
基于SDN的两级大象流负载均衡策略
2020-03-19 06:04杨桂芹
兰州交通大学学报 2020年1期
白 雪,杨桂芹
(兰州交通大学 电子与信息工程学院,兰州 730070)
庞大的SDN数据中心网络中,存在两种数据流量:一种为生存时间短的老鼠流,携带信息量小;另一种为生存时间长的大象流,携带信息量大[1],当有大量的大象流出现在数据中心网络中会产生拥塞等现象,对网络的性能产生影响,因此对于大象流的识别以及大象流的路由转发至关重要,如果对大象流不采用适当的路由策略,将会导致网络负载不均衡,所以对于出现的每一条大象流,均需要精确检测,并将检测出的大象流运用适当的转发策略,使流的传输不影响网络正常运营.在数据中心网络中,最被广泛应用的负载均衡算法为ECMP(equal-cost-multi-path)[2],其核心是将不同的数据流通过哈希算法随机映射到一条可以被选择的最短路径上,但在ECMP算法映射时没有考虑当前网络中链路的实时负载情况,是一种静态负载均衡方式[3],因此会造成网络发生拥塞,不能动态协调全局网络及实现全局网络的负载均衡.
本文针对以上数据中心网络出现的问题,提出一种基于SDN的数据中心网络大象流负载均衡策略,在大象流识别第一阶段通过设定一个自适应动态接受数据包阈值来判定可疑大象流;第二阶段根据流的持续时间,判定真实大象流;最后设计整体负载均衡框架,将大象流检测阶段嵌入到整体负载均衡框架中,实现网络的动态负载均衡,以提高网络的传输性能.
1 大象流检测及整体负载均衡策略设计
1.1 全局网络拓扑获取
通过链路层发现协议(link layer discovery protocol,简称LLDP)识别全局网络拓扑[4],在交换机与控制器连接成功之后,Ryu控制器通过发送LLDP报文与交换机之间进行信息交换,当交换机收到发来的LLDP报文消息时,交换机会向控制器发送相应的端口信息,此时Ryu库中的链路层发现协议模块收集到交换机发来的端口消息,并对端口信息进行汇总,绘制整体的网络拓扑结构,若网络拓扑发生变化,则需要不断更新控制器中拓扑发现的收集信息,因此交换机需要周期的向网络发送LLDP报文协议,当网络发生变化的时候,第一时间对拓扑进行感知、更新,实现此阶段的关键模块在Ryu控制器下的topology模块,该模块文件下的switches.py文件主要负责交换机的监测部分,目录下的dumper.py文件负责调用switches.py文件的监测内容,并传递到控制器进行分析操作.
1.2 全局网络状态收集
通过sFlow检测网络状态,sFlow由sFlow Agent和sFlow Collector组成,两部分协同工作共同实现网络状态的收集,主要通过采样的方式统计数据流中数据包的数量,能够很好的减小网络开销.此处需要用到基础设施Mininet,其中内嵌有sFlow Agent模块,需在开启网络拓扑之后进行端口配置[5],并在终端中开启sFlow Agent模块,与sFlow Collector端口6343连接,将sFlow Agent中获取到的接口统计信息和数据信息封装成sFlow报文,发送给sFlow Collector上进行分析,sFlow Collector负责对sFlow报文分析、汇总、生成流量报告,最后将收集以及统计完成的网络状态信息上传给控制器进行其他操作.
1.3 大象流识别第一阶段
规定若流量的比例超过总流量θ(θ=0.1%)的数据流,将超过的数据流定义为大象流.假定在时间T内检测到的流量为t,用N表示接收到的数据包数量,用pi表示流i接收到的数据包,用ti表示流i的字节大小;若数据流i的流量大于所设定的总流量的数据流比重θ,则判断当ti≥t·θ时数据流i为可疑大象流.但仅根据流量大小判定大象流不能精确的检测出大象流,因此还需使用sFlow对网络的数据流进行检测,利用随机采样数据包的方式对网络数据流实时检测,若按照预先设定好的数据包阈值PT进行大象流的检测,可能会出现错误的检测,即可能将老鼠流误认为是大象流,出现的这种错误识别称之为误检率[6],简称FPR(false positive rate),见公式(1);若在检测大象流的过程中存在漏检的大象流,这种漏检的概率称之为漏检率,简称FNR(false negative rate),见公式(2),且误检率与漏检率的选取直接影响大象流的检测效率.
