
基于Seq2Seq模型的港口进出口货物量预测①
2020-03-18 07:55贾宇欣林友芳万怀宇
计算机系统应用 2020年3期
王 涛,张 伟,贾宇欣,林友芳,3,万怀宇,3
1(北京交通大学 计算机与信息技术学院 交通数据分析与挖掘北京市重点实验室,北京 100044)
2(天津市商务局 口岸平台处,天津 300040)
3(北京交通大学 综合交通运输大数据应用技术交通运输行业重点实验室,北京 100044)
1 引言
港口进出口货物吞吐量是港口发展战略研究的重要内容,是港口物流规划、物流资源合理配置过程中的重要环节,同时它也为政府和港口管理部门制定科学发展规划以及切实可行的市场开拓策略提供依据.政府可以通过港口物流需求预测评估港口物流行业对当地经济发展的总体贡献,从而制定港口物流行业的发展政策,并引导物流市场资源的合理利用与优化配置.因此,正确地预测港口进出口吞吐量对于合理布局港口、科学制定投资规模和营运策略,以及综合运输规划都是十分重要的.与此同时,天津港作为世界上等级最高的人工深水港,也作为我国北方地区重要进出港口,国内国外辐射广,货物种类多,运输模式复杂,基于多年的港口运行特点形成了自己独有的物流和报关模式,在进口和出口通关数据预测方面十分需要根据目前实际运行状况做深入的梳理和研究,以进一步提高口岸管理信息化和通关作业装备自动化水平,同时提高口岸工作效率[1-5].
根据实际需求,本文研究以天为粒度级同时预测八种不同类型的集装箱吞吐量,具体包括:进口集装箱数量(进口),出口集装箱数量(出口),大集装箱数量(大箱),小集装箱数据(小箱),进口大集装箱数量(进口大箱),进口小集装箱数量(进口小箱),出口小集装箱数量(出口小箱),出口大集装箱数量(出口大箱).不同类别的集装箱吞吐量不仅可以反映港口的承载量变化,也可以反映港口的不同类别的集装箱的变化趋势.
预测不同类型进出口货物的吞吐量是一个非常有挑战性的问题,因为进出口货物的吞吐量受到许多复杂因素的影响.在时间维度上,未来一段时间的货物吞吐量与距离当前时间较近的一段时间以及历史上具有相似特征时间节点上的吞吐量都有很大的关系.另外,由日常工作的规律可知,货物吞吐量具有明显的以日和周为单位的周期性规律,利用这些规律都可以帮助我们有效提高货物吞吐量预测的准确性.进出口货物的吞吐量还会受到天气、节假日、国家政策、外部事件等外部因素的影响.
近年来,深度学习在很多应用领域都取得了很大的成功.循环神经网络[6](RNN),在普通多层前馈神经网络基础上,增加了隐藏层各单元间的横向联系,通过一个权重矩阵,可以将上一个时间序列的神经单元的值传递至当前的神经单元,从而使神经网络具备了记忆功能,对于处理有上下文联系的NLP、或者时间序列的机器学习问题,有很好的应用性.长短期记忆模型(Long Short-Term Memory,LSTM)[7]作为一种改进的循环神经网络,有效地缓解了传统循环神经网络在处理长序列数据时存在的梯度消失问题,被广泛应用于时间序列学习任务上.在LSTM 中输入序列和输出序列必须等长,为了解决输入输出不定长的问题,改进了经典的LSTM,并且加入了编码器、解码器模块.Seq2Seq是一个Encoder-Deocder 结构的模型,输入是一个序列,输出也是一个序列.Encoder 将一个可变长度的输入序列变为固定长度的向量,Decoder 将这个固定长度的向量解码成可变长度的输出序列.受此启发,为了同时刻画货物吞吐量在时间维度上的依赖特性,本文提出了基于Seq2Seq 模型的神经网络结构,用于解决进出口货物吞吐量预测问题[8-11].
基于Seq2Seq 的预测模型首先利用长短期记忆模型刻画货物吞吐量随着时间的推移变化规律.同时,编码器-解码器模块可更好的学习历史货物吞吐量之间在高维隐藏空间的变换模式.该模型还可以对外部影响因素建模,进一步提高进出口货物数量预测准确性.
2 相关工作
近年来,进出口货物量预测已经成为海关进出口贸易的一个重要问题.进出口货物量预测分为定性预测和定量预测两类,在定性预测中研究人员主要关心的是货物量的发展趋势.定性研究方法主要有德尔菲法和专家会议法.而定量问题则更关心进出库货物量的具体大小以及一些细节的变化比如特殊节日,传统的定量预测集中在以年为单位进行预测,更关注整年的情况.本文研究的问题属于定量预测问题,而且预测的单位为天级别,可以做到更细粒度的预测,这个问题的难度更大,更具有研究与实际应用价值.
进出口货物预测的核心研究对象是时间序列数据.早期的研究主要采用经典的时间序列预测模型,如自回归滑动平均模型(Autoregressive Moving Average,ARMA)[12],自回归积分滑动平均模型(Autoregressive Integrated Moving Average,ARIMA)[13-15].基于ARIMA模型,一些扩展模型如SARIMA[16]、KARIMA[17]、VAR[18]以及STARIMA[19]等被提出来以适应不同的预测问题.然而,此类时间序列预测模型具有很大的局限性,其预测结果通常很难满足人们的要求.
随着大数据技术越来越成熟,学者们在解决时间序列的预测问题时,开始关注并重点研究数据驱动的模型.其中应用得最多的模型包括支持向量回归模型(Support Vector Regression,SVR)[20]和多元线性回归模型(Multivariable Linear Regression,MLR)[21]模型以及回归决策树模型(Regression Decision Tree,RDT)[22].其中,SVR 模型通过核函数将数据映射到高维空间以描述交通数据的非平稳变化特征,但其预测结果的好坏很大程度上取决于核函数的选择.MLR 和RDT 模型则比较关注于特征的选择方式,很多学者针对不同的需求设计了不同的机器学习模型[23-25]用于特定场景下的进出口货物数量问题.
近年来,因为深度神经网络强大的表示能力,基于深度学习的模型在时间序列预测问题当中应用越来越广泛,此类模型中的两个重要分支分别是基于BP 神经网络的模型和基于循环神经网络(Recurrent Neural Networks,RNNs)的模型[26-28].BP 神经网络,即反向传播网络,它是利用非线性可微分函数进行权值训练的多层网络,具有极强的容错性、自组织和自学习性,有着较好的函数逼近和泛化能力.作为第二类重要分支的循环神经网络常被用于序列数据学习任务[9,29,30].其中,长短期记忆模型[31]在文本分析[32]、语音识别[33]以及机器翻译[34]等序列数据学习任务中都取得了巨大的成功.基于长短时记忆模型的Seq2Seq 模型则克服了其输入输出定长的缺陷,可以更灵活的进行预测.在进出口货物数量预测问题中,我们希望预测模型能够自动学习过去一段时间数据之间的依赖关系,而不需要人为发现其中的联系.因此,本文提出一种基于Seq2Seq的深度学习网络结构来解决这一问题.
3 问题描述
本节对货物进出口数量预测问题进行形式化描述,首先对历史进出口货物数量的整体数据特征进行描述,然后在此基础上对问题进行形式化定义.
图1 是其几种不同类型的集装箱吞吐量的历史变化趋势图.类别分别为大箱进口,小箱进口,大箱出口,小箱出口.如图1 所示,不同类别的集装箱以天为单位在时间轴上连续分布,形成连续的时间序列,因此港口进出口货物问题是一个典型的时间序列预测问题.

