
基于小数据的钢筋检测方法的研究
2020-03-20 08:39:28王志丹中国联通智能城市研究院北京100048
邮电设计技术 2020年2期
王志丹(中国联通智能城市研究院,北京 100048)
0 引言
近年来,国家大力推动钢结构建筑发展,数据表明,2017年以来中国钢筋年产量已超过2亿吨,2017年建筑业的总产值超过21万亿元,而其中钢铁在建筑材料中所占的造价达到了20%~30%[3]。钢筋广泛应用于各种建筑结构,特别是大型、重型以及高层建筑结构,但在实际运用中,钢筋计数问题一直困扰着从业者。自上世纪70年代便有好多工程人员投入至钢筋计数的研究中,对于成捆钢筋,曾有研究利用重量传感器的方法来进行计数,该研究理论为同类型钢筋有着相同的重量和长度的标准,根据总重量和单根钢筋的重量便可以得出一捆钢筋的数量。但是由于不同钢材厂的工艺不同,以及部分钢材厂存在负公差生产,故重量传感器方法无法得出精准的结果。随着计算机视觉技术的发展,有研究将神经网络应用于钢筋计数方法,该研究认为虽然钢筋端面形状不规则,但是面积是相近的,故可以通过将一捆钢筋端面图片进行二值化,通过判断每一个端面的面积与平均值的差异便可以得出成捆钢筋的数量[4]。但该方法存在一定缺陷,钢筋端面平均值和目标物体有较大的依赖性,自适应性较差,同时,若多个钢筋的端面大面积重叠,也无法判断具体数量。随着双目视觉和激光技术的发展,一些大型钢材制造商将“双目视觉+线激光”技术应用于钢筋计数,该技术利用激光测距的测量结果对双目视觉的测量结果进行修正,有效地提高双目立体视觉远距离测量精度[5],但是该技术成本高,需要使用双目立体视觉仪和激光测距仪等大型设备,在工地这种特殊而复杂的场景中无法便利地使用。为解决以上问题,同时工地钢筋图像数据不便于大量采集和标注,本文提出基于小数据目标检测算法并将其应用于钢筋计数应用中,工地工作人员只需将钢材照片通过终端上传至云服务器中的钢筋检测模型,便可以快速准确地得到照片中钢筋的数量。
1 目标检测算法
目前,深度学习已经应用到了各个领域中,应用场景主要为3类:物体识别、目标检测、自然语言处理。其中目标检测作为计算机视觉的重要任务之一,不仅要识别出物体属于哪个分类,还要得到物体在图片中的位置。近年来随着深度学习技术和算力的高速发展,目标检测算法也从基于手工特征的传统算法转向了基于深度神经网络的检测技术,深度神经网络的目标检测算法主要分为2类:one-stage和two-stage,onestage算法主要包含SSD[14]、YOLO[11]等算法,two-stage算法主要包含R-CNN[13]、Fast R-CNN[12]、Faster RCNN[6]等算法,两者的主要区别在于two-stage算法需要先生成可能包含物体的预选框,其次再进行物体检测;而one-stage算法会直接在网络中提取特征来预测物体的分类和位置,one-stage相关的算法计算速度比较快,但是准确率略低于two-stage算法。
本文使用的算法主要为two-stage中的Faster RCNN算法,算法模型结构如图1所示,Faster R-CNN算法实现图像中的目标检测需经过如下4个步骤:第1步将预训练卷积神经网络作为特征提取器,对输入的图像进行特征提取得到图像的特征图;第2步利用RPN(Region Propose Network)网络对提取的卷积特征图进行处理,得到一定数量的包含目标物体的候选区域;第3步通过ROI Pooling对卷积神经网络提取的特征和包含目标物体的边界框进行处理,同时提取每个候选区域的特征,得到一个新的向量;第4步基于RCNN模块对前3步得到的特征进行分类和边框回归。在深度目标检测算法中,最难的问题是生成长度不定的边界框列表,边界框是具有不同尺寸和长宽比的矩形,但是构建深度神经网络时,最后的网络输出一般是固定尺寸的张量输出,Faster R-CNN网络在第2步的RPN中,通过采用 锚(Anchors)来解决边界框列表长度不定的问题,Anchors是固定尺寸的边界框,即在原始图像中统一放置固定大小的参考边界框,不同于直接检测目标位置,这里将问题转化为求解每个Anchor是否包含目标和如何调整Anchor以更好地拟合目标对象[15],故RPN网络最终为每个Anchor提供2个输出结果:一是Anchor目标物体的概率和背景的概率,二是4个预测值(Δ xcenter、Δ ycenter、Δ width、Δ height),用来调整Anchor的边界框,使其更好地拟合预测的目标对象。RPN处理后,将得到约2 000个候选区域,若直接进行分类和回归计算,则会出现效率低、速度慢等问题,Faster R-CNN采用RoI Pooling即对每个候选区域提取固定尺寸的特征图,继而对固定尺寸的特征图进行分类和回归,这样便可以提高计算的效率。以上便是Faster R-CNN算法实现图像目标检测的流程。
2 基于小数据的目标检测模型

