
井下WLAN位置指纹定位中改进区域划分方法研究
2020-04-13 06:28:08宋明智钱建生胡青松
工矿自动化 2020年3期
宋明智,钱建生,胡青松
(中国矿业大学 信息与控制工程学院,江苏 徐州 221116)
0 引言
矿井人员定位是煤矿安全生产与管理的重要研究课题之一[1],井下作业人员位置信息的记录与监测保证了煤矿生产调度的高效性以及井下事故救援的有效性。近年来,电子信息技术、计算机网络技术和移动互联技术的快速发展为井下人员定位课题的研究与创新提供了必要的技术支持[2-3]。RFID(Radio Frequency Identification)、ZigBee、WiFi等技术都已在井下人员定位课题中有相应的研究与应用[4]。在上述定位技术中,以WiFi技术为基础的井下WLAN(Wireless Local Area Network)位置指纹人员定位方法因其扩展性强、易维护、用户接入量大、覆盖范围广、成本较低、传输速率高、保密性好、抗干扰能力强等[5-6]特点,有着广泛的应用前景[7]。
现阶段,对于井下WLAN位置指纹定位的研究主要集中在位置指纹样本降噪、无线接入点最优选择[8]、在线位置指纹匹配算法[9]等方面,而对于实际应用中定位效率提升的研究却很少。一般应用场景中,由于井下定位区域较大,如果在线定位阶段使用全局位置指纹数据库进行遍历求解,不仅很大程度上会影响定位系统的运行效率,同时也有可能引入不必要的噪声干扰。目前的解决方案是将定位区域进行合理划分,将位置指纹数据库分割成与定位子区域对应的子数据库,用于子区域粗定位和位置指纹精确匹配[10]。经典的位置指纹定位系统中,主要是通过聚类算法来实现位置指纹样本的整体性划分。常用的聚类算法包括K均值法(K-Means)、模糊C均值法(Fuzzy C-Means,FCM)[11]和放射传播法(Affinity Propagation, AP)[12]等。上述聚类算法虽然在位置指纹样本的划分上有较好的性能表现,但只是针对接收信号强度(Receive Signal Strength,RSS)的统计分布特性进行聚类划分,并没有充分考虑到奇点问题[13]。因此,本文提出了一种基于类关系的K-Means(Class RelationshipK-Means,CRK-Means)算法,用以解决位置指纹数据库聚类划分过程中的奇点问题。对聚类划分后的定位区域一般采用随机森林(Random Forest,RF)算法进行粗定位,以降低系统资源消耗,提升定位效率。但传统RF算法中决策树总数和参考点特征数的取值来自经验数据[14],并不具备普适性。对此,可以考虑将遗传算法(Genetic Algorithm,GA)与RF算法相结合,通过GA算法的选择、交叉和变异操作求解RF算法中决策树总数和参考点特征数的最优取值。实验结果表明:与其他几类聚类算法相比,CRK-Means算法较好地解决了奇点问题,并在提升定位精度的同时,改善了实时定位的效率。而GA-RF算法对于RF算法中决策树总数和参考点特征选择数的取值有着更好的优化效果,使得井下子区域的粗定位更加准确。
