
基金关联特征提取的大数据随机搜索算法及应用
2020-04-14 03:22袁先智刘海洋周云鹏严诚幸李欣鹏郭铁信钱国骐
管理科学 2020年6期
袁先智,刘海洋,周云鹏, 严诚幸,冯 驰 李欣鹏,李 波,郭铁信,钱国骐,曾 途
1 成都大学 商学院,成都 610106 2 广西大学 商学院,南宁 530004 3 中山大学 管理学院,广州 510275 4 成都数联铭品科技有限公司,成都 610041 5 中国平安财产保险股份有限公司 苏州分公司,江苏 苏州 215006 6 山东大学 中泰证券金融研究院,济南 250100 7 重庆理工大学 理学院,重庆 400054 8 中南大学 数学与统计学院,长沙 410083 9 墨尔本大学 数学与统计学院,墨尔本 VIC3010
引言
2016年9月11日,中国证监会颁布并实行《公开募集证券投资基金运作指引第2号——基金中基金指引》,为基金中基金(fund of fund,FOF)的市场化和规范化铺平了道路,进一步丰富了中国金融产品体系,为投资者提供更多的选择。FOF通过遴选优质基金构建基金池来实现提高收益、降低风险和降低费用的目的,因此如何选取优质基金成为构建FOF基金池的核心要素之一。从SHARPE[1]建立基于风险和收益的基金评价指标,到BARBER et al.[2]从基金自身以外的因素对基金业绩的影响的研究,以及GALAGEDERA et al.[3]建立的三阶段多维度基金绩效网络评估方法,已有研究都将挖掘基金业绩的有效信息作为重要的研究方向。基金市场的迅速发展,学术界和应用领域对基金绩效的探讨层出不穷。由于数据存储技术和网络技术的进步,金融科技领域的数据量级飞速增长。现有的社会网络中存在大量的信息,信息量大、密度低且来自不同维度,因此对于数据的融合处理变得尤为重要,而在大数据框架下从多维度数据提取出影响基金绩效强弱的特征和方法的研究还很少见。鉴于上述背景,本研究以2018年Wind基金评级无缺失的701个债券型基金作为样本,从基金自身、基金经理和基金公司3个维度出发,结合海量结构化和非结构化数据构建刻画基金特征的基础指标体系;特别是在5%(基于抽样样本2倍的标准方差)的误差容忍度下使用基于马尔科夫链蒙特卡洛的吉布斯抽样方法[4]对与基金业绩相关的特征进行深入挖掘,提出提取基金特征的有效方法,筛选出与基金业绩有关联的特征指标;利用比值比,即在逻辑回归模型中以自然对数为底数的回归系数的指数函数,对筛选出的特征指标进行相关性分类;使用受试者工作特征曲线[5]对筛选后的特征指标对基金业绩的预测能力进行系统分析。本研究提出在多种可以影响基金业绩的特征因子且存在观测样本数据不全的情况下,如何有效进行特征提取,实现构建FOF基金池的一般方法论,为支持业界针对FOF建立优质基金池提供了一种新的思路,也为更多学者探讨影响基金绩效的指标特征提供新的分析方法。
1 相关研究评述
SHARPE[1]建立了基于基金风险和收益的基金绩效评价指标——夏普比率,通过对美国34家共同基金的研究表明,基金绩效具有一定持续性,即基金现有业绩对基金未来业绩产生影响;VIDAL-GARCA et al.[6]基于时间序列模型对35个不同国家的共同基金样本的研究表明,基金的绩效表现在统计和经济意义上具有一定的持续性,特别是对于排名靠前和靠后的国家的共同基金。基金绩效表现也受到基金规模的影响,ELTON et al.[7]和YIN[8]的研究表明,基金规模过大会带来流动性问题等,从而侵蚀基金业绩;梁珊等[9]通过实验研究发现,开放式股票型基金规模对基金选股能力和基金平均风格收益存在倒U形的影响。关于基金费率对基金业绩影响的研究,一般认为较高的费用代表基金管理者个人投入多、实力强,基金投资管理能力也应该较好,投资业绩较佳。还有学者关注基金业绩与基金资金流量之间的关系以及对赎回异象进行分析,即基金的净资金流随基金业绩的增长而下降[10],但也有研究表明基金业绩与资金流量之间具有正相关关系[11-12]。
