
面向超大规模计算系统的监控、调度及网络优化实践
2020-04-18 08:56:14秦晓宁王家尧胡梦龙苏勇万伟李斌戴荣王志鹏吉青
数据与计算发展前沿 2020年1期
秦晓宁,王家尧,胡梦龙,苏勇,万伟,李斌,戴荣,王志鹏,吉青
1.南京航空航天大学,计算机科学与技术学院,江苏 南京 210016
2.曙光信息产业(北京)有限公司,北京 100193
3.中国人民大学附属中学,北京 100080
引言
在第34届国际超级计算大会ISC19 上,TOP500作为全球最快计算系统的榜单发布[1]。该榜单显示最快系统的峰值达到~150Pflops。而入榜的最后一名峰值也超过了1Pflops。整个榜单正式全面进入千万亿次规模时代。中国的计算系统也呈现类似的趋势。中国TOP100的平均Linpack 性能继续保持高于国际TOP500平均Linpack 性能的局面,且TOP100的入门性能门槛仍然超过TOP500[2]。更有学者指出,峰值Exaflops的机器将在2019-2020年间出现;峰值10Exaflops的机器将在2022-2023年间出现;峰值100Exaflops的机器将在2024-2025年间出现[2]。这些都足以显示出,业界计算系统规模不断在提高,超大规模的计算系统也在逐步部署并投入使用。
然而,大规模计算系统的出现与投入运营,在给研究学者带来超强计算能力的同时也给系统的设计人员、使用人员和运维人员带来了一系列挑战。如清华大学信息科学与技术国家实验室的高性能计算公共平台在运营过程中就遇到了如设备类型复杂、数量众多、任何设备出现故障都会对平台运行有不同程度的影响;集群系统全年24小时开机服务,使设备故障发生率提高,管理难度加大;空调等设备故障,几分钟之内温度可以上升至50℃~60℃,导致硬件设备损坏甚至火灾的危险等等问题[3]。因此,及时有效的告警,不仅可以降低运维人员的劳动强度,更加可以提高故障诊断效率,为故障修复争取更多时间。这对于超大规模计算系统尤为重要。
IBM的Tivoli[4],Dell的Open Manage Essentials[5],中科曙光的GridView[6]等等不少厂商的集群管理软件或多或少都有告警功能。但是随着系统规模的急速增加,新的问题聚焦到两个具体的方面。首先是告警及时性。系统需要通过稳定的性能指标监控、应用监控、操作监控等方式,不断积累相关数据,并借助数据挖掘、人工智能等手段,对性能、能效和可靠性进行自适应优化。通过和作业调度系统的结合,系统积累的数据和调优参数可动态应用到作业运行之中,才能使用户任务以最有效率的方式运行,使集群发挥其最大作用。目前大规模的指标采集与告警技术在集群系统整体设计时面临严峻挑战,系统需采用完全可横向扩展的设计,同时兼顾超大规模系统和小型集群的部署、运维成本等等。其次是系统的可管理性及易维护性。计算机规模越来越大、节点数越来越多,需要解决大规模监控的问题,不仅仅要采集,还要支持智能化告警与维护,当节点达到上万节点会造成告警风暴,监控系统都面临这些问题,因此,数据的聚合处理必不可少。
大规模计算系统普遍需要一个调度系统来执行资源管理和作业调度的功能。首先需要选择合适的集群调度系统以支持超大规模集群。其次集群节点规模越大导致集群调度系统启动时间越长。此外,长时间作业吞吐对调度系统的提交性能、调度性能和记账性能都产生了较大压力。相比于之前的PBS[7-8]和LSF[9],SLURM 已经成为最流行的调度系统之一[10]。2019年6月的Top500 前10的系统中有一半使用了SLURM。这是因为SLURM 提供了包括基于拓扑感知的优化资源分配、具有公平共享作业优先级的分层帐户系统和许多资源限制等一系列丰富特性。SLURM 目前管理的大型系统包括天河2号(中国国防科技大学,拥有1.6万个计算节点和310万个核心)和红杉(劳伦斯利弗莫尔国家实验室的IBM Bluegene/Q,拥有98,304个计算节点和160万个核心)。并且由于其开源的特性,用户可以对源代码进行相应的定制以满足集群需求。这让我们可以基于SLURM 进行特定配置,甚至进行代码级的优化成为可能。
超大规模计算系统内部众多的处理器之间如何高效通信,这对互连网络提出了严峻挑战。Google对数据中心网络的能耗情况进行了研究,发现当处理器的利用率达到100%时互连系统的能耗占全系统的20%,但是数据中心的利用率一般是在15%左右,此时网络能耗高达50%[11]。因此,如何利用互连技术提高网络的能效,降低系统成本和功耗正成为目前的研究热点问题之一。对于规模达十万节点的超大规模计算系统来说,互连网络按系统能耗的三分之一来算是6MW,平均每个路由器的能耗是60W。带宽的不断提高,使得功耗也成为限制端口数目的主要因素,大端口交换机越发困难,有研究称在400Gb/s 带宽下的单芯片基数(radix)可能仅为10[12]。
