
高通量众核处理器设计
2020-04-18 08:53:42叶笑春李文明张洋张浩王达范东睿
数据与计算发展前沿 2020年1期
叶笑春,李文明,张洋,张浩,王达,范东睿,2
1.中国科学院计算技术研究所,计算机体系结构国家重点实验室,北京 100190
2.中国科学院大学,北京 100049
引言
随着云计算、物联网以及人工智能等技术的迅猛发展,大型数据中心的并发请求数量迅速发展到亿级以上。经统计,百度日处理的搜索量已经超过100亿次,平均每秒11万次以上;淘宝的后台数据库在2019年双十一的峰值访问速度约为7万次每秒,全天合计为56亿次读请求;Facebook 每天有14.9亿活跃用户,每天上传超过1亿张图片。根据国际数据公司(IDC)2019年发布的白皮书《2025年中国将拥有全球最大的数据圈》,全球数据圈将从2018年的33ZB 增至2025年的175ZB,我们的世界将会在2025年被数据所“淹没”[1]。为了应对如此大规模的海量数据,据预测,到2020年将新增互联网数据中心机柜18.54万台,较2016年的5.82万台的保有量增加接近319%[2]。更甚的是,诸如微博、团购、“秒杀”等网络应用的出现,给大规模数据的实时处理及QoS(服务质量)提出了更高的要求。因此,互联网技术的普及应用带来的种种新特性给当前的高性能处理器芯片和计算机系统带来了巨大的挑战。
这种由网络发展带来的新型应用,已经成为数据中心的主要负载,其特征也从传统的浮点计算为主变成处理大量高并发的用户服务请求以及海量数据分析,强调任务的高并发、用户服务请求的强实时以及数据的高吞吐处理能力。这类应用的目标已不再是传统的评价超级计算机性能的LINPACK 速度[3],而是高通量,即提高单位时间内处理的并发任务的数量。这种由互联网发展带来的新型应用负载,我们称之为“高通量应用”。高通量应用和传统的高性能应用存在本质上的区别,表1对高通量应用负载特性和高性能负载特性进行了对比。从表中可以看出,面向网络服务的新型高通量应用在很多方面和面向科学计算的高性能应用存在着不同之处。传统高性能计算主要针对科学计算应用,程序往往具有较好的局部性,属于计算密集型应用,其所追求的目标是追求高速度。而高通量应用面向的是新型网络服务,任务并发度大且对实时性有较高要求,其数据量大且程序局部性较差,属于请求密集型应用。这类应用追求的目标是高通量,即提高单位时间内处理的并发任务数目[4-7]。由于高性能计算由来已久,目前的主流通用计算机和高端计算系统的发展都深受其影响,这也使得当前主流处理器体系结构在针对网络服务这种高并发、高实时、低延迟的高通量应用时表现出诸多不足,已有的诸多研究成果也表明高通量应用与传统处理器架构的不适应性[8-17]。
针对数据中心面临的挑战,设计实现高能效大规模众核处理器结构是应对高通量应用的有效手段,也已经成为国内外学术界和产业界的研究热点。比较有代表性的研究成果包括,P.Lotfi-Kamran 等人提出了Scale-out Processor 设计理念,以性能密度(performance-density)为衡量标准提出了共享LLC众核Pod 单元,并利用多个Pods 搭建整个Scale-Out Processor,通过寻求单位芯片面积上的最优计算性能,尽可能提高单芯片上的数据吞吐能力[10]。同时还提出了提高片上LLC 访存效率的NOC-Out众核拓扑结构,通过将LLC 中心化并设置专用访问数据通路,提高数据访问效率[11]。Hardavellas 等人从数据中心处理器能效比的角度出发,通过采用异构专用众核以及动态控制异构逻辑单元电压,来提高处理器芯片的高性能和高能效比,使其更加适用于数据中心应用场景[12]。Jongse 等人提出了面向机器学习的Scale-Out 处理器,将处理的通用性、数据通量及能效等进行了综合考量设计[13]。Akshitha等人通过分析数据中心典型微服务算法特征,为面向数据中心高通量众核处理器提供了设计思路[14]。Artemiy 等人分析和权衡了在多种并存的数据中心应用下处理器在面向QoS和处理通量之间的关系和设计思路[15]。国内也有许多面向数据中心的众核处理器结果设计,例如,申威处理器(SW26010)以及飞腾处理器(FT2000)等,都在数据中心得到广泛的应用,取得了优异的成绩。当然,还存在其他众多针对数据中心应用的体系结构研究成果,均取得了较好的性能及能效比提升。虽然在面向数据中心应用的众核体系结构设计中已经出现诸多的研究成果,取得了较好的效果。但是,随着高通量应用的数据量、并发请求数量以及对实时性的需求的急速增加,需要更为有效的高通量众核处理器结构优化设计,提高处理器在数据处理端、数据传输端以及数据存储端的吞吐能力、并发处理能力以及实时响应能力。
目前传统计算机系统的设计并不能很好地满足高通量应用的新特性,主要体现在以下几个方面。
(1)数据格式与处理器数据结构不匹配
在高通量应用中相当一部分的访存粒度小于8 Bytes。如图1所示,对于K-Means 来说,近90%的访存粒度为4Bytes,而对于Grep 来说,1Byte的访存粒度近90%。相比而言,在传统高性能计算测试程序集SPLASH-2[18]应用中,8 Bytes 访存粒度占绝大部分。可见对于高通量应用来说,访存粒度明显小于传统应用。这种细粒度的数据请求与传统高宽度的数据通路不匹配,造成硬件资源的利用率下降。

表1 高通量计算与传统高性能计算的对比Table1 Comparison of HTC and HPC
(2)数据流动与处理器数据通路不匹配
典型的高通量应用其数据重用性低,数据处理通常以一系列处理阶段分步骤完成,而通用处理器以L1、L2、L3 分级缓存集中处理的方式明显与数据流动加工的天然过程不匹配。实验选用WordCount,TeraSort,Search 三个典型的基于MapReduce的高通量应用作为基准测试程序。实验硬件平台选用Intel Xeon E5645 多核处理器对上述高通量应用的访存行为进行相关测试。

图1 高通量应用(左)及传统SPLASH-2应用(右)访存粒度分布示意图Fig.1 Distribution of memory access granularity in HTC applications (left) and conventional applications (right)
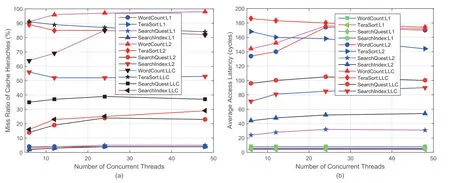
图2 传统多核处理器Cache 结构在典型高通量测试程序下的性能统计。(a)展示了各级cache 在不同用例下的失效率随线程数增加变化情况;(b)展示了各级cache 在不同用例下的平均访问延迟随并发线程数的变化情况。Fig.2 Cache performance in traditional multi-core processor under WordCount,TeraSort and Search Quest applications.(a)shows the miss ratio of cache hierarches with different number of concurrent threads under different applications; (b)shows average access latency of cache heartaches with different number of concurrent threads under different applications.
