
基于融合聚类算法的电子商务产品垃圾评论识别研究
2020-03-10 02:56陆佳涣
智能物联技术 2020年2期
柳 毅,钱 枫,顾 虎,陆佳涣
(1.杭州电子科技大学管理学院,浙江 杭州 310018;2.杭州市质量技术监督检测院,浙江 杭州 310018)
0 引言
电子商务产品评论中往往会夹杂着垃圾评论,而且与占大部分的有效评论相比,在语义相似度上非常低(如与当前产品无关的没有利用价值评论或不包含任意观点、难以辨别情感倾向的随机文本)。Jindal和liu[1]在2007年最早提出垃圾评论识别问题。垃圾评论识别研究的难点在于如何更有效地对评论文本、用户等因素进行特征挖掘或者表征学习,进而提高垃圾评论检测的准确性[2]。Li等人[3]从词性特征角度,发现有效评论与垃圾评论在词性特征上有较大的区别,分别呈现如下特点:有效评论的文本中一般包含更多的名词、形容词、介词、限定词等,而垃圾评论的文本中往往包含更多的动词、副词、代词等。Mukherjee等人[4]在Yelp数据集上采用词袋特征以及词性特征,采用支持向量机作为分类器,发现在酒店及饭店领域数据集上的准确率达到65.6%和67.8%。景亚鹏[5]首次尝试采用深度学习算法识别垃圾评论,首先采用信息增益(IG)进行特征选择,然后分别采用普通神经网络、DBN-DNN网络、LBP网络三种算法进行垃圾评论检测实验;在实验中,深度学习算法表现出更为优异的性能,其在数据集上准确率最高可以达到92.5%,优于支持向量机89.6%的准确率。Abbasi等人[6]使用卷积神经网络(CNN)将评论文本转换成词向量,将表示文本的向量作为输入特征进行分类,取得了较好的实验效果。从语义表示学习角度,Lau等人[7]基于语义相似性计算,提出了语义语言模型,通过计算评论文本的语义相似度对垃圾评论进行检测,该方法在实验中的AUC(Area under the Curve of ROC)值为99.87%,大幅度优于支持向量机(SVM)的55.71%。谭文堂等[8]从元数据的角度,认为评论的元数据为除文本内容之外的特征,如发表时间、评论星级、用户等级等,评论的元数据特征有助于识别垃圾评论。Al Najada H.等[9]研究者均进行了将元数据特征运用于垃圾评论检测的实验,结果表明加入元数据特征能够有效提升对垃圾评论的识别准确率。
