
运用最大熵模型和随机森林模型对东北红松分布的模拟1)
2020-04-10 05:55张劳模罗鹏庞丽峰唐小明
东北林业大学学报 2020年3期
张劳模 罗鹏 庞丽峰 唐小明
(中国林业科学研究院资源信息研究所,北京,100091)
全球气候变化使植物的分布区域也随之发生改变,研究植被的潜在分布显得越来越重要[1-4]。植被的分布主要受到生物因素和非生物因素的共同作用,其中以温度和降水等非生物因素最为重要。近些年来,随着数学方法和地理信息技术的发展,建立了多种潜在物种分布模型,其中主要以物种分布模型(SDMs)和数据挖掘模型应用最为广泛。典型的物种分布模型主要有MaxEnt[5]、BIOCLIM[6]、PORSKA[7]、GAM[8]、GLM[9]、LANDIS[10]等。数据挖掘模型主要有随机森林和分类回归树(CART)等。
在SDMs模型之中,最大熵模型(MaxEnt)是最可靠的模型之一[11-13]。MaxEnt模型是基于Jaynes于1957年提出的最大熵理论而建立的模型[14],而Philips将最大熵模型首次应用于物种分布[5]。MaxEnt模型在使用时,需要物种的分布数据和环境变量数据,一般使用经纬度来表征物种的分布点,而环境变量数据通常包括温度和降水等气候数据,也包含地形地貌和植被覆盖等信息。利用MaxEnt模型模拟物种的潜在分布结果时,对于数据量的要求比较低,即使数据有部分缺少或者样本容量很小的情况下,依旧可以模拟出较为合适的结果[15]。目前,利用MaxEnt模型对不同尺度范围的物种潜在分布和适宜性评价均有研究[16-20],对MaxEnt模型本身模型精度和不确定性分析以及不同物种分布模型之间的差异也有相关研究[21-24]。
近年来,数据挖掘模型也是在物种潜在分布研究中运用较为广泛的一类模型,其中以随机森林的模型的运用最为广泛。随机森林模型是典型的弱分类器组合成为强分类器的模型,利用随机森林模型进行分析时,样本抽样和特征数的选取都是随机的,每棵树自由生长,不进行修剪,结果依靠平均值或者投票获得[25]。目前,随机森林模型不仅对云南松和荞麦等植物物种以及白冠长尾雉、中华穿山甲和藏酋猴等动物物种进行了潜在分布模拟,而且也对城市需水量预测、林火发生概率模拟等[26-30]。
目前,对于MaxEnt模型和随机森林模型单独的研究成果有很多,但是对于这两个模型之间的对比研究还相对较少,为了探究这两个模型之间对于某一物种潜在分布的预测结果的差异,我们利用东北红松作为研究对象,讨论两种模型的精度差别和模拟结果的差异。
1 研究区概况
东北林区是我们国家最大天然林区,尤其是大兴安岭、小兴安岭和长白山地,森林资源十分丰富,林地面积和蓄积量分别占全国林地总面积和森林总蓄积量的27%和30%。该地区地形主要以山地和平原为主,海拔最高点是位于吉林省,海拔2 691 m。东北地区普遍纬度较高,冬长夏短,年均气温6 ℃,年降水量为400~1 000 mm。主要树种为红松(PinuskoraiensisSieb. et Zucc.)、落叶松(Larixgmelinii(Rupr.) Kuzen.)