由实验结果图2可知,对于一级Cache 来说,具有非常好的命中率。对于二级Cache 来说,由于数据的局部性(数据空间局部性为流式局部性,数据按地址顺序使用一次即被抛弃)被一级Cache所消耗,因此导致二级Cache的命中率很低,而LLC的相联度大并且容量也大,反而比L2 有更多命中,但是绝对命中率也并不理想。实验结果体现出传统多级Cache 在高通量应用场景下的不适应性。
(3)数据实时处理需求与处理器结构预测性不匹配
大量互联网应用场景对云端数据处理有实时性需求,网络游戏与网络安全中也有实时编码解码需求,而目前处理器大量采用的复杂调度方法,如乱序执行、复杂流水线设计等,都使得整体结构的最坏执行时间(WCET)不可预测。在面对不断发展的新型应用的需求下,当前主流计算机系统的数据处理能力和并发服务能力已难以满足大规模数据中心需求。为了确保服务质量,当前数据中心很多关键部件的利用率都处在较低的水平,例如,对微软的Bing 搜索、Hotmail和并行数据分析引擎Cosmos 服务器的运行情况分析,发现在处理器有67~97%使用率的压力测试中,内存带宽的使用率只有2~6%[17]。谷歌数据中心也有类似情况,据统计,2013年,谷歌在线应用数据中心的平均CPU利用率只有30%左右[20],而更多的其它企业甚至还更低[21]。
综上所述,传统的高性能计算机已难以高效处理互联网时代新产生的高通量应用,亟需设计一套针对高通量应用的新型体系结构来面对互联网时代的挑战。
1 高通量计算
1.1 什么是高通量计算
高通量计算是适用于互联网新兴应用负载特征,在强时间约束下处理高吞吐量请求的一种新型高性能计算。传统的高性能计算主要是“算得快”,旨在更快地解决更大的问题,典型负载是诸如LINPACK、FFT 之类的科学计算应用。而高通量计算则是“算得多”,即并发处理的数据多、请求多,典型负载如无线通信控制系统、互联网服务等。对于此问题,我们可以用赛车项目中的“正计时”和“倒计时”两个概念来形象地说明高性能和高通量之间的区别。高性能计算是指在“正计时”的时间内“更快”地完成某个任务负载。而高通量计算是指在“倒计时”的时间内尽可能高并发地完成“更多”的任务负载,强调单位时间内能够处理更多的任务。
1.2 高通量处理器设计思路
高通量计算定位于提高数据的并发处理能力,因此在高通量处理器设计中,数据通路的高效控制是一个核心问题,高通量处理器的设计目标是在通量场景下全局全时地保证数据通路的有序控制。基于此,高通量处理器在数据通路的三个核心环节,即数据存储、数据传输和数据处理方面都提出了新的设计需求:
(1)数据处理:需要设计高并发执行、实时性可控的处理机制;
(2)数据传输:需要设计支持离散细粒度访存的高吞吐片上网络;
(3)数据存储:需要设计可有效应对高通量流式数据访问特征的存储系统。
在高通量处理器的数据通路设计方面,我们借鉴了城市交通管理的思路。高通量计算在结构特征、资源管理、调度策略等方面都非常类似于城市交通管理,两者的共同特征都是在单位时间内完成尽可能多的处理请求,并保证QoS。如表2所示,我们参考交通设计方法开展了高通量处理器结构的设计。
(1)在数据处理端:我们实现了基于硬件支持的任务调度机制,将任务按照优先级及剩余裕度时间进行动态调度,有效保障了任务的QoS。
(2)在数据传输端:针对大量细粒度访存的需求,实现了高密度路网,提高片上网络的利用率和吞吐量。
(3)在数据存储端:优化了片上缓存层次的配置,提高片上缓存的有效利用率,进而降低对面积和功耗的开销。