本文将电子商务评论文本转为向量,构建领域性停用词表,更好完成去停用词操作,并基于无监督学习的融合聚类算法[10]进行垃圾评论识别。电子商务垃圾评论由于在语义上与有效评论距离较大会被分到主要簇之外,形成小簇或者离群点,达到识别区分垃圾评论的目标。然后通过Python爬虫抓取苏宁易购上消费类电子产品的评论数据,实验验证本文提出的DBSCAN(Density-Based Spatial Clustering of Applications With Noise)和Mean Shift融合聚类算法提高对电子商务垃圾评论识别的准确性。
1 电子商务产品垃圾评论识别算法
1.1 均值漂移(Mean Shift)
均值漂移算法通过迭代更新质心的候选位置偏移量进行漂移,这些侯选位置一般是所选定区域内全部样本的均值。并且这些候选位置在之后阶段将被过滤以避免近似重复,从而形成最终质心集合。算法会自动确定最终聚类数目,同时也可以指定初始质心。参数带宽(band width)是决定搜索区域大小的参数。图1是Mean Shift算法质心依据偏移量进行漂移的过程示意图。

图1 Mean Shift漂移过程示意图Figure 1 Process of Mean Shift
对于数据集X∈Rd中的某样本点xi,其Mean Shift向量基本形式如式(1)所示。
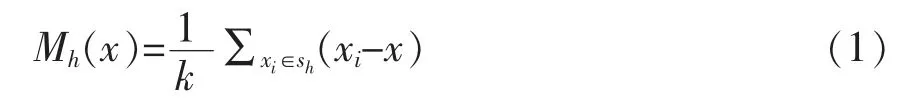
其中,Sh指到点x的距离为h的高维球形区域,其定义如式(2)所示。
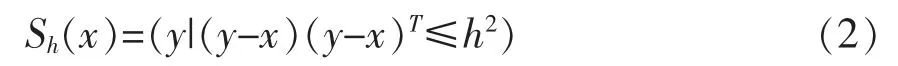
式(2)中假设在半径为h的球形区域内的每个点对点x的贡献是一样的。但是实际上这种贡献与距离是相关的,即重要程度与距离是相关的。基于这种情况,有研究者提出了加入核函数的漂移向量,即对每个区域内的点加上了权重,改进后的向量形式如式(3)所示。
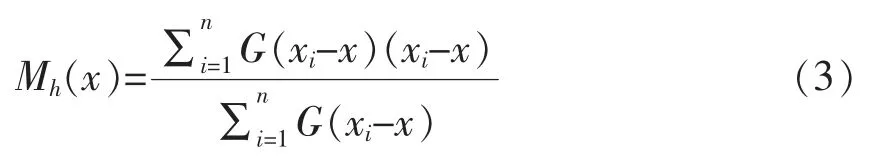
其中,G(x)是核函数。核函数种类有很多,如常用的高斯核。Mean Shift算法的具体计算过程如表1所示。

表1 Mean Shift算法的具体计算过程Table 1 Calculation process of Mean Shift algorithm
1.2 DBSCAN
