图表软件对数据进行统计和可视化处理,采用文字与图表结合的方式,从专利申请和授权趋势、专利技术、专利相关主体、诉讼及运营等4个方面进行专利情报剖析。
2 结果与分析
2.1 美国自然语言处理领域专利趋势分析
(1)专利申请趋势。因美国公开专利申请文献是从2001年3月15开始,此前仅公开授权专利,所以这里分析申请趋势只能以2001年起算。2001—2018年,样本专利申请有46 958件,简单同族后有45 682件,由图1可知,整体而言,美国自然语言处理领域专利申请量呈波浪式上升状态。21世纪初,人工智能仍处在第二次浪潮结束后的寒冬[8],但随着互联网爆炸性的普及,软硬件条件和海量数据开始对人工智能,包括自然语言处理技术带来利好;2001—2006年,专利申请稳步增长,但自2007年起又开始疲软无力,逐年下降,2010年跌至2 235件,直到2012年才恢复到与2006年基本持平的数量,究其原因,主要是受到2008年金融危机影响,市场震荡、资本寒冬,恶劣的内外部环境迫使科技公司纷纷倒闭,同时美国政府削减公共科研资金,企业缩减研发经费,直接导致了专利申请数量的下挫;此后,经济逐渐复苏,2012—2016年,美国在自然语言处理领域的融资规模已经遥遥领先,占全球NLP领域总融资的50%到80%,每年新增的自然语言处理企业占当年全球NLP领域新增企业的40%左右[5],2013年与新一轮人工智能爆炸几乎同步,自然语言处理领域的专利申请量一跃而上,以极快的速度跃过3 000件大关,此后一直稳定地保持在高位水平,逐渐进入技术成熟期。
(2)专利授权趋势。1999—2018年,样本专利总授权数量是37 370件,简单同族后是36 316件。其中,1999—2011年这13年间,专利授权量保持在1 000~2 000件范围内;随着人工智能第三次浪潮来临,2012—2016年的专利授权量跃上2 000件,增势迅猛;此后,仅用了5年时间,于2017年进入“3 000+”时代。

图1 1999—2018年样本专利申请与授权数量
2.2 美国自然语言处理领域专利技术分析
(1)10个主要技术方向。以IPC中的小类代码为技术方向,表1展示了样本发明专利主要集中的10个小类。其中,G06F(电数字数据处理)和G10L(语音分析识别)分居专利授权量的冠亚军,二者占到样本专利总数的61.6%,是创新热度最高、发展速度最快的领域;处在第二梯队的是H04M(电话通信)、H04L(数字信息的传输)、H04N(图像通信)、H04R(声-机电传感器)、H04B(传输)5个小类,授权专利数量从5 000至2 000件不等;第三梯队是H04W(无线通信网络)、G06Q(特殊目的的数据处理系统或方法)、G08B(信号装置或呼叫装置)、G06K(数据识别),授权专利数量为1 000余件。

表1 1999—2018年样本10个主要技术方向专利授权量