表2 高通量计算结构与城市交通结构类比Table2 Analogy between high-throughput computing structure and urban transportation structure
2 高通量众核处理器整体架构设计
通过对高通量应用的特征分析,我们在文献[19]中提出了如图3结构的高通量众核处理器设计。
众核包含256个同构处理器核,采用16×16的两级环状拓扑结构,如图3所示,主环即为图中内部的环,子环通过路由器和主环连接。主环一共16个路由器与子环进行连接,并与Shared Cache、Memory、PCIe 等设备连接。在256 核的设计中,目前采用了4个DDR4 作为高通量处理器的存储结构。子环通过路由器与主环连接,子环包括16个处理器核。每个处理核通过路由器与子环连接。基于上述结构,本文对数据处理端、传输端和存储端的关键设计进行分析探讨。
3 实时任务调度机制
3.1 实时性任务调度需求分析
在大规模并行多线程处理器体系结构中,保证线程的服务质量,即满足线程的实时性约束保障,是一个非常重要的问题。针对这一问题,我们首先分析了实时调度机制对性能的影响。我们构造了如表3所示配置项的测试环境进行测试。测试分三阶段进行。
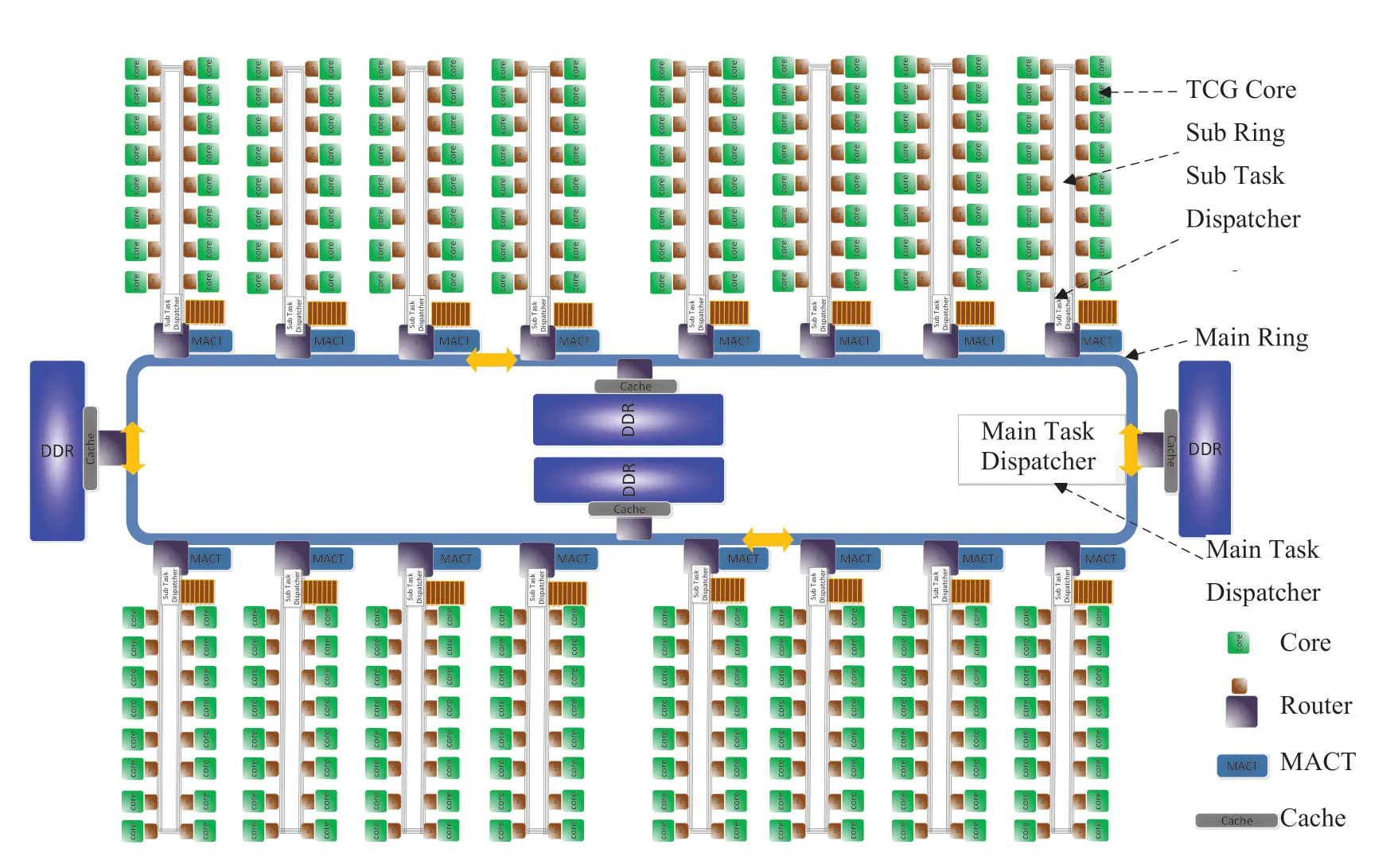
图3 高通量众核处理器架构示意图Fig.3 High-throughput many-core processor architecture diagram

表3 系统配置Table3 Configuration of System
第一阶段,热身阶段,均匀注入2*N_TASK个任务;这个阶段的时间是2*N_TASK*任务执行时间,也即能满足任务刚好在时间内执行完。
第二阶段,实际测试阶段,使用4种不同模式注入N_TASK个任务。这个阶段的时间是N_TASK*任务执行时间,也即如果均匀注入,可以在时间内刚好执行完毕。测试时分别在开始的1/4时间内,注入N_TASK的1/4、2/4、3/4、4/4。后面三种模式都会导致系统在这个区间出现集中注入的情况,从而容易引起任务失效。
第三阶段,退出阶段,均匀注入2*N_TASK个任务,时间和第一阶段相同。
测试时,将所有任务组织成优先级队列,按照不同的优先级进行轮询,如果发现任务未执行完,且优先级是最高优先级,即调度该任务执行固定cycle,如此循环,直到所有任务执行完毕为止。其中:
Deadline_1:任务的deadline是任务执行时间的64倍,deadline 最严格;
Deadline_2:任务的deadline是任务执行时间的96倍,deadline次严格;
Deadline_3:任务的deadline是任务执行时间的128倍,deadline 要求最松。
Case1:前1/4时间注入1/4的任务量;
Case2:前1/4时间注入2/4的任务量;
Case3:前1/4时间注入3/4的任务量;
Case4:前1/4时间注入4/4的任务量;
实验结果如图4所示,图中纵坐标数值是成功完成的任务占总任务的比例,红色为优先级调度的结果,蓝色为没有优先级调度的结果。Deadline 越严格,成功完成的任务越少,但是,加入优先级调度后成功完成的任务数明显多于无优先级调度的情况。
图5所示的纵坐标数值是实际调度执行的平均完成时间相比于任务所需的理论执行时间的比值。可以看到,对于无优先级的调度,不同deadline 下,任务的完成时间几乎相同,因为都是简单的轮询调度。当加入优先级调度后,任务完成时间明显变短,有利于满足deadline的要求,而且还可以看到,deadline越严格,任务的平均完成时间会越短。因为此时优先级调度会使得优先任务得到更多的连续调度机会。