作为大规模计算系统的代表性技术之一,性能局部性和时间局部特性,对并行应用的计算效率有着重要影响[13]。Agrawal 认为如果不同节点间的通信概率随着物理距离而减少则并行应用具有通信局部性,应用的通信局部性有助于提高直接网络的吞吐率并降低延迟[14]。IBM的研究人员分析了11种典型高性能应用的通信模式[15],发现大部分高性能应用具有很好的空间局部性和时间局部性,且通信度较低,通信对象通常是4到8个。伯克利的Vetter指出大规模应用可扩展性效率最高的通信模式是处理器的平均通信拓扑度为3~7个通信目标或近邻[16]。应用的通信矩阵分析显示大部分应用都具有近邻通信的特征,特别是像3D Stencil 这类应用,每个节点至多和6个近邻通信,这是由其代码的计算结构所决定的,其通信矩阵呈现斜带状分布。Nick 等人分析了Splash-2和Parsec 测试集中24种应用的通信行为[17],发现通信局部性对拓扑设计有重要影响。一是像LU,Ocean和Water-spatial 等的通信局部性特征非常显著。二是许多应用在近邻CPU之间发生非常强的通信,比如Barne、Ocean和fmm,通常是一个CPU与其他6~10个CPU通信。数据显示高性能计算应用的通信局部性更明显。由此可见,针对超大规模计算时网络通信特点,直联的nD-Torus 网络拓扑结构将有一定的优势。
在近期超大规模计算系统的设计和使用中,作者及其团队采用了基于动态负载均衡的分布式监控架构设计,基于高速缓存的分布式告警架构设计,基于SLURM的源码和配置优化,以及nd-Torus 网络拓扑对比等相关技术手段,实现了对于过万节点的计算系统的相应支持,优化效果基本达到了业务使用的要求。本文就监控、调度、网络优化三方面予以总结,希望为同行提供一定参考。
1 面向超大规模计算系统的监控管理实践
超大规模计算系统需要针对动力环境资源、计算资源、存储资源、网络资源、业务基础环境、应用等进行管理,通过进行分割、分层和分区管理,将集群中的物理资源、业务基础资源、应用数据、应用等整合统一调度管理、统一监控分发[18]。
计算系统针对功能需要动态性、模块化采用可扩展性平台,采用OSGi技术作为模块化的基础平台,以面向服务的思想为导向,构建管理平台软件模块“热插拔”机制,灵活的应对软件的动态扩展需求[19]。可以以OSGi bundle为粒度,实现基于插件机制的模块的动态在线添加、升级、卸载功能,同时允许多版本共存,为软件平台提供坚实的基础。
插件架构体系的核心理念是基于松散的模块积累方式,通过新增插件以及扩展原有插件的方法来完成系统的实现[20]。一个插件模块的更新不需要对整个系统进行重新编译,不会影响其它插件模块。插件架构体系的优点非常明显,像硬件一样的即插即用。在开发的时候只需划分好模块,各个插件开发人员只需遵循接口协议,就能开发出互不影响的插件模块,非常方便开发和调试;由于其灵活性,可以实现系统的灵活定制,当新增功能或者修改功能时,只需对相应插件进行修改即可实现,为软件的发展带来了极大的灵活度。本文将OSGi技术和插件的思想具体应用到了超大规模计算系统的监控与管理之中。
1.1 基于动态负载均衡的分布式监控架构设计
我们采用消息机制构建了一种基于动态负载均衡的分布式监控架构。架构的核心主要由总管理节点、分管理节点、消息中间件和映射关系配置几部分构成,如图1所示。每部分功能介绍如下:
总管理节点主要负责三项功能。首先,实时监控各分管理点的状态,并根据分管理点的数量、状态及性能情况,将系统所管理的服务器资源均匀分配给各个状态正常的分管理节点,并将此对应关系记录在映射关系配置文件中。其次,总管理节点监控消息中间件中监控数据队列的内容,实时将各分管理点传输来的监控数据从数据队列中取出,进行汇总后存储到数据库中,同时根据监控数据值及监控阈值触发对应的告警。最后,总管理节点通过浏览器为用户提供统一的界面入口,使得运维人员能够清晰地浏览集群中各服务器的状态及监控数据。
分管理节点负责收集和监控服务器集群的节点。主要有以下三个功能:首先,它会定期向总管理点查询管理范围是否变化,即所监控的服务器列表是否发生变化。如发生变化,则请求最新的监控范围,重新初始化监控调度列表。其次,根据监控的范围,采集服务器监控数据。最后,根据总管理点调度周期,定期将所监控范围内的服务器的监控数据,发送到消息中间件中,供总管理点收集汇总。