(2)10个技术方向专利授权趋势。1999—2018年,G06F类和G10L类是样本专利授权增速最快的两个技术方向,近6年尤为明显,一路遥遥领先;此外,H04R以传感器为代表的硬件类表现也很抢眼,20年来增长了约15.7倍,应该是自然语言处理领域下一个技术爆炸点。H04L和H04N有着相似的趋势,样本专利授权量分别增长了3.7倍和3.3倍。H04M虽然起步早,但多年来维持在200~400件左右的授权量,2018年被H04L赶超。H04B与H04M雷同,两者数据表现均疲软无力,属于发展早、后劲弱,亟待技术革新的方向。后3位H04W、G06、QG08B的样本专利授权量分别增长了5.6倍、8.2倍和2.6倍,由于它们的基数本来偏少,尚需要进一步的积累。见表2所示。

表2 1999—2018年样本10个主要技术方向的专利授权量 单位:件
(3)被引频次最高的前10件专利。被引频次,指的是某个专利文献在首次公开之后被后续专利文献引用的总次数[9]。专利的被引频次能够反映技术重要程度,是判断一件专利在本领域是否具有基础和核心地位的关键指标。表3列出了在样本专利中被引频次最高的前10件专利,它们的申请日都很早,除排名第一的以外,其他皆是在20世纪末提出的申请;较早的申请时间也导致其中8件专利保护期已届满,只有排名前两名的专利尚处在有效期,第10名的专利因2011年没有按时交纳年费而失效。值得关注的是,“申请人”一栏中的Hoffberg,其本人身兼发明家和专利律师两种角色,在专利运营中非常活跃;在“当前专利权人”一栏中,微软技术许可公司也很醒目,微软公司在NLP领域的专利运营水平不容小觑。

表3 1999—2018年样本高被引频次专利(前10名)
2.3 美国自然语言处理领域专利相关主体分析
对专利各类相关主体进行分析,有助于我们辨别自然语言处理领域的主导者,进一步了解各大创新主体的专利竞争实力、持续发展能力及其技术布局战略。
(1)申请人(已获权)国别分布。样本专利中,在美国提出发明专利申请并获得授权的主体中,为美国籍的多达24 501件专利,占总数的67.47%,本土创新实力很强;其次,日本籍主体占12.48%,成为在美国进行专利布局最多的外国国家,韩国籍主体占3.60%,中国籍主体共1 104件专利(含中国台湾653件),占3.04%,可见,亚洲国家抢占美国市场的竞争非常激烈;德国作为老牌技术强国,占2.27%,名列第五,也是欧洲诸国的排头兵;其后是加拿大(2.16%)、英国(1.27%)、法国(1.16%)、荷兰(0.88%)、瑞典(0.80%)。