图4 实时任务完成率的对比Fig.4 Comparison of real-time task completion rates

图5 实时任务完成时间的对比Fig.5 Comparison of real-time task completion time
图6中纵坐标数值表示的是任务失效时的剩余执行时间占所需执行时间的比值,图中某些空的项是由于该场景下没有失效任务。对于失效任务,在失效时其剩余的执行时间越长越好,这说明浪费在这个失效任务上的计算资源更少。可以看到,加入优先级调度后,失效的任务的剩余执行时间都比较长,大部分情况下,已执行的比例都不足50%。而没有优先级调度时,任务失效时,失效任务已经都基本要执行结束了,可见无优先级的调度对计算资源的浪费比较严重。
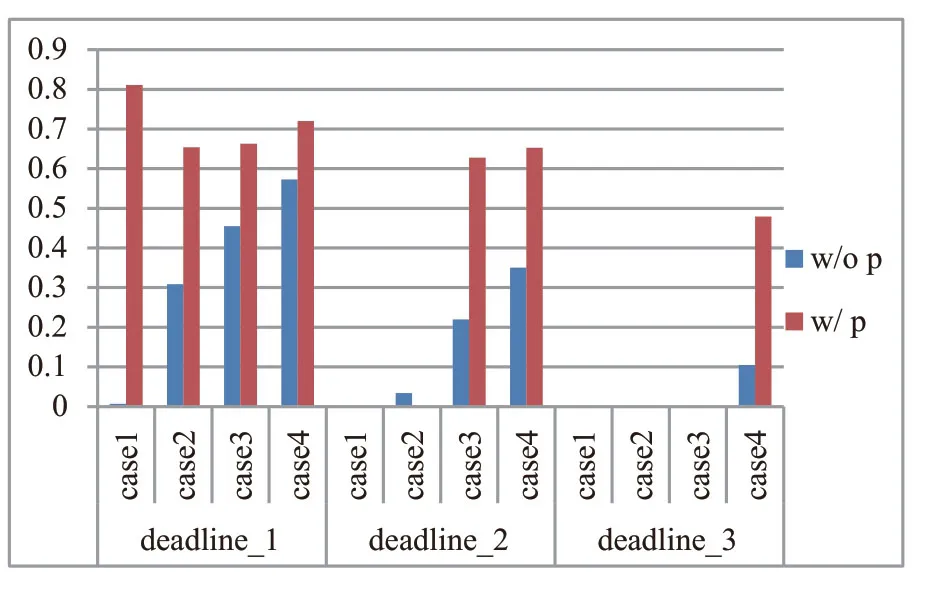
图6 失效任务在失效时的平均剩余执行时间对比Fig.6 Comparison of remaining time of failed tasks
3.2 调度机制设计及性能评估
基于以上分析,在高通量处理器设计中,我们通过基于硬件任务调度机制对任务的实时性需求提供保障。图7所示为硬件实现的任务分发器,用于对处理器内并发执行的线程进行裕度时间管理,通过多个任务链表的方式,实现了不同的任务优先级管理。其中,PID 代表任务所属进程号,TID为相应线程号,Occupied 域标识任务是否正在运行,Core_Num 用来记录任务运行的核号,Threshold_Time 记录需要转入高优先级模式的时间点,Context_Pointer为指向该Thread的Context 对应的内存地址,Next_Thread为指向本链表中下一个Thread的Index。分发器中在同一时刻存在三个链表:(1)空任务链表(Null Thread List):这个链表中存储的是还没有被分配任务的硬件线程,一开始所有的任务分发器上的线程都属于该列表;(2)普通任务链表(Normal Thread List):这个链表中存储的是正在运行的硬件线程,这些线程的门槛时间还没有过,所以处于普通优先级;(3)高优先级链表(High Priority List):这个链表中存储的是正在运行的硬件线程,这些线程的门槛时间已过,所以处于高优先级。
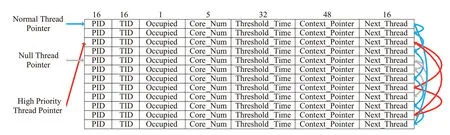
图7 任务分发器Fig.7 Tasks dispatcher

图8 采用基于硬件的实时任务调度机制前后的任务完成情况对比Fig.8 Comparison of task completion before and after using hardware-based real-time task scheduling mechanism
为了节省功耗和面积,整个任务分发器由RAM构成,用链表方式进行遍历。随着核数和线程数的增多,任务分发器将变得越来越大,此时可以采用分级管理机制,高优先级任务被率先分配至表中待执行,多个分发器并行执行。
我们进一步测试了在前文所提及的高通量众核处理器结构下的实时任务调度机制的性能。如图8所示,在左图中,我们使用了Deadline Scheduler[22],它根据每个任务的剩余时间动态地调度任务,以提高所有任务的成功率。结果如图所示,在采用了实时调度机制控制下,尽管最早的退出线程的执行时间大于左图的执行时间,但线程执行的成功率得到明显提升,线程的完成时间也变得明显更加规整。
