
基于用户意图的搜索结果文本突显方法
2020-03-09 01:36马少平
上海交通大学学报 2020年2期
张 辉, 马少平
(清华大学 计算机科学与技术系; 智能技术与系统国家重点实验室, 北京 100084)
用户根据自身的信息需求形成查询意图,并将查询意图通过关键词或自然语言的方式提交给搜索引擎;搜索引擎则根据用户提交的查询词或自然语言,从网络上搜集相关信息整理成与查询意图相匹配的搜索引擎结果页面(SERP),每条搜索结果包含了标题、摘要、网址等信息[1].从用户查询意图的形成到用户提交查询关键词的整个过程受限于用户自身的语言特点,可能发生信息模糊、信息丢失或信息冗余等情况,在这种条件下查询关键词通常难以充分并准确地表达用户的查询意图[2].
Clarke等[3]提出相关性间接判定假设,即用户主要根据SERP中的结果标题和结果摘要判断搜索结果与用户查询的相关性,继而决定是否浏览/点击这一搜索结果.因此, SERP中所展示的搜索结果是决定用户搜索交互行为的关键因素.SERP中所展示的搜索结果给予用户的最终感受包括内容和展现形式两方面.目前,商用搜索引擎在SERP的展示形式上,通常采用查询词突显(QTH)策略,即通过变色/加粗等方式突出显示查询词,进而达到吸引用户注意力的目的.这种策略包含两个假设:① 查询词是体现用户查询信息需求最重要的词,这一假设忽略了用户提交查询本身的局限性以及用户意图和提交查询词之间的不一致性;② 搜索引擎的SERP包含合适数量的查询词,这一假设忽略了结果摘要的生成方式千差万别,能同时满足代表原始网页文档和完美匹配查询词这两个条件的结果摘要少之又少.例如,查询需求为“中秋看望父母,听说喝红酒对老年人有好处,想买1瓶千元以内,适合老年人喝的红酒”.
查询方法1以“老年人红酒”作为查询关键词时,1条SERP中展示的搜索结果为:老年人可以适当饮用葡萄酒,不过应该注意的是,如果老年人有三高症状就坚决不能喝酒.在给老年人选择葡萄酒时,应尽量选择酒精含量比较低的干型葡萄酒,避免过量……
查询方法2以自然语言“我想买适合老年人饮用的千元以内的红酒”作为查询语句时,1条SERP中展示的搜索结果为:事实上葡萄酒并非都很贵,很多葡萄酒都是百元以内的,甚至四五十块的红酒有很多都很好喝.很多适宜日常饮用的葡萄酒,果香丰富,口感顺滑,便宜又好喝.……这些拍卖行的葡萄酒拍品,往往是老年份的葡萄酒,市场上比较少见的酒,……事实上,新世界的酒,以果味新鲜为主,适合尽早饮用,新西兰不少走自然风格……
查询方法1的信息量有限,不能充分地表达用户的查询意图,存在信息模糊及信息丢失现象,如“葡萄酒”、“干红”这些对于满足用户查询需求有用的词语并不会被突出显示;查询方法2使用的查询语句较长,与目前商业搜索引擎通常采用的关键词框架设计不一致,存在信息冗余现象,搜索引擎容易把“适合”、“饮用”等这些对于满足用户信息需求不重要的词语突出显示.
在中文语言环境下,用户提交的查询以关键词查询为主,查询往往较短,含有的信息量有限.余慧佳等[4]统计了查询日志,发现有93%的查询包含不超过3个查询词,平均长度为1.85个词.因此,当用户提交的查询为关键词时,将研究对象定为SERP的文本突显策略.同时,考虑到结果标题和结果摘要在用户查询过程中所承担的作用,为了使所研究的问题更有针对性,重点关注了搜索结果中结果摘要的突显策略.首先基于用户标注的突显词,提出一种关键词突显策略;然后,基于4种常用的序列标注机器学习算法——结构化支持向量机(SVMStruct)、隐Markov(HMM)、最大间隔Markov网络(M3N)和条件随机场(CRF)算法,提出一种新的联合序列标注学习(JSL)算法,并利用词语4个方面的属性特征自动识别突显词;最后,对比分析在2种文本突显方法下的用户搜索行为,调查不同文本突显方法在整个用户搜索交互过程中所承担的作用.
1 相关研究工作
研究内容主要包括3个方面:文本突显对于用户阅读、认知及搜索行为的影响;查询扩展、查询缩减和查询推荐的方法;文本关键词的提取方法.
