
Spark参数重要性研究
2020-04-14 04:54王奕
电脑知识与技术 2020年4期

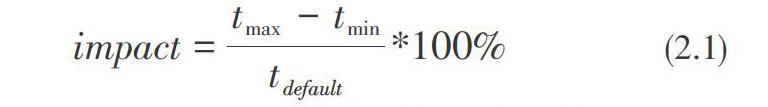
摘要:随着大数据时代的到来,Spark因其基于内存的计算方式,已经成为当前最流行的分布式计算框架之一。为了提升易用性,Spark为用户提供了约200个可配置参数,这些参数控制着任务的运行。然而,Spark参数空间巨大,用户经常无法合理选择哪些参数进行配置。针对此问题,本文通过实验对不同Spark参数与任务运行时间之间的关系进行了详细分析,对Spark参数重要性进行研究。实验表明,不同参数对任务影响程度差异巨大,这对开发者如何选择参数进行配置具有指导意义。
关键词:Spark;分布式;配置参数;任务运行时间;重要性
中图分类号:TP311.13
文献标识码:A
文章编号:1009-3044(2020)04-0247-03
收稿日期:2019-11-02
作者简介:王奕(1994—),男,浙江衢州人,同济大学在读硕士研究生,主要研究方向为大数据。
Research on the Importance of Spark Configurations
WANG Yi
(Tongji University,Shanghai 201804,China)
Abstract:With the advent of the era of big data,Spark has become one of the most popular distributed computing frameworks due to its memory-based computing methods.To improve ease of use,Spark provides users with about 200 configurable parameters that control the operation of the task.However,Spark has a huge parameter space,and users often cannot reasonably choose which parameters to configure.Aiming at this problem,this paper analyzes the relationship between different Spark parameters and task running time through experiments,and studies the importance of Spark parameters.Experiments show that the impact of different parameters on the task varies greatly,which has guiding significance for developers to choose parameters for configuration.
Key words:spark;distributed;configuration parameters;task runtime;importance
1 研究背景
Apache Spark[1]是由UC Berkeley AMP lab在2009年開发的一个基于内存的分布式计算系统。由于其在编程模型和性能的灵活性方面改进了Hadoop[2]MapReduce[3],尤其针对迭代式应用,所以Spark已经成为广泛应用的大规模并行数据分析的计算框架之一。Spark 的编程核心是弹性分布式数据集(RDD)[4],RDD是一种不可变的分布式数据集合,它可以将计算中间结果:保存在内存中以加速计算。Spark对于RDD有两种算子操作:Transformation(转换)和Action(行动),其中Transformation(如map ilter等)表示父RDD转换成子RDD是惰性执行的过程,直到有Action(如count、top等)操作时,才会触发Spark提交作业开始计算。RDD之间存在宽依赖(W ide Dependencies)和窄依赖(Narrow Dependencies)两种依赖关系,其中宽依赖指的是一个父RDD分区对应多个子RDD分区,如ReduceByKey、SortbyKey等,窄依赖指的是一个父RDD分区对应一个子RDD分区,如filter .union等。