4 高密度片上网络结构
4.1 高密度片上网络结构设计
随着高通量处理场景对并发核数需求的不断增加,加之高通量应用中存在着大量的细粒度访存,造成了片上网络的效率依然不高。为了更深入地理解网络通路设计上存在的问题,我们以城市交通网络为例进行类比分析。在北京、东京、巴黎、纽约这些全球主要大都市中,北京汽车不比东京纽约多,而且面积也不比东京纽约小,但北京的交通状况和生活环境却感觉如此拥堵和拥挤。分析可知,东京、巴黎、纽约的路网密度比较大,既有比较宽的主干道路,也有众多高密度的网络道路。主干道单位时间内可以通过大量的车流,当主干道发生阻塞时,邻近众多的高密度辅路和支路网络也可以分担大量的车流来缓解交通阻塞。
基于以上的分析,借鉴高密度道路设计的思路,我们提出了高密度片上网络的设计。为了最大限度控制硬件开销,我们在原有片上网络的基础上将较宽的通路拆分成多个细粒度的通道,每个通道独立控制,如图9所示。当不同粒度的访存请求从一个路由器发送到下一个路由器的时候,可以根据请求的大小选择合适的通道宽度,而其它未被使用的通道带宽可以并行传输其它请求。如此,可以提高带宽的有效利用率。
图9展示了高密度路网中链路与传统链路之间的结构对比图。以下图为例,假设每个路由器有三个方向(左、右、本地),宽度为64bit 宽。我们将传统的高宽度链路分割成低宽度的自治子链路,如图所示,64 bit 宽的通路分割成8个8 bit 宽的自治子链路,每个子链路可独立控制传输细粒度的数据包,也可以共同工作传输大数据包。
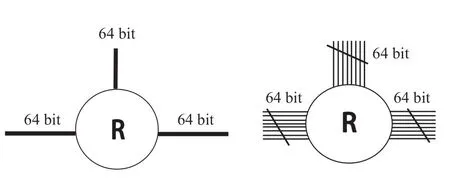
图9 传统片上网络链路(左)与高密度片上网络链路(右)结构对比Fig.9 Structure comparison between traditional on-chip network links (left) and high-density NoC links (right)
图10所示为高密度路网中路由器内部连线逻辑结构示意图。每个路由器有3个输入端口和3个输出端口。图中每个输入端口被分割成3个自主控制的子链路通道,且每个子通道支持两个虚通道。图中路由器结构分为三个主要的部分,左边为3个输入端口,与传统端口的不同是将链路的宽度分割成3个子链路,每个链路有自己的控制线(缓存区使能信号线等)、Credit 信号线。相对于传统链路,添加的物理硬件即为控制信号线即控制逻辑等,链路的总宽度未发生变化,缓存大小也未发生变化。图中右上为仲裁器逻辑单元,与外界的连线包括与输入端口之间的虚通道分配控制信号、端口传输请求信号、端口传输使能、输出端口或下一路由传来的控制信号以及仲裁结果输出信号。所有的控制信号线由原先的一套变成高密度中的四套。

图10 高密度片上网络路由器内部结构示意图Fig.10 Inner structure of router in high-density NoC
当传统网络结构变为高密度路网结构后,路由器内部传统的交叉开关分配算法并不能充分利用高密度路网带来的优势。为了适应高密度片上网络,我们结合链路连接结构提出了贪心传输机制来提高链路的有效利用率。“贪心”意味着传输链路在同一时刻尽可能传输更多的数据包。当几个待传输数据包大小不大于几个子链路通路的宽度时,这几个数据包便可以并行传输,以达到数据链路的充分利用。为了保证贪心传输机制的正常执行,在传统的(SA)Switch Allocation 阶段,我们实现了GA(Greedy Algorithm)。在GA 执行过程中,以输出端口为中心,在端口大小为上限的条件下,选择尽可能多的数据包。但是,为了保证公平性,算法需遵循一定的规则。