除了基金自身的因素外,基金经理的个人特质、职业特质和能力特质等也影响基金的业绩。基金经理的个人特质方面,BARBER et al.[2]的研究表明,男性基金经理比女性基金经理交易更加频繁,进而带来的交易成本的增加使男性基金经理的收益率较低;ESHRAGHI et al.[13]认为基金经理的自信与基金业绩存在倒U形关系;BODNARUK et al.[14]的研究结果表明,基金业绩与基金经理的风险厌恶程度存在相关性。基金经理的职业特质方面,HAN et al.[15]的研究表明团队管理的基金比单一经理的基金业绩更好;徐琼等[16]发现排名靠前的基金经理平均任职时间相对较长,反映出投资经验丰富的基金经理在提高基金业绩和风险控制方面具有一定的竞争优势。基金经理的能力特质方面,CHEVALIER et al.[17]采用横截面法研究基金经理个人特征对基金业绩的影响,在被解释变量中加入体现基金风格的代理变量,结果表明管理基金业绩与基金经理毕业院校和成绩高度相关,是否有MBA学历对基金业绩影响不显著。
基金公司特征对基金业绩也产生影响。基金公司经营规模反映了基金公司的整体实力,通常认为基金公司规模越庞大,实力越雄厚,旗下基金数量越多,基金整体水平可能越高,存在规模效应[18-19]。但ELTON et al.[7]认为基金公司规模越大,每只基金获得的支持和资源越分散,最终对基金产生负面影响。基金公司董事会的强监管也将给基金的业绩带来积极的影响[20],ADAMS et al.[21]的研究证实独立董事比例高的基金公司旗下基金的业绩表现更好。此外基金公司的历史业绩表现也对基金未来业绩产生影响,SIALM et al.[22]的研究证实经营不善的基金公司旗下的基金即使表现良好,也难以带来足够的新资金,同时面临极高的基金经理流失率。中国部分学者也专门对机构投资者的投资特征与企业和市场之间的联动关系进行研究分析[23-25]。
综合上述研究,刻画优质基金的指标可能来自于多个方面的多个特征,因此通过模型方法筛选优质基金面临可选特征维度过高的问题(即维数灾难),不同维度的特征给分析基金业绩带来难度。PREMACHANDRA et al.[26]利用二阶段DEA网络模型建立基金的绩效评估方法,GALAGEDERA et al.[3]进一步将评估方法拓展到三阶段DEA网络模型,但该方法仍然是基于多个指标的基金绩效评估方法,并未解决如何提取基金绩效关联特征。
在金融科技领域,对多维数据的特征信息(特别是包含非结构化数据特征信息的信息集)进行特征挖掘和提取的方法较少。基金的特征种类繁多,与基金相关的海量数据中包含非结构化的文本或图形特征,用传统方法难以在大量数据中进行有效的量化筛选等。本研究结合金融科技领域目前的数据现状,利用随机搜索算法提取基金绩效关联特征,是不同于已有研究的一个方向。在大数据随机搜索算法方面,AGRAWAL et al.[27]提出关联规则的概念和APRIORI算法,认为动机是针对购物篮分析问题。但在搜索关联规则空间时要实现这些算法在计算上非常困难,规则空间随着特征数的增加呈指数级扩大。之后诸多学者都对关联规则挖掘问题进行了大量的理论探索、算法改进和设计,特别是基于随机搜索方法及相关的应用方面做了许多工作,如在吉布斯抽样方法的研究和应用方面,除GEMAN et al.[28]、SCHWARZ[29]和QIAN et al.[30]进行了一系列基础性工作外,QIAN et al.[31]提出基于吉布斯采样构建的算法,在不损失信息的情况下大大减少了后续挖掘的规则空间,并在之后利用基于吉布斯抽样方法,针对贝叶斯多变点问题进行研究。