1 CRK-Means算法
1.1 奇点问题
位置指纹数据库聚类划分的奇点问题主要是指经聚类划分的某些参考点虽然在RSS特征上属于某一个聚类空间,但这些参考点所在实际物理位置却不属于该聚类空间对应的物理空间。奇点问题会直接导致某些位置指纹子数据库的RSS样本缺失或误归类,最终影响人员定位的精确性。对于奇点问题,研究人员也给出了不同的解决方案,比如忽略这些奇点位置并删除对应位置上的参考点,或者人为调整奇点的所属类别[15]。不过这些解决方案有可能会使已分类的聚类中心发生变化,从而影响定位性能。而且定位区域越大,这些解决方案的效果越差。为了解决上述问题,本文提出了CRK-Means算法。该算法在K均值的基础上结合自组织迭代分析算法(Iterative Self-Organizing Data Analysis,ISODATA)[16],并以Fisher准则[17]、类内离散度和类间离散度为限制条件,通过聚类融合和奇点分离过程,最终完成定位区域的合理划分。
1.2 CRK-Means算法原理
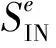
(1)
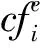
(2)
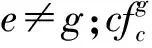
根据类内离散度和类间离散度的定义,则区域划分的目标函数为
(3)
式中Ce为第e个聚类类内离散度与类间离散度的比值。
使式(3)最小化的聚类划分就是理论上的区域划分,不同子区域的划分越明显,则区域定位的判别特征越明显。
采用经典凸优化方法求解式(3)有可能难以满足区域参考点物理位置连续的限制条件,因此,可以采用含有聚合、分离过程的CRK-Means聚类算法求解式(3),具体的实现步骤如下:
步骤1:对位置指纹数据库进行1/2划分,即位置指纹数据库中每2个位置最近的参考点分为一个单位聚类,每个单位聚类的类属性用Ce表示:
(4)
式中K=N/2,N为参考点总数。如果N为奇数,则K=(N-1)/2,最后未分类的3个参考点分为一个聚类。
步骤2:预设聚类中心数(与目标聚类数不同)并计算聚类中心点。以Ce为聚类特征,依次计算每2个聚类特征Ce的相似度,第e个聚类与其他聚类间Ce的平均相似度为
e,f=1,2,…,K且e≠f
(5)
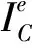
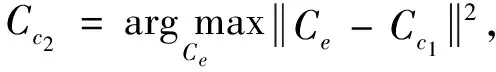
e=1,2,…,K且e≠c1
(6)
第3个聚类中心点通过计算剩下所有聚类中与Cc1、Cc2相似度最小的聚类求得。
e=1,2,…,K且e≠c1,c2
(7)
依次类推,可以求解出预设数目下的初始聚类中心点。
步骤3:聚类融合。初始聚类中心点求解完成后,将K个单位聚类根据Ce的相似度分配至对应的聚类中心。聚类融合后,融合的聚类对应的参考点也进行合并,且此时聚类数与目标聚类数相同。
步骤4:奇点分离。为了保证各聚类内参考点的连续性,给出聚类内参考点之间位置关系的限制条件:
(8)