Spark为常见的大数据存储技术提供了接口,如HDFS和NoSQL数据库。Spark功能组件较为完善,如图1所示,Spark.Core为核心组件,实现了常见的算子;SparkSQL[5]提供了类似SQL的结构化查询方式;SparkStreaming[6]使得Spark可以支持流计算;Mllib[7]提供了常见的机器学习算法库;GraphXI[8]提供了常见的图算法用于图计算。
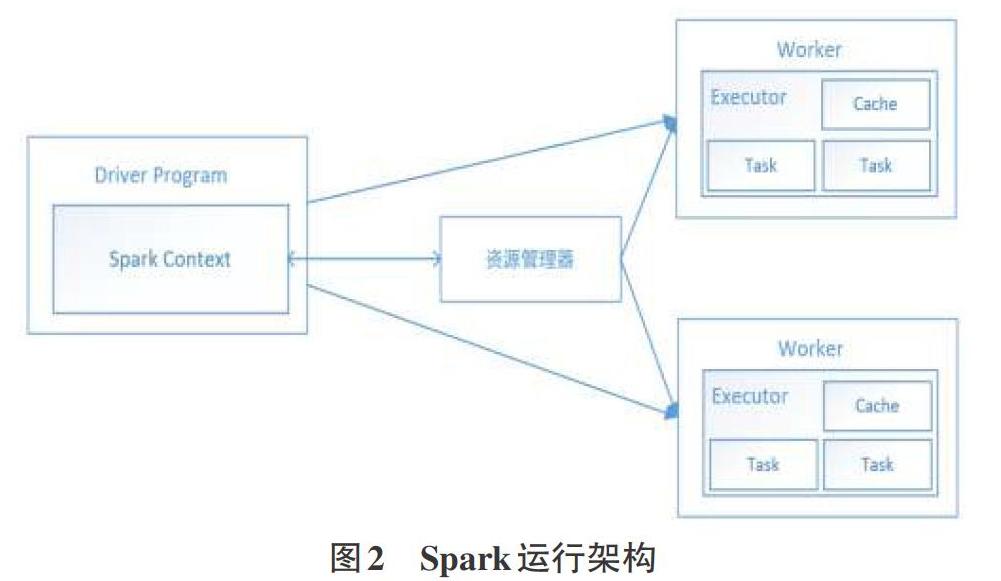
如图2为Spark运行架构,Driver所在节点为主节点,Worker所在节点为从节点。当用户使用spark-submit提交一个任务后,SparkContext首先会向Master进行注册并向资源管理器进行资源申请。资源管理器会根据参数配置,在各个从节点上启动一定数量的Executor,每个Executor都会占用一定的计算资源(如CPUCore、内存大小等)。申请到资源后,Spark会根据程序代码将RDD间的依赖关系形成有向无环图(DAG),然后划分为不同的Stage,每个Stage包含若千个Task,这些Task被分配到Executor中进行分布式计算。Task是最小的执行单元,等到所有节点上的Task执行完毕,Spark会将任务执行结果进行汇总,然后将结果输入到下一个Stage,直到代码逻辑执行完毕,得到最终结果并保存。
为了支持上述所有功能,Spark已经发展成为一个高效且负责的分布式计算系统,其为用户提供了约200个参数,这些参数决定了资源的分配,控制着任务的运行。国内外很少有针对Spark参数和性能之间作用关系的研究,对于前者,Spark官网为理解大多数参数的作用提供了宝贵的指导作用。由于参数众多,这些建议并不能使用户快速定位自己应该配置的参数。大多数参数我们可以直观地知道参数或多或少地影响任务执行效率和集群性能,然而熟悉不同参数对Spark任务的影响程度比仅仅知道存在影响更加重要。
在本文中,我们研究了不同Spark参数与任务运行时间之间的关系。对于每个参数,通过在相应的值范围内随机配置参数值,我们通过实验获取任务最短和最长运行时间,从而确定每个参数对任务的影响程度,确定其重要性。
2 实验分析
Spark有约200个参数,可以分为全局参数、环境参数、任务执行参数、序列化与压缩参数Shuffle行为参数、内存存储参数等,其中全局参数和环,境参数数量众多,但基本与性能之间无关,比如 name 信息、Java环境变量、HDFS地址信息等。本文结合Spark官网川的指南,选择了16个参数进行重要性研究:
(1)任务执行参数:spark.cores.max,spark.executor.cores,spark.de-fault.parallelism
(2)序列化与压缩参数:spark.serializer,spark.io.compression.codec,spark.rdd.compress,spark.shuffle.compress,spark.shuffle.spill.compress
(3)Shuffle 行为参数:spark.shuffle.manager,spark .shuffle.file.buffer,spark .shuffle.io.retry W ait,spark.shuffle.io.maxRetries
(4)内存存储参数:spark.executor.memory,spark.memory.fraction,spark.memory.storageF raction,spark.driver.memory
每个参数的取值范围在由于不同集群硬件资源的差异不尽相同,除去可选值为离散值的参数外,其余的参数我们通过算法2.1确定参数的取值范围。
本研究从大数据压力测试工具HiBench[9]中选取了3个有代表性的任务进行实验,包括Sort、K-Means和PageRank。对于每个选定的参数,我们通过随机参数生成器才参数范围内生成参数,为其执行上述3个Spark任务并获取平均运行时间。对于离散值的参数,我们选取每个可能取值进行测试,对于连续值的参数,我们为每个参数随机生成50个参数值进行测试,单个任务对应的一个取值情况下运行两次取平均运行时间。
本实验在参数取默认值情况下,Spark任务平均运行时间为62.92秒,如图3所示为每个参数在取值范围内对应的Spark任务最短和最长运行时间,实验结果显示spark.cores.max参数对任务运行时间影响最大,最长执行时间是最短执行时间约5.35倍。为了更好地评估参数对任务运行时间的影响程度,我们定义了公式2.1,其中tmax表示任务最大运行时间,tmin表示任务最短运行时间,t。default 表示任务默认运行时间:
通过公式2.1计算可知,所选取的16个参数对任务运行时间的平均影响程度impact为58.13%,其中参数spark.cores.max的impact值达到158.93%,对任务運行时间影响最大,参数spark.shuffle.io.maxRetries的impact值为14.62%,对任务运行时间影响最小。我们还可以计算获取任务执行参数、序列化与压缩参数、Shufle行为参数、内存存储参数的impact值分别为123.97%、31.47% .42.99%和57.22%。
3 结论
本文实验分析了Spark参数与任务执行时间之间的关系,研究了参数的重要性。实验结果表明不同参数对任务影响程度差异巨大,对Spark任务执行时间影响程度最大和最小的参数分别为spark.cores.max和spark.shufle.io.maxRetries。对于不同类型的参数,任务执行参数对Spark任务运行时间影响程度最高,其次是内存存储参数,接着是Shuffle行为参数,最后是序列化与压缩参数。本文对于Spark参数重要性的研究对于用户选择哪些参数进行配置优化具有很好的实用价值和指导意义。参考文献:
[1]Apache Spark,htp://park.apache.org/.
[2]White T.Hadoop:The definitive guide[M]." O'Reilly Media,Inc.",2012.
[3]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):.107-113.
[4]Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation.USENIX Association,2012:2-2.
[5]Armbrust M,Xin R S,Lian C,et al.Spark sql:Relational data processing in spark[C]//Proceedings of the 2015 ACM SIG MOD international conference on management of data.ACM,2015:1383-1394.
[6]Zaharia M,Das T,Li H Y,et al.Discretized streams:A fault-tolerant model for scalable stream processing[R].Defense Technical Information Center,2012.
[7]Meng X,Bradley J,Yavuz B,et al.Mllib:Machine learning in apache spark[J].The Journal of Machine Learning Research,2016,17(1):1235-1241.
[8]Xin R S,Gonzalez J E,Franklin M J,et al.Graphx:A resilient distributed graph system on spark[C]//First International W orkshop on Graph Data Management Experiences and Sys-tems.ACM,2013:2.
[9]Huang S S,Huang J,Dai J Q,et al.The HiBench benchmark
suite:Characterization of the MapReduce-based data analysis [C]//2010 IEEE 26th International Conference on Data Engineering Workshops (ICDEW 2010),March 1-6,2010.Long Beach,CA,USA.IEEE,2010.
[通联编辑:光文玲]
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国生殖健康(2020年4期)2021-01-18
中国生殖健康(2018年4期)2018-11-06
制导与引信(2017年3期)2017-11-02
唐山文学(2016年11期)2016-03-20
自动化博览(2014年12期)2014-02-28
汽车电器(2014年5期)2014-02-28
