
基于协同训练算法的微博垃圾评论识别
2020-03-18 09:42曹春萍杨青林
智能计算机与应用 2020年10期
曹春萍, 杨青林
(上海理工大学 光电信息与计算机工程学院, 上海 200093)
0 引 言
微博,微博客(MicroBlog)的简称,通过微博这个平台可以发布、分享和获得信息。微博能够更新140字之内的文字信息,实现信息的即时分享。随着微博的流行,微博评论也随之具有研究价值。微博评论有二种不同注解:
(1)针对社会问题、现象直抒胸臆发表的见解、意见, 与述评或杂文类似;
(2)对于微博发表的后续评论。
通过这些评论,能够了解民情、民意,以及一些事件的具体情况和后续进展。但是微博评论中存在大量垃圾评论。垃圾评论是指一些没有任何意义或用户带有某些目性质的微博评论,这些评论是由用户随便或者故意发布的不真实的甚至是带有欺骗性质的评论信息,垃圾评论制造者通过发表评论发泄负面情绪、制造舆论或推销产品。这些垃圾评论影响读者情绪,浪费网络资源,还对面向评论的数据挖掘工作造成干扰[1]。因而,识别微博中垃圾评论显得极其重要。识别微博中垃圾评论不能只考虑单一因素,只考虑单一因素会使识别不准确。为此,本文从评论文本和评论用户两个视图选取多种特征,采取协同训练算法,以更好识别微博垃圾评论。
1 相关研究
微博垃圾评论一般分为:
(1)广告评论与超链接评论;
(2)与评论无关的信息;
(3)重复评论;
(4)与微博内容不相关的其他评论;
(5)虚假评论。
国内外学者提出了一系列方法来识别垃圾评论,主要集中在3个方面:电子商务、博客和微博。对于微博的评论主要依据内容来识别。例如:黄玲等提取表示微博评论的8个特征值向量,这8个特征值向量包括相似度、超链接数、评论重复数、情感词数、广告词数、句子长度、名词度、评论的被评论数,通过AdaBoost算法在这些特征上训练出若干个弱分类器,弱分类器加权集合成强分类器来识别微博垃圾评论[2],但是对于短小评论和虚假评论识别效果不好;李志欣等提取特殊符号的数量、URL 的数量、情感词的数量、点赞的数量、句子长度、名词比重等6个特征构建AdaBoost分类器和支持向量机分类器,通过Co-Training算法进行协同训练,判断其是不是垃圾评论[3],但对于虚假评论和短小评论识别结果欠好。
目前微博垃圾评论识别,仅仅从评论自身特征出发,而忽略评论者的一些特性,识别效果差。
在电子商务和博客领域,识别垃圾评论很多时候是从内容和评论者特征两方面着手。如:在电子商务领域,Jindal等人提出垃圾评论检测,将产品评论中垃圾评论分为3类:虚假评论即只针对品牌的评论以及非评论;从评论内容即评论者以及被评论的产品3方面提取特征,采取构造二类分类器的方法对产品评论进行分类[4];在博客领域,将垃圾评论分为二大类,对博客中显示垃圾评论用基于规则的方法识别,对隐式垃圾评论采取基于主题的特征选取和基于主题的检索模型二种方法来识别,从评论、评论者、作者、博文4方面出发构建特征集。