消息中间件是总管理点和分管理点监控数据传输的异步通道。分管理节点将监控数据发送到消息队列中,总管理点从消息队列中取出所有分管理节点的监控数据,最终进行告警触发和数据存储。
映射关系配置由总管理点维护,记录了各分管理点所监控的服务器范围。总管理点也会根据分管理点状态、数量的变化以及被监控管理的集群服务器数量变化,对映射关系配置进行对应的更新。
此外,对于超大规模计算系统来说,负载不均衡是非常常见的现象,且与作业调度系统的策略直接相关。本文从四个层次,为负载均衡的监控目标做出了努力。
(1)总管理节点通过映射关系配置文件查询所有分管理点信息及历史状态,然后依次通过网络监控各节点实时状态。如果有节点状态改变,则修改映射关系配置文件的映射关系,并更新状态。
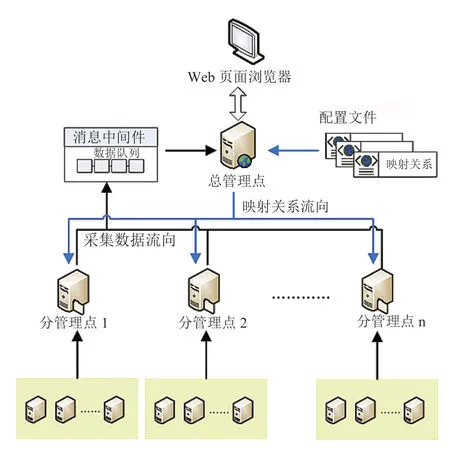
图1 基于动态负载均衡的分布式监控架构Fig.1 The load-balanced distributed monitoring architecture
(2)根据当前状态为正常的分管理节点数量及所有被管理服务器资源数量,调整各分管理节点与服务器资源的对应关系。即取消状态异常的映射关系,为状态变为正常的分管理节点增加与服务器资源的映射关系。同时根据实际计算值增减状态未发生变化的分管理节点与服务器的映射关系。
(3)将最新的映射关系及映射关系更新到映射关系配置文件中。
(4)分管理节点会定时从总管理节点获取映射关系,以及时更新所管理的服务器资源列表及指标。首先,分管理点从总管理查询映射关系是否发生变化,如未变化,则流程结束,如发生变化,则继续操作;其次,分管理点暂停采集监控数据,从总管理点查询最新的所管理的服务器列表及相应的指标。再次,重置采集调度列表后重启采集调度流程,采集对应的服务器的监控数据。
监控的及时准确性是以数据采集的质量和速度为基础的。首先,我们采用分管理节点调度程序通过IPMI、SNMP 等协议采集被监控服务器的监控信息,并将数据发送的消息中间件中的数据传输到队列中。随后,总管理节点从消息中间件中读取消息,获取所有服务器的监控数据。最后,总管理节点将读取的数据进行告警触发、汇总、统计等,并将处理后数据存储到数据库中。
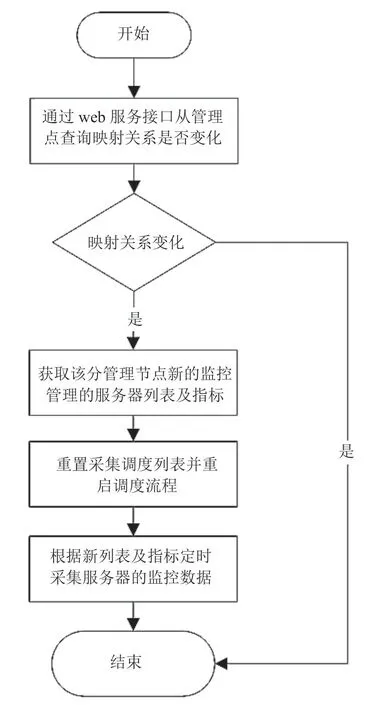
图2 分布式架构下的更新指标流程Fig.2 The flowchart of monitoring indicators updating

表1 单层监控采集架构与二层监控采集架构支持节点规模对比Table1 The support scale of one-layer monitoring architecture and two-layer monitoring architecture
通过采用基于动态负载均衡的分布式监控架构,中科曙光管理软件系统可支撑的系统监控规模从传统架构的1000 节点提升至10 000 节点,并可支持进一步扩展。具体数值列于表1之中。
1.2 基于高速缓存的分布式告警架构设计
对系统进行监控的目标是及时有效的协助运维人员掌握计算系统的健康状态和作业状态,并做出相应的调整。但是随着计算系统规模的增加,单纯由人工来诊断指标,变得越来越不可行。这就让告警的需求提上了前台。
在超大规模的集群监控系统中,通常展示的都是各个服务器部件对应的指标,如服务器的部件CPU指标,网卡部件的网卡速率指标,内存部件的内存利用率指标等。以及每个指标对应的系统告警信息,如CPU、内存利用率过高告警、网卡速率传输异常告警、IPMI 网络、计算网络异常告警。以上的集群服务监控可以有效的监控到大规模服务器集群下每一个节点下的指标运行情况,快速地定位指标是否实施采集,异常指标是否产生告警。
但是随着集群规模的不断壮大,大批量的数据随之产生。传统的告警数据存储已经不能满足现有的需求。对大规模告警数据的及时及准确处理显得尤为重要。为了提高告警产生与恢复的效率,在本系统的数据流转过程中,引入了高速缓存Redis 来负责接收中转数据[21]。为可快速查询实时告警,通过设计实时告警与历史告警相分离,从而减少了实时告警数据库表的数据量,其数据量大小基本可以控制在100万条以内,可以保证多表联合查询时对实时告警的查询效率。通过自定义告警规则的方式来满足用户对告警定义的定制化需求,从而从根本上提高告警准确性与易用性。
