
关系数据库中树形结构的矩阵算法研究
2020-04-09 04:54杨国清
计算机时代 2020年3期
杨国清

摘 要: 关系结构是最常用的数据逻辑形式。在关系数据库中,存在局部的树形结构数据形态。针对关系数据库中的树形结构数据,提出一种基于矩阵模型的数据组织方法,直接使用SQL查询,在数据库内部实现树形结构的插入、遍历、删除、移动等算法。
关键词: 关系数据库; 算法; 树形结构; SQL
中图分类号:TP311.52;TP311.138 文献标识码:A 文章编号:1006-8228(2020)03-50-03
Research on matrix algorithm of tree structure in relational database
Yang Guoqing
(Guangdong Peizheng College School of Data Science and Computer Science, Guangzhou, Guangdong 510830, China)
Abstract: Relational structures are the most commonly used form of data logic. In the relational database, there is a local tree structure data form. A matrix model based data organization method is proposed for the tree structure data in the relational database, and the SQL queries are used directly to implement the interpolation, traversal, deletion, and moving algorithms of the tree structure within the database.
Key words: relational database; algorithm; tree structure; SQL
0 引言
数据库设计活动中,概念模型是面向用户、面向现实世界、与数据库管理系统(DBMS:DataBaseManagement System)无关的数据模型。逻辑模型是概念模型在具体DBMS中的数据组织形式。逻辑模型有四种形态:层次结构、网状结构、关系结构、面向对象结构。层次结构也就是树形结构,由一个根结点和多个双亲结点、孩子结点、叶子结点、非叶子结点等数据形态构成。现实世界里常见的层次结构有单位组织架构、磁盘目录与文件结构、家谱、论文标题与正文结构等[1]。
关系结构以二维表的形式留存数据,是管理信息系统中最常用的数据逻辑形式。在数据库应用中,存在这样的特殊情况:主体数据形态采用关系结构,但局部存在使用树形结构描述的数据。例如:学生论文写作系统中,学生、老师等多数实体数据是基于关系结构的,而学生论文中的标题与正文内容是基于树形结构的。解决这种特殊应用问题,成为论文写作系统项目设计与实现的重点与难点。
目前比较普遍的做法是:使用双亲法或孩子法,单独建立结点关系表,记载每个结点的双亲或者孩子,以确定结点之间的先后关系。由于树形结构的遍历算法无法用单纯的SQL (Structured Query Language)实现,所以往往需要以C++、Java等高级语言的结构体或类为载体,编写客户端程序,运用递归思想,实现树形结构的遍历、插入、删除等算法。该方式无法在模型-视图-控制(MVC:Model View Controller)软件开发模式中,将数据业务逻辑与前台用户界面完全分离开来,前端程序需要过多地参与数据层活动,不利于软件团队的分层开发,导致开发效率较低。另外,需要建立结点内容与结点位置的联结,即建立单独的结点关系表,实现起来较为困难。与此同时,当结点位置有变化时,需要重新调整结点关系表,必然会消耗较多的系统资源。