图1 不同种类别集装箱数据趋势变化
本文的研究问题是依据不同类别的集装箱吞吐量历史数据来以周(7 天)为级别预测未来的集装箱数量.
问题定义.给定不同类别进出口货物历史统计值{Xt|t=1,2,…,n},预测Xt+△t.其中Δt∈{1,2,…,7}表示待预测的时间区间与当前时间区间t 之间的跨度,即预测未来一周的数量.
4 基于Seq2Seq 模型进出口货物量预测方法
本节将详细介绍基于Seq2Seq 神经网络模型的进出口货物量预测方法.Seq2Seq 是RNN(循环神经网络)的一个变种,它是一个Encoder-Decoder 结构的网络,它的输入是一个序列,输出也是一个序列,Encoder中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标信号序列.这个结构最重要的地方在于输入序列和输出序列的长度是可变的.将Seq2Seq 网络应用于时间序列预测问题,可以根据历史一段时间的信息,去预测未来一段时间的数据情况,通过神经网络的记忆性、容错性、自学习性来拟合预测函数,从而进行时间序列问题的预测.
4.1 问题分析
在进出口货物预测问题中存在4 种时间依赖特性,分别为:短时依赖(closeness)特性和周周期依赖(week influence),节假日影响(holiday influence)特性,特殊情况影响(special influence).例如,图2 是港口进口集装箱量在某段时间的以天为单位的变化情况,很明显地展示了港口集装箱吞吐量的3 类时间依赖特性.

