
基于机器学习的行业电力大数据预测
2020-04-16 06:30郑阳胡博郝美薇杨丹丹
中国科技纵横 2020年19期
郑阳 胡博 郝美薇 杨丹丹
(国网天津市电力公司信息通信公司,天津 300010)
0.概述
随着国家对经济发展政策的不断调整,行业之间的发展和影响更加紧密。基于细分行业的电力大数据,结合产业发展数据和相关指标的梳理,分析、挖掘不同行业之间的影响关系并进行相关预测研究,可以为公司发展、营销服务等长期发展战略制定提供决策支撑,同时对区域经济结构转型、地方经济发展和相关经济政策调整具有参考意义[1]。
2010 年,英国著名杂志《经济学人》推出了一项用于评估中国GDP 增长量的指标“克强指数”,其中首要指标就是耗电量[2]。利用电力消费的结构、趋势变化,可以对地区产业结构和宏观经济走势进行分析和预测,在高质量发展的背景下为地方政府科学决策提供支撑[3]。
电力需求预测中常用的方法有回归分析、时间序列分析、模糊预测、神经网络、灰色理论、小波分析、支持向量机等。然而,直接使用上述模型分析,耗电量可能无法获得合理的结果,基于这一考虑,应采用更加成熟的行业指数模型,在考虑电力消费结构的基础上,综合考虑气温、产品产值等外部数据。
本文以天津市电力局的耗电量数据,并结合对应年度的国家统计局的外部数据及其他外部数据,采用BP 神经网络模型算法,预测各个行业的累计同比增长值增速,从而预测行业的景气指数。
1.问题分析与数据收集
电力消费结构与地区的经济走势息息相关[4]。国内外学者对电力数据进行了一些相关研究。然而,这些研究只反映了电力消费的静态结构,而不能反映其动态结构,在对电力消费的研究中,其预测往往基于一些主观推测,缺乏定量客观上的研究。另外,行业的发展与其耗电量息息相关。因此,有必要通过研究电力消费结构来对行业的景气指数作出预测。
影响经济的因素包括长期因素及短期因素。长期因素会对经济发展造成长远影响,如城市化率、政策影响。短期因素则会对经济发展造成短期影响,在众多因素中,季节、气候、节假日安排、行业上游供给、行业下游需求等,都能够在短期内影响一个行业的景气程度。因此,可以将行业的用电情况与以上景气影响因素相结合,来得到行业景气的变化趋势,预测行业未来的景气指数。
利用特征数据对目的数据预测的方法有很多,而机器学习是其中最常见的预测算法[5]。机器学习是一种用数据和以往的经验,以此来优化计算机程序的标准。在机器学习算法中,BP 神经网络是一种常见的方法,由于BP 神经网络所具有的优良的拟合特性,它可以以任意精度去拟合数据[6]。由于本文引入的外部数据为行业累计同比增加值增速,以及处理成为累计同比增加值增速形式的行业主要产物数据,这种同比形式的数据可以忽略时间序列因素的影响,因此在本次应用环境中,选用形式相对简单、训练速度较快的BP 神经网络来进行拟合。
本文使用的电力数据来源于天津市电力局的耗电量数据,其包含2012 年1 月至2019 年9 月每月的数据。另外,本文使用的外部数据包括累计同比增加值增速,以及处理成为累计同比增加值增速形式的其他外部数据,用来为行业的累计增加值增速提供辅助帮助。
2.行业景气指数预测模型
行业景气指数预测模型是用于预测某一地区行业景气程度的模型,本节介绍该模型的方法和流程。为了预测行业景气程度,首先需要根据各个行业的特点进行特征选择,并进行数据收集。然后需要对数据进行预处理和清洗,并划分训练集和测试集。其中,行业耗电量数据和行业相关数据是输入,行业产值数据是输出。利用训练集对机器学习模型训练,找到算法模型的最优超参数,并用其预测测试集。
2.1 特征选择
特征选择的目的是确定与目标行业相关的数据及行业产值累计同比增加值增速数据,即外部数据,并最终确定模型的输入和输出。外部数据即包括气温等对各个行业都有广泛影响的因素,也包括目标行业的原材料和产出等上下游数据。本节选择了5 个典型的行业进行分析,各个行业的输入如表1 所示,各个行业的输出都为累计同比增长值增速。
选择行业的增加值增长速度作为行业景气程度的判断指标的原因是,工业增加值增长速度,即工业增长速度,是用来反映一定时期工业生产物量增减变动程度的指标。利用该指标,可以判断短期工业经济的运行走势,判断经济的景气程度,也是制定和调整经济政策,实施宏观调控的重要参考和依据[7]。由于此处使用的增加值增速是累计同比,也就排除了季节、假期等外部因素的干扰,因此只需考虑累计月份的平均气温以及行业的用电情况作为主要影响因素。
由于目标行业的上游供给和下游需求对目标行业的景气程度有着至关重要的影响,因此目标行业相关的上下游产业的主要产品产量也被作为模型输入的一部分,使得模型更具有现实应用意义,并且能够提高模型的准确性。