(2)主要专利申请人授权趋势。据表4显示,IBM不仅很早就在自然语言处理领域进行专利布局,持续投入铸造强大技术实力,近3年来授权量迅猛,2018年甚至获得218件授权专利。至于微软,虽然从2015年起专利授权量开始大跌,2018年“交白卷”,但这并不意味着它从该领域退出,相反,微软自推出智能助理Cortana(微软小娜)起,必然需要大量的专利作为支撑,事实上,排名第九的微软技术许可公司承担了大部分专利任务,把母公司的专利业务分担出去;谷歌也在做类似安排。三星和索尼两家日本公司比较稳健。纽昂斯(Nuance)作为目前全球最大的语音识别科技公司,是苹果语音助手Siri的技术提供商,从2010年起其样本专利授权量开始攀升。创建于1877年的AT&T,是美国老牌固网电话服务供应商及第二大的移动电话服务供应商,但直到2008年才实现专利零突破。亚马逊表现出后发制人之势,2018年专利授权量仅次于IBM,其在2014年推出的智能音箱Echo的市场占有率排名第1名,专利是它攻城略地的必备武器。

表4 1999—2018年样本主要专利申请人授权趋势(前10名) 单位:件
(3)标准化专利申请人(已获权)与标准化当前专利权人。从上文的分析可知,科技公司常常因市场布局、风险分散,分流母子公司业务等因素,以旗下某个/些公司的名义进行专利申请,因此,对们进行标准化处理,把母子公司的数据进行整合,才能看到其全面而真实的技术实力。从表5可知,经过标准化后,索尼和三星的排名调换了,AT&T跌出前10名,日本电气跻身第9名。另一方面,最初的专利权人可能会对手中的专利进行转让,那些渴望快速获得技术的公司也会通过购买、加入专利池、并购等方式积极储备专利,因此,通过对当前专利权人进行标准化分析,我们发现,纽昂斯持有的专利最多,成为行业领军者;英特尔、高通、富士通3个科技巨头通过多种方式获得了可观的专利,均有一定优势。

表5 1999—2018样本标准化专利申请人(已获权)与标准化当前专利权人(前10名)

表5 (续)
(4)发明人及其技术方向。主要发明人的数据展示了该领域的核心技术人才及其擅长方向。从专利授权量的分布看(见图2),Bangalore作为AT&T实验室的首席技术官,在自然语言处理领域很有建树,论文的被引率也非常高,其发明专利集中在G06F和G10L两类。Acero在G10L小类上特别突出,与Bangalore在G10L的专利数量不相上下,他的技术成果绝大多数由微软持有。Rhoads参与发明的专利在五大类别都有可观的分布,这在发明人中较为少见,他是Tektronix(泰克)公司的首席科学家,该公司是测试、测量和监测领域的全球领导企业,因他曾供职于美国知名的音频、视频、图片识别公司Digimarc,所以当前数据显示其近60%发明成果由Digimarc享有。其他7位发明人都以G10L类见长,需要注意的是Rahim、Tur、Gilbert、Riccardi 这4位发明人都有AT&T背景;此外,Sharifi来自谷歌。唯一上榜的中国发明人Li Deng来自微软,Moore V S来自IBM。总体来看,科技公司是技术人才极为重要的成长土壤,其中,AT&T成为自然语言处理领域的“黄埔军校”,培养了很多优秀的人才。
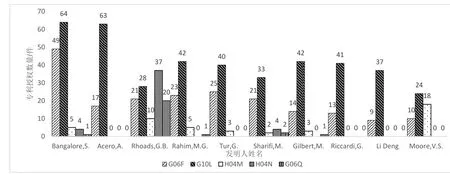