DBSCAN是通过寻找被低密度区域分隔的高密度区域来完成的聚类算法。一组彼此靠近的核心样本和一组接近核心样本的非核心样本,组成一个簇。DBSCAN使用基于中心的方法来定义密度,然后根据基于中心的密度对点进行分类。该方法将点分类为三种:核心点、边界点和噪声点。DBSCAN核心点(core samples)属于高密度区域的样本,如果在该点的给定领域内点的数量超过阀值Minpts,则该点为核心点。领域由距离参数Eps决定,其中参数Eps和Minpts均由用户指定。边界点落在某个核心点的领域内,但其不是核心点,并且可以落在多个核心点的领域内。噪声点是既不是核心点也不是边界点的任何点。图2形象说明DBSCAN算法的核心点、边界点、噪声点这三类点的区别。
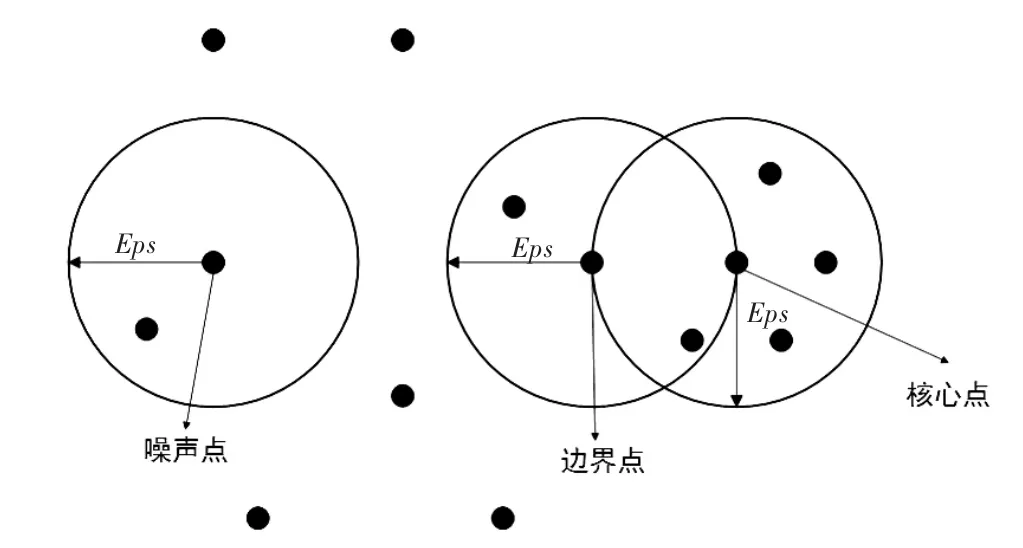
图2 DBSCAN算法的核心点、边界点、噪声点Figure 2 The core,noise and boundary point of DBSCAN
DBSCAN算法可以描述为:任意两个足够靠近(两者之间的距离小于距离参数Eps)的核心点将被放入同一个簇;然后与核心点足够靠近的边界点也将被放入核心点所在的簇中;如果一个边界点与多个分属不同簇的核心点靠近,则需要额外解决方法,最后噪声点被丢弃。
表2给出了DBSCAN算法的细节和主要步骤。DBSCAN使用密度来定义簇,因此它对噪声有较好的抗干扰能力,且能处理任意形状和大小的簇。但是当簇的密度变化很大,或者数据维度很高时,效果会受到影响,因为这类数据,其密度定义变得更困难。

表2 DBSCAN算法的主要步骤Table 2 Main steps of DBSCAN algorithm
1.3 Mean Shift-DBSCAN融合聚类算法
本文将Mean Shift和DBSCAN两种聚类算法通过Stacking集成思想进行组合,得到融合聚类算法,基于如下考虑:Mean Shift算法旨在发现一个样本密度平滑的区域,优点是该算法总是保证收敛,缺点就是它的初始质心是随机选择的,而随机带来的就是选到合适初始质心的概率非常低,即容易受到噪声数据的影响,易陷入局部最优。这种对初始质心选取和噪声点敏感的特性,与K-means类似。而一般数据集都混杂着一定量的噪声,因此总会给Mean Shift带来负面影响。同时不合适的初始质心会造成需要更多的迭代次数,因此Mean Shift的运行时间通常较长。
DBSCAN是将被低密度区域分隔的高密度区域视作簇,可以发现任何形状的簇。但是该算法需要构建一个相似度矩阵,比如使用稀疏矩阵,这个矩阵将消耗n2个浮点数,因此在较大规模数据集上运行时的内存消耗是非常大的。