、蒙古栎(QuercusmongolicaFisch. ex Ledeb)、水曲柳(FraxinusmandshuricaRupr.)和樟子松(Pinussylvestrisvar.mongolicaLitv.)等。红松是我国重要的珍贵树种,同时也是国家储备林树种之一。成熟红松树高可达40 m以上,胸径1~2 m。由于特殊的地理和气候条件,红松主要分布在中国的东北部,即小兴安岭和长白山附近[31](见图1)。近年来,由于气候变化和人类活动增加,红松的数量正在逐渐减少。因此,探究红松可能的分布范围和适宜区域,对于红松的保护具有重要的意义。
2 研究方法
2.1 数据来源
在国家森林资源连续清查数据中收集了东北地区159个红松分布点。国家森林资源连续清查,也叫做一类调查,是一种森林资源调查方法,调查内容包括土地利用与覆盖、森林资源、森林生态状况、林业生产和社会经济情况调查等项目。国家森林资源连续清查数据为自然条件下生长的红松数据,不包括人工种植以及移栽等其他因素获得的数据。
气候数据来源于世界气象(http://www.worldclim.org),其中包括了19个环境变量(年平均温度、昼夜温差月均值、等温性、温度季节变化标准差、最暖月最高温、最冷月最低温、气温年变化范围、最湿季度平均温、最干季度平均温、最暖季度平均温、最冷季度平均温、年平均降水量、最湿月降水量、最干月降水量、降水量变异系数、最湿季度降水量、最干季度降水量、最暖季度降水量、最冷季度降水量),这些数据是根据世界各地气象站1950—2000年的观测数据,通过空间插值实现的栅格数据集,被广泛用于生态系统的相关研究,空间分辨率为1 km。地形数据是来源于地理空间数据云(http://www.gscloud.cn),分辨率为1 km的数字高程模型(DEM)数据,并利用软件输出坡向和坡度信息。土壤数据下载自来源于寒区旱区科学数据中心(http://westdc.westgis.ac.cn),该数据是联合国粮农组织(FAO)和维也纳国际应用系统研究所(IIASA)所构建的世界土壤数据库(HWSD),空间分辨率为1 km,土壤因子包括上层土壤碎石体积分娄、上层土壤中沙体积分数、上层壤土质量分数、上层土壤黏土质量分数、上层土壤有机碳质量分数、下层土壤碎石体积分娄、下层土壤中沙体积分数、下层壤土质量分数、下层土壤黏土质量分数、下层土壤有机碳质量分数。

图1 研究区与红松分布位置点
2.2 模型精度判断指标
判定最大熵模型和随机森林模型本身建模精度的指标为AUC(曲线下面积)。AUC是ROC曲线与横坐标之间所形成区域的面积,由纵坐标的特异性和横坐标的敏感性构成。在图2中,红色曲线为ROC曲线,是以真阳性率(判定为正例,也是真正例的概率)为纵坐标,假阳性率(判定为正例,但却不是真正例的概率)为横坐标绘制的曲线,而曲线与横坐标轴围成的图形面积(AUC),对于判断模型本身预测能力和准确程度有着良好的应用成果,AUC通常为0.5~1.0。AUC为0.5~0.6,模型预测失败,模型本身不具备预测能力;AUC为0.6~0.7,模型本身的预测能力很差,这种情况下的预测结果通常不予采纳;AUC为0.7~0.8,预测能力一般;AUC为0.8~0.9,表示模型具备很好的预测能力;AUC为0.9~1.0是预测精度最高。