式中:(xi1,yi1)和(xi2,yi2)分别为同一聚类e中参考点RPi1和RPi2的位置坐标,i1,i2=1,2,…,Ne;LLIM为聚类内部参考点距离阈值,由井下巷道定位环境和参考点采样密度决定。
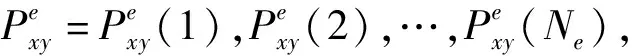
步骤5:判断聚类结果是否满足收敛条件,如果满足,则输出聚类结果,否则返回步骤2继续迭代执行。
2 基于GA-RF算法的井下子区域定位
使用CRK-Means聚类算法将井下定位区域进行划分后,定位区域中所有参考点被人为附加上所属类别的标签。该聚类划分过程可以看作是一种集成学习过程,井下子区域的定位可以利用类别标签并采用集成学习的方法来实现。本文采用的RF算法[14]就属于并行集成学习的一种。
2.1 RF算法
RF算法是指利用多棵决策树对样本进行训练和预测的一种集成分类器,其决策过程同Bagging[18]和Boosting[19]方法类似,是通过对每棵决策树的输出投票获得最终结果。与Bagging和Boosting方法不同之处在于RF算法会同时对样本及样本特征进行采集,并且无需剪枝(Pruning)过程[20]。由于RF算法引入了对数据项行、列的随机采样,因此较好地解决了过拟合问题,且对高维数据处理有一定的性能优势,适用于位置指纹数据库处理。
井下位置指纹定位问题中,使用RF算法实现子区域粗定位的主要步骤如下:
步骤1:初始化。假设子区域数量为K,定位区域参考点总数为N,AP(接入点)信号总数为R(各参考点的特征数为R),训练样本集选取的参考点数为Ne(Ne≤N),训练样本集选取的参考点特征数为Re(Re≤R),决策树总数为D。
步骤2:对于第p棵决策树,随机选择一组位置指纹数据库的聚类(包含Ne个参考点),并记录该聚类的类标签(类属性),同时记录位置指纹数据库中未被选中的剩余(N-Ne)个参考点用作训练测试集的误差测评。
步骤3:对于第p棵决策树中第q个节点,随机选取对应参考点的Re个RSS的特征向量,根据最优划分构建判决标准。最优划分可以根据聚类信息增益进行判断。
步骤4:q加1,如果q>Ne,则跳至步骤5执行,否则返回步骤3继续执行。
步骤5:p加1,如果p>D,则跳至步骤6执行,否则返回步骤2继续执行。
步骤6:决策树训练结束,集成分类器构建完成,此时的构建模型即为RF分类模型,可以用于井下子区域定位判别。RF分类模型的输入为用户随身携带的移动终端实时采集的来自所有AP信号的一组RSS序列(不在接收范围内的AP信号对应的RSS默认赋值为-80 dB·m),通过对模型中所有决策树的输出以投票方式获得最终的结果(目标聚类类别),即可判定用户所处井下子区域。
RF算法的优点:RF分类模型中的决策树都是并行处理生成的,且不依赖于上一时刻的运算结果,运算效率较高。但在不同巷道环境的区域中,RF算法的部分参数需要优化调整。对于不同巷道环境,应该设定相应的决策树总数D和参考点特征选择数Re,用以提升子区域定位的精度。
2.2 GA-RF算法