另外,GLASSERMAN[32]利用马尔科夫链蒙特卡洛方法在计量金融方面进行了大量的应用研究,NARISETTY et al.[33]探讨一种用于支持模型选择的一致可伸缩吉布斯抽样算法。但是比较全面的、基于随机搜索方法对影响基金业绩的关联特征指标方面的系统性研究和方法目前并不多,特别是在大数据范畴下以多维度数据信息为出发点,并在设定控制误差容忍度(如不大于5%)情形下,建立与基金业绩强弱关联关系的特征因子提取和分类的工作更是少见。因此,本研究希望找出影响基金业绩的特征因子的提取、筛选并分类的方法,将分类样本按相关性排序,从而基于FOF优质基金池,构建针对基金筛选的一般方法。
2 大数据随机搜索算法
2.1 基金业绩相关特征提取的基本思路
本研究的重点是建立针对影响基金业绩的主要特征指标的提取方法。需要指出的是,提取影响基金业绩的特征不是基于传统计量回归分析工具直接实现的,本研究要考虑存在多种可能影响基金业绩的特征因子,同时还面临样本观测量不足的客观现实困难,在这样的前提下,需要采用新的方法和路径实现特征提取。
通常情况下,假定有M个可能影响基金业绩的变量,最基本的筛选方法是考虑所有可能的组合情形。但对这种考虑所有可能组合的方法,即使只考虑线性组合,也至少有2M次的判断处理,这就是典型的NP问题[34]。另外,如果使用统计回归分析方法,可能出现建模时支持M个自变量的统计推断模型方法面临样本观测量不足的问题,特别是大数据场景下海量数据与有限样本观测量之间的矛盾。为了解决NP问题和样本观测量不足的困难,从20世纪50年代开始,在马尔科夫链蒙特卡洛模拟框架下的吉布斯抽样方法日趋流行和发展起来,其实质是通过随机搜索的思想[4],可以解决上面提到的NP问题以及样本观测量数据不足前提下的许多实践和应用问题。吉布斯抽样方法也在最近30多年中得到极大发展,如GLASSERMAN[32]的研究。
本研究在马尔科夫链蒙特卡洛框架下,利用吉布斯抽样方法建立影响基金业绩的特征因子的提取方法。假设任意一个变量是否与基金业绩存在关联性服从伯努利分布(仅包含存在关联性和不存在关联性两种结果),伯努利分布的参数可表示为一个变量与基金业绩存在关联的显著性(以下简称关联显著性)。为了计量关联显著性,首先,本研究随机从备选变量集合中选择一个子集I0进行建模,拟合基金业绩指标,本研究选择以Wind评级作为业绩评价标准;其次,采用AIC准则[35]或BIC准则[28]构造马尔科夫链蒙特卡洛中的状态转移概率,保证用于构建模型的特征子集始终能向拟合优度更高的方向转移,最终每一个变量被选入特征子集的概率(非条件概率)随着模拟次数的增加而稳定于一个特定的值,这个值即为各个变量关联显著性的理论值;最后,由马尔可夫链的性质可知,进行吉布斯抽样抽取的初始特征子集I0不会影响最终的模拟结果。同时,在特征因子与基金业绩是否存在关联性服从伯努利分布的假定下,为了使吉布斯抽样结果的误差不大于5%,本研究设定控制样本误差需要的随机抽样样本量为400,这就解决了特征空间复杂度高而且观测样本不足的问题,同时将NP问题通过吉布斯抽样方法中的随机搜索转化为多项式复杂度问题,从而减少计算的复杂度,即在观测样本数量有限的条件下,通过吉布斯抽样方法,基于AIC准则或BIC准则构造转移矩阵,对特征因子的所有情况(构建成的幂集)进行筛选,得出与基金业绩相关的特征集,基于比值比的指标分类方法,提高了指标的可解释性。
2.2 基于吉布斯抽样方法支持下的影响基金业绩的特征因子提取方法