此外,在告警生成与恢复的环节,本文也改进了传统计算系统设计中采集系统向告警系统传送数据的接收环节,告警模块直接把告警数据写入高速缓存中,告警系统与采集系统数据交互各自相对独立,在性能上互不影响,做到了告警与采集松耦合。
为应对超大规模计算系统的告警需求,我们从告警指标的定义、告警触发、告警恢复、告警聚合四个方面进行了进一步的优化升级。
(1)告警指标定义:计算系统指标的采集是依赖采集框架中的采集插件,在采集插件中会预先定义采集指标以及此指标的告警基本信息。其中包括:是否告警(isalarm),告警级别(threshold severityname),告警级别为:严重(critical)、重要(major)、一般(minor)、轻微(warning),默认阈值(threshold),阈值名称 (threshold name),阈值中文描述(threshold description)以及阈值条件(threshold conditionid)。
(2)告警触发:在采集框架中设计了一个告警与采集相关联的子系统模块,当系统模块启动时会把采集插件定义的指标、阈值以及与此指标相关联的告警阈值模板存入到缓存中。当采集到指标,就会根据指标ID 在缓存中遍历出此告警所对应的阈值模板。用指标值和阈值模板中的阈值进行对比,如果超过阈值,则放入告警过滤器模块。告警过滤器模块中有负责记录告警触发次数的缓存器,此缓存器接收超过阈值的采集指标和此指标的告警模板,返回是否可以发送告警到告警平台。
我们采用的告警过滤与缓存机制如下:
a.告警初始化,当平台启动,启动告警发送功能,同时将上次实时告警存入告警过滤器缓存;
b.告警计数过滤,如果有告警记录,则增加告警记录次数,如果次数达到告警门槛,则不再记录;
c.删除资源过滤器处理,当有资源变更或删除资源时,告警过滤器缓存中的指标对应用资源缓存就会做出相应的删除,其中处理的资源包括子资源和主资源的指标;
d.触发告警时更新资源与告警缓存,当一个指标触发告警,告警过滤器会把指标和指标对应的资源添加到过滤器的资源指标缓存中,删除资源时和告警恢复后删除。
(3)告警恢复:通过对采集到指标进行告警阈值判断,确认是否需要恢复告警,不需要则不做处理。如果需要恢复告警,在告警过滤器中查出告警恢复对应的告警时间和告警ID,存储到Redis 中。我们设计了3个缓存库,分别用于存储实时告警,存储恢复告警记录,写入数据库时临时数据缓存。
(4)告警聚合:即告警按一定的维度的对告警原始信息进行统计与合并,达到告警归类统一处理的目的,为告警通知和告警处理提供可行性策略与规则,配合通知系统完成告警通知功能。本系统中,告警聚合均为实时告警进行聚合。历史告警不做聚合处理。对于告警聚合维度的设计,我们从以下6个方面进行了考量。
a.对达到此阈值的资产个数进行聚合,如达到此规则(严重告警:10个,重要告警:5个,一般告警:5个)的资产共有10个;
b.对用户关注的指标进行聚合统计资产数量,如集群中CPU温度超过阈值(80度)的告警资产的数量为10个;
c.对用户关注的多个指标进行聚合统计,如集群中DCU 温度过高且CPU温度过高的节点数为10个;
d.对资产种类进行告警统计聚合,如集群中交换机严重告警 10条,重要告警5条,共15条。Linux 服务器严重告警5条,重要告警4条,共9条;
e.当集群中对严重告警或是严重告警数量高度关注时,按严重程度进行聚合。如集群中严重告警4条,一般告警5条,重要告警10条。
f.当用户关注集群运维效率与集群故障处理的及时性时,按告警持续时长与级别进行聚合。如集群中严重告警超过1小时未恢复的告警为10条,重要告警超过2小时未恢复告警为5条。
通过对告警指标的定义、告警触发、告警恢复、告警聚合四个方面进行优化升级,中科曙光的监控平台基本实现了对上万节点系统监控的业务级使用需求。
2 面向超大规模计算系统的作业调度实践
Slurm 管理节点守护进程Slurmctld 作为核心服务,负责节点、网络、License 等集群资源的管理,还要维护跟计算节点的通信,最重要的是通过管理一个作业队列来仲裁对资源的争用[10]。集群规模越大管理节点任务越繁重,因此要求大规模集群的管理节点的CPU频率和核心数要高。使用Intel(R) Xeon(R) Gold 不同规格CPU测试了提交性能,对比如图3所示。数据显示Slurm 提交作业对芯片核数和主频都较为敏感。
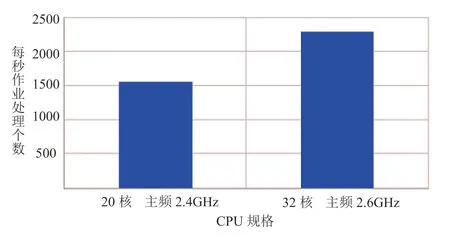