本文提出基于协同训练的微博垃圾评论识别方法,在特征提取时从评论文本和评论用户二个视图选取多种特征,从7种分类方法中选出合适的基分类器,通过协同训练完成对微博垃圾评论的识别。
2 基于协同训练的微博垃圾评论识别方法
2.1 识别流程
微博垃圾评论识别流程如图1所示。
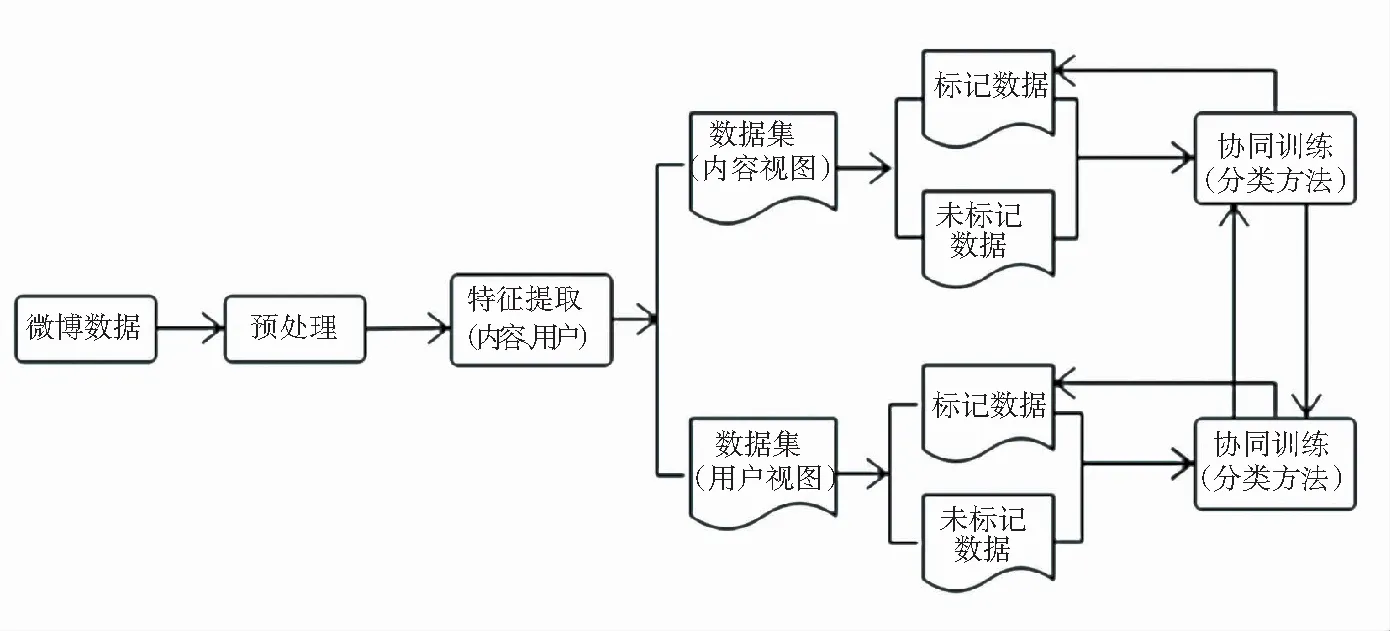
图1 微博垃圾评论识别流程
在识别过程中,首先对数据预处理,提取评论内容和评论用户的特征,选择出合适的基分类器,在每个视图中,利用有标记数据和部分未标记数据训练分类器,然后进行垃圾评论识别。
2.2 数据预处理
数据预处理主要包括二方面:
(1)微博评论文本清理,清理微博评论中的噪声数据包括评论、回复、转发、@及其用户名、评论中的图片、日期等;
(2)采用IKAnalyzer工具对微博原文和评论分词,以便于下一步的特征提取。
2.3 特征提取
特征提取是微博垃圾评论识别流程中的重要步骤,本文从评论内容和评论者二个方面对特征做细化,以便协同训练,具体内容见表1。

表1 特征指标集合
2.4 协同训练算法
协同训练的基本步骤:首先从数据集中选出部分评论,对这些评论进行标注,将数据集分为有标注数据集L和无标注数据集U,从U中随机选取2p+2n的数据放入缓冲池U1中;在迭代过程中,利用L的两个子集L1和L2分别训练得到分类器h1和h2, h1和h2分别挑选置信度最高的(p+n)个正反例给对方,以便训练更新;将2p+2n个标记好的数据加入到L中,再次从U中随机选出2p+2n个数据放入缓冲池U1中。协同训练迭代算法步骤描述如下:
输入有标注数据集L,无标注数据集U;
输出分类器h1和h2
(1)根据有标注数据集L得到基于2个视图的已标注数据L1和L2;
(2)从未标记数据U中随机选取u个示例放入缓冲池U1中;
(3)使用训练集L1训练出分类器h1;
(4)使用训练集L2训练出分类器h2;
(5)h1在U1中挑选置信度最高的p个正例和n个反例,加入到L2中;
(6)h2在U1中挑选置信度最高的p个正例和n个反例,加入到L1中;
(7)将以上2p+2n条评论从缓冲池U1移除;
(8)从U中随机产生2p+2n个未标记样本放入缓冲池U1;
(9)U为空或分类器不发生改变或迭代次数达到最大值,停止迭代。
3 实验结果与分析
3.1 数据集
本文从新浪微博上抓取评论得到评论数据集,包括用户名为头条新闻发表的“雪乡宰客”微博,用户名为奢车志发表的“奔驰漏油事件”微博,用户名为央视新闻发表的“巴黎圣母院火灾”微博,用户名为腾讯体育发表的“周琦发球失误”微博。
3.2 实验评价标准