影响基金业绩的因素非常多,如何在指标复杂、观测数据有限的前提下平衡模型的可靠性和可解释性,是一个比较困难的工作。QIAN et al.[30]首次在特征挖掘过程中使用吉布斯抽样方法,给出大数据框架下进行特征筛选的方向。本研究采用的基金业绩特征筛选方法正是在这一方法基础上,使其能够对金融场景做出实时、准确、有效和可解释的全面分析。在此基础上,建立一种基于马尔科夫链蒙特卡洛框架下的吉布斯抽样算法,以比值比作为验证标准参数,实现基金绩效关联特征的提取和分类,从而支持FOF基金池的构建。提取影响基金业绩的特征因子的主要流程如下:
第1步 建立基准模型,构建初始特征集合。
在筛选特征之前,根据基金的三分类确定基础模型,本研究基于Softmax函数建立评价基金的模型,基于模型初步筛选部分特征作为初始特征,随机抽取一个特征子集,即
I0=(0,1,1,…,0)∈{0,1}k
(1)
其中,I0为在初始特征中随机抽取的一个特征子集,k为在初始特征样本中存在的特征数。初始模型中系数不为0的特征记为1,系数为0的特征记为0。
第2步 基于AIC准则和BIC准则构建特征分布函数,即构建支持随机抽样的标准。
PC(js=1|J-s)
(2)
其中,PC(js=1|J-s)为概率分布函数,s为特征数,js为第s个特征,J-s为除第s个特征之外全部特征的组合,IC为J-s的确定值。由于特征的复杂性,本研究无法直接构建概率分布函数PC(J),因此尝试基于AIC准则和BIC准则构建指标转移概率函数PAIC(J)和PBIC(J),分别基于AIC准则和BIC准则构建两组条件概率分布函数,目的是在最后一步中比较两者的模型效果。条件概率分布函数可表示为
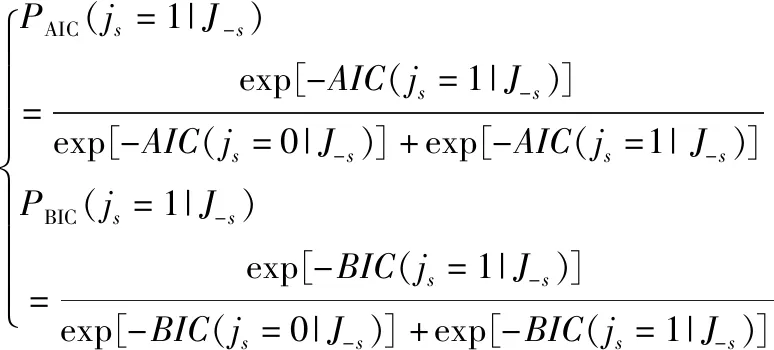
(3)
第3步 确定抽样次数,若进行有限次重复抽样关联显著性的误差,可根据(4)式进行计量,即

(4)
其中,Std(p)为特征频率的标准差;p为某一变量的关联显著性;t为抽样次数,t=0,1,2,…,M。在样本特征的吉布斯抽样中假定所有样本特征服从伯努利分布,可以表示抽样误差。
若按照2-sigma准则控制模拟误差,为了保持提取特征的显著性,通常需要使模拟误差控制在0.05以内,则由(4)式可知需要进行400次抽样。这里,n-sigmia等于n个单位的标准差Std(p),n=1,2,或3。若选用更严格的误差控制准则(如3-sigma准则)或缩小误差控制范围,则需要更多的抽样次数。本研究使用2-sigma准则控制模拟误差,可以在保证显著性的同时降低计算的复杂度。
确定好最大抽样次数M后,进行吉布斯抽样,具体过程如下:
(2)对s循环进行抽样,s=1,2,…,k,有

(5)
(3)得到(J(1),J(2),…,J(M))。
第4步 计算特征频率,并筛选入模指标。

第5步 构建最终分析模型并进行模型效果测试。
选择关联显著性大于某个设定水平(根据实际工作的需要设定)的特征指标建立逻辑回归模型,分别在训练集合和测试集合中检验模型的效果。比较使用AIC构建分布函数的模型与使用BIC构建分布函数的模型结果,根据比较结果确定最优模型。
3 基金业绩关联的特征刻画
3.1 基金样本的选取和划分
由于基金业绩与市场整体走势相关,同时考虑到数据样本的丰富性,本研究选取2018年Wind基金评级无缺失的701个债券型基金作为样本,用于特征挖掘和分类模型构建。训练集和测试集的样本中好、中、坏3个等级的样本比率相同,并按照3:1的比例将总样本划分为训练集(526个样本)和测试集(175个样本)。在本研究的分析中,训练集将用于特征挖掘、模型的参数估计和模型效果的初步检验,测试集将用于模型效果的最终检验及坏样本的阈值划定。