图1 Faster R-CNN结构图

图2 钢筋图像
本文通过将优化后的目标检测算法模型应用于钢筋识别应用中,在工地复杂环境中,工人只需将拍摄后的钢筋照片通过终端上传至模型,便可以快速准确地得出照片中钢筋的数量。为了训练出钢筋检测模型,本文首先收集了约250张成捆钢筋图像,钢筋图像如图2所示,每张图像的标记为[N,4],其中N为一张图像中的目标框的数量,4维数据分别为[X1,Y1,W,H],X1和Y1分别为目标中心点的(X,Y)坐标,W和H分别为目标的宽度和高度值,将这250张图像随机分为训练集(200张图像)和测试集(50张图像),训练集图像用于训练钢筋检测模型,测试集图像用于检测模型的准确率。由于工地环境复杂,钢筋图像采集较困难,同时单个钢筋目标较小,标注需要大量的人力,故很难达到目标检测算法所需的图像数量级(通常为100 000数量级),为了在小数据集的图像上得到更高的准确率,本文做了2处优化,一是从数据层面对训练集图像进行数据增强,二是利用在ImageNet数据集上的预训练模型对钢筋检测模型进行微调。
数据增强是一种通过让有限的数据产生更多等价数据的人工扩展训练数据集的技术,它是克服训练数据集不足的有效手段,目前在深度学习的各个领域中应用广泛,对于图像分类问题,已有大量实验通过对图像进行剪裁、平移等操作来增强数据集,实验结果表明数据增强可以极大的改进图像分类的表现。而对于图像目标检测问题,若对原始图像进行随机剪裁和平移操作,对应图像内目标的位置坐标信息也会发生变化,Quoc Le等研究者表示[8],尽管数据增强能极大的改进图像分类表现,但它在目标检测任务上的效果还未被透彻研究过,此外,目标检测所用图像的注释会造成大量的成本,所以数据增强对此计算机视觉任务的影响可能会更大。在此研究中,作者们研究了数据增强在目标检测上的影响,在COCO数据集上的实验结果说明,优化后的数据增强策略将检测准确率提升了2.3 mAP,使单推理模型能够达到最佳效果——50.7 mAP。
计算机视觉中的图像增强包括剪裁、翻转、旋转一定角度、扭曲等几何变换以及像素扰动、添加噪声、光照调节、对比度调节、样本加和或插值、分割补丁、基于GAN网络[9]的图像生成等的数据增强方法。但是并不是所有的数据增强方法都适合于数据集不足的应用,对于不同的应用场景需要具体分析,数据增强要保证原始数据、增强后的数据以及测试数据满足同一分布。本文的钢筋计数应用中的单个钢筋具有旋转不变性,故可以使用几何变换的数据增强方法,同时,考虑由于实际应用场景受光照、拍照角度等因素的影响,为了让模型训练学习的更全面,我们还使用了噪声扰动的数据增强方法。对钢筋图像训练集使用旋转和随机剪裁增强方法强制目标检测模型学习这些变换方式,一方面使模型学习的数据更全面,同时数据增强起到了正则化的作用,这样可以减小模型的结构风险,提高模型的鲁棒性,防止发生过拟合。本文使用imgaug方法对钢筋图像做了旋转、随机裁剪以及噪声扰动这3种方式的数据增强,增强后训练集约有10 000张图像,imgaug方法支持图像中关键点和目标边框一起变换,故对图像进行旋转和剪裁操作图像中目标的坐标也会随之发生变化,减少了大量的人工标注的工作量。图3为随机剪裁增强后的钢筋图像,图4为扰动增强后钢筋图像。

图3 随机剪裁后的钢筋图像

图4 噪声扰动后的钢筋图像
本文使用了在ImageNet数据集上的预训练模型对钢筋检测模型进行微调。ImageNet数据集由李飞飞教授团队在2009年发布,包含了超过2万类物体,共计1 400多万张图片,为整个人工智能领域奠定数据基础,诸多计算机视觉任务都是在ImageNet数据集上进行预训练,将预训练得到的参数应用在相应的目标任务上作为初始参数,在新模型训练过程中慢慢调整参数,以取得较好的效果。卷积神经网络底层提取的图像特征更为一般化,包括边缘特征、纹理特征等特征,而顶层才会提取到图像特有的高级特征,在目标检测算法中加入微调,即使算法中的卷积神经网络只需侧重于提取高级特征,这样效果会比原始的网络提升很多。本文使用了同类深度学习模型中精度较高的深度残差网络ResNet101的 预训练模型[7],ResNet101包含100个卷积层,一个全局平均值池化层和一个1 000维的全连接层,去掉最后的全局平均值池化层和全连接层,最后加上了一个1 024维的1×1卷积层用以降维。
本文提出的基于小数据的目标检测系统架构如图5所示,其中底层为基础的数据层,数据层主要是产生高质量的数据以供服务层的算法模型使用,数据对于一个算法模型至关重要,需要为算法提供足够多、高质量的数据,除先验知识外,算法能达到的最佳性能受限于数据所提供的有用信息容量,当算法性能接近某个极限时,不管如何改进算法,基本没有意义,但是通过增加有用的数据集却可以提高算法准确性。架构的第二层为服务层,在服务层封装基于小数据的目标检测算法,对外提供调用接口。第三层为接口层,接口层介于应用层与服务层之间,应用层通过接口层的接口服务模块调用钢筋识别能力服务,接口层兼有任务分配和记录功能,支持HTTP协议。顶层为应用层,对接终端,用户通过发送请求便可以快捷地使用算法模型,图6为终端调用钢筋识别算法进行钢筋计数,工地用户只需将待计数的成捆钢筋进行拍照,将拍摄后的照片上传即可快速地得到图片中钢筋的数量,该方法相比于传统的人工计数更准确、更便捷。