图2 ROC曲线
2.3 模型构建
2.3.1 MaxEnt模型构建
MaxEnt生态位模型是通过收集物种的已知地理分布信息和相关环境因子,对物种的潜在适生分布区域及影响因子进行模拟分析的空间分布模型。利用MaxEnt模拟物种分布时,首先需要输入物种在地理空间真实的点位分布数据,一般用经纬度来表示;其次需要输入相关的环境数据,环境数据要求分辨率和分布范围相同,否则模型会无法输出预测结果。MaxEnt模型预测物种分布的基础是合理的测试结果,此部分测试结果是从输入数据中随机抽选得到,一般来说,模型会默认从数据中选择70%的数据集作为训练数据,30%的数据集作为测试数据。此部分测试数据用于构建模型,模型是否合理,是否精度达标,直接影响着模拟的结果。如果测试数据集的结果精度较好,结果合理,则可以将环境数据代入模型中,进行物种潜在分布模拟。
2.3.2 随机森林建模过程
随机森林模型是典型的弱分类器组成为强分类器的例子,“森林”中每个个体都是一棵“决策树”,每个决策树单独运作,但是最后的结果由整个“森林”决定。对于已知的N个分布数据和M个环境因子,N个分布数据中包含了实际分布的红松点位数据和模拟的非红松分布的点位数据,在建立模型时,首先需要从N个分布数据进行有放回地随机抽取组成样本集,得到n棵决策树,在每棵决策树进行节点分裂时,随机抽取m(m≤M)个环境因子来与决策树进行组合匹配,从而得到最为合理的分解组合;其次在每棵决策树进行生长分裂时,外界不得进行干预和修剪,让其完全自由“生长”,以确保建模结果的随机性与合理性;最后,n棵决策树组成的随机森林的分类结果的众数即为最后的结果。但是,在这一系列操作中,难免会有一些数据被遗漏,而这些经过了n次随机抽样依旧没有被抽中的数据,我们将其称为袋外数据(OOB),这些袋外数据组成测试数据,用来对样本精度进行测试。建立随机森林模型的关键参数是n和m,为了最大程度上得到合理的值,在本研究中,采用K折交叉检验法。具体来说,对原始数据进行随机组合子集,数目是K个,这些子集互不相交,每一次过程中,一个子集作为目的子集,用于模型检验,其他子集是训练样本集,这样进行K次运算。结合前人的研究成果,将K设置为10。经过10次运算,结果显示,n=500,m=4,即生长的树的数目是500,在每一个分裂节点处样本预测器的数目为4最合理。
3 结果与分析
3.1 模型精度
根据模型预测能力和精度判断指标(AUC)可知,MaxEnt模型,训练数据为0.927,检测数据AUC为0.865,均超过0.8,表明预测结果很准确,模型具备很好的预测能力。随机森林模型的AUC为0.902,预测精度在最高区间,表明预测结果十分精确。从模型精度来看,MaxEnt模型和随机森林模型的精度基本都在0.9左右,可以满足模型使用的精度要求,MaxEnt模型的精度略低于随机森林模型,但是差距较小。
3.2 重要环境因子排序
由图3可知,MaxEnt模型的输出结果显示,各因子的重要性排序有明显差距,年平均降水、降水量变异系数、温度季节变化标准差等对于红松的分布影响程度最大,其次是最湿季度降水量、最暖季度降水量、气温年变化范围,其他的环境因子影响程度相对较小。3类环境要素对红松分布的影响重要性顺序为气候要素大于地形要素大于土壤要素。