通常从基金的投资收益和风险角度测量基金业绩。综合考虑基金投资收益和风险的指标中较为经典的3个指标为詹森指数、夏普比率、特雷诺比率[36-37]。目前多家评级机构和学者都提出了较新的业绩评价体系和方法,这些方法基本都是对传统经典方法的拓展和改进。为了使分析结果符合中国市场的一般规律,本研究根据基金业绩将基金分为好、中、坏三档,这3个档次是基于万得资讯提出的Wind基金评级给出。Wind基金评级建立在投资者风险偏好基础上,通过投资者的风险厌恶指数对基金收益进行调整定义万得风险调整收益(简称WRAR),再根据WRAR的相对排名将基金划分为5个等级,即一星至五星,一星最差,五星最好。本研究基于Wind评级对基金业绩进行重新划分,将评级为一星的定义为坏基金,将评级为二星和三星的定义为中基金,将评级为四星和五星的定义为好基金。
3.2 初始特征指标池的建立
通过梳理已有研究可以发现,基金本身、基金经理、基金公司等维度的特征将对基金业绩产生影响。基金本身层面,如前文所述,基金历史业绩能够对基金未来业绩产生影响,基金规模过大带来流动性问题等,从而侵蚀基金业绩。因此,基金的投资结构、风险指标和其他关联特征也有可能对基金业绩产生影响[38],特别是面临行情变化时前两者对基金业绩的影响就显得较为重要。从基金经理的角度出发,赵秀娟等[39]认为基金经理的经验和能力与基金业绩之间存在正相关关系。所以,本研究将基金经理的个人特质、职业特质和业绩指标纳入与基金业绩有关联的特征指标池。
通过对基金业绩相关特征的梳理,结合业界的实践经验,本研究将基金公司维度特征从经营规模、财务指标、经营能力、基本信息和股权结构等方面进行初始特征分类,形成基金初始特征。基于3个维度的基金初始特征见表1,有58个3级指标的特征都有可能对基金业绩产生不同程度的影响,每个指标包含不同基金、不同时间段的数据,最终形成初始指标数据池。
3.3 基金关联特征的提取和解读
本研究基于基金业绩较好和较差的特征分类,第1步采用吉布斯算法从58个初步特征中筛选出36个与基金业绩之间存在显著关联性的特征。第2步使用这些特征建立三分类逻辑回归模型,以逻辑回归模型中各个特征的比值比作为测量特征与基金业绩的关联显著性的标准。然后与使用全部58个特征构建的三分类逻辑回归模型进行对比,以验证提炼出的特征结果的表现程度。
应用比值比对特征与基金业绩(好或者不好)的关联性强弱进行定义,规则如下:
(1)较强关联。对应特征的比值比小于0.800或大于1.200时,此特征为与基金业绩(好或者不好)的关联性较强;

表1 基金初始特征Table 1 Initial Features of Funds

续表1
(2)一般关联。对应特征的比值比大于等于1.100且小于等于1.200或比值比大于等于0.800且小于等于0.900时,此特征为与基金业绩(好或者不好)的关联性一般;
(3)较弱关联。对应特征的比值比大于0.900且小于1.100时,此特征为与基金业绩(好或者不好)的关联性较弱。
基于上面的特征分析和对应好坏基金的特征刻画,本研究根据36个特征与基金业绩的关联性强弱划分为强相关特征、一般相关特征和弱相关特征3类,分类结果见表2。
由表2可知,①强相关特征有16个,它们对基金业绩较好和较差都呈现出较强关联性;②一般相关特征有9个,它们包含两类:第1类为对于基金业绩较差的呈现较强关联而对基金业绩较好的呈现出弱关联的特征,第2类为在基金业绩较差和较好中都呈现出一般关联的特征;③弱相关特征有11个,它们对基金业绩较差的呈现出较弱关联。
需要说明的是,本研究中强相关特征、一般相关特征和弱相关特征的定义是基于特征与基金业绩的关联性强弱定义的,因此使用相关性命名,从而与上文中使用的关联性区别开来。
对基于吉布斯抽样得到的特征进行分析可以发现,强相关特征与一般相关特征都能从基金评价的业务逻辑层面得到解释。例如,16个强相关特征和9个一般相关特征从投资表现、风险管理、团队能力和公司经营状况4个方面反映了基金业绩。
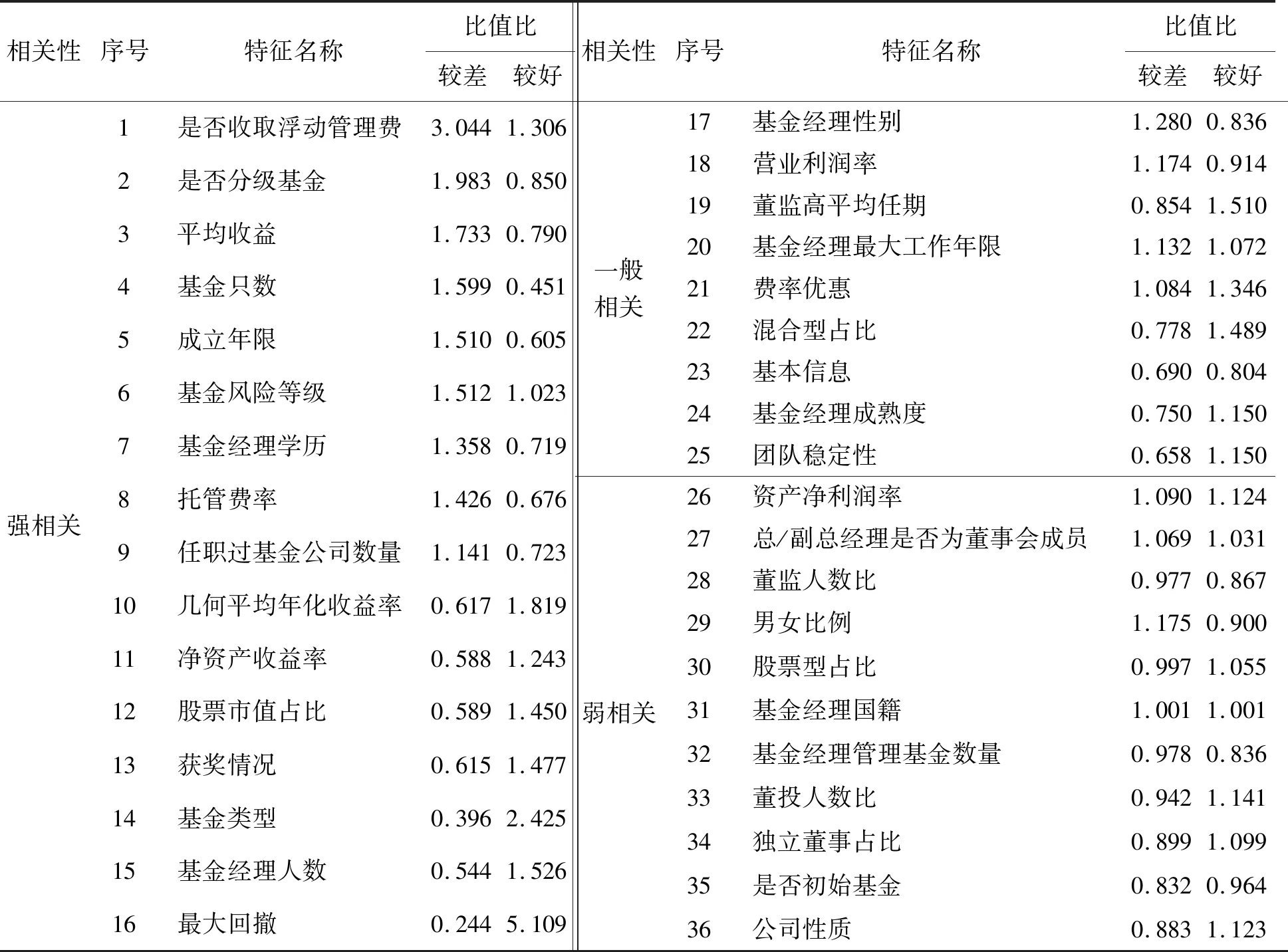