融合聚类算法思想可简单描述为:首先,人工选取规模较小、质量较好的文本数据形成一个小批量数据集,接着用DBSCAN对该数据集进行聚类,获取聚类中心;然后,将从DBSCAN得到的中心作为Mean Shift的初始质心进行聚类,这样就可以使Mean Shift避免面临由于随机选择造成的找到合适初始质心的概率特别低的情况,从而在很大程度上减少随机选择的初始质心和噪声点对其影响,提升聚类效果,提升运行速度;最后,用该算法对整个数据集进行聚类,垃圾评论会被标记为离群点或者被划分为一个个数量极少的独立簇,实现对垃圾评论识别及清除的目标。算法的具体步骤描述如表3所示,算法结构如图3所示。

表3 Mean Shift-DBSCAN融合聚类算法的具体步骤Table 3 Steps of Mean shift-DBSCAN fusion clustering algorithm
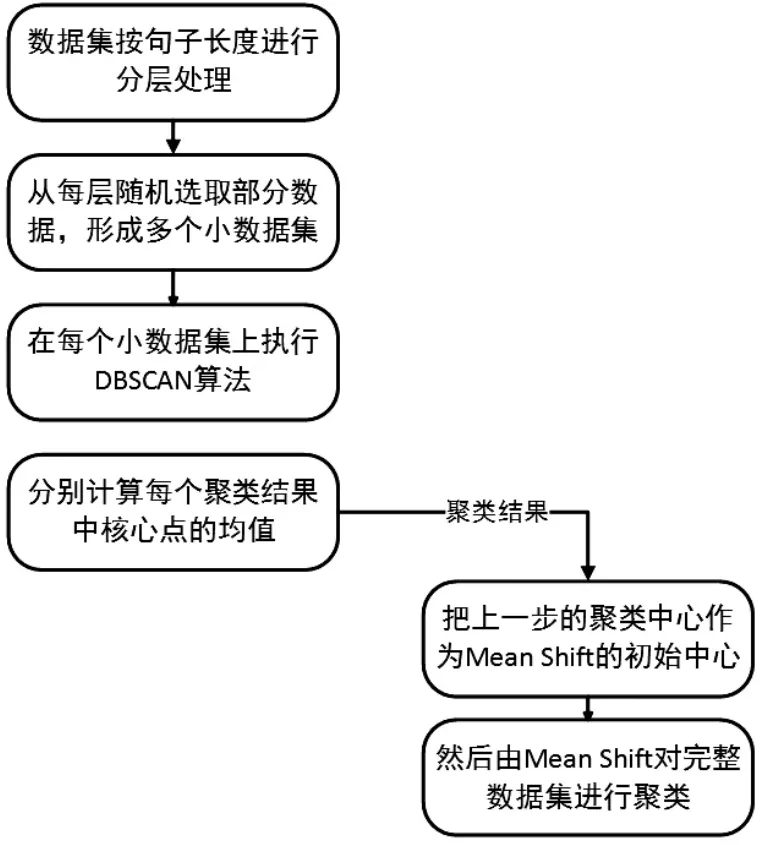
图3 Mean Shift-DBSCAN融合聚类算法结构Figure 3 Clustering ensemble algorithm structure
在融合聚类算法中,第一步是将评论数据集按评论文本长度进行分层。这样做的主要原因是:电子商务产品评论有一个特点,就是评论文本的句长差异很大,有些很长,即词的数量相对较多,有些很短,即词的数量相对较少。这会导致在通过相加词向量得到句向量的过程中,因为词数量的差异造成得到的句向量在语义距离上的偏离。如评论“续航能力一流,充电也快,满意”、“电池续航:电池很强大,充电也快,稳稳当当的一天没任务压力”,两条评论的评价对象都是电池,都是表达对电池的满意。但是可能因为第二条评论的长度大于第一条,使得两个文本在通过余弦距离计算语义相似度时造成偏差。
融合后的聚类算法,相比原始Mean Shift,采用DBSCAN的聚类结果作为初始质心,可以避免随机选择和噪声点带来的影响,并且提高它的运行速度。相比原始DBSCAN,只对高质量的小批量数据进行聚类,避免DBSCAN的高内存消耗情况,且利用到了它能区分各种形状的簇和确定性特点,即以相同顺序输入相同数据时总能得到相同的结果,也就是形成相同的簇。通过对DBSCAN和Mean Shift两种算法的采长补短,既能有效利用各个算法的长处,又能避免两个算法的缺陷,最终得到一定程度的性能优化和聚类效果的提升。