一段文本内不同亮度、颜色的文本具有视觉敏感性.文本突显的目的是通过改变文本的外在展示形式获取视觉注意,即“吸引注意力”[5-6].Few[7-8]发现通过在摘要中突显查询词(颜色突显)可以吸引用户的注意力,改善用户搜索中信息的获取效率.然而,过多的颜色突显反而会降低用户的视觉注意力,引起视觉分散的现象.Kickmeier等[9]通过实验发现文本突显的密度对用户的点击行为及记忆准确性都有明显的影响,文本突显密度过高或过低都会对用户造成选择困扰,从而增加结果相关性的判断时间.然而,这些实验都着重于研究突显查询词及文本突显密度对于用户行为的影响,并没有考虑突显不同的词语对用户搜索效率的影响.
为了解决用户所提交的查询与用户的查询意图不一致的问题,查询扩展技术、查询缩减技术和查询推荐技术通过一定的方法策略,如增加、减少或更换一些词或词语到原查询中,达到提高信息检索的查全率及查准率的目的[10-11].这些方法从一定程度上解决了查询信息不足的问题,但其出发点为查询词,被扩展或更换的词语往往是查询词的同义词、近义词,或来自于搜索引擎公司提供的查询推荐词,这些词语并不一定存在于SERP的结果摘要中.因此,搜索结果的展示方式依然是面向查询、而非面向用户查询意图的.文本关键词的提取技术通过一定的方法策略提取能够体现作者(原始文本)主要思想的重要词语[12-13],但其仅与文本自身相关.搜索结果中需要突显的词语是由用户的查询任务所决定的,文本的关键词并不一定是满足用户意图的关键词.综上所述,基于查询的查询扩展技术、推荐技术和基于搜索结果的关键词提取技术都不能直接作为SERP的结果摘要突显词.SERP的结果摘要突显词是存在于结果摘要中、与查询任务相关且对于用户信息查询需求最重要的词或词语.

图1 用户标注前后的SERP示意图Fig.1 The diagram of SERP before and after highlighting words by users
2 突显词用户标注调查
研究由日本国家科学信息系统中心(NACSIS)策划主办的检索与自然语言处理测试任务(NTCIR IMine)[14]中的12对中文查询词,如表1所示.每组2个查询任务的查询需求类似、查询难度相当,其中包括2组4个导航(NA)类查询,2组4个事务(TR) 类查询和8组16个信息(IN)类查询.针对每个查询任务,利用Google搜索引擎获取前10个纯文本的搜索结果,去除SERP中含有图片、视频等内容的查询结果.
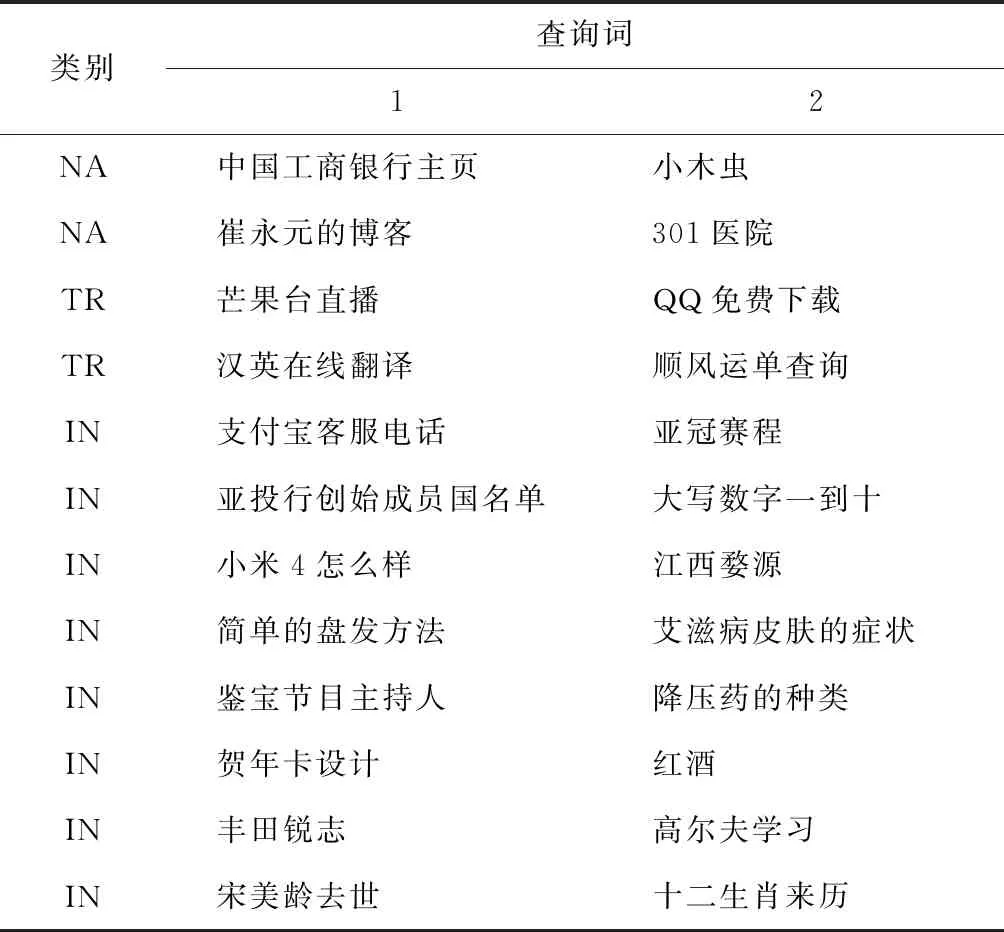
表1 用户标注采用的24个中文查询Tab.1 Twenty-four Chinese queries annotated by users