FPRi=P[pi≥PT|ti (1) FNRi=P[pi (2) 在文献[7]中,提到一种两阶段自适应大象流检测系统.在检测的第一阶段,若发现一个流的数据包数量超过设定的阈值PT,则将该流暂定为可疑大象流,在此阶段检测过程中可能将老鼠流误检为大象流,也可能存在部分漏检的大象流,因此导致第一阶段得到自适应的大象流检测系统发生漏检的概率较高,如若将大量误检的大象流按老鼠流的方式转发,会致使网络发生堵塞,所以在第一阶段大象流检测方法中需要严格控制大象流漏检率的出现,将误检率与漏检率综合考虑,而不仅仅追求最小的平均误检率,因此可总结出数据包数量的阈值PT如式(3)所示. (3) 式中:ε的值为根据网络实时状态所设置的流量监测值.SDN数据中心网络的流量体系规模大、种类多、具有广泛性,在文献[8]中提到在数据中心网络中流量的分布呈双峰分布,其可定义为 (4) 其中:μ为数据流的平均长度;σ为数据流的长度标准差.由于老鼠流与大象流均服从双峰分布,根据这一特点可得到老鼠流与大象流的流量密度分布如图1所示,左边曲线为老鼠流,右边曲线为大象流,左边阴影部分的面积为FNR,右边阴影部分的面积为FPR,因此可得到FNR和FPR计算公式如下: (5) (6) 结合式(3)和式(4),可得最终的优化阈值PT,其计算公式为 (7) 其中:μe表示漏检率最大时流的平均长度;σe表示漏检率的长度标准差. 设网络数据包的字节数为PB(packet byte),若PB的值大于设定的字节数阈值时,则认定该流可能为真实大象流,当字节数PB的值小于阈值时,引出参数count,用来计数PB有几次没有超过规定的阈值.不断检测PB的值,若PB字节数没有超过阈值,即可能存在变质可疑,利用count值进行计数,若达到N时则认定第一阶段检测的大象流变质.具体的算法步骤如下: 1) 对第一阶段识别出的可疑大象流进行判别,第一步需要统计出以上可疑大象流的字节数PB,计算某一时刻字节数公式如式(8)所示.设定一个初始化变量count,用于记录字节数小于一定阈值时的次数. PBt=BCt-BCt-1. (8) 式中:BC表示计数器统计的流累计字节数;BCt表示在t时刻接受的字节数;BCt-1表示在t-1时刻接收的字节数;PBt表示在t时刻单位时间内接收的数据包字节数. 2) 将计算出的PBt值与设定的平均字节数阈值T进行比较,其中T的值设定为超过总字节数的0.1%,若PBt≤T,则此时该流可能变质,将count值加1,进入步骤3);若PBt>T,则该大象流无变质现象[9],重置count值为0,重新计算PBt值,返回步骤1)继续进行监测. 3) 将得到count的值与设定的最大容忍次数N对比,若count SDN控制器接收来自网络的数据流,利用LLDP获取网络拓扑结构,并利用sFlow检测网络状态,对接收的数据流进行分析.将上两节所提到的大象流检测模块嵌入到整体的负载均衡框架中[10-11],若检测为真实大象流,则进行大象流调度算法;若为老鼠流,则用常规的ECMP算法,减少控制器开销.总的负载均衡流程如图3所示. 利用两阶段大象流识别模块识别出大象流,进入路径决策模块.利用Yen-KSP算法从可行路径中计算k条最优路径作为备选路径,根据当前的网络状态计算出最佳转发路径,转发大象流;不断检测网络状态,检测网络拥塞状态[12].若出现网络拥塞,则在k条路径中选取次优先级最佳转发路径,转发数据流;而对于识别出的老鼠流,老鼠流流量少、数量多,并对实时性要求较高.因此本文将检测出的老鼠流用静态ECMP负载均衡算法,避免持续调用控制器带来额外负荷,提高网络的传输速率;并在OpenFlow交换机中根据接收到的数据流进行分析,查看路由表中是否存在该条路径的转发路径.若存在则直接进行转发,不需向控制器发送请求消息;若在路径表中查询不到转发路径,则OpenFlow交换机需向控制器发送Packet-in消息[13],请求控制器来寻找最短路径,然后调用控制器中的负载均衡算法,对发送来的流进行计算;计算完毕后,控制器发送Packet-out下发消息给OpenFlow交换机,OpenFlow交换机再进行流表的安装工作[14];安装完毕后,将安装的流表规则下发到Mininet基础设施层进行流的转发,完成数据传输;与此同时,实时检测网络当前的状态,并不断更新流表,根据网络实时状态调用不同模块进行负载均衡. 