
基于Adaboost算法的滑坡预测模型研究
2020-03-26 01:57:28孟欣
卷宗 2020年36期
孟 欣
(重庆交通大学土木工程学院,重庆 400074)
1 引言
根据中国地质环境信息网发布的《全国地质灾害通报》数据统计[1],中国2018、2019年度发生的地质灾害分别为2966起、6181起,滑坡占比分别为55%、68.27%,可见滑坡灾害是中国当前最严重的地质灾害。
近年来学者们提出了多个滑坡预测模型,如:黄发明(2017)[2]Extreme Learning Machine,ELM滑坡位移组合预测模型;李麟玮等(2018)[3]GWO-MIC-SVR滑坡位移预测模型等。随着软件技术以及机器学习算法的发展,也开始有学者研究基于机器学习的滑坡灾害空间预测技术。
机器学习算法中,目前主要有:最近邻分类算法、人工神经网络(Artificial Neural Network,ANN)、支持向量机(Support Vector Machine,SVM)等,但利用Adaboost算法进行滑坡预测的研究还比较少。本文选取对滑坡影响较大的降雨、地震因素来开展基于Adaboost算法的滑坡预测模型研究。
2 Adaboost算法原理
Adaboost是英文“Adaptive Boosting”的缩写,算法中不同的训练集是通过调整每个样本对应的权重来实现的:开始时,每个样本对应的权重是相同的,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重。这样,分错的样本就被突出出来,从而得到一个新的样本分布。在新的样本分布下,再次对弱分类器进行训练,得到一个新的弱分类器。依次类推,经过T次循环,得到T个弱分类器,把这T个弱分类器按一定的权重叠加起来,得到最终理想的强分类器。
Adaboost算法的计算过程如下:
1)权值初始化:给训练样本中的每组数据赋予一个初始权值。
2)迭代计算:第 t 轮迭代中,使用权值分布Dt训练样本数据,得到第t个弱分类器Gt(x),计算Gt(x)在训练样本数据上的误差率εt、系数αt,以及函数f t(x),从而得到第t个弱分类器:
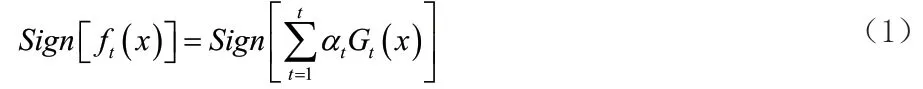
3)得到最终强分类器:如此往复训练,直到第 t=T 轮迭代后将数据全部分类正确时为止,得到最终强分类器:
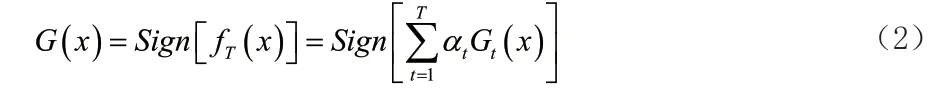
3 Adaboost算法滑坡预测研究
3.1 数据获取及预处理
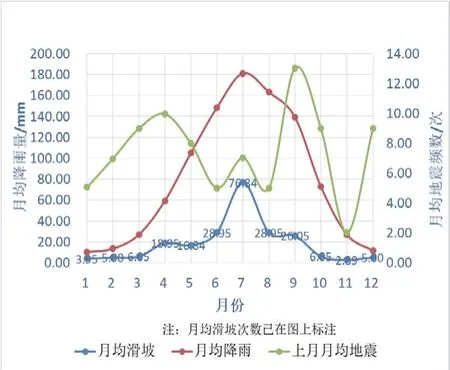
图1 月均滑坡次数-降雨量-地震次数(上月)分布曲线
通过中国地质环境信息网[1]、中国气象数据网[4]、国家地震科学数据中心[5]、中国统计年鉴[6]等官方网站获取到了四川省1949—2001年及2014—2017年的滑坡数据、降雨数据、地震数据,前者作为建模样本数据,后者作为测试数据。
经整理绘制了1949—2001年月均滑坡次数-降雨量-地震次数(上月)分布曲线(图1)如下所示。
为了便于计算,将当月平均滑坡数≥18次的类别值设为“1”;将当月平均滑坡数<18次的类别值设为“-1”。
3.2 Adaboost算法预测模型训练
计算前,绘制数据坐标分布如图2所示:
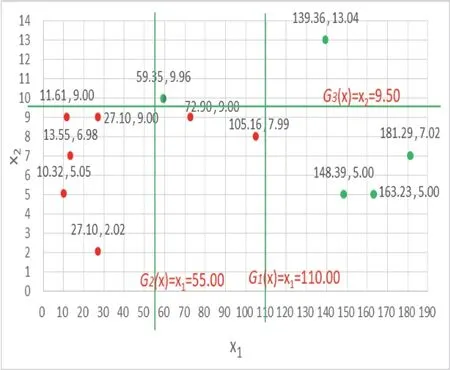
图2 数据坐标分布图
由上图可找到3个基本分类器如下:
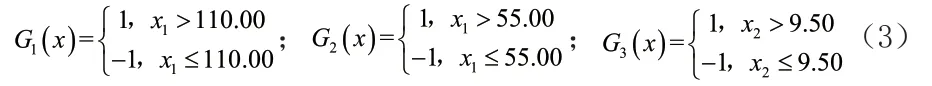
按照Adaboost算法原理进行迭代计算,得到最终的强分类器即滑坡预测模型为:
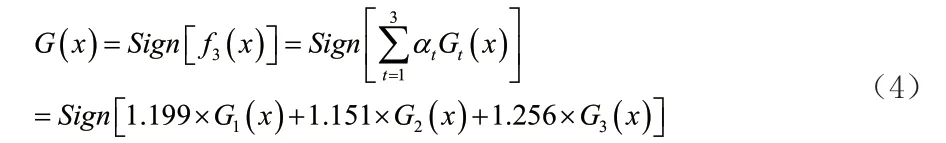
3.3 预测模型验证
用上述模型对四川省2014—2017年的月滑坡次数进行验证,在48组数据中,预测成功的次数为41次,预测成功率为85.42%。
4 研究结论
Adaboost算法可建立包括降雨量、地下水、库水位、地应力、地震、深部位移、地表沉降等的多维度预测模型,且在通过大量实测数据对模型进行优化后能具有较高的预测准确度,可为滑坡灾害防治提供宏观决策依据。
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
商用汽车(2021年4期)2021-10-13 07:16:02
河北地质(2021年1期)2021-07-21 08:16:08
数学物理学报(2020年6期)2021-01-14 01:00:14
电子测试(2018年1期)2018-04-18 11:52:35
中学生数理化·中考版(2017年12期)2017-04-18 12:55:03
北方交通(2016年12期)2017-01-15 13:52:59
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
水利科技与经济(2016年6期)2016-04-22 05:07:30