规则(1):以Round-Robin 算法选择基准端口。所谓基准端口即以此端口的数据包大小为初始大小,通过贪婪算法选择其它端口的数据包,最终获取局部最优策略。使用RR 算法轮询选择基准端口的原因是防止造成端口传输的不公平;
规则(2):基准端口数据包传输优先。对于某次传输,被选择的端口具有优先传输权利。所谓优先传输权利是指,当端口的虚通道或是虚通道内的缓冲中存在多个期望发往同一个输出端口时,优先组合基准端口的各个数据包,使其达到最优的传输效率。尽量选择同一端口的优点是降低输出端口所一次映射的输入端口,可以尽量使其它端口与其它输出端口映射,提高端口的利用率。若基准端口无法填满传输链路,则选择其它端口数据包进行合并传输;
规则(3):组合传输时不能存在重叠子通道。在合并传输的过程中,不能存在子通道重叠的数据包同时传输至同一个输出端口,例如端口1的子通道1和其它端口的子通道1 不能同时传输至同一个输出端口。因为为了降低路由器内部交叉开关连线的复杂度,输出端口和输入端口的子通道是一一对应,非全相联映射关系。
4.2 高密度片上网络性能评估
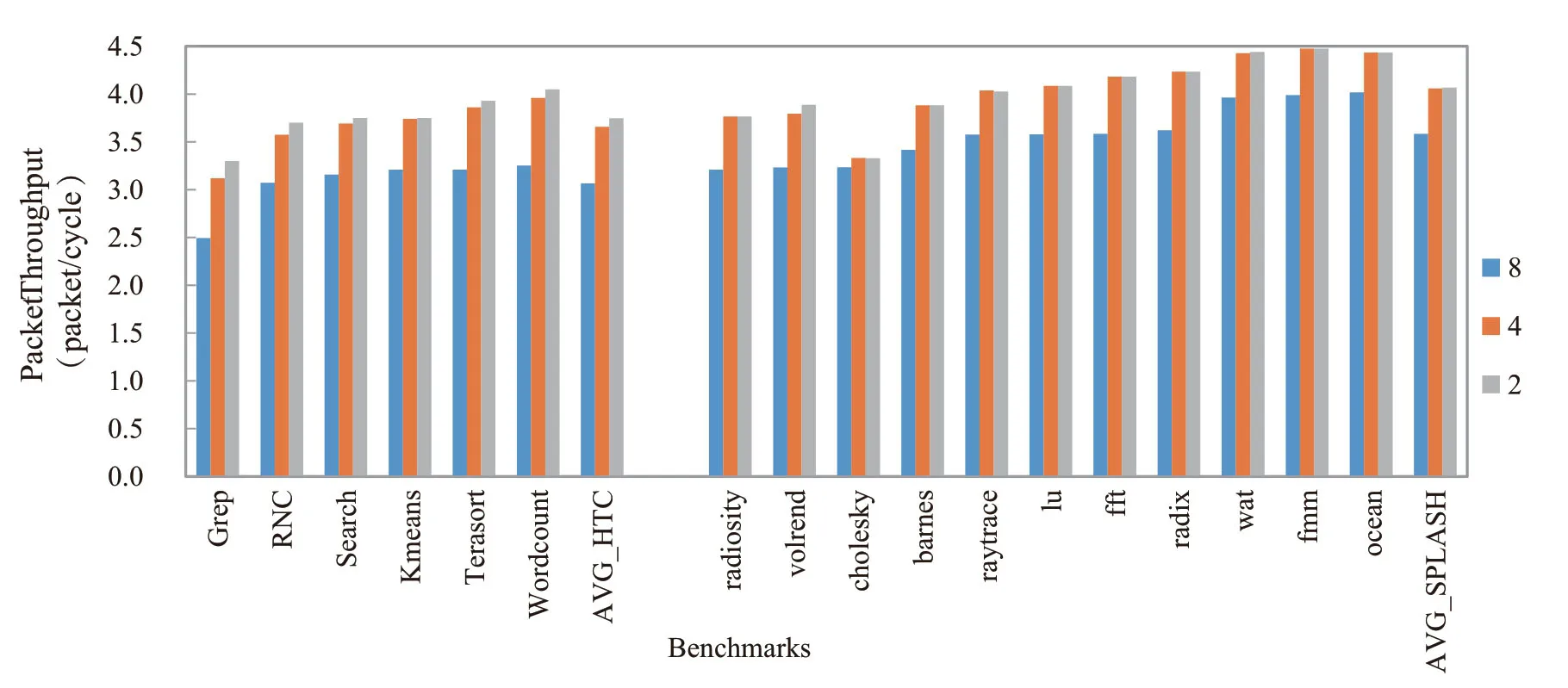
图11 不同Channel 宽度选择下的数据吞吐量对比Fig.11 Data throughput comparison under different channel width choices
图11展示了高通量应用和SPLASH-2 应用的数据吞吐量在饱和注入情况下随通路宽度的变化情况。实验中,我们分别测试了将64bits 宽的链路切分成16bits、32bits以及原有宽度的配置下的饱和吞吐率情况。因为数据包的大小不一,理论上饱和吞吐量会随着链路的切分加深而上升。因为当切分的子链路越小时,可并行传输的数据包的概率会增多,从而增强片上网络的有效吞吐率。从实验结果可以看出,无论是高通量应用还是SPLASH-2 应用,其吞吐率都随着通路宽度的降低而逐渐升高。对于高通量应用,子链路宽度从8 Bytes到4 Bytes 时,平均吞吐率提高了19.3%,从8 Bytes到2 Bytes 时,平均吞吐率提高了22.2%。其中,Grep 应用分别提高了25.2%和32.4%。因为在Grep 应用中,1 Byte的访存粒度占了近90%的比例,大量的细粒度访存消息使得高密度片上网络的优势得到了充分的发挥。对于SPLASH-2 应用,子链路宽度从8 Bytes到4 Bytes时,平均吞吐率提高了13.3%,从8 Bytes到2 Bytes时,平均吞吐率提高了13.5%。因为在SPLASH-2 中1 Bytes 或2 Bytes 细粒度访存比较少,所以从4 Bytes到2 Bytes的平均吞吐率的提高很小。由实验结果可知,高密度路网对于高通量应用和传统的SPLASH-2应用来说都有一定的性能提升,尤其对于高通量应用来说,效果显著。为了继续探索数据包大小在不同的比例下对片上网络的吞吐率(Throughput,网络所能够接受的最大注入率)的影响,我们试验了在不同数据包粒度下的数据吞吐率的变化趋势。实验选取了16bits和64bits 两种数据包进行测试,片上路由链路宽度为64bits,两种数据包的出现比例为0:10,1:9,2:8,3:7,4:6,5:5,6:4,7:3,8:2,9:1,10:0,数据包出现的序列随机产生,实验结果如图12所示,可见低粒度的数据包占比较高时,网络的吞吐量有一定的性能提升。