图3 芯片核数和主频对SLURM 提交作业速度的影响Fig.3 The job submission rate with different CPUvia SLURM scheduler
为了更好的改进作业提交的效率,基于SLURM调度系统,我们对管理节点、记账服务、调度参数进行了有针对性的优化。
2.1 管理节点配置优化
为提高作业调度效率,我们首先对管理节点配置进行了优化。Slurmctld 启动时有两个阶段比较耗时,第一个是从配置文件解析所有计算节点IP,第二个是slurmctld 周期性ping 计算节点同时所有计算节点会向管理节点发送注册信息。这两个过程造成了管理节点服务启动卡顿。可以通过在节点配置文件中写NodeAddr 来消除第一阶段卡顿时间。测试结果显示设置NodeAddr 可以每个节点节省5 毫秒。第二段可以尝试调大ping 周期,跟处理计算节点注册信息时间错开。还可以调整消息聚合MsgAggregationParams的配置,减少计算节点注册消息数量。测试结果显示,通过以上设置至少可以将Slurmctld 启动时间缩减为原来的三分之一。
向集群提交作业时,Slurmctld 会在State Save Location 目录为每个作业创建至少一个临时目录和两个临时文件,此外该目录还保存节点状态、分区状态、QOS 状态等运行时的系统状态快照,在高可用配置中主备服务器会共享该目录。因此该目录要挂载于专用快速的文件系统之上,这个文件系统的IOPS是作业吞吐量的主要瓶颈之一。
此外调低Slurmctld的调试级别可以减少调试信息的输出,同时提高了Slurmctld的响应。
2.2 记账服务优化
Slurmctld 运行过程中的一些记账信息会通过Slurmdbd 服务写入mysql 数据库。因此Slurmbdb也要运行在一个较快的文件系统上。在测试中,设置Slurmdbd 提交数据到数据库的时间间隔为1 秒可以显著提高slurmdbd的性能并减少开销。此外mysql 数据库本身也需要优化,测试有影响的参数有 innodb_buffer_pool_size,innodb_log_file_size和innodb_lock_wait_timeout 等。
2.3 调度参数优化
调整调度参数对调度系统作业吞吐量有较大影响。长时间维持较高的作业吞吐量将使系统中存在大量活跃线程。如果Slurmctld 守护进程中的活跃线程数等于或大于此值max_rpc_cnt,将会产生锁进而推迟作业的调度,但是可以提高Slurm 处理请求能力。具体值需要根据系统实际情况设置,以便调度不总是被禁用,同时请求能够在合理的时间段内通过。
sched_min_interval 用于限制调度周期最小值。任何提交作业、挂起作业、修改作业、取消作业或者作业正常结束等事件都能触发调度。如果这些事件发生频率很高,则调度过程会非常频繁的执行,进而消耗大量资源。设置合理的值限制由于大量作业结束导致频繁的调度,可以保持系统负载稳定。
batch_sched_delay是用来为批处理作业的调度延迟时间,sched_max_job_start 用于设置单次调度最大作业数。在高通量的环境中,批处理作业通常以非常高的速率提交,这两个参数配合使用可以减少调度每个作业的开销。
由于上述地缘环境的影响,尽管中越文化因历史渊源而形成了诸多相通或相似之处,但如今越南对中国文化的传播却持有一定的警惕态度。如2010年中越合拍的历史剧《李公蕴:到升龙城之路》就因越南影视审查部门认为风格“太中国化”而被取消播出;2014年,越南文化部又向全国各地发出公函,建议从古迹和宗教场所等地移除中国造型的石狮子,替换成具有本土风格的灵物雕像。
如果回调(backfill)调度不会延迟任何优先级较高的作业的预期启动时间,则它会启动优先级较低的作业。回调调度通常用来提高集群的利用率,如果启用了回调调度,在高通量环境下通常需要酌情设置bf_resolution、bf_min_prio_reserve、bf_min_age_reserve 等参数。
我们对proctrack,jobacct_gather,select 三个常用的SLURM 参数进行了组合设置对比。使用Intel(R) Xeon(R) CPUE5-2650 v3 @ 2.30GHz 型CPU和Intel 730 SSD 480G 磁盘,以proctrack/linuxproc,jobacct_gather/none,select/cons_res 作为参考点,测试其他参数对SLURM 高通量作业提交的影响如图4所示。数据显示,当选用A 组合的方式,即linuxproc为作业追踪插件方式,作业账号信息不做收集,仅记录CPU和内存信息,作业提交速度最快,范围在每分钟3000~5500个。