图2 进口集装箱变化曲线
1)短时依赖特性:体现在某一天的集装箱数量与其前面刚刚过去的几天内的集装箱量对预测该天的影响,即相邻天集装箱数量之间存在很强的相关性.
2)周周期依赖特性:体现了集装箱数量以星期为单位的周期性规律.历史上相同的周次之间之间存在一定的联系,以此类推即集装箱吞吐量会受到当前日期的星期数的影响.
3)节假日影响特性:体现了节假日(周六,周日,法定放假节日等)与非节假日的区别,节假日之间的联系,还包括节前补班与节后上班之间的差异.图2 中节假日显示出明显的差异.
4)特殊情况影响特性:体现在每个月的月末出现的集装箱变化异常,以及特殊政策因素造成的影响.
根据以上分析结果,我们进行了相应的特征构造.根据反复的特征构造实验以及实验结果,我们确定以星期(1-7),是否节假日,是否补班,月底(月末一周),放假前(前3 天)作为最优特征组合,以上特征反映货物进出口数量在时间维度上的所有特性.
4.2 模型结构
图3 是本文提出的基于Seq2Seq 的神经网络模型的完整网络结构.该模型可以将短时依赖特性、周周期依赖特性、节假日影响、特殊情况影响全部都考虑进去,并进行规律的学习.

图3 基于Seq2Seq 的神经网络结构
图3 的底端表示模型的输入.输入以3 周作为一个窗口,前两周的特征矩阵作为Encoder 层的输入,后一周的集装箱量的值作为Decoder 层的输出,Decoder层的输出与真实值作为损失函数计算的输入.每一个窗口的输入由21 天组成,用input= [day1,day2,day3,…,day14]表示每一个窗口里Encoder 层的输入,dayi=[“Holidays”,“Work”,“Month_end”,“Before_holidays”,“Days1”,“Days2”,“Days3”,“Days4”,“Days5”,“Days6”,“Days7”] 其中dayi∈input.dayi表示特征向量,采用one-hot 方法表示.
output= [day15,day16,day17,…,day21],output向量表示当天真实的货物进出口数量.这样每一个训练窗口window= [input,output],表示由Encoder 层的输入和Decoder 层的输出维度大小组成的向量,每一个window为 21×12.具体含义见表1.基于深度学习的Seq2Seq 模型中有很多需要学习的参数,所以需要大量训练样本.本文提出一种滑动窗口样本构造方法,在给定历史时间(单位:天)的集装箱数据上,可构造出更多训练样本.本方法尤其适用于历史数据量不充分的情况.每一个训练的窗口window大小为连续21 天的数据,然后以天为单位向后滑动窗口,类似于TCP 的滑动窗口选择[35].假设总数据有N个点(N> 21),那么就可以构造(N-21 + 1)个窗口,极大提高了独立样本的数量.滑动窗口可很好刻画集装箱量的短时依赖特性,保证数据在时间上的连续性,充分利用每一天的数据,且可以实现数据在时间维度上的交叉验证即数据在不同的窗口内既可以充当测试集也可以充当验证集,可以更好的优化学习参数.
图4 表示单层Seq2Seq 网络结构,Source 表示网络输入,h(x)和H(x)分别表示LSTM 的cell,在每一层网络里Encoder 将输入Source 序列转为上下文向量(context vector)C,Decoder 将C转化为输出序列.