随机森林模型的输出结果显示,各因子的重要性排序虽然也有明显差距,然而排名靠前的几个因素差距较小,以上层土壤黏土质量分数、下层土壤黏土质量分数、上层土壤有机碳质量分数、下层壤土质量分数、下层土壤有机碳质量分数和上层壤土质量分数等土壤数据,以及最冷月最低温、最冷季度平均温、年平均温度、温度季节变化标准差、气温年变化范围和年平均降水等气候数据,对于红松的分布影响程度最大,并且影响能力相当。3类环境要素对红松分布的影响重要性顺序为土壤要素大于气候要素大于地形要素。

图3 不同模型输出的环境变量对物种分布的影响程度排序
由图4可知,在MaxEnt模型中,最重要的因子为年平均降水,年降水在400~900 mm,对于红松分布的影响是呈正相关的关系,即降水越多,分布概率越大;降水量变异系数大约为98时,出现明显拐点,小于拐点值时,函数趋势略有增加,大于拐点值,则出现明显的下降。温度季节变化标准差为1 450时,出现明显拐点,小于拐点值时,函数呈增加趋势,但是趋势较缓,大于拐点值,则出现明显的下降,并且下降速度较快;最湿季度降水量小于650 mm时,函数曲线基本没有变化,之后迅速增加至最大值,随后保持不变。最暖季度降水量和气温年变化范围的函数图像十分相似,最暖季度降水量在270~650 mm、气温年变化范围在35~65 ℃时,函数值持续增加,最后达到最大值后保持不变。

图4 MaxEnt模型输出的主要环境因子与红松分布的关系
由图5可知,在随机森林模型中,排名靠前的土壤属性为土壤黏土质量分数、土壤有机碳质量分数和土壤壤土质量分数,由于上层土壤和下层土壤的函数图像基本一致,所以只输出上层土壤的结果。选取年平均气温、年平均降水和最冷月最低温对气象数据进行详细描述。上层土壤黏土质量分数小于5%、土壤有机碳质量分数大于21%、土壤壤土质量分数小于15%,有利于红松的分布,否则,不利于红松的生长。对于气候因子,年平均气温在0 ℃以下时,年平均降水在600 mm以下,以及最冷月最低温在-28 ℃以下时,有利于红松的生长,否则,不利于红松的生长。
3.3 红松潜在分布模拟
由图6可知,红松最合适的分布区域为辽宁省东北部和吉林省东南部的交界区域,在黑龙江的南部也有一片相对较大适生区域,最小的一片适生区域分布在黑龙江省的中北部地区;整体上来看,MaxEnt模型所模拟的区域主要分布在东北地区的东部,西部地区基本没有特别适合红松生长的区域。随机森林模型模拟结果可以看出,红松的适生范围主要分布在辽宁中北部和西南部分地区、吉林中东部,以及黑龙江省的中东部;随机森林模拟的红松潜在分布区域面积较大基本包含了MaxEnt模型模拟的潜在分布范围。从整体上看,两个模型对于红松的模拟结果有着很大的重合度,主要集中于东北地区的中东部,说明东北地区的中东部最适合红松的生长。

图5 随机森林模型输出的主要环境因子与红松分布的关系

图6 红松潜在分布模拟结果
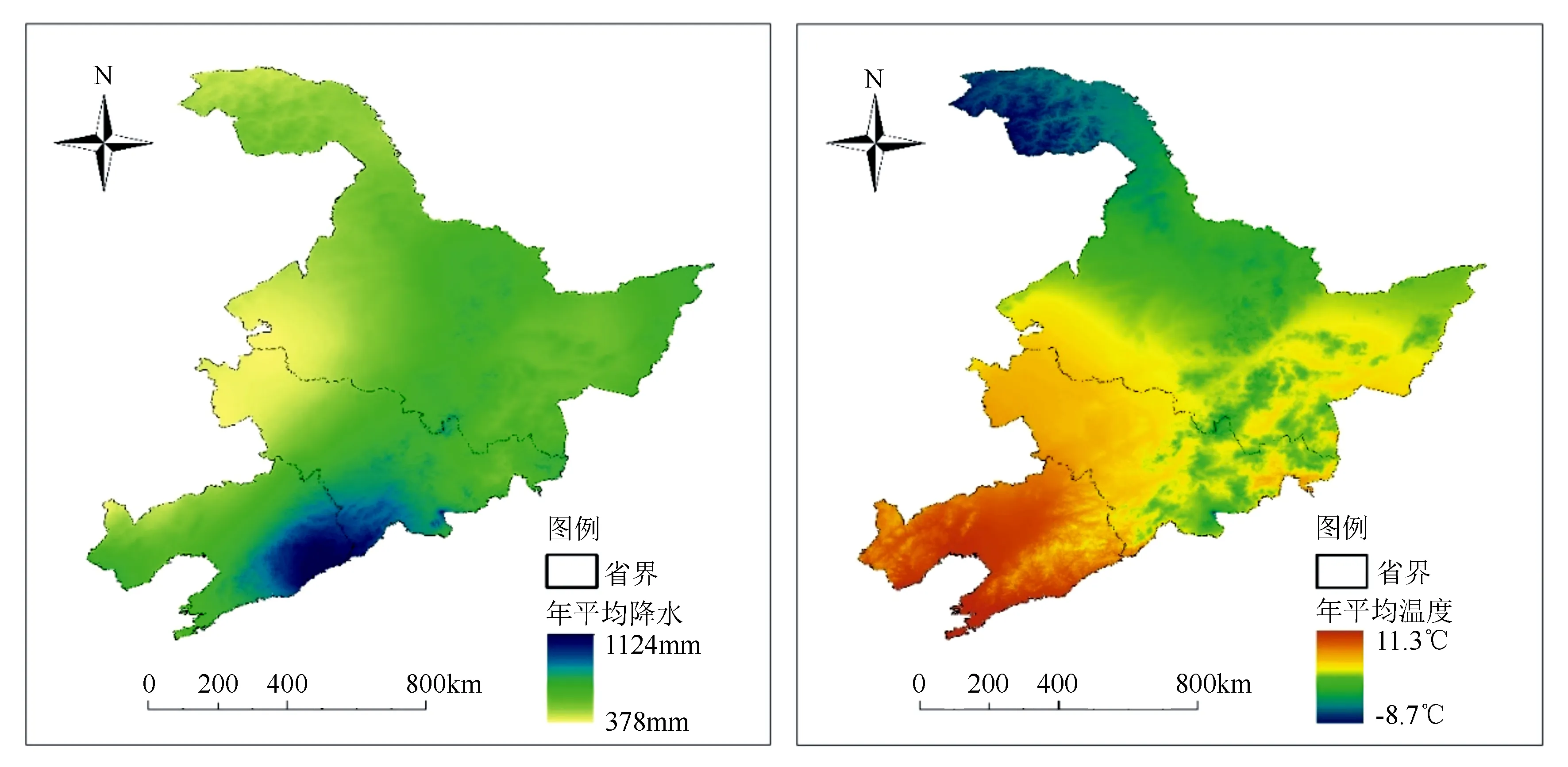
图7 东北地区年平均降水和年平均气温分布

图8 东北地区气候和土壤分布图