表2 特征提取结果Table 2 Results for Features Extraction
(1)投资表现。投资表现是能够最直接从收益率中反映的,平均收益率和几何平均年化收益率反映基金的投资表现,净资产收益率反映基金在投资过程中对于杠杆的运用能力。
(2)风险管理。测量基金管理团队成绩的一个重要标准就是最大回撤,它体现了管理团队对于风险的控制能力。在本研究的初始特征池中,基金风险等级也是一个能有效反应风险管理能力的特征。在中国证券投资基金大致可以分为股票型、债券型和混合型,仅有混合型基金能够有效地利用各种不同的资产进行风险分散和对冲,因此基金类型也能够有效反映基金的风险管理能力。
(3)团队能力。投资表现和风险管理可以有效反映基金管理团队的能力,但这两个方面都要经过一段时间的任职才能观测到。基金经理的个人经历可以在其上任之前为我们提供关于管理团队能力的信息,基金经理学历和基金经理最大工作年限两个指标从定性角度为刻画基金经理能力提供了信息,学历较低和工作年限较短且风格青涩的基金经理很难领导一个优秀的基金管理团队;基金经理曾任职基金公司数量越多,通常意味着其工作更换比较频繁,有可能显示出其工作能力难以领导基金管理团队;团队稳定性能够为投资策略和风险管理流程带来更好的一致性。
(4)公司经营状况。基金团队的表现可以反映出公司的经营状态。董监高平均任期和成立年限反映基金公司的日常经营的稳定性;公司获奖较多和托管费率较低反映基金公司在行业中的口碑和商务运营能力较强;基金公司旗下基金数量多意味着基金公司规模较大,也能反映出基金公司经营状况的稳定性;浮动管理费率和费率优惠反映基金团队的薪酬激励方式,浮动管理费率和费率优惠越高基金管理团队的收入与其投资表现的关系越密切,这也反映了基金团队对于自身能力的自信。
4 实证分析
4.1 数据使用说明
本研究使用逻辑回归模型对测试集中较差的基金检验特征筛选效果。首先,使用筛选得到的36个特征进行逻辑回归建模,并与使用初始特征集中所有58个特征建立的逻辑回归模型的效果进行比较,再比较使用不同的数据处理方法和建模方法的模型效果,从而找出最佳的建模方案。
对于分类模型,本研究希望其能在准确预测出坏样本的基础上尽可能少地将好样本归类为坏样本,因此使用ROC曲线分析进行模型检验。
4.2 数据测试结果
本研究使用假阳率(false positive ration,FPR)为0.100和0.200时的真阳率(true positive ratio,TPR)测量模型效果,将其分为6个级别的分类标准,见表3。

表3 ROC分类标准Table 3 ROC Standard of Classification
测试集的模型检验结果见表4,模型1~模型4分别表示使用相应的特征集合及建模方法得出的模型效果,4个模型的ROC曲线见图1(a)~图1(d)。图中,横轴为假阳率,表示非坏样本被归类为坏样本的比率;纵轴为真阳率,表示被识别出的坏样本在所有坏样本中所占比例。由图1可知,模型1训练集的ROC曲线表现得很好,但测试集的ROC曲线表现与训练集的ROC曲线有较大差距,且不如模型2测试集合的ROC曲线,说明模型1的预测能力不佳,可能存在过拟合现象。模型2~模型4各自训练集和测试集的ROC曲线表现较为一致,反映出模型能够有效刻画基金的表现,模型3和模型4有更好的刻画能力。

表4 测试集的模型检验结果Table 4 Model Validation Results for the Test Set

(a)模型1
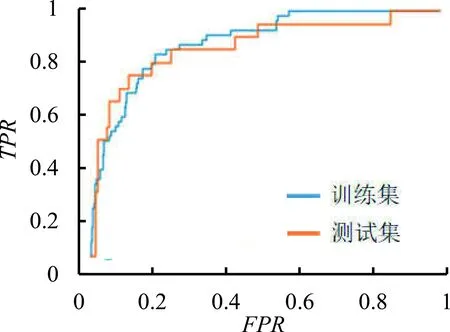
(b)模型2
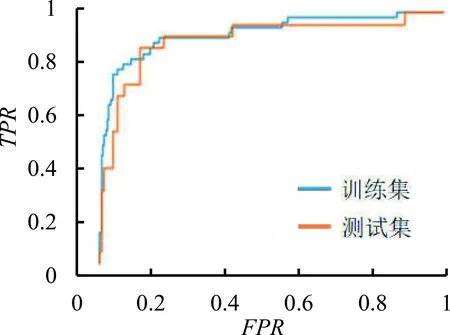
(c)模型3

(d)模型4