表1 模型输入输出信息表
2.2 数据收集
根据已经确定好的模型输入输出表,收集5 个行业的外部数据,将原始数据以表格或CSV 格式存储。外部数据中,天津市月度平均气温(2012 年1 月至2019 年9 月)来自天津市统计局,行业累计同比数据(2013 年2 月至2019年9 月)来自前瞻数据库,产量累计值数据(2012 年2 月至2019 年10 月)来自中国国家统计局。
2.3 数据预处理
2.3.1 数据清洗与数据预处理
由于所收集的原始数据可能存在缺失值和异常值的情况,因此需要填充缺失值并替换异常值,使用相邻数据的均值来代替缺失值或异常值。在进行了数据清洗操作后,需要进行数据预处理,根据现有的气温数据以及用电数据计算得到模型的输入数据。
由于行业景气程度的判断指标是行业产值的累计同比增长值增加速度,它的数据形式是:

从这个式子可以看出,作为训练标记的增长值增速是一个时间段数据,而作为训练输入的气温和耗电量都是时间点的数据,因此需要将它们转换为时间段的形式。由此,引入了气温上升幅度t 和耗电量增长率e。它们的计算方式如下:
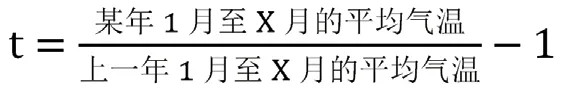

而对于上下游产业的主要产品的产量数据,采取相同形式的数据处理方式,获取产品产量的累计同比增加值。
2.3.2 数据集划分
在训练模型前,需要对数据集划分,将数据集划分为训练集、验证集、测试集。训练集用于训练模型参数;验证集用于训练模型的超参数;测试集用于评估模型的预测效果。在划分数据集时,对数据集进行混洗,训练集、验证集、测试集的比例为8:1:1。
2.4 机器学习预测模型
本节介绍的机器学习预测模型以BP 神经网络为基础。BP 神经网络是通过误差反向传播算法训练得到的多层前馈神经网络,BP 神经网络包括输入层、隐含层、输出层3 种组成,每一层有若干节点,通过误差反向传播算法,就可以训练神经网络,改变隐含层的状态,从而影响输入和输出的关系,最小化神经网络的预测值与实际值之间均方误差。
通常认为,隐含层数的增加虽然可以降低均方误差,提高预测精度,但也同时使得网络结构复杂化,增加了网络的训练时间,提高了过拟合的风险。因此,在设计神经网络时应优先考虑只含1 个隐层的3 层网络,并适当增加隐层单元的数量,因此,本文采用不易过拟合的三层神经网络结构。
2.5 损失函数
在模型的训练与测试中,需要设置损失函数,判定模型的预测效果。本文采用的损失函数为L1损失函数。L1损失是把预测值与目标值之间的绝对差值的总和最小化。
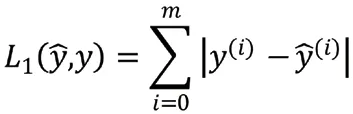
3.实验结果与分析
3.1 实验环境

图1 2013~2019黑色金属冶炼和压延加工业
本文实验的硬件平台为Intel(R)Core(TM)i5-8400 CPU@2.80GHz 2.81GHz、16GB 内存、1TB 硬盘以及Windows10 系统,软件环境为Python3.7、Tensorf low。
模型的2 个隐藏层的神经元个数皆设为500,其他训练参数如表2 所示。

表2 训练参数
3.2 结果分析
将数据集输入到行业景气指数预测模型中,并对不同的行业分别准备模型,然后进行训练和测试,不同行业的模型在各个数据集上的L1损失如表3 所示,其中行业名为对应缩写,5 个模型的平均L1损失均在可接受范围内。

表3 不同行业的模型在各个数据集上的L1损失
以黑色金属冶炼和压延加工业为例,展示模型的拟合效果和行业的经济趋势,如图1 所示。蓝色线条是2013年—2019 年黑色金属冶炼和压延加工业每个月份的累计同比增长值增速,反映了行业的景气程度,黄色线条是模型拟合得到的累计同比增长值增速,绿色线条是测试结果。在经过多轮迭代训练之后,神经网络获得了一组表现较好的参数,使用训练好的神经网络对数据进行处理,就得到了图中黄色线条所示的一组输出值。从总体上看,该模型对经济运行的趋势有着较为准确的判断。
4.结论
本文利用机器学习方法进行行业电力大数据预测,从而对地方经济产业结构和宏观经济走势进行分析和预测。本文使用BP 神经网络方法,挖掘耗电量数据、行业产值累计同比增加值增速数据、行业相关数据之间的潜在关系,从而预测行业景气程度。实验结果表明,基于BP 神经网络的机器学习预测方法,可以拟合行业运行的趋势,从而预判行业未来的发展趋势。
猜你喜欢
四川化工(2022年3期)2023-01-16
今日农业(2022年14期)2022-09-15
中国经济周刊(2022年8期)2022-05-07
日用电器(2021年7期)2021-08-17
煤气与热力(2021年6期)2021-07-28
伴侣(2018年9期)2018-09-19
消费导刊(2018年7期)2018-08-22
消费导刊(2018年10期)2018-08-20
消费导刊(2018年9期)2018-08-14
消费导刊(2018年8期)2018-05-25