4 结论与讨论
本文利用MaxEnt和随机森林两种模型,结合东北三省气候、土壤、地形数据和红松分布样点,分析了两种模型在模拟红松潜在分布时的共性与区别。结果表明两个模型精度接近,模型模拟的红松潜在分布结果有着很大的重合度,主要集中于东北地区的中东部,说明东北地区的东部最适合红松的生长,但两个模型的输出的因子重要性排序结果却有显著差异。
MaxEnt模型认为重要性因子排序顺序为气候、地形和土壤,而且气候中,年平均降水的重要性最大。由图7可知,东北地区的降水空间差异较大,整体呈现由西向东、由北向南的递增趋势。温度条件在该地区不是限制红松分布的主要因子,降水的作用显得更重要。所以红松主要分布在东北地区的东部,这片区域温度普遍都可以满足红松的生长要求,然而和西部地区相比,该地区具有充沛的降水量,水分条件成为主要限制因子。
随机森林模型认为重要性因子排序顺序为土壤、气候和地形,但是因子的重要性程度相差无几。由图8可知,东北地区的土壤空间格局有很明显的空间差异,西部平原区在各种土壤理化指标上都和其他地区有所差异,这种差异很可能导致了红松的分布范围偏向于中东部地区。而最冷月、最低温、年平均气温和年平均降水等气候数据显示,气候要素在东北地区的空间分布上也有一定差异,并且差异也非常明显,所以气候要素也成为限制红松分布的重要因子。
MaxEnt模型和随机森林模型预测物种潜在分布都有着良好的表现,无论是预测范围还是精度要求都很合理。MaxEnt模型的输入信息是物种的分布数据和环境数据,其中分布数据只包括实际分布的数据;而随机森林中,输入数据同样是分布数据和环境数据,但是分布数据中不仅包括实际分布的数据,也包括非分布的数据,非分布数据的选取会对结果产生很大的影响,如果非分布数据的选择十分合理,也确实选取的区域没有红松的生长分布,则会增加模型的精度,结果会更加准确,如果选取的数据有所偏差,则会适得其反。在本研究当中,非分布数据多采样于远离分布数据的其他区域,对于这些非分布数据,如果其所带有的环境数据与分布数据差异较大,则可能成为限制因子,例如随机森林中的土壤数据,解释了为什么最终分布模拟结果大致类似,而环境要素重要性排序却有显著差异。在研究中,结合数据情况,两种模型的因子重要性分析结果都有一定道理,而那种结果更符合实际情况则是我们接下来需要研究的内容。同时,不同类型的训练样本对于输出结果会产生影响。因此,在构建物种分布模型时,需要考虑输入样本的合理性,分析样本对预测物种分布可能造成的影响。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
格言·校园版(2022年17期)2022-07-06
一重技术(2021年5期)2022-01-18
小哥白尼(野生动物)(2021年9期)2022-01-17
新农民(2020年5期)2020-12-10
科学大众(中学)(2019年3期)2019-05-17
汽车观察(2018年10期)2018-11-06
科技知识动漫(2017年1期)2017-02-06
华人时刊(2016年16期)2016-04-05
少儿科学周刊·少年版(2015年1期)2015-07-07