由表4可知,模型2在假阳率为0.100和0.200时,其真阳率都比模型1高,证明风险基因筛选得到的36个特征能够有效刻画基金的表现,但模型效果仍未达标。模型3在假阳率为0.100和0.200时,其真阳率都比模型2高,模型效果达到Ⅱ-a级标准。由此可以看出,对筛选特征中的结构化数据进行归一化处理比对所有特征都做标签化处理更有利于建模,说明针对多维数据进行特征提取再进行分类对模型效果具有显著的提升。模型4在假阳率为0.100和0.200时,其真阳率都比模型3低,模型效果达到Ⅱ-b级标准,由此可以看出,二分类逻辑回归对坏样本的识别效率略优于三分类逻辑回归。
综上所述,对比模型1与模型2的效果可知,本研究用大数据特征提取方法得到的特征子集能够更有效地识别较差的基金。对比模型2与模型3的效果可知,对结构化数据进行归一化处理,对非结构化数据进行标签化处理,模型检验效果有非常显著的提升。对比模型3与模型4可知,在对某一类(较差)基金进行识别的建模工作中,二分类逻辑回归与多分类逻辑回归模型的效果差异不大,在本研究中二分类逻辑回归因其计算复杂度较低而体现出优势。
本研究在评价模型时已经确定了对假阳率的容忍度为0.200,则可以按照假阳率为0.200时对应的逻辑回归概率设置判定的阈值,阈值设定结果见表5。
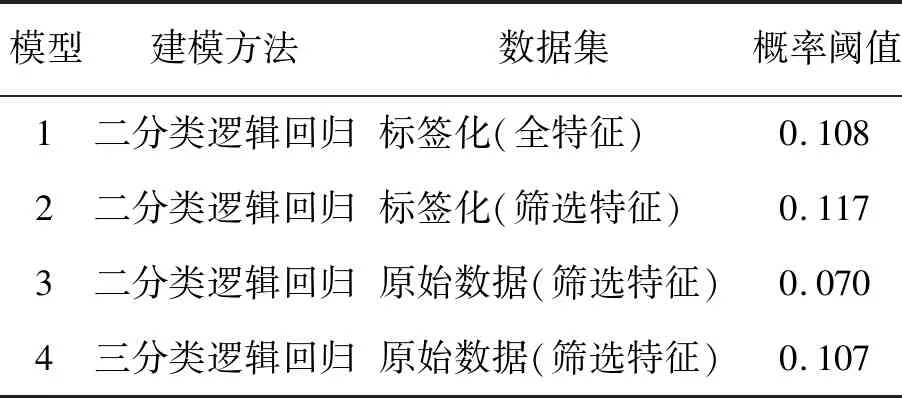
表5 逻辑回归概率阈值Table 5 Threshold of Logistic Regression Probability
根据4个模型的ROC表现,当模型的假阳率控制在0.200以内,使真阳率达到最大时的概率阈值都在0.100左右。
4.3 稳定性检验
本研究使用AIC准则和BIC准则构建马尔科夫链筛选特征,将按比值比分类后的结果进行比较。使用AIC准则和BIC准则进行特征筛选的流程与上文相同。
使用AIC准则进行特征筛选得到37个特征,经过比值比分类,有20个特征与基金业绩强相关,有9个特征与基金业绩一般相关,剩余8个特征与基金业绩弱相关,特征筛选的结果见表6。
使用BIC准则进行特征筛选得到18个特征,经过比值比分类,有10个特征与基金业绩强相关,有5个特征与基金业绩一般相关,其余3个特征与基金业绩弱相关,特征筛选的结果见表7。
与使用逻辑回归模型预测准确性评分筛选特征的结果(表2)相比,使用AIC准则进行特征筛选得到的强相关特征更多,而使用AIC准则和BIC准则进行特征筛选得到的弱相关特征都比逻辑回归模型进行特征筛选得到的结果要少。
由表4可知,使用筛选后的特征子集,并对其中的结构化数据进行归一化处理,对其中的非结构化数据进行标签化处理后,可以使逻辑回归模型对坏基金的识别效果达到最佳。使用AIC准则和BIC准则进行特征筛选得到的强相关和一般相关特征进行二分类逻辑回归建模。建模方法和模型评价标准与前文相同,模型回归结果见表8,ROC曲线见图2。
由图2可知,模型5和模型6各自训练集与测试集的ROC曲线表现较为一致,模型对基金的表现均有较好的刻画能力,且用AIC特征筛选准则的模型6的ROC曲线优于用BIC特征筛选准则的模型5,并且当假阳率为0.200时的真阳率优于模型3。使用BIC准则进行特征筛选的特征子集中包含的特征数较少,所以拟合效果劣于模型3和模型6。综上可知,使用AIC准则进行特征筛选也可以得到较优的模型效果。
5 结论
本研究基于影响基金业绩的多维度数据信息构建基础特征池,通过吉布斯抽样实现多维数据信息下的有效特征提取方法,并运用逻辑回归模型,通过比值比进一步对有效特征进行相关性分类,建立与基金业绩相关性强弱排序的特征集,并用于对基金业绩的预测。
研究结果表明,基金业绩可以通过投资表现、风险管理、团队能力和公司经营状况4个方面进行比较全面的刻画。
(1)投资表现刻画特征。平均收益率和几何平均年化收益率刻画基金投资表现的强关联特征,净资产收益率是刻画基金在投资过程中对于杠杆的运用能力的强关联指标。