图2 1999—2018年样本主要发明人及在5个技术方向的专利授权量
2.4 美国自然语言处理领域专利运营及诉讼分析
(1)授权专利转让情况。从样本已获得授权的专利转让趋势,我们可以看到NLP领域在不同时间段的技术转化、应用、推广与合作的情况。图3显示出在1999—2013年,专利转让数量呈小幅攀升,技术运营和实施的热度正在酝酿;2014年,专利转让突然跃升到5 745件,究其主要原因,是因为当年美国科技行业并购异常频繁,而并购中一般会将专利打包转让,其中大事件包括微软收购诺基亚手机业务及其专利组合、谷歌收购摩托罗拉移动后转手出售给了联想、苹果收购了20家规模不同的科技公司等等,经过此次行业“洗牌”,专利进一步集中到科技巨头手中,转让需求开始减少;2015年之后专利转让数量回落也印证了以上结论。

图3 1999—2018年样本授权专利转让趋势
(2)主要转让/受让人及其转让/受让专利数量。转让/受让人数据可以表明,哪些主体在具体实施专利运营,以及技术输出/入活跃度。图4(a)4(b)显示,微软转让的专利数量最多;AT&T股份公司及其资产公司、知识产权公司占据4席,颇有“狡兔三窟”之意;安华高科技(Avago Technologies)多年来不断在电子通信行业扩展和收购,转让专利也很频繁。在受让专利方面,IBM成为最大买家;微软旗下的技术许可公司位居第二;纽昂斯本身的研发实力和原有专利储备不足,因此它主要是收购专利;索尼和三星为了在美国市场站稳脚跟,也买入了很多的专利来保驾护航。此外,转让人和买受人中还出现美国四大银行中的3个,即美国银行(Bank of America)、花旗银行(CitiBank)、摩根大通银行(JPMorgan Chase Bank)。除了自有的专利外,银行作为债权人或经纪人,在破产、质押等过程中会涉及到大量专利的转让和受让,这也从侧面反映了美国科技与金融两大行业关系密切。
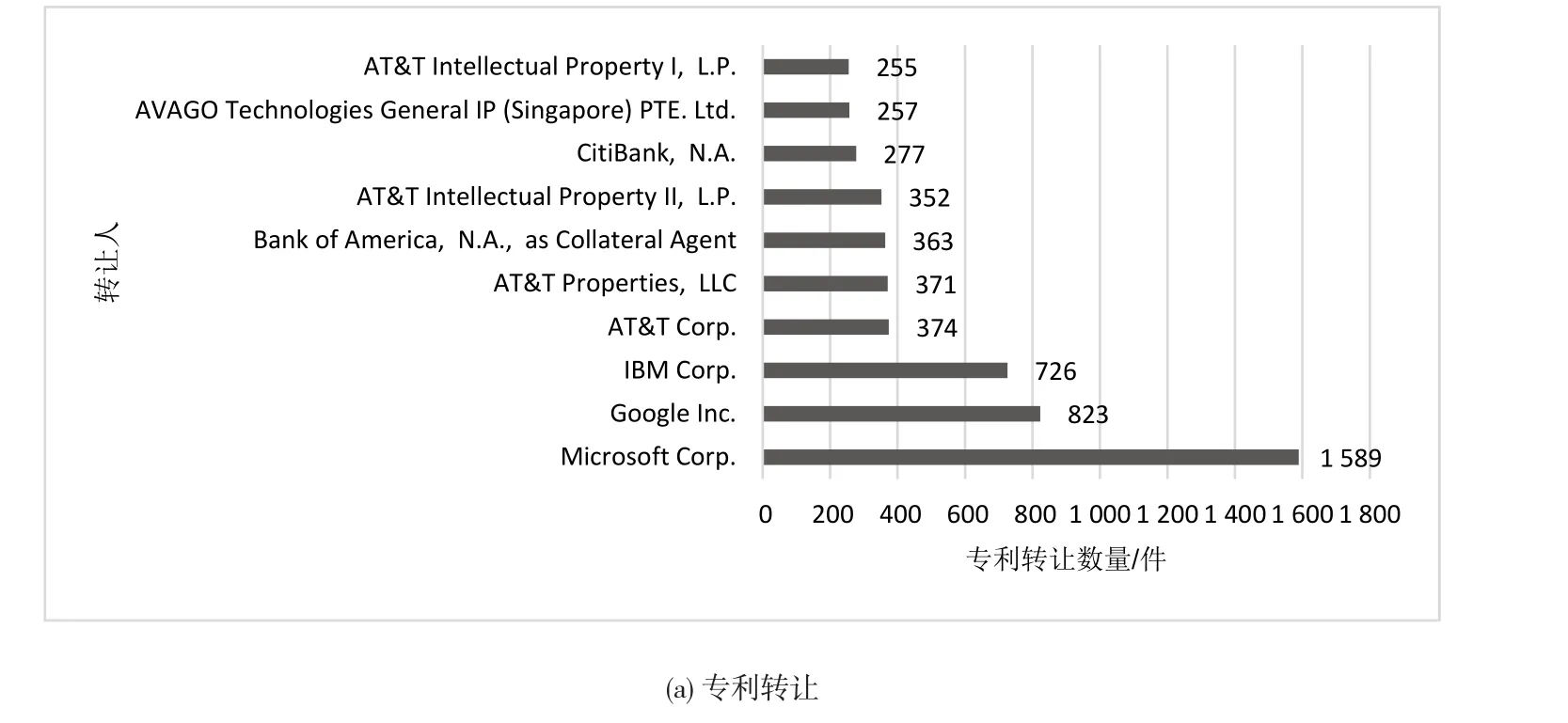

图4 1999—2018年样本专利转让/受让人情况(前10名)
(3)涉诉专利数量。普华永道的报告显示,近5年来,美国总体专利诉讼案件数量持续走低,与授权量走高形成截然相反的趋势[10]。在这样的大背景下,加上2014年的行业“洗牌”,美国自然语言处理领域诉讼案件涉及的授权专利数量以该年为转折点,结束了2000年以来的高增长,近5年大幅下跌(见图5),再一次反映了主要竞争者逐步变为少数科技巨头的行业现状。

图5 1999—2018年样本涉诉授权专利数量
(4)主要诉讼当事人。实践中,一件专利前后涉及十余个诉讼案件较为常见,母、子公司同时成为诉讼当事人或第三方也经常发生。为避免重复统计多个案件和母子公司,通过对诉讼当事人进行标准化处理,以涉案专利数量为指标,本文得到了表6所示数据。涉及的案件类型除常见的在美国进行的司法案件,还包括美国专利商标局专利审查和上诉委员会(PTAB)审理了复审案件。诉讼当事人包括了原被告、反诉原被告、第三方、复审请求人。涉案专利不限于自己持有的专利,还包括侵犯他人的专利。数据显示,苹果成为涉及专利数量最多的诉讼当事人,其后是微软、谷歌、三星等行业巨头。