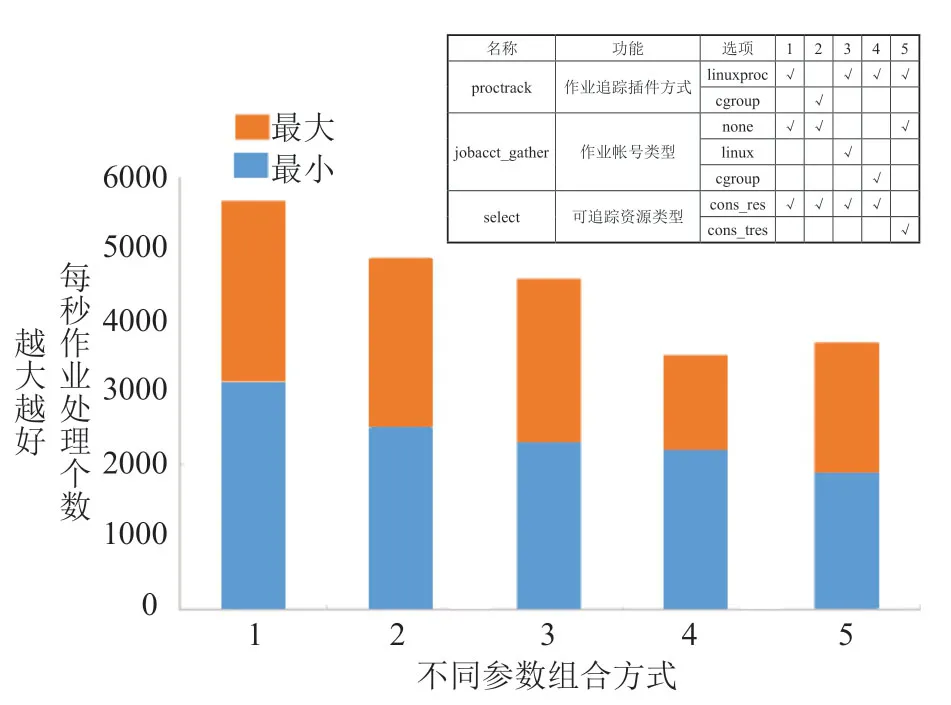
图4 部分Slurm 参数对高通量作业提交的影响Fig.4 The effects of different parameters on job submission via SLURM scheduler
此外,我们还进行了调度器源码优化,主要集中在线程数和IO模型优化,以及内存模型优化两个方面。
分析Slurm 源码可以看出Slurmctld是高度线程化的,可以通过调大Slurmctld 最大线程数提高其吞吐能力。目前Slurm 使用select 接口实现了单Reactor 多线程模型。select 接口本身具有诸多限制,而epoll 因为没有最大并发连接的限制并且通过利用回调和mmap 映射等方式大大提高了IO 效率。因此,改造Slurm 源码使用epoll 替换select 可以提高调度系统响应和吞吐能力。
Slurmctld 维护一个就绪作业链表,里面保存了所有提交的作业结构体。作业结构体是一个非常大的结构体,每次提交一个作业都分配一个作业结构体,添加到作业链表,开销较大。参考Linux 内核slab 内存管理机制修改Slurm 源码,空闲时建立缓存对象内存池,分配一些空的作业结构体,当有作业提交时从内存池取一个空作业结构体进行填充,初始化好后挂到就绪作业链表上。作业结束后释放资源,空的结构体放回内存池。这样可以有效减小提交作业、添加作业链表的开销。
3 面向超大规模计算系统的nd-Torus网络拓扑架构
影响大规模直接网络性能的因素主要有网络拓扑、路由算法、交换策略和拥塞控制等方面内容,其中拓扑和路由从宏观上决定了网络的可扩展性和通信延迟及容错性能,因此,网络拓扑结构和路由协议成为领域内重点研究的热点问题。合理的互连结构不但可以提供高性能的通信还可以减轻并行程序的设计负担,所以互连网络的设计必须考虑并行应用程序的通信模式和特征。直接网络已经得到多家厂商的关注,如IBM BlueGene/Q 5D Torus[22],Fujitsu K computer 3D Torus[23],Cray cascade Dragonfly[13]等。
汇总发现,Torus 网络具有如下特征:
(2)可扩展性好、易于系统扩容。Torus 网络结构规则,易于扩展,可根据应用需求渐进式扩容。例如,结构为[8,8,8,6,6,6]的6D-Torus 直接网络即可连接110 592个节点,可完全满足超大规模计算系统的互连需求。而Fat-Tree 受端口限制,扩容不易。除非系统规模和路由器的维度匹配完好,否则会有许多无用的交换端口。
(3)系统利用率高。Torus 网络的结构特征决定了可以根据应用的规模高效分配任务方案,灵活的子网结构可以高效分配任务,系统利用率高。
(4)通信局部性好。Torus 拓扑结构天然的适合局部通信密集型应用,对局部通信密集的高性能应用具有加速作用,因而更适合高性能应用的通信局部性特征。
(5)低成本、低能耗、高性能。Torus的拓扑结构仅需少量的端口即可满足大规模扩展的需求,因而具有更低的网络成本和能耗。
(6)路由算法简单高效,便于硬件实现。Torus网络由于拓扑规整,基于最短路径的维度路由可快速计算路由,并最小化传输延迟,已经在大规模计算系统中得到了广泛应用,比如Cray 公司的XT5、XK6、XK7,IBM 公司的BlueGene,日本的K-Computer 等。
(7)容错性能好,网络更稳健。对于大规模网络,设备发生故障的概率是无法避免的,因此,路由算法具有较强的容错能力,将至关重要。而Torus 网络的维度路由可绕过故障路径,确保通信完整。而且Torus 网络具有多条冗余路径,采用发散路由可提供路径分集功能,有利于网络负载均衡。
针对超大规模计算时网络通信特点,我们设计了6D-Torus 网络结构,用于系统的计算通信。计算网络整体采用6D-Torus 网络架构连接所有的计算节点、存储节点与管理节点。计算网络共分为三层,第一层为全交换网络,第二层为3个局部维度构成的双列交叉结构的局部网络,第三层为由3个全局维度构成全局3D-Torus 网络。全局3D-Torus 网络又被划分为若干区域,光交换网络构成区域间的快速通路。图5展示了6D-Torus 系统网络层次化结构图。