在ubuntu系统环境下利用Ryu控制器,以Mininet为基础设置层搭建胖树拓扑图(见图4),完成大象流负载均衡的搭建以及验证工作[15].同时,测量网络的传输时延以及链路利用率,将SDN网络中基于大象流识别的网络负载均衡策略与ECMP算法、Hedera算法进行对比. 网络的传输时延是指网络在传输过程中数据包的传输时间,即发送的数据报文从源主机到目的主机之间的传输时间.网络的传输时延越小,则说明网络传输性能越强.本文通过利用Mininet中的pingall指令来获取路径的传输时延,然后进行累加统计,计算出胖树网络中各路径的传输时延.计算平均传输时延的公式如式(9)所示. (9) 通过不同程度增加流量负载的方式观察各条路径的时延,并在网络基本稳定时计算平均传输时延,测量时延结果如图5所示. 从图5中可以看出,网络的传输时延随负载的增加而增加.当流量负载低于300 Mbit/s时,三种算法时延相差不大,但当负载超过300 Mbit/s之后,三种算法的平均时延的上升趋势都较为明显.是因为随着流量负载不断的增加,网络链路的负载会出现拥塞等情况,因此在流量传输过程中会出现网络时延增加的现象,但从整体来看随着负载的增加,提出的大象流负载均衡算法更能实现链路的负载分担,有效地降低了网络中的平均时延. 网络中链路的平均利用率是指各传输链路数据流实际带宽与传输链路最大可用带宽的比值[16].链路的平均利用率越大,表明网络传输能力越强.获取实际端口占用带宽的方法通过统计交换机的端口信息来实现,并且将统计得到的占用带宽与链路最大可用带宽进行比较,即可得到网络链路的利用率.将得到的带宽进行累加求得平均链路利用率,如公式(10)所示. (10) 依然根据流量负载检测网络中的链路平均利用率,然后计算出平均的链路利用率,如图6所示. 从图6中可以看出,当流量负载低于400 Mbit/s时,三种算法的平均链路利用率十分相似,并且变化不大,这是由于低于400 Mbit/s时链路中剩余的带宽较大,并有足够的带宽传输数据流,因此网络中链路很少会出现拥塞;但当流量负载处于400 Mbit/s~900 Mbit/s之间时,三种算法的平均链路利用率均处于上升趋势,并且上升趋势较为明显,此时的平均链路利用率显出优势来.可看出,提出的算法在一定程度上较ECMP算法和Hedera算法更为提高了平均链路利用率;当流量负载超过900 Mbit/s后,三种算法的平均链路利用率变化趋于平稳并稍有下降趋势.但从整体来看,大象流负载均衡算法较其他两种算法降低了产生拥塞的概率,增加了带宽利用率. 针对目前数据中心网络存在的大象流识别效率低,网络拥塞以及负载不均衡等现象,提出一种大象流负载均衡策略;在大象流的检测算法中重点突出大象流漏检率的检测,第二阶段通过设定数据包阈值对第一阶段的大象流继续进行检测,进一步提高大象流的检测效率,并构建整体框架,调用不同模块实现整体网络的负载均衡;搭建仿真平台,使用网络时延和链路利用率两个指标来验证提出的大象流负载均衡策略.实验结果表明,较之前常用的ECMP算法和Hedera算法相比,提出的大象流负载均衡策略可以实时监控网络状态,将网络实时状态传输到控制器进行处理,通过实验对比验证了提出的大象流负载均衡策略减少了时间延迟,提高了大象流的识别效率,并且提高了链路利用率,为数据中心网络的传输提供一个更好的传输策略.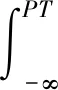
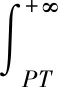
1.4 大象流第二阶段识别
1.5 大象流负载均衡整体流程
2 实验结果分析
3 结论
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16航空学报(2022年7期)2022-09-05网络安全与数据管理(2022年6期)2022-07-13计算机与数字工程(2022年3期)2022-04-07移动通信(2021年5期)2021-10-25汽车维修与保养(2020年10期)2021-01-22民用飞机设计与研究(2020年4期)2021-01-21汽车维修与保养(2020年11期)2020-06-09计算机技术与发展(2020年5期)2020-05-22物联网技术(2018年8期)2018-12-06