5 片上存储结构
5.1 片上Cache 性能分析
片上存储在处理器结构设计中扮演着重要角色,弥补了处理器核与主存储器的速度鸿沟。而对于数据密集型的高通量应用来说,片上存储对性能的影响更为巨大,因此需要合理设置片上存储来提高处理器的整体能效比。如前文中图2所示,传统Cache 结构在高通量应用场景中出现了结构设计与应用需求明显不匹配的问题。一级Cache 命中率极高,而二级Cache 命中率很差。在高通量众核处理器片上存储设计中,为了保障通用性和可编程性,除SPM 存储外,同时实现了片上Cache 存储结构。为了探究在高通量应用中,对片上缓存的需求,我们首先对L1 Cache和L2 Cache 进行试验分析和参数的确定,通过测试WordCount、TeraSort、KMP、K-Means、LP测试benchmark,对本文设计的面向高通量应用的的众核处理器 Cache Miss 率进行了评估。实验配置私有L1 Cache 32K,4个共享256K L2 Cache。

图12 不同的16bits和64bits 数据包比例下吞吐率变化图Fig.12 Changes in throughput of different 16-bit and 64-bit data packet ratios
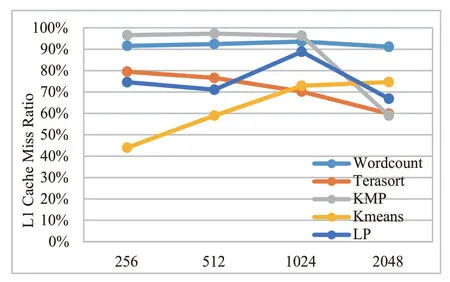
图13 L1 Cache 失效率Fig.13 L1 miss rate
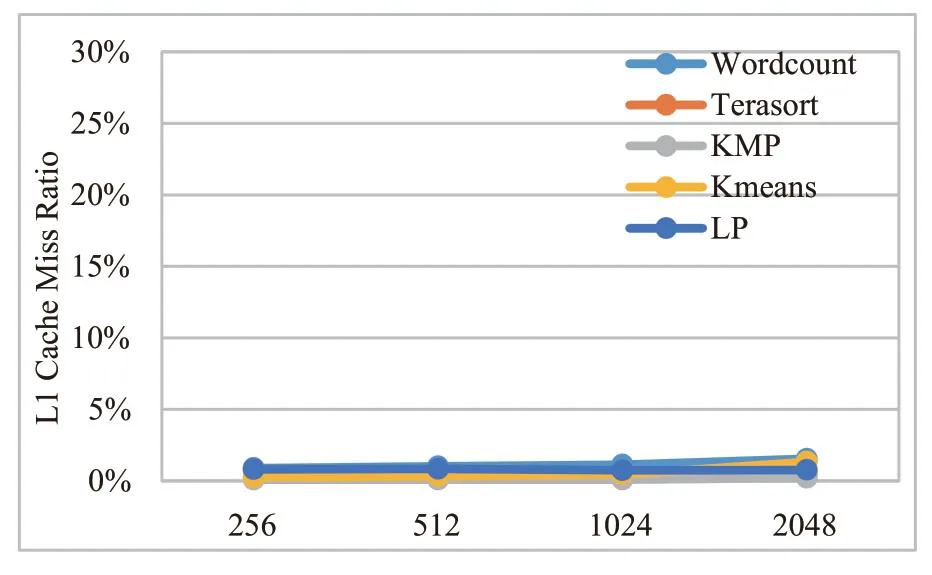
图14 L2 Cache 失效率Fig.14 L2 miss rate
对于一级Cache 来说,具有非常好的命中率,缺失率均稳定在1%以内。对于二级Cache 来说,由于数据的局部性(数据空间局部性为流式局部性,数据按地址顺序使用一次即被抛弃)被一级Cache所消耗,因此导致二级Cache的命中率不高。
5.2 片上Cache 设计探讨
考虑通用性,本文在文献[19]所提众核结构上配置传统三级Cache 结构并探讨其在高通量应用下的性能。图15和图16所示为高通量应用在传统3级Data Cache 存储结构中各级Cache 命中率。图15中的L2 Cache为核私有,而图16中的L2 Cache为共享Cache。Cache 具体配置见表4。
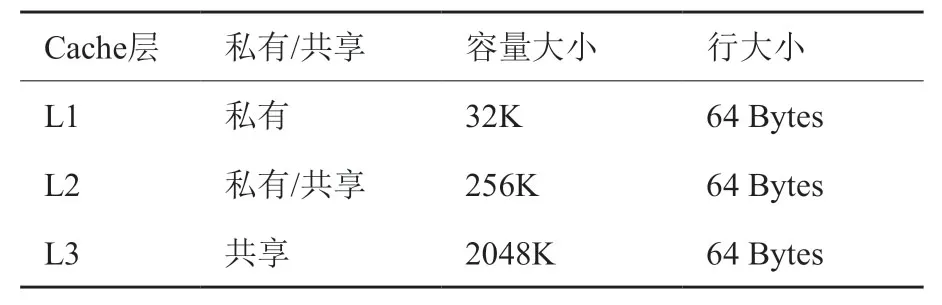
表4 Cache 层级配置参数Table4 Configuration of Cache Levels
从结果中可以看出,几个典型高通量应用在访存行为上存在一个共同现象:L1 D-Cache的命中率非常高,L2和L3 有一个的缺失率很高。其原因主要是由于Cache line 大小保持了一致(64B),且大部分访存为流式数据,即数据地址连续且仅使用一次,导致其下一级Cache 几乎全部是缺失。从面积和功耗的角度来说,L2和LLC的命中率并不高,但却占用了大量的片上面积,同时也带来了较高的功耗比。从实验结果来看,私有的L2 Cache 没有必要,使用私有L1 Cache以及共享L2 Cache 即可在性能和面积功耗上达到较好的权衡,无需L3 Cache。

图15 L1/L2 私有,L3 共享下的Cache 性能统计Fig.15 Cache performance statistics for private L1/L2 and shared L3