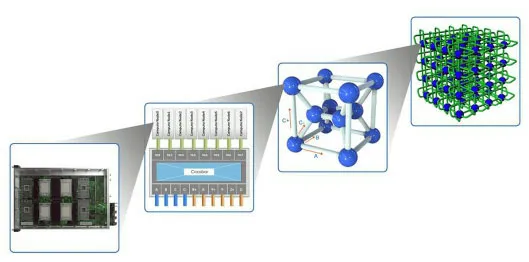
图5 6D-Torus 系统网络层次化结构图Fig.5 The layer design of 6D-Torus network topology
第一层为全交换网络。如图6所示,14个计算节点连接到一个高速交换模组,形成一个超节点(Super Node)。每个高速交换模组对外提供6个维度,10个方向(A、B、C+、C-、X+、X-、Y+、Y-、Z+、Z-)的高速互连,分别用于局部维度和全局维度的连接,维度间提供1000G 超高带宽。

图6 超节点内部网络连接图Fig.6 The interconnection linkage with a super-node
第二层为3个局部维度构成的双列交叉结构。12个超节点通过其高速交换模组的A、B、C+、C-四个高速接口,连接成一个双列交叉结构,形成一个硅元(Silicon Node)。每个硅元可连接14×12=168个节点。
第三层为全局维度的3D-Torus 网络。每个硅元通过其12个超节点的X+、X-、Y+、Y-、Z+、Z-共 6×12=72个高速接口,连接成一个全局3D-Torus 网络,形成整个硅立方(Silicon Cube)系统。图7展示了第二层与第三层网络的连接图。
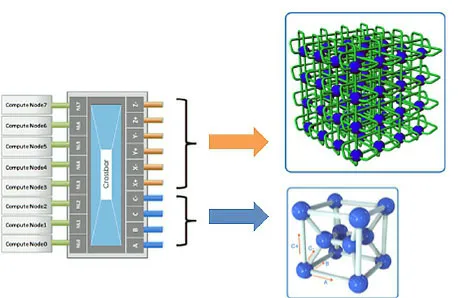
图7 第二层与第三层网络连接图Fig.7 The interconnection linkage in the seconde layer and the third layer
对于大规模互连网络来说,网络拓扑结构应具有良好的扩展性才能保证网络带宽不会成为限制系统规模扩展的瓶颈。直接网络的平均距离H 与处理器数目P的关系如表2所示。对应超大规模计算系统的高性能网络,3D-Torus 网络的平均距离为35 跳,如此高的通信延迟是高性能应用无法容忍的,而6D-Torus 网络的平均距离只有10 跳,极大地降低了通信延迟,网络性能会有更大提升。图8显示了各种直接网络的通信延迟性能。数据表明,Hypercube拓扑具有最好的延迟性能。但是由于端口数量限制,Hypercube 难以大规模扩展。而Torus 拓扑随着维度的提高,网络延迟随之下降。相同规模,Torus 维度越高,网络直径越低。因此,提升Torus 拓扑的维度,将有利于网络扩展。如表2所示,6D-Torus的延迟随着规模的扩展增长非常缓慢,可以认为,6D-Torus拓扑更适合大规模网络。

表2 网络平均距离和拓扑类型的关系Table2 The average distance of different interconncetion topology
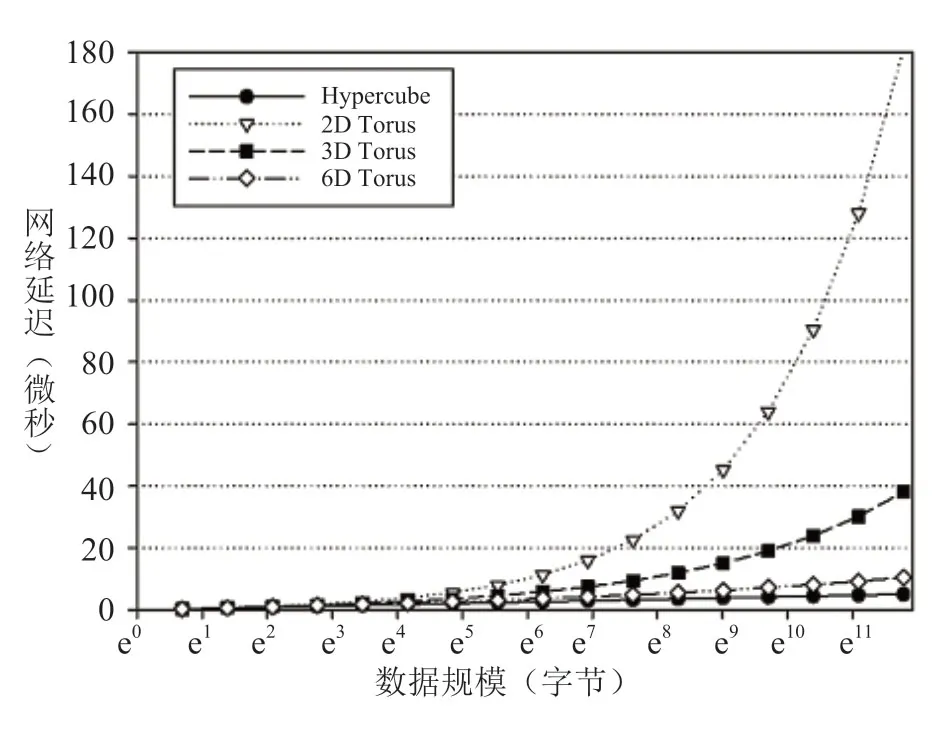
图8 直接网络通信延迟性能的理论仿真Fig.8 The theoretical simulation on the latency of direct interconnetion
为了检验网络系统在超大规模计算系统的性能,我们在约110K(7x7x7x7x7x7=117649)节点规模进行了性能测试。这里我们将经典的3D-Torus 拓扑和新颖的Dragonfly 拓扑作为比较对象。图9是三种不同流量类型的仿真结果。仿真采用的是cHPPNetSim多功能可配置并行网络模拟器和网络模拟器(Fabric Simulator)[24]。图中横轴是归一化吞吐率,纵坐标是点对点通信延迟,单位是时钟周期。从该图中可以看出,对于均匀随机流量,3D-Torus 拓扑由于网络直径大,通信距离长,饱和吞吐率仅为15%;而6D-Torus 网络由于网络直径低,平均通信距离短,因而,性能较3D-Torus 有很大提升,饱和吞吐率超过40%;Dragonfly 拓扑由于网络直径只有5 跳,因而具有最优的性能,吞吐率最高。
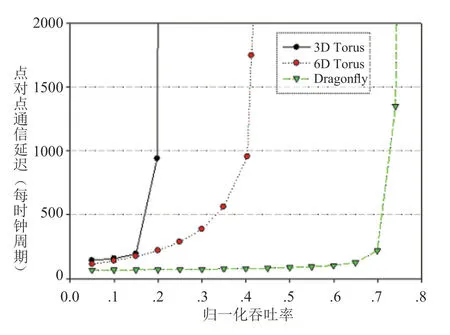
图9 均匀随机流量性能的理论仿真Fig.9 The theoretical simulation on the throughput of direct interconnetion