经过研究发现,采用一种全新的基于矩阵的组织形式留存树形结构数据,可以完美地解决上述问题。该方法只需要在结点数据中添加相关的位置特征值,不需要建立单独的结点关系表,结点的位置可以直接从自身数据中得到。新方法不用考虑树的度(结点孩子数的最大值),只需要关注树的深度(树的层数)。直接用SQL语句,就可以方便快捷地实现数据遍历、插入、删除、移动等算法。与此同时,数据业务处理逻辑可以完全交由数据后台完成,可以方便快捷地实现MVC所要求的分层处理目标[2]。
1 树形结构中数据的矩阵化
1.1 数据原始形态
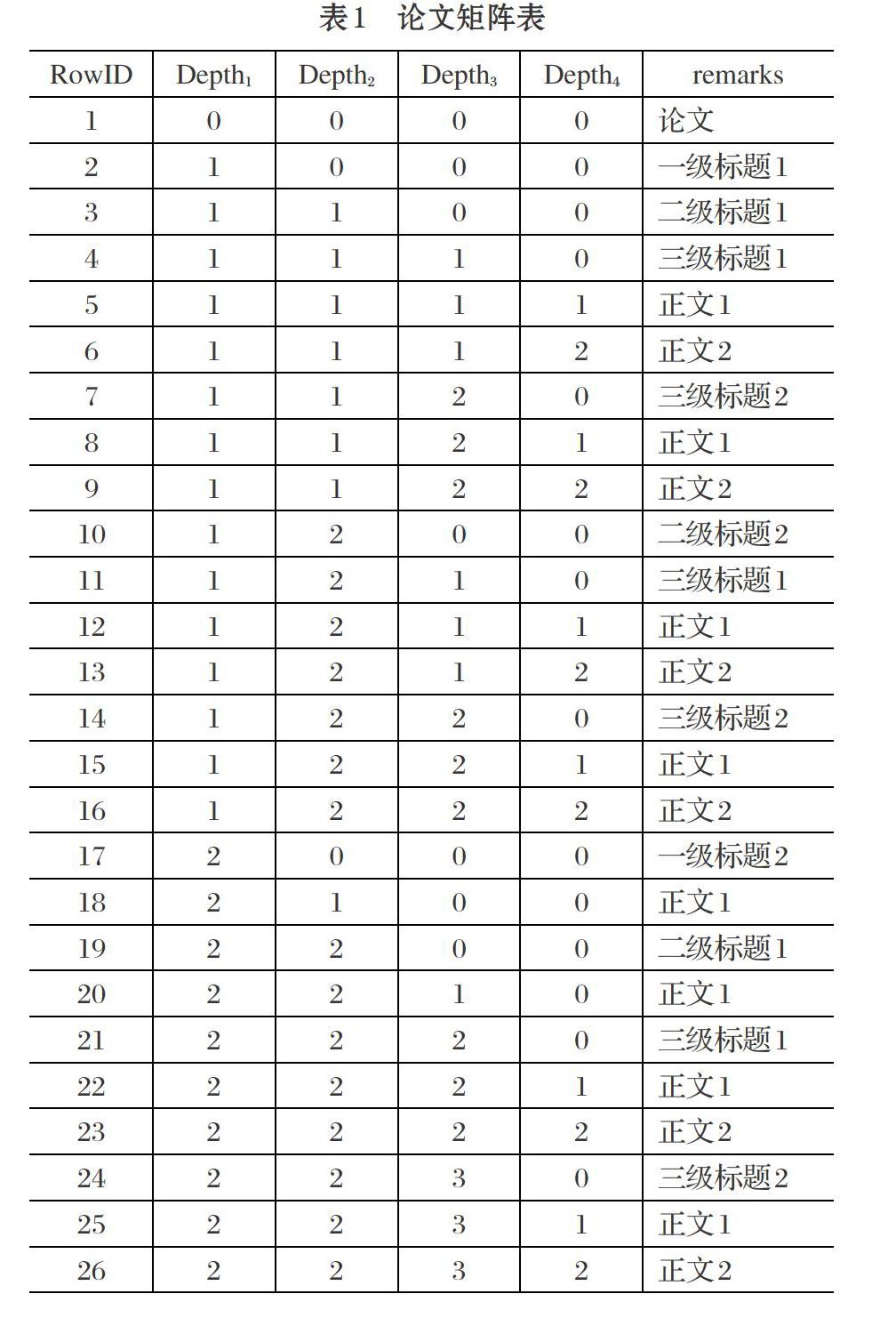
我们以论文写作系统中,论文的标题与正文结构为研究蓝本,描述树形结构数据的矩阵化过程。假设有一篇论文的简化结构如图1所示。从图1中可以看出,树中“论文”为根结点,所有“正文”均为叶子结点,其他为中间结点。该树的度为3,深度为5[2]。
1.2 树的矩阵化
树形结构矩阵化的具体转换规则有三条:
⑴ 根结点编号为0;
⑵ 将某结点的孩子按从上到下编号,从1开始,依次加1;
⑶ 每个结点独占矩阵中的一行。该结点所处的深度特征值为其编号,前面的深度特征值继承长辈的编号、后面深度特征值指定为0。
按照以上規则,图1所示的某论文的树形结构被处理为一张矩阵表,如表1论文矩阵表所示。Depthi代表深度i的特征值。i为深度索引号,其最大值为树的深度减1[3-4]。
2 常用算法实现
2.1 当前结点深度获取
用于获取当前结点的深度。在存储过程中使用动态SQL语句,可以方便获取结点深度。存储过程的头部为NodeDepth @RowIDbigint。具体实现代码如下:
2.2 遍历算法
用矩阵法处理过的树形结构数据,其遍历算法实现起来比较容易,直接用带有排序子句的SQL查询语句即可,代码如下:
2.3 插入算法
在矩阵的某位置插入新行,只需要确定新行不同深度的特征值,不需要修改其他结点的数据。算法思路为:获取当前结点的位置,在其双亲的所有孩子中,寻找最底层的最大特征值,加1后的新值作为新行的最大深度特征值,同一行前面的特征值来源于其父辈,后面默认为0。使用头部为addPart @RowIDbigint的存储过程,结合动态SQL语句技巧,可以快速实现插入算法。具体代码如下:
上述算法插入的是当前结点的兄弟结点,如果需要插入孩子结点,只需要作适当调整。另外,结点的删除、移动与插入算法相类似,本文不再赘述[6]。
3 结束语
针对关系数据库中的树形结构,按照矩阵化转换规则,将树形数据变为关系表。通过结点的特征值,可以方便地实现结点定位、遍历、插入等算法。该模型可以在数据库内部直接使用SQL实施,不需要借助高级语言在客户程序中实现,较好地达到了MVC设计模式中分层开发的目标。
参考文献(References):
[1] 尹志宇,郭晴.数据库原理与应用教程(第2版)[M].清华大学出版社,2017.
[2] 李国勇,王燕霞,熊黎丽等.基于树形组织结构的数据隔离模型[J].自动化与仪器仪表,2018.11:231-235
[3] 张凤林,皮德常,丁宗红.关系数据库实现U/C矩阵的方法[J].微计算机应用,2000.4:214
[4] 周琴.矩阵特征值和特征向量在实际中的应用及其实现[J].高师理科学刊,2019.7:8-10
[5] 梁敬彬.探讨动态SQL扩展的应用[J].福建电脑,2018.3:92-94
[6] 王洪兰.ASP.NET与SQL数据库的连接与查询方法探索与实现[J].信息系统工程,2018.10:27-28
猜你喜欢
山东冶金(2022年2期)2022-08-08
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
河北大学学报(自然科学版)(2015年1期)2015-02-27
江西理工大学学报(2013年1期)2013-03-20