为了使RF算法具备一定的巷道环境自适应性,可以考虑使用GA算法对RF算法的参数进行自适应调整。GA算法源自对生物遗传进化规律的学习与总结,通过种群中个体的优胜劣汰机制保证种群始终具备更强的适应性。GA算法的优化过程主要包括选择、交叉和变异3个操作[21]。选择操作是在当前代的个体中选取一定数目的最优个体用于下一代种群的更新。交叉操作用于个体信息交换,从而提取和保留种群中个体的优良基因。变异操作是对种群中的少量个体进行基因突变,形成新的多样性个体。对于RF算法,其适应度函数为
(9)
式中δ为RF分类模型的误分概率。
3 实验及结果分析
3.1 实验环境
实验巷道环境平面图如图1所示,定位巷道中总共部署有10个矿用本安型无线交换机作为AP信号源,符号“+”代表预设参考点位置,参考点的设置密度按照巷道延伸方向上每隔1 m平均设置2个参考点,在巷道十字交叉位置处另外设置补偿参考点。由于在线定位阶段,位置指纹匹配过程使用的是参考点位置指纹样本数据的统计均值,所以,在位置指纹数据库的离线采集过程中,需要在每个参考点处采集1 000个位置指纹样本,以确保各参考点位置指纹样本的有效性。实验主要分为3组:
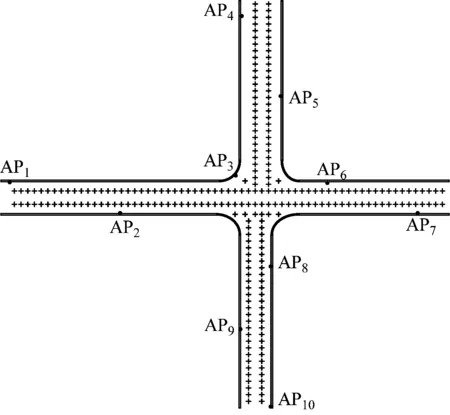
图1 井下子区域粗定位实验巷道平面图
实验1:完成K-Means算法、FCM算法和CRK-Means算法对定位区域聚类划分的对比测试。
实验2:完成GA-RF算法和RF算法对于CRK-Means算法聚类划分后的子区域粗定位的对比测试。
实验3:完成K-Means算法、FCM算法和CRK-Means算法定位精度的对比测试。
3.2 实验过程及结果分析
实验1分别使用K-Means算法、FCM算法和CRK-Means算法对井下定位区域进行聚类划分,并根据定位区域的结构特征,设置聚类总数为5。图2—图4分别给出了使用K-Means算法、FCM算法和CRK-Means算法时井下区域的划分结果,其中T1-T5表示划分后的5个子区域。3种算法在5个子区域的划分上区别很小,但K-Means算法和FCM算法的区域划分结果中都存在奇点,使用CRK-Means算法则有效解决了奇点问题。
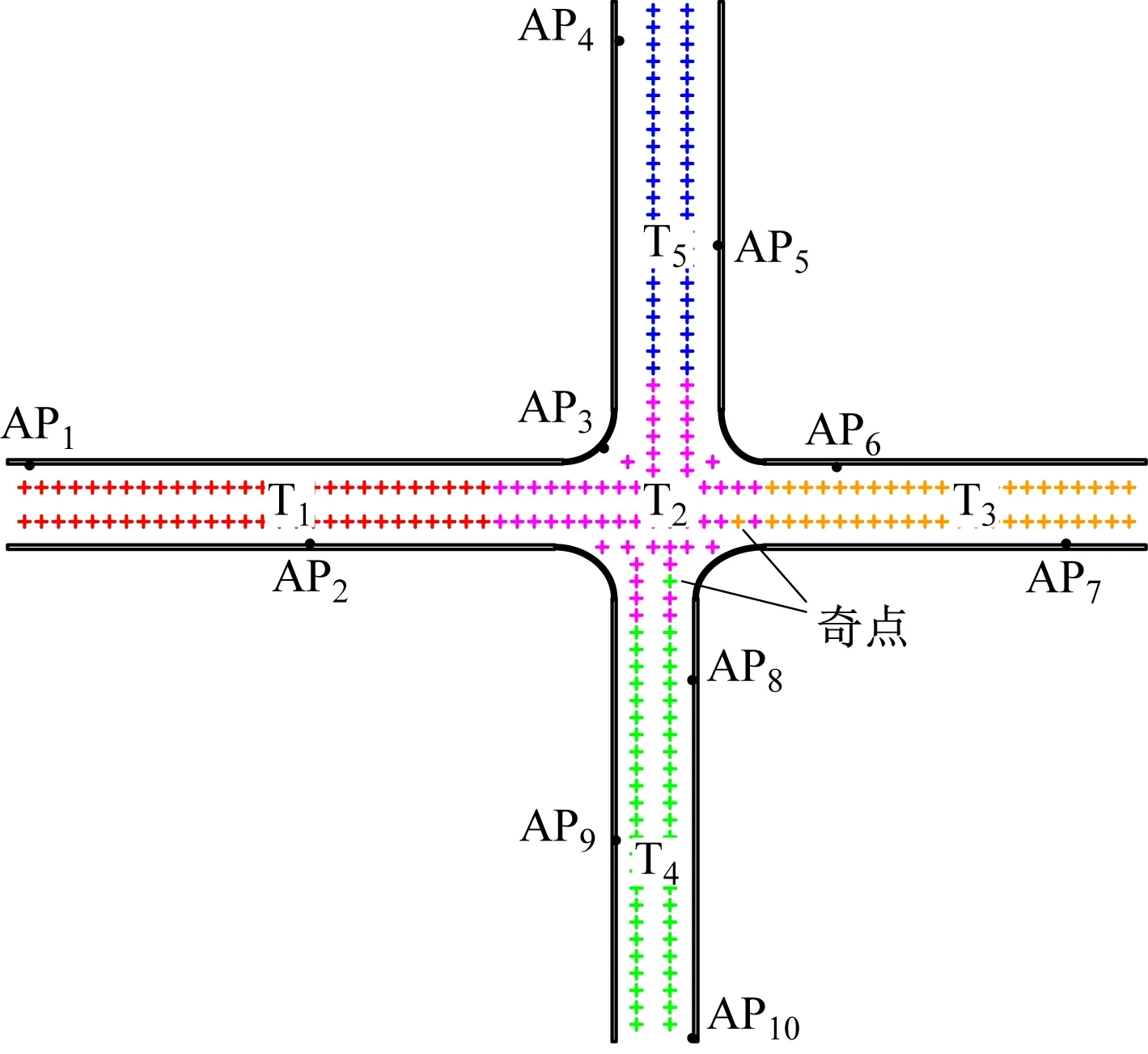
图2 K-Means算法聚类划分结果
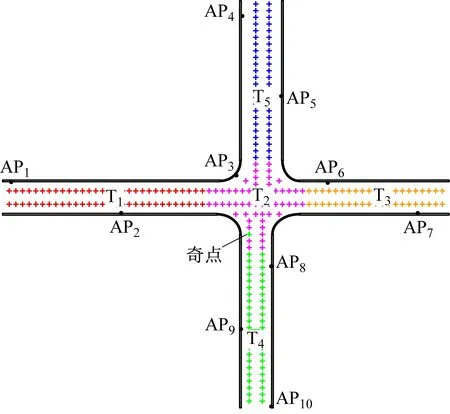
图3 FCM算法聚类划分结果
实验2在实验1的基础上,对CRK-Means算法聚类划分后的区域分别使用RF算法和GA-RF算法进行在线子区域粗定位,每组定位实验中在5个子区域中分别进行200次子区域粗定位。为了保证粗定位的实验效率,每个子区域中的粗定位位置都尽量靠近划分区域的区分处。子区域粗定位只对用户所在子区域进行判定,不对具体的位置进行估计。表1给出了子区域粗定位结果。RF算法子区域粗定位的平均正确率为94.7%,而将GA算法与RF算法结合后,RF算法中的决策树总数D和参考点特征选择数Re经过GA算法的自适应调整机制与当前的聚类划分更匹配,子区域粗定位的平均正确率为97.9%,因此,GA-RF算法在用户所处区域的实时判断上有着更好的决策机制。