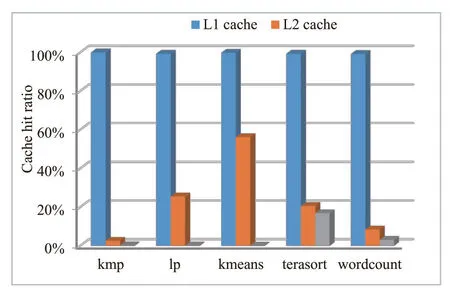
图16 L1 私有,L2/L3 共享下的Cache 性能统计Fig.16 Cache performance statistics for private L1 and shared L2/L3
从以上实验数据中还可以看出,共享的二级Cache的命中率不高,对此我们进行进一步的探究,继续增加共享二级Cache的容量并对性能进行评估,以典型的KMP 应用为例,测试结果如图17所示。
由实验数据可知,在Cache块大小保持64 Bytes不变的情况下,即使二级Cache的容量不断增长,二级Cache的命中率依然比较低且变化可忽略不计。但当Cache块大小从64B 增长到256B 时,命中率从14.9%左右骤增到73.6%左右。主要原因是应用程序的顺序局部性较好,二级Cache所预取的值对一级Cache来说命中率非常高。因此,对于二级Cache的设计,推荐采用大Cache Block的配置(128B 或256B)。
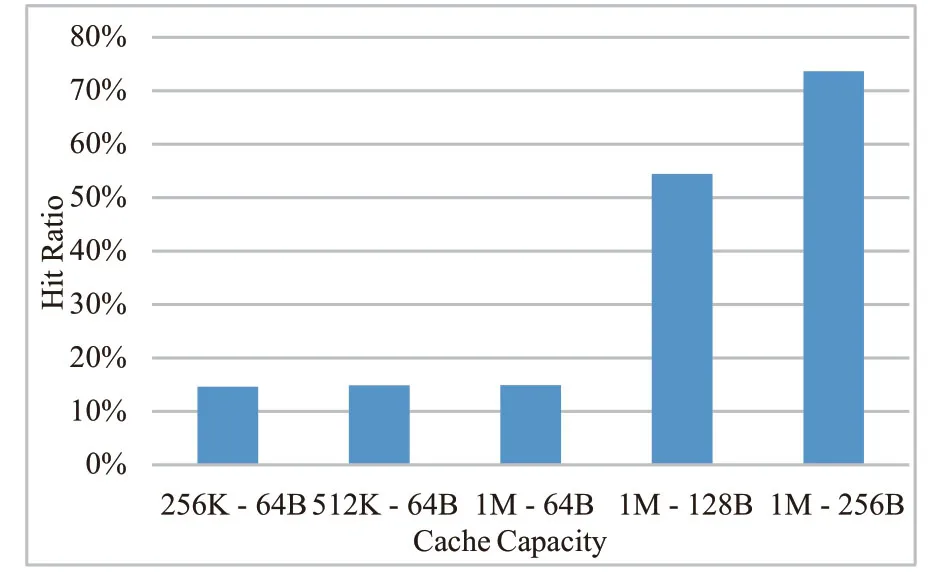
图17 KMP 应用下L2 命中率随容量大小或Cache块大小变化趋势Fig.17 Trend of L2 hit rate in KMP applications with capacity or cache block size
6 总结
随着具有高并发和强实时等特征的高通量应用成为网络服务数据中心的主要负载,传统高性能处理器设计已难以满足高通量应用的高效处理,必须针对高通量应用特征系统性地研究符合新应用特征的处理结构,高通量处理器的设计目标就是要打破传统高性能处理器一味追求速度快的设计方法,转而重点满足海量并发数据服务请求。本文通过对高通量应用特征的实验和分析,总结出高通量处理器需要面对的新型应用特征需求,基于两级环状网络的256 核高通量众核处理器架构开展了关键技术的设计探讨。在数据处理端,针对高通量应用中高并发处理的实时性需求,采用基于硬件结构的两级任务调度和分配机制,提高大规模并行任务的调度有效性和实时性。在数据传输端,针对高通量应用离散的细粒度访存特征,采用高密度片上网络传输机制,提高片上网络对数据的传输能力。在数据存储端,针对高通量应用对片上存储的需求,优化了片上存储的配置参数,提高了高通量应用的数据存取能力。本文通过全面的实验和结果分析,探讨了面向高通量应用的众核处理器体系结构在数据处理端、传输端以及存储端的设计思路,期望对未来面向数据中心高通量应用的处理器体系结构设计具有一定的借鉴意义。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
国际太空(2023年1期)2023-02-27 09:03:42
透析与人工器官(2020年1期)2020-11-16 01:42:34
铁道通信信号(2019年8期)2019-10-10 05:06:00
网络安全和信息化(2018年4期)2018-11-09 12:01:54
中国发展观察(2017年8期)2017-04-26 03:51:50
环球市场(2017年36期)2017-03-09 15:48:21
中国新通信(2014年11期)2014-09-11 19:27:52
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
电子设计工程(2011年24期)2011-06-09 10:15:02