本文参考相关研究,采用F-measure方法作为评价指标,评价标准包括召回率R、查准率P、准确率Accuracy以及综合评价指标F-measure值。建立混合矩阵,见表2,并计算相应的评价指标值。
(1)召回率。测量被正确提取的信息的比例,公式(1):
(1)
(2)查准率。测量提取出的信息中有多少是正确的,公式(2):
(2)
(3)准确率。整体的正确率,公式(3)
(3)
(4)综合评价指标F-measure,评论F1,公式(4):
(4)

表2 混合矩阵
3.3 基分类器的选择
使用相同训练集,在不同视图特征上,分别测试了随机森林算法(RF)、朴素贝叶斯算法(NB)、K近邻分类算法(KNN)、逻辑回归算法(LR)、决策树算法(DT)、支持向量机算法(SVM)、梯度提升决策树算法(GBDT)的分类性能,以构造基分类器,结果为图2所示。
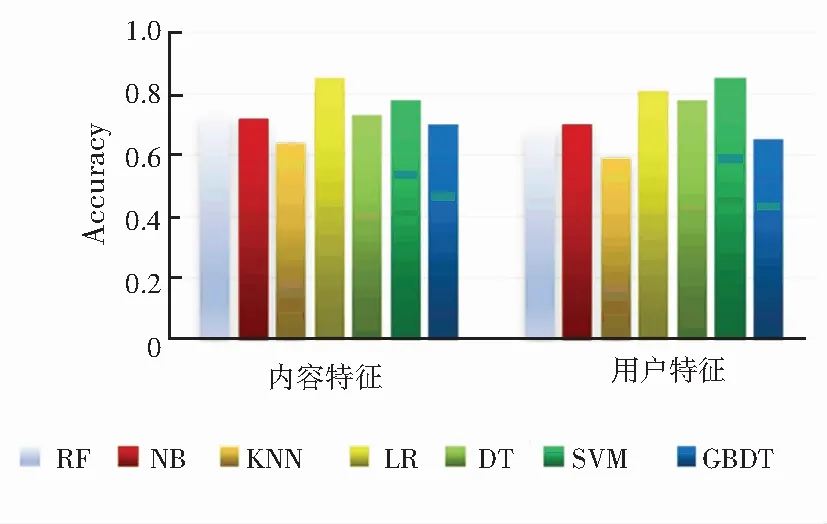
图2 不同视图特征上分类器的总体准确率
由图2可知,LR与SVM的性能要比剩余几种分类模型要好,因此实验中选择LR与SVM作为协同训练的二个基分类器。测试LR与SVM互相结合形成的4种协同方式的分类性能,结果见表3,其中h1为评论内容特征视图上的分类器,h2为评论用户视图上的分类器,组合1的分类性能最佳。因此选取组合1作为本文方法所选用的基分类器组合。
3.4 实验结果及分析
为了验证本文方法的有效性,设计了几组对比试验方法:
(1)采用LR和DT作为基分类器的协同训练算法;
(2)采用从相似度和其它内容特征分为两视图的协同训练算法[5]。
不同方法采用相同的训练集和测试集。二个对比实验以及本文方法实验结果见表4,可以看出本文从评论内容和评论用户二个视图建立基分类器协同训练的方法是有效的。
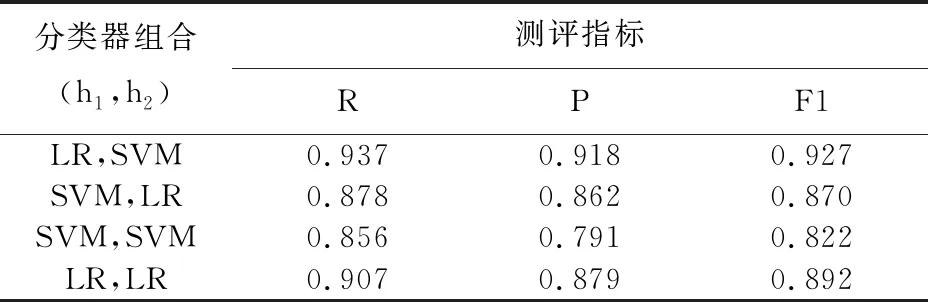
表3 不同分类器组合识别结果
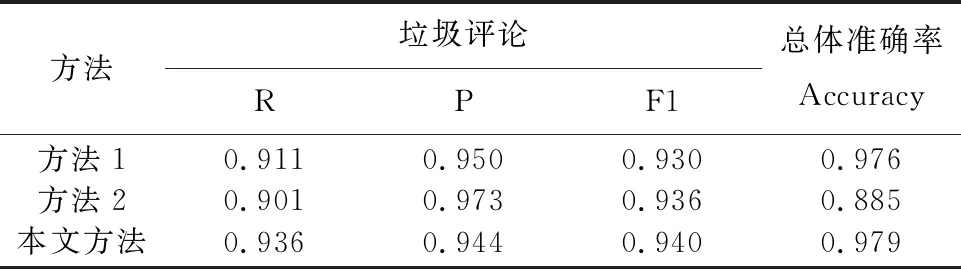
表4 不同方法的识别结果对比
4 结束语
本文针对之前微博垃圾评论识别研究时忽略了评论用户特征这一缺点,从评论内容和评论用户二个视图构建基分类器进行协同训练。实验结果表明,本文的方法是有效的,对于垃圾评论的识别取得了良好的效果。但是对于短小评论的识别效果仍然不佳,下一步将考虑提高只有几个文字的短小评论的识别效果。
猜你喜欢
社会科学战线(2022年9期)2022-10-25
现代电子技术(2022年15期)2022-07-28
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
民生周刊(2017年19期)2017-10-25
软件导刊(2017年4期)2017-06-20
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