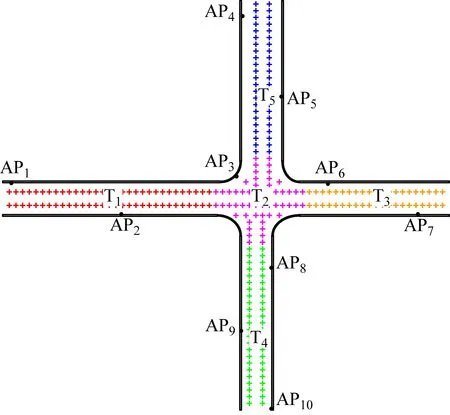
图4 CRK-Means算法聚类划分结果
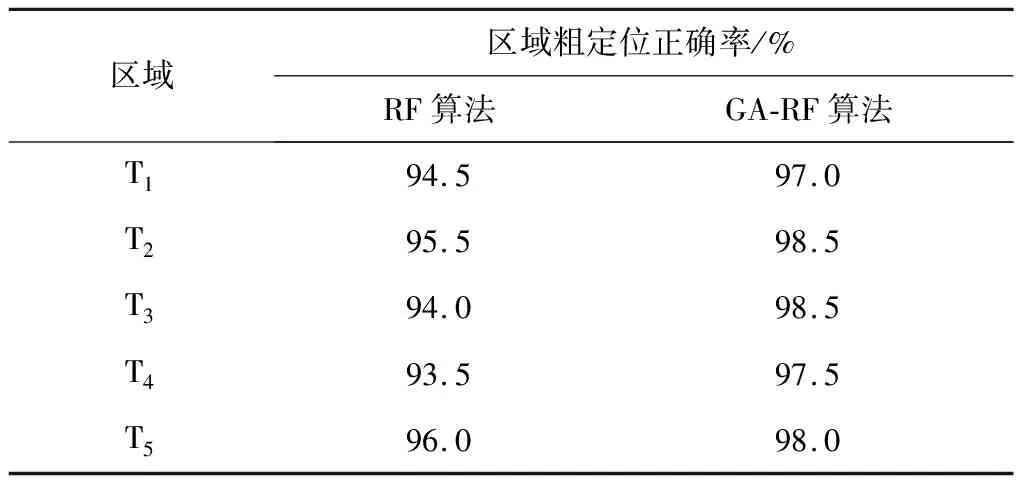
表1 RF算法和GA-RF算法对CRK-Means聚类划分区域粗定位结果
实验3对K-Means算法、FCM算法和CRK-Means算法聚类划分后的定位区域各自使用GA-RF算法先进行子区域粗定位,再使用WKNN(Weighted K-Nearest Neighbor)定位算法进行位置指纹精确匹配,每种聚类算法分别进行500次随机位置的定位。图5给出了3种聚类算法区域划分后的定位精度对比。因为CRK-Means算法有效地解决了奇点问题,使用GA-RF算法进行粗定位的精度得到了提升,进而使得位置指纹匹配更加精确。使用CRK-Means算法聚类划分后的位置指纹数据库进行WLAN井下人员定位时,置信概率大于90%的最小定位误差为3 m,而使用K-Means算法和FCM算法后的位置指纹数据库的定位结果,在置信概率大于90%时的最小定位误差为3.5 m。这说明CRK-Means算法在有效解决奇点问题的同时,对定位精度的提升也优于传统的聚类算法。

图5 基于不同聚类算法的定位性能对比
4 结语
在井下人员定位应用中,采用WLAN位置指纹定位技术一定会构建数量庞大的位置指纹样本。区域划分技术不仅大幅度减少了定位过程中位置指纹匹配的计算量,并且能够辅助提升定位的精度。CRK-Means算法的提出有效改善了传统聚类算法可能出现奇点的问题,GA-RF算法则较好地解决了RF算法在子区域定位过程中决策树总数和参考点特征数的最优取值问题。实验结果表明:GA-RF算法的子区域粗定位正确率为97.9%,要优于RF算法94.7%的子区域粗定位正确率。而使用CRK-Means算法聚类划分后的位置指纹数据库进行WLAN井下人员定位时,置信概率大于90%时的最小定位误差相比于K-Means算法和FCM算法提升了0.5 m,达到了3 m。CRK-Means算法在有效解决奇点问题的同时,对井下人员定位精度的提升也有一定的优势。
猜你喜欢
小学生学习指导(爆笑校园)(2021年10期)2021-11-01 08:43:58
小学生学习指导(爆笑校园)(2021年9期)2021-09-27 03:45:38
小学生学习指导(爆笑校园)(2021年4期)2021-04-29 09:34:02
军事文摘(2020年14期)2020-12-17 06:27:46
金属加工(冷加工)(2020年11期)2020-11-24 08:58:20
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
测控技术(2018年5期)2018-12-09 09:04:24
电子制作(2018年16期)2018-09-26 03:27:06
精密制造与自动化(2018年1期)2018-04-12 07:42:50
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