图5 基于小数据目标检测算法的架构

图6 终端调用钢筋识别算法进行钢筋计数
3 实验
本文的实验在NVIDIA TITAN XP 12G显卡、64G内存、Ubuntu操作系统的计算机上运行,实验中使用的编程语言为python3,深度学习框架为PyTorch,Py-Torch是一个实现机器学习算法的接口,同时也是执行机器学习算法的框架,具有简洁、快速、易用的特点。本文使用的250张原始数据集为网上公开的钢筋图像。
在目标检测问题中,目标的分类和定位都需要进行评估,每张图像都可能具有不同类别的不同目标,因此,在图像分类问题中所使用的标准度量不能直接应用于目标检测问题,目标检测问题中常用的度量指标为均值平均精度(MAP——Mean Average Precision),即将所有类别的平均精度求和除以所有类别,如式(1)所示。
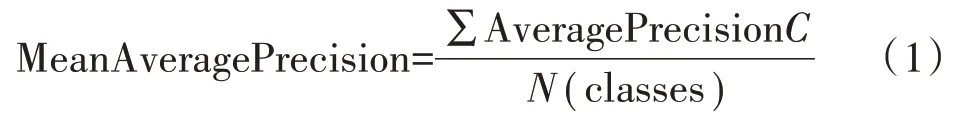
本文使用的IoU(目标框和预测框的交并比)阈值为0.5,若IoU>0.5则认为是正确的检测,否则认为是错误的检测,给定一张图像的类别C,计算其Precision如公式(2)所示,图像正确预测的数量除以在这张图像上这类目标的总数量。

C类目标的平均精度为在验证集上所有图像对于C类的精度值的总和除以有C类目标的所有图像的数量,如公式(3)所示。

Faster R-CNN目标检测算法的损失主要分为RPN网络的损失和Faster R-CNN的损失,计算方法如公式(4),并且两部分都包含分类损失和回归损失。计算分类损失用的是交叉熵损失,而计算回归损失用的是Smooth_l1_loss,Smooth_l1_loss损失和L1损失基本相同,只是当L1误差值非常小时,表示为一个确定值σ,在计算回归损失的时候,只计算正样本(前景)的损失,不计算负样本的位置损失。
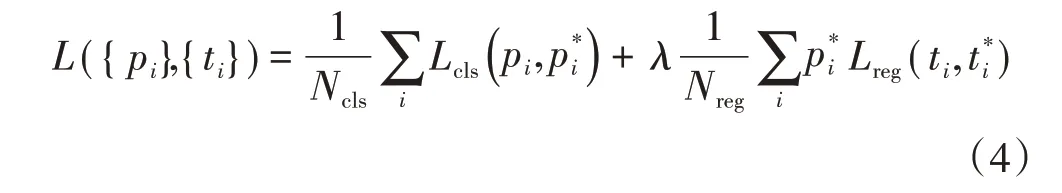
图7为本文提出的基于小数据的目标检测算法和Faster R-CNN算法训练损失的变化,基于小数据的目标检测算法的分类损失和回归损失均比原始Faster R-CNN算法低很多,同时有效地防止了模型过拟合,加速收敛。此外,基于小数据的目标检测算法的mAP为98.2%,比原始Faster R-CNN提高了2.1%,图8为基于小数据的目标检测算法的识别结果,图9为基于Faster R-CNN算法识别的结果。通过以上结果证明本文提出的小数据钢筋检测模型在钢筋图像数量不足的情况下显著地提高了钢筋计数的准确率和泛化能力。
4 总结与展望

图7 2种算法的训练损失变化

图8 基于小数据目标检测算法的检测结果

图9 Faster R-CNN算法的检测结果
本文提出了基于钢筋训练数据集不足情况下的小数据目标检测模型,该模型可用于工地复杂环境中,工地工作人员只需将拍摄的钢筋图像上传至该模型,便可以快速得出钢筋的数量,相比于传统的人工计数方法,更高效、准确。同时,该模型在一些特殊情况下识别效果有待提高,例如钢筋长短不齐、存在遮挡等情况,后续需根据实际应用场景出现的各种情况进行针对性的算法优化。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
山东冶金(2022年1期)2022-04-19 13:40:24
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
中等数学(2020年8期)2020-11-26 08:05:58
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
今日农业(2019年15期)2019-01-03 12:11:33
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
红领巾·探索(2017年8期)2017-08-04 19:09:52
中国质量监管(2016年10期)2016-07-10 10:24:23