2 实验与分析
2.1 实验数据预处理
为验证融合聚类算法识别电子商务产品评论中的垃圾评论的能力,本文使用Python的Scrapy框架编写爬虫从苏宁易购网站上共抓取6万多条的电子产品评论数据作为实验数据。首先需要在数据处理环节将评论文本中会对识别准确率造成影响的词去掉,如“苹果手机”、“小米手机”中的“苹果”、“小米”在语义上与电子类产品差距较大,会影响识别结果。针对这种情况,本文构建了针对手机类产品评论文本的特有领域性停用词表(如“超赞”、“苹果”、“小米”、“非常”、“续航”),以实现有效去停用词处理。
本文将采用Word2Vec工具将文本转换成词向量,然后用预处理后的语料导入已初始化的Word2Vec进行训练,得到一个有效的Word2Vec模型用于聚类前的文本转词向量任务。本文使用model.wv()来得到每个词向量,再将其组成句向量。通过上述几个步骤的处理,就把非结构化的文本数据转换成了机器能够识别处理的结构化数据,便于后续任务计算评论文本间语义距离来实现垃圾评论识别,实验用的评论数据部分展示如表4所示。

表4 爬虫抓取部分有效/垃圾评论数据内容Table 4 Spam/Real Reviews from E-commerceby Scrapy
2.2 实验过程及分析
为了说明在聚类前将电子商务产品评论数据按句子长度进行分层的重要性,本实验先直接在数据集上执行DBSCAN,得到的聚类结果如图4所示(该图为了更好的展示效果,选取部分数据形成,完整数据集数量过多,无法进行有效展示)。图中有三种类型的点:圆形大点、圆形小点、黑色方点。圆形大点表示核心点,圆形小点表示边界点,黑色方点表示离群点,即垃圾评论。可以看到图上有较多的黑色方点,但是考虑到本文在展示用的数据集中只放入了一条垃圾评论,这样的结果是存在问题的。通过检查结果,DBSCAN算法能把真的垃圾评论识别出来,但是同时也把一些有效评论当成垃圾评论做了错误的分类。
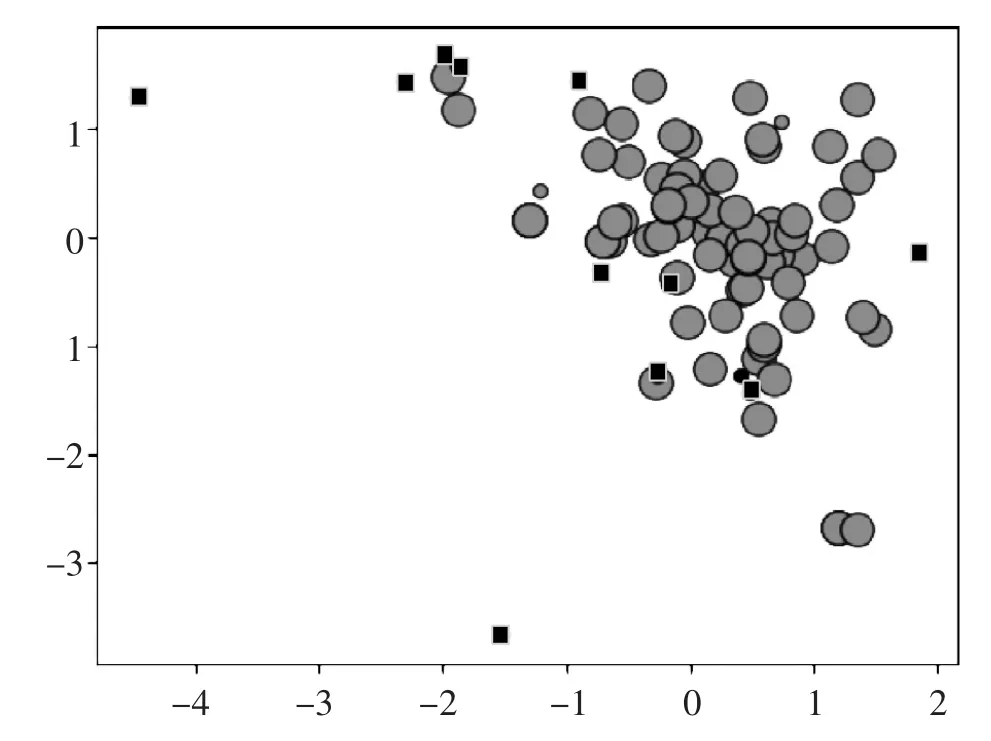
图4 原始数据的DBSCAN聚类结果图Figure 4 DBSCAN clustering results of original data
针对这种情况,本文通过多次实验,观察实验结果的变化。多次试验的垃圾评论识别结果如图5所示。