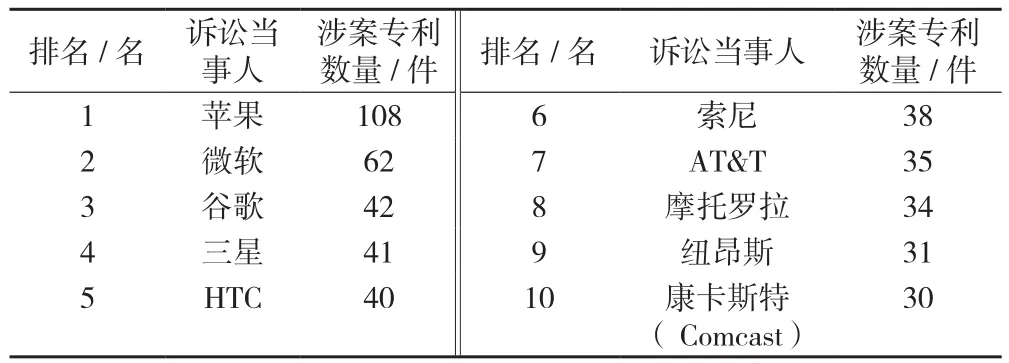
表6 1999—2018年样本诉讼当事人及涉案专利数量
3 结论
通过对1999—2018年美国自然语言处理领域专利数据的分析,本文可以得到以下结论:
(1)在竞争环境方面,自然语言处理技术的机遇伴随着人工智能第三次浪潮而到来,2014年之后,逐渐进入技术成熟期[11]。美国的专利申请量和授权量都增长迅速,其中,G06F和G10L是最重要的技术热点,侧重软件领域,H04R所代表的硬件领域也极有爆发潜力,从“软”到“硬”说明自然语言处理技术商业化落地速度加快。美国在NLP领域起步早、发展快,在全球技术竞争中占据了绝对的领先地位,其本土市场拥有多家标杆性的科技企业、成熟的科技与金融联动机制以及较好的科研基础和人才队伍。此外,日、韩两国的实力也非同一般。
(2)在创新和竞争主体方面,科技企业成为最主要的主体,它们的技术研发针对性和目的性强,创新意愿强,发明成果应用程度高,尤其是美、日、韩的代表性企业,不管是传统巨头还是后起之秀,多年的经营使它们具备扎实的技术基础,拥有推动自然语言处理技术迭代和升级的实力。同时,随着行业“洗牌”和竞争加剧,各大企业成立多个子公司以应对专利诉讼、许可、买卖等事项,保护企业的核心业务不受侵扰,专利技术和人才也逐渐集中到少数企业手中,形成了较为明显的马太效应。
4 启示
《中国制造2025》把人工智能列为智能制造核心信息设备的关键技术,中国《国家中长期科学和技术发展规划纲要(2006—2020年)》也把中文信息处理列为前沿技术之一,不管是国家层面的战略规划,还是产业发展的现实需要,自然语言处理技术已然是中国人工智能产业发展的重要一环。当前,中国与美、日、韩在NLP领域的差距较大,建议从以下方面进行改进:
第一,培育以企业为主导的创新格局。现今,美国在自然语言处理领域已拥有涵盖基础层、技术层和应用层的完整产业链,市场与企业的规模和成熟度都远超中国。有数据显示,美国在NLP领域的创业公司有252家,中国仅有92家[12]。与美国不同,专利数据和论文发表数量表明[11,13],中国在NLP领域的主要创新主体并不是科技企业,而是高校和科研机构,而他们并不是市场主体,只有让处在竞争中的企业成为创新的主导者,才能缔造出充满活力的市场和产业。2017年,中国采取扶持巨头企业做大技术平台以带动全行业发展的策略,科技部设立百度、阿里巴巴、腾讯和科大讯飞为首批国家新一代人工智能开放创新平台,初步显现出积极影响。然而,创新格局的培育是一个庞大工程,还需要系统的人才梯队、成熟的市场机制、完善的法律制度、良好的营商环境,以及保护创新的社会共识等众多板块的协调发展。