表1 特征向量表示

其中,i∈[15,21]且F和G分别表示编码器和解码器模块.
模型的训练以最小化损失函数为目标.我们将损失函数定义为每个窗口里的集装箱数量的真实值和预测值之间的平均绝对误差,我们以表示模型输出值,dayi表示真实大小,其中i∈[15,21].

其中,θ包括Seq2Seq 模型中所有需要训练的参数.
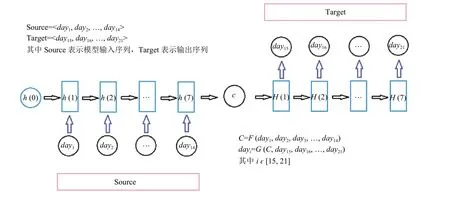
图4 单层Seq2Seq 网络结构
基于Seq2Seq 的预测模型相比于其他方法强调模型结构的深度,突出特征学习的重要性,通过逐层特征变换,将样本在原空间的特征表示变换到新特征空间,并将时间及外部特征进行编码、解码的高维度映射,使预测结果更准确.
5 实验与结果分析
5.1 数据集
实验数据集为天津港历史集装箱吞吐量数量数据集(TJ_DataSet),数据集的统计信息如表2 所示.

表2 数据集统计信息
5.2 数据预处理
(1)无效数据过滤
首先对分析数据,剔除异常数据,异常原因主要有关检融合,系统未普及等,数据清洗后选定数据质量良好的时间段,即2018-3-1~2018-8-25 为实验数据集.
(2)滑动窗口
实验采取滑动窗口的形式来组织训练集和测试集,将原始数据按类别(大箱/小箱/进口大箱/进口小箱/出口大箱/出口小箱/进口/出口)、时间顺序排列,数据总量为2018-3-1 到2018-8-5,共185 个点,每个时间窗口的大小为21 天(2 周输入,1 周输出),并按天滑动.训练集与测试集的比例为7:3,总窗口数为164 个,其中训练集窗口个数为126 个,测试集窗口个数为28 个.
(3)数据标准化
对集装箱量大小进行min-max 标准化,进行标准化可以加快模型的收敛速度以及提高模型的精度.
5.3 基准方法与评价指标
本文将Seq2Seq 模型和以下4 个基准方法进行比较.
(1)RDT:回归决策树模型,是一种基于决策树的回归模型.
(2)SVR:支持向量回归模型,SVR 是使用SVM(支持向量积)来拟合曲线,从而进行回归分析,是一种应用广泛的时间序列预测方法.
(3)MLR:多元线性回归模型,是在线性回归的基础上进行时间序列拟合.
(4)LSTM:长短期记忆模型,是一种循环神经网络模型,擅长处理序列类型的数据.
本文使用均方根误差(Mean Absolute Deviation,MAE)作为模型预测效果的评价指标:

其中,dayi表示集装箱数据的真实值,表示集装箱数据的预测值,n表示连续天数大小.
5.4 TJ_DataSet 数据集实验
在TJ_DataSet 数据集上验证了基于Seq2Seq 神经网络的预测效果.模型的超参设置见表3 所示,预测结果如表4.
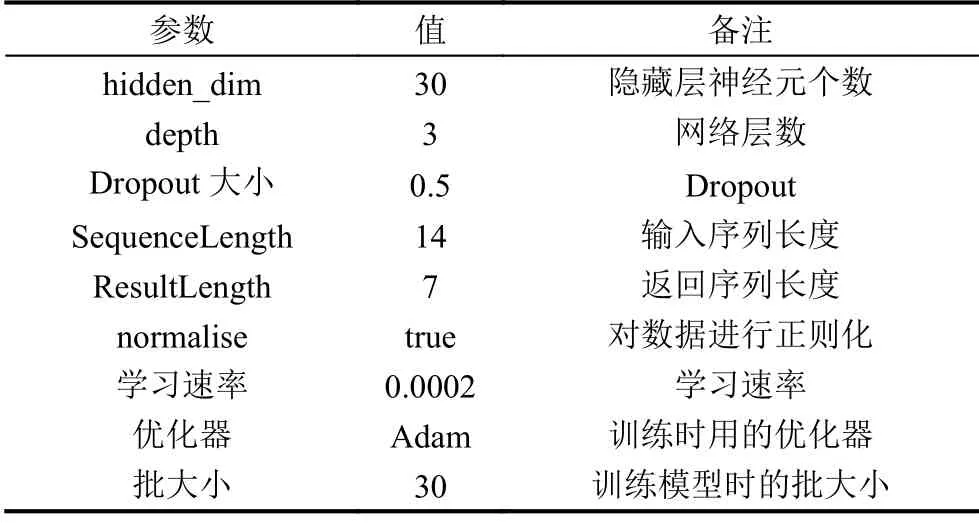
表3 Seq2Seq 中的超参设置

表4 各种方法预测结果
如表4 所示,基于Seq2Seq 的神经网络明显比其他基准方法要好,在大箱进口,大箱出口,小箱出口,进口,出口,大箱,小箱这7 种类别上,Seq2Seq 方法的MAE明显比其他所有的方法要好,在小箱进口上基于RBF 核的SVR 表现要略好一点,通过对小箱进口的数据进行分析发现,测试集种小箱进口的数据短期依赖性比较差,而SVR 可以在长期记忆性上做的更好一些.Seq2Seq 模型相对于单独的LSTM 模型具有较大优势,首先Seq2Seq 可以通过更长时间的数据来学习短期内的一段数据,而LSTM 只能通过定长的时间来学习并预测与之等长的时间序列,而且Seq2Seq 的编码器-解码器模块具有更高维度上的拟合性.
各种类型的集装箱数量预测图如图5 所示,这里截取测试集中2018-7-3~2018-7-31 这一时间段的进行展示.由图5 可以看出来,模型在未来一段时间内的预测效果相对较好.其中7-23 到7-27 这一周出现明显的误差,后经过业务分析,这一周的确存在因为关检融合造成的原数据不准的情况,进一步说明了模型的稳定性和正确性,并且具有一定的异常纠错功能.

图5 模型预测效果图
6 结束语
本文提出一种基于Seq2Seq 的神经网络模型用于解决港口货物量预测问题.基于Seq2Seq 的模型可以同时对影响港口货物量变化的两类因素,即时间依赖以及外部影响因素进行建模.基于Seq2Seq 的神经网络模型结合长短期记忆模型和编码器、解码器模块能够学习港口货物量数据的时间特征,最终通过滑动窗口的学习方式,得到准确的预测结果.我们将基于Seq2Seq的模型和经典的时间序列预测模型、机器学习模型,基于深度学习的预测模型同时在相同的数据集上进行了对比实验,实验结果表明基于Seq2Seq 的网络在不同数据集上取得了7 种类型下的最优和一个类型下的次优的预测效果.但该方法还有优化的空间,比如其他外部特征比如政治因素,经济形式,天气,股票等,也会对集装箱的吞吐量大小产生一定的影响,但这部分因素难以进行合理量化,可作为后续模型调优的方向.
猜你喜欢
进出口经理人(2020年11期)2020-11-24
进出口经理人(2020年10期)2020-11-17
小猕猴学习画刊(2019年9期)2019-11-08
世界热带农业信息(2017年3期)2017-07-13
小天使·三年级语数英综合(2017年6期)2017-06-07
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
集装箱化(2014年2期)2014-03-15
娃娃画报(2009年11期)2009-12-07