图5是本文通过对参数Eps和min_samples多次取值,获取的实验结果的分布图。从图中可以看到,在参数min_samples为4时保持不变。而参数Eps的取值从10到14增加过程中,错误分类的数量在减少;而当取值变成15时,错误数量在继续减少,但是已经不能区分真正的垃圾评论,也就是当参数Eps取15时,模型失去实际意义。然后在保持参数Eps为14,改变参数min_samples的取值时,当值由4变为5时,错误分类数量从10增加到了14;然后继续增加参数min_samples的值,发现错误分类数量并不随之发生改变。直到增加到值为14,错误分类数量增加到15,但接下去本实验一直增加到30,错误分类数又都保持不变,但在这个过程中算法能一直保持对真正垃圾评论的识别。从上述实验过程中,可以推断大概有80%~90%的有效数据是可以通过算法聚到一个簇中,剩下的可能因为某些原因导致与核心样本的距离过远,被定义为噪声点。
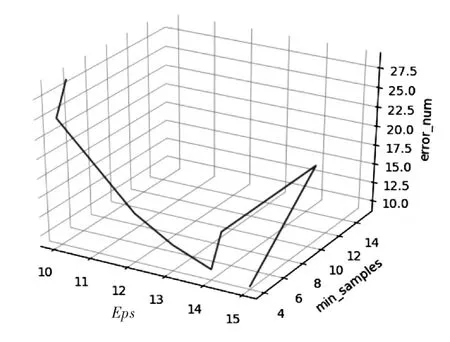
图5 原始数据多次融合聚类结果图Figure 5 Clustering ensemblealgorithm results of original data
本文已通过构建领域性停用词表,删除了容易因为语义的不相关对准确率造成影响的词,因此可以确定还存在什么原因导致语义距离过远。通过对数据的详细分析,发现评论文本的长度存在巨大差异,猜测这可能是造成少部分数据始终被错误分类的原因。通过对文本长度的分析,具体结果如图6所示。
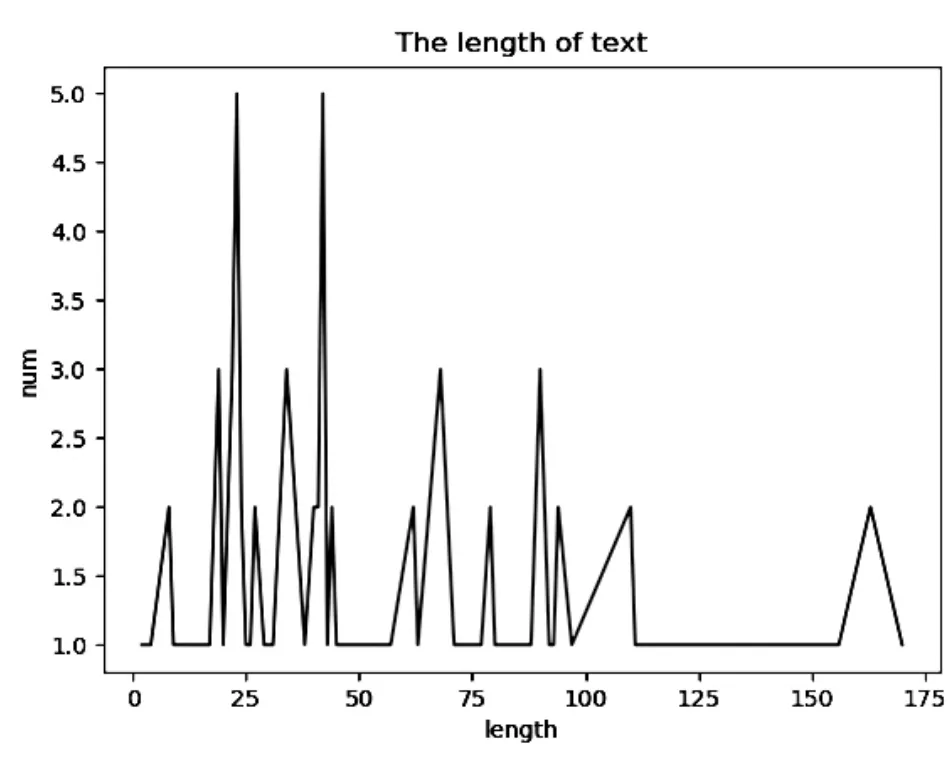
图6 电子商务产品评论文本长度分布图Figure 6 Text length distribution of E-commerce product review
图6显示实验中使用的电子商务产品评论文本长度集中在几个区间段内。因此推断长文本因为分词后的词量相较短文本更多,导致词向量相加后,整个句向量与短文本句向量的空间距离开始偏离,不能再很好地表示原本的语义距离。基于这个假设,本文将数据按照文本长短分别归入以下五类:(0,25)、(25,50)、(50,75)、(75,100)、(100,+∞),然后再分别对每个区间内的数据进行聚类。经过数据分层后再进行聚类,模型能够在验证集上正确分类,实验结果如图7所示(第四幅小图中左上角小黑方点是测试集中垃圾文本,其他小图中的圆点是边界点,并非是噪声点)。

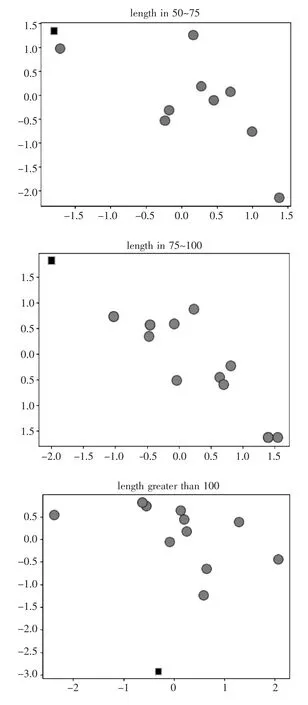