在局部性较强的LU Trace 流量情况下(见图10),3D-Torus 性能提升很快,吞吐率达55%,6D-Torus 性能提升一倍,饱和吞吐率接近80%,而Dragonfly 性能略有提升,延迟下降较快。在Ocean Treace 近邻通信模式下(见图10),3D-Torus 由于拓扑结构和应用的通信模式最匹配,因而饱和吞吐率最高,但是未饱和之前,延迟还是较高,6D-Torus拓扑的通信延迟进一步下降,只是饱和状态延迟有所提高,而Dragonfly 相对于LuSim 流量略显下降,主要是因为流量都集中到固定的6个邻居节点,造成局部链路拥塞,因而性能下降。
除性能外,我们还对相关网络拓扑的理论线缆消耗量和交换机消耗量进行了推算,如表3所示[24]。结果表明在考虑对线缆的使用量的问题时,理论数值显示Fat-Tree 拓扑在交换机和线缆的使用量上,会由Torus的N倍上升为LogfN*N倍,所以直联网络可以极大的节省交换机和线缆的使用量,尤其对于超大规模计算系统,这种优势会随着节点数N的增加而激增。
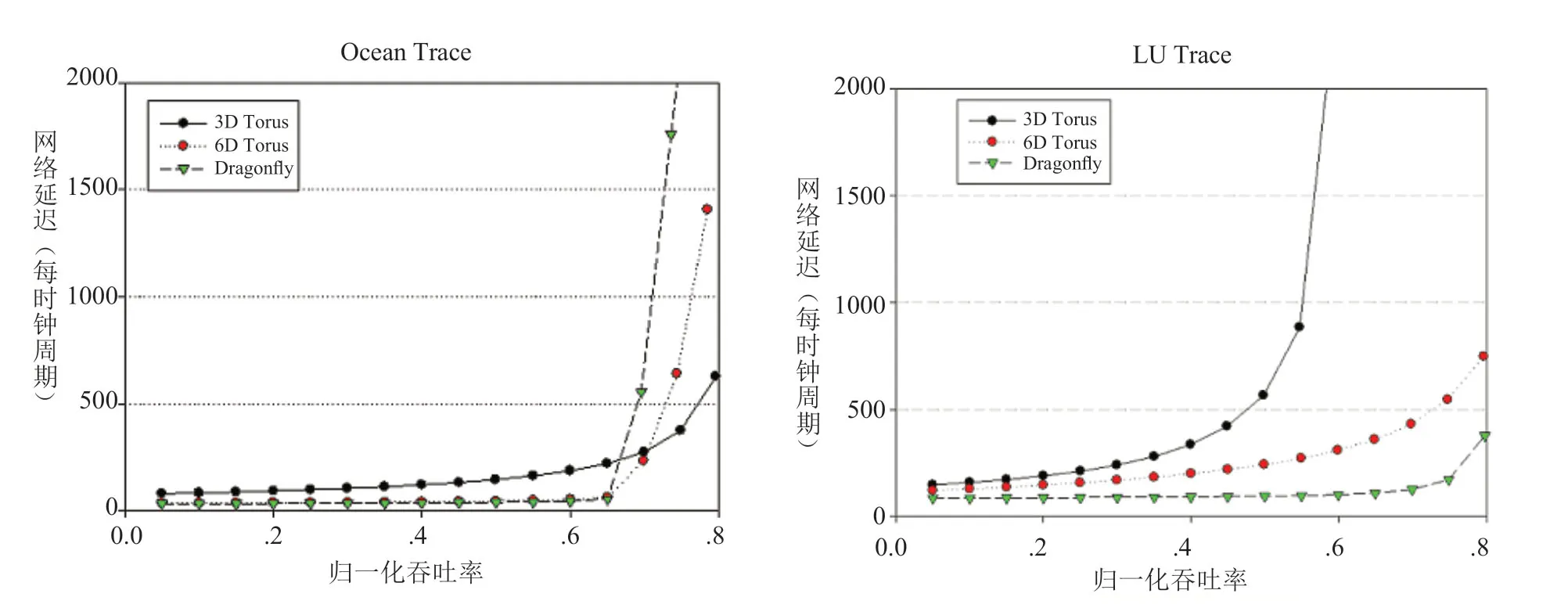
图10 LU Trace 流量性能与Ocean Trace 流量性能的理论仿真Fig.10 The theoretical simulation on the ocean trace of direct interconnetions
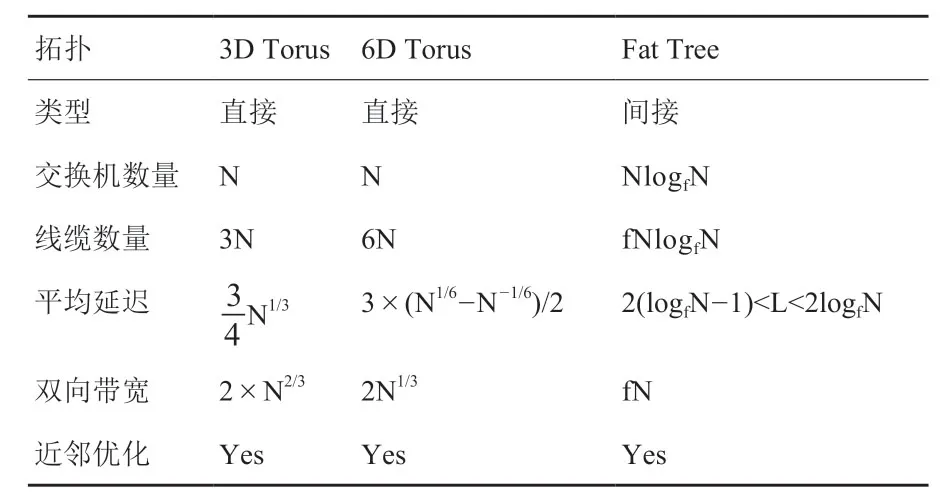
表3 3D-Torus 与Fat-tree 网络拓扑的理论对比,其中N为节点数,f为优化因子Table3 The theoretical comparison on 3D-Torus and Fat-tree topology.N is the nodes number and f is the optimizing indicator.
通过对3D-Torus,6D-Torus,Dragonfly 三种网络拓扑在通信延迟性能、均匀随机流量性能、LU Trace 流量性能、Ocean Trace 流量性能进行对比,数据显示6D-Torus 优于3D-Torus。但Dragonfly 会有更好的理论性能。未来的研究,我们将会侧重于Dragonfly的探索。
4 结论与展望
本文介绍了中科曙光在近期实际大规模计算系统的设计与使用过程中使用的技术方法,以应对在系统监控、作业调度、网络拓扑选择三个方向的实际业务问题。
超大规模计算系统监控采集信息的种类更多、数量更大,给管理节点带来了较大压力,甚至会影响系统的正常运行。曙光采用了基于动态负载均衡的分布式监控架构设计,基于高速缓存的分布式告警架构设计,基本解决了上万节点规模的监控和告警问题,同时为更大规模系统的监控预留了空间。同时,为了提高告警的准确度和可用性,避免监控数据风暴的发生,我们从告警指标的定义、告警触发、告警恢复、告警聚合四个方面进行了进一步的优化升级。SLURM是超大规模计算系统可用的作业调度系统之一,其提交效率对芯片核数和主频都较为敏感。我们对SLURM 参数组合和源代码都进行了一定优化,以提高作业提交的速度和稳定性。
并行计算的可行性和效率直接依赖于计算系统的网络性能。对于超大规模计算系统,选择合适的网络拓扑架构尤为重要。通过对2D-Torus,3D-Torus,6D-Torus,Dragonfly,以及Fat-tree 网 络在网络平均距离、通信延迟性能、均匀随机流量、LU Trace 流量性能与Ocean Trace 流量性能几个方面的仿真模拟对比,我们发现6D-Torus 较3D-Torus 性能更好。此外,如考虑交换机和线缆用量,直联网络较Fat-tree 网络更有优势。数据同时也表明,Dragonfly 网络拓扑在均匀随机流量、LU Trace 流量性能、Ocean Trace 流量性能等方面会显示比6D-Torus 更优异的性能。因此,下一步我们会侧重于Dragonfly 来进行超大规模计算系统的网络拓扑选型、分析和模拟验证。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
疯狂英语·新读写(2021年10期)2021-12-07 02:41:30
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
新世纪智能(英语备考)(2019年4期)2019-06-26 00:49:04
铁道通信信号(2019年11期)2019-05-21 03:06:06
电子制作(2018年11期)2018-08-04 03:25:40
中国公共安全(2017年8期)2017-10-13 08:12:17
中国交通信息化(2017年3期)2017-06-08 06:09:28