第二,加快科研成果转化。世界知识产权组织的报告指出,全球人工智能专利申请前20名学术机构中有17家来自中国,人工智能相关科学出版物数量前20名学术机构中有10家来自中国,10年里中国论文数量增加了150%[14]。可见,中国的人工智能具有不错的学术研究基础。但另一方面,中国人工智能论文的引用率却被美国远远甩在后面,低于世界平均水平[13],论文质量还有待提高。高校和科研机构利用公共资金产生的技术成果,转化率并不理想,造成了很大的浪费。这一问题不仅存在于自然语言处理领域,在其他技术领域也较为常见[15]。为了鼓励科技成果转化,中国已采取的措施有修订《促进科技成果转化法》、建设高校科技成果交易网站、设立高校科技成果转化和技术转移基地等等,这些以行政手段为主的措施起到了一定效果,但转化的动力根本来源于市场。因此,需要优化科研成果的知识产权和利益分配机制,激励科研人员的主动性;加大引入专利市场运营主体、中介机构,扩宽供需信息渠道;条件成熟的高校成立专门的知识产权运营公司,避免校内行政人员低效率管理。
第三,加强在美国的专利布局。虽然百度、中国科学院、浙江大学等在国内的自然语言处理专利申请数量非常突出,但他们的美国专利却寥寥无几;而中国企业在美国布局该领域专利的以华为技术有限公司、鸿海集团、台湾工研院、深圳市腾讯计算机系统有限公司、中兴通讯股份有限公司为主,其美国专利数量依旧很少,与日韩企业相差甚远。在技术竞争全球化的今天,不能无视作为科技行业必争之地的美国市场,我们应当加快在美国的NLP领域专利布局,尤其是重点技术方向,运用灵活的专利运营策略,以在激烈的竞争中赢得主动权。
第四,注重专业人才培养。中国在自然语言处理领域的高校专业体量偏小,专业人才储备不足,员工人数仅为美国的1/3[12]。基础层面人才薄弱、顶尖领军人才欠缺,无法持续为产业输出有生技术力量,制约了中国NLP产业的长期发展。因此,我们亟需夯实相关专业课程建设,完善在职人员技能培训体系,搭建人才成长平台,把培养自然语言处理专业人才作为一项长期工作坚持下去。
致谢:感谢重庆大学法学院2018级知识产权法研究生郭芳制作本文部分图表。
猜你喜欢
水运工程(2022年7期)2022-07-29 08:37:38
传感器世界(2019年4期)2019-06-26 09:58:44
河南科技(2018年3期)2018-09-10 07:35:32
河南科技(2017年4期)2017-06-06 11:59:01
河南科技(2016年8期)2016-09-03 08:08:22
发明与创新(2016年5期)2016-08-21 13:42:50
河南科技(2016年6期)2016-08-13 08:18:27
河南科技(2016年4期)2016-07-25 08:46:00
化学分析计量(2013年1期)2013-03-11 16:37:15
发明与创新(2013年1期)2013-03-11 15:53:28