(2)风险管理刻画特征。测量基金风险大小的一个高度关联的特征指标是最大回撤,它体现了管理团队对于风险的控制能力;另外,基金风险等级也是一个能有效反映风险管理能力的特征。
(3)团队能力刻画特征。投资表现和风险管理两个方面可以有效反映基金管理团队的能力,但这两个方面都要经过一段时间的任职才能观测到,而基金经理个人经历、基金经理学历和基金经理最大工作年限是刻画基金经理团队能力的强关联指标。
(4)基金所在公司经营状况刻画特征。基金公司的经营状况是其下属基金团队表现的基础,董监高平均任期、成立年限、公司获奖和托管费率较低是刻画基金公司在行业中的口碑和商务运营能力较强的强关联特征,基金只数多少、浮动管理费率和费率优惠可以刻画基金管理团队的收入与其投资表现的紧密关系和团队自信能力。
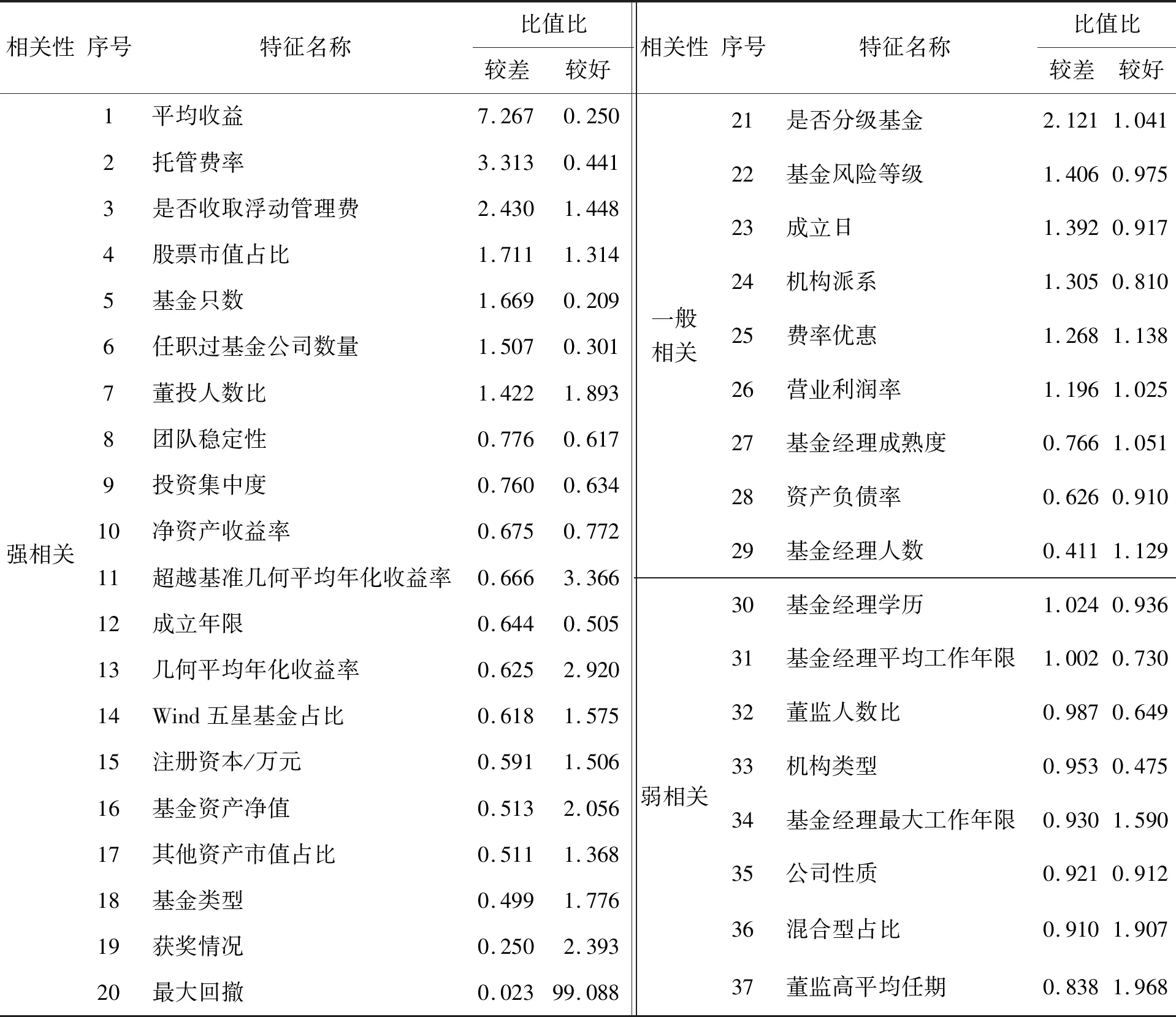
表6 使用AIC准则进行特征提取的结果Table 6 Results for Feature Extraction(AIC)
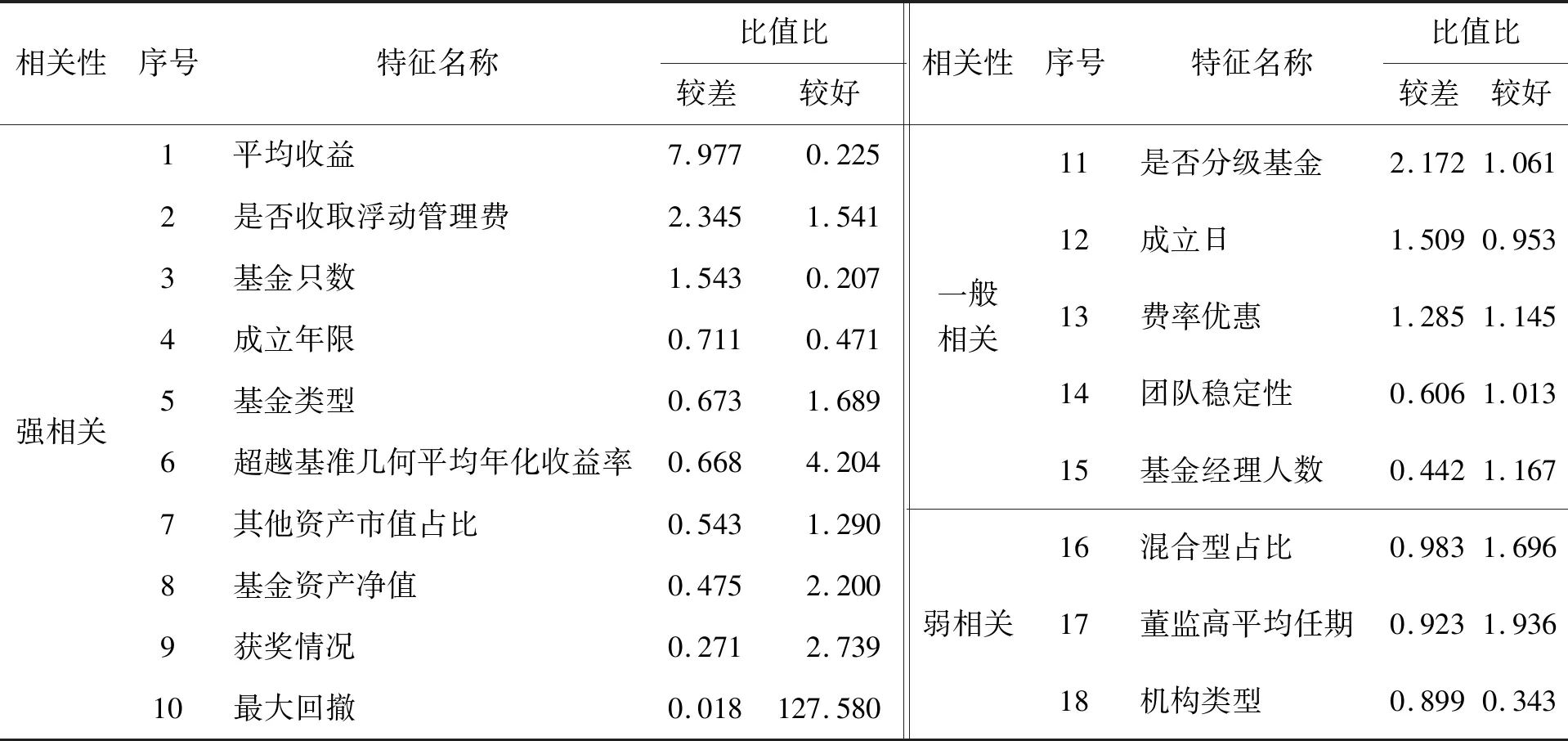
表7 使用BIC准则进行特征提取的结果Table 7 Results for Feature Extraction(BIC)

表8 测试集的模型检验结果(AIC准则和BIC准则)Table 8 Model Validation Results for the Test Set(AIC and BIC)
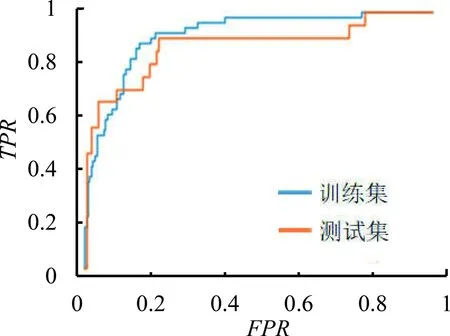
(a)模型5
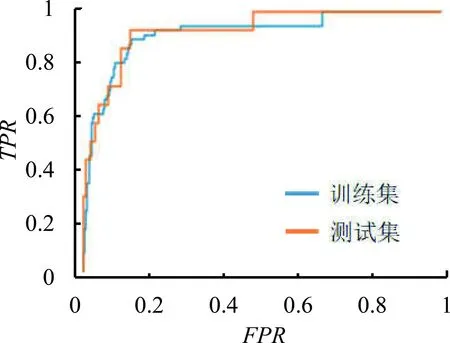
(b)模型6
本研究基于AIC准则和BIC准则建立的随机搜索方法均能对指标起较好的筛选作用。使用AIC准则进行特征筛选得到37个特征,经过比值比分类,有20个特征与基金业绩强相关,有9个特征与基金业绩一般相关,剩余8个特征与基金业绩弱相关;使用BIC准则进行特征筛选得到18个特征,经过比值比分类,有10个特征与基金业绩强相关,有5个特征与基金业绩一般相关,其余3个特征与基金业绩弱相关。
在模型效果方面,使用AIC准则和BIC准则进行特征筛选得到的强相关和一般相关特征进行二分类逻辑回归建模并对基金业绩进行预测,利用特征筛选后的指标建立的模型能够较好地预测未来基金业绩的好、坏,同时基于BIC准则的过拟合风险更低。本研究方法为金融科技领域如何处理海量的非结构化信息、实现有效的特征提取提供了一种思路和框架,在大数据的5V特征中如何有效处理数据并形成支持实践的运用上提供了完整的案例;本研究提出的基于大数据随机搜索算法的特征提取方法框架下对刻画基金业绩特征的特征提取方法,不仅是理论上的创新,同时其结果可以用于指导业界实践,如基金风险管理和相关的资产投资业务的实践工作。
本研究建立了与基金业绩相关性强弱的特征集,但依据特征集构建形成不同的FOF,对其业绩好坏的分类对比的实证研究还有待进一步展开,这部分内容还需要更为深入的后续工作。
猜你喜欢
证券市场红周刊(2021年46期)2021-11-27
中国注册会计师(2021年10期)2021-11-22
当代陕西(2019年15期)2019-09-02
证券市场红周刊(2018年38期)2018-05-14
证券市场红周刊(2018年10期)2018-05-14
证券市场红周刊(2018年5期)2018-05-14
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
消费导刊(2014年12期)2015-02-13
棋艺(2014年7期)2014-09-09