图7 数据分层后融合聚类结果Figure 7 Clustering ensemblealgorithm results of layered data
通过将评论按句长分层后,再执行DBSCANMean Shift融合聚类算法能很大程度减少被错误分类的情况,这样得到的聚类结果更准确。然后获取每个层级聚类结果的核心点,计算这些核心点的平均值,作为Mean Shift的初始质心。实验结果表明,通过上述改进后Mean Shift的错误分类数同样能够得到可观的减少,同时更重要的是运行速度得到了极大提升。不同算法运行时间对比如表5所示,表6展示了当数据集为1500时的实验运行结果。
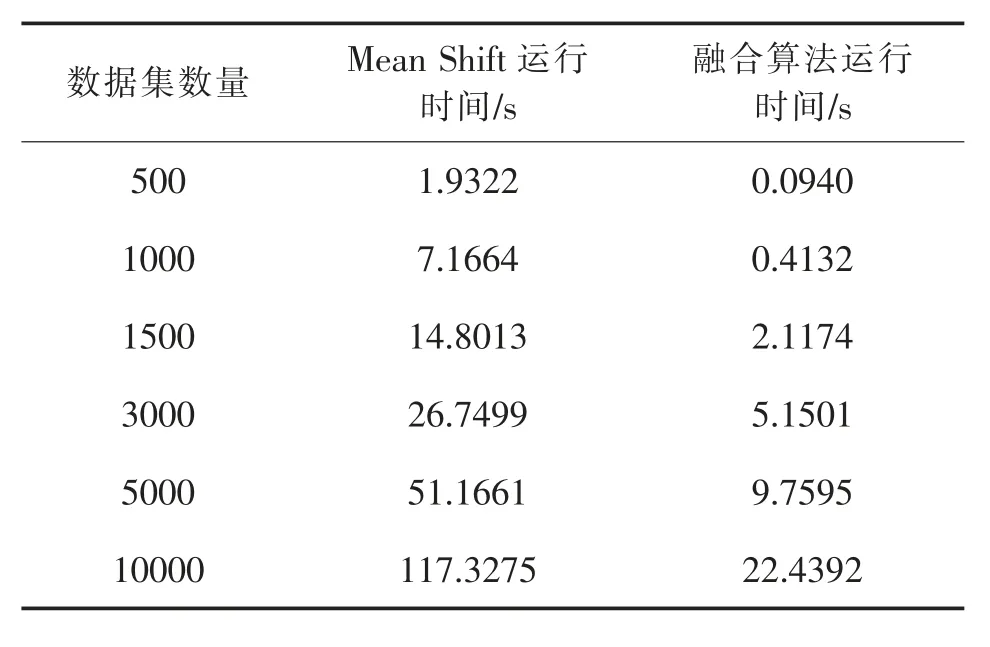
表5 不同算法运行时间对比Table 5 Running time comparison of different algorithms
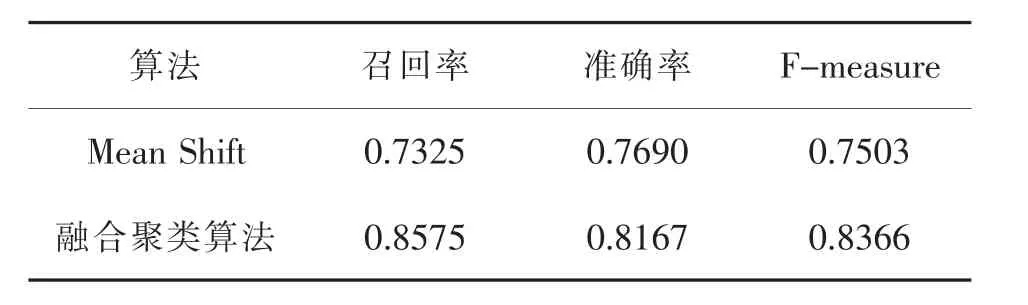
表6 融合聚类算法与Mean Shift算法对比结果Table 6 Comparison of fusion clustering Algorithms and Mean Shift Algorithms
根据表6所示,融合聚类算法相比原始Mean-Shift算法在召回率上提升0.12,即能够识别出数量更多的垃圾评论,说明通过将DBSCAN聚类得到的均值中心作为初始质心,可以减少Mean Shift迭代次数,并且很大程度上避免因随机选择初始质心带来的负面影响。
3 结语
本文提出了用于电子商务垃圾评论识别的Mean Shift-DBSCAN融合聚类算法,通过对大批量电子商务评论文本数据进行分层,然后使用DBSCAN进行聚类得到聚类中心,再将其作为Mean Shift的初始质心,可以有效提高电子商务垃圾评论识别的准确率。实验结果验证了本文提出的融合聚类模型的有效性,在运行时间、识别垃圾评论等方面远超过Mean Shift,相比DBSCAN亦有一定程度的提升和改进。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·教与学(2019年5期)2019-06-06
汽车实用技术(2017年20期)2017-10-24
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