针对表1中的每个查询任务撰写相应的任务描述.提供用户查询任务说明、查询词以及去除结果摘要中文本突显的SERP(形成统一的字体颜色),供用户进行突显词的选择及标注,如图1(a)所示.调查对突显文本的内容、长短及次数不进行任何限制,只要求用户根据自身对任务描述及查询(词)的理解,标注出个人认为最重要的、对完成查询任务最有价值的、最应该被突显的词或词语,标注结果如图 1(b) 所示.调查一共邀请了10个计算机专业、自述能够熟练地使用搜索引擎的用户对24个任务的SERP(前10个结果)进行标注,最终产生 2 400 个搜索结果的突显词标注结果.
由图1可知,用户标注的突显词(关键词)与查询词并不一致.挑选几个用户标注的突现词进行示例,如图2所示.当查询为“艾滋病皮肤症状”时,用户更倾向于将“艾滋病初期皮肤症状”作为一个整体突显来标注,而不是分别标注“艾滋病”、“皮肤”、“症状”等这些单独的词语;当查询为“丰田锐志”时,用户除了标注“丰田锐志”这个实体,还倾向于标注“参数配置”、“报价”等与该实体相对应的属性词;当查询为“支付宝电话”时,用户更倾向于标注出可能的答案,如“95188”和“0571-6500-5120”. 综上所述,在不同的查询任务中,用户更倾向于标注较长的突显词、更为丰富的关键词或直接标注可能的答案.

图2 用户标注突显词示例Fig.2 Examples of highlighting words labelled by users
3 突显词自动识别算法
3.1 问题描述
结果摘要的文本突显问题可以看作为一个序列标注任务.如图3所示,在给定查询Q、结果标题T和结果摘要S的情况下,序列标注的最终目的是预测结果摘要中词语的突显标签Y和非突显标签N.前文的用户标注调查已经得到了 2 400 条用户的标注数据,因此可以把识别突显词任务看成一个有监督的序列标注任务.

图3 结果摘要文本的突显词识别问题示例Fig.3 An example of search result snippet highlighting terms tagging
假定摘要的固定长度为K,则输出序列为y=[y1y2…yK],其中yk(k=1,2,…,K)为第k个词.能够观测到的用户标注序列为x=[x1x2…xK].其中:xk,yk∈{N,Y},k=1,2,…,K.突显词识别任务由已经观测到的用户标注序列x对最终的输出序列y进行估计和推断[15].在自然语言处理序列标注任务中广泛应用的SVMStruct[16]、M3N[17]和CRF[18]算法选取条件概率P(y|x),而HMM[19]算法选取联合概率P(x,y)分布中最大的一个y*作为输出序列.在模型训练阶段,预测序列可由下式计算得出:
y*=argmaxyP(y|x) 或
y*=argmaxyP(x,y)
(1)
其中:argmax可以通过Viterbi动态规划算法获得.
3.2 序列标注模型
由于SVMStruct、HMM、M3N和CRF算法在预测不同标签上的特性不同,将这些机器学习算法联合起来提出一种新的JSL算法,用以进一步提高算法性能,如图4所示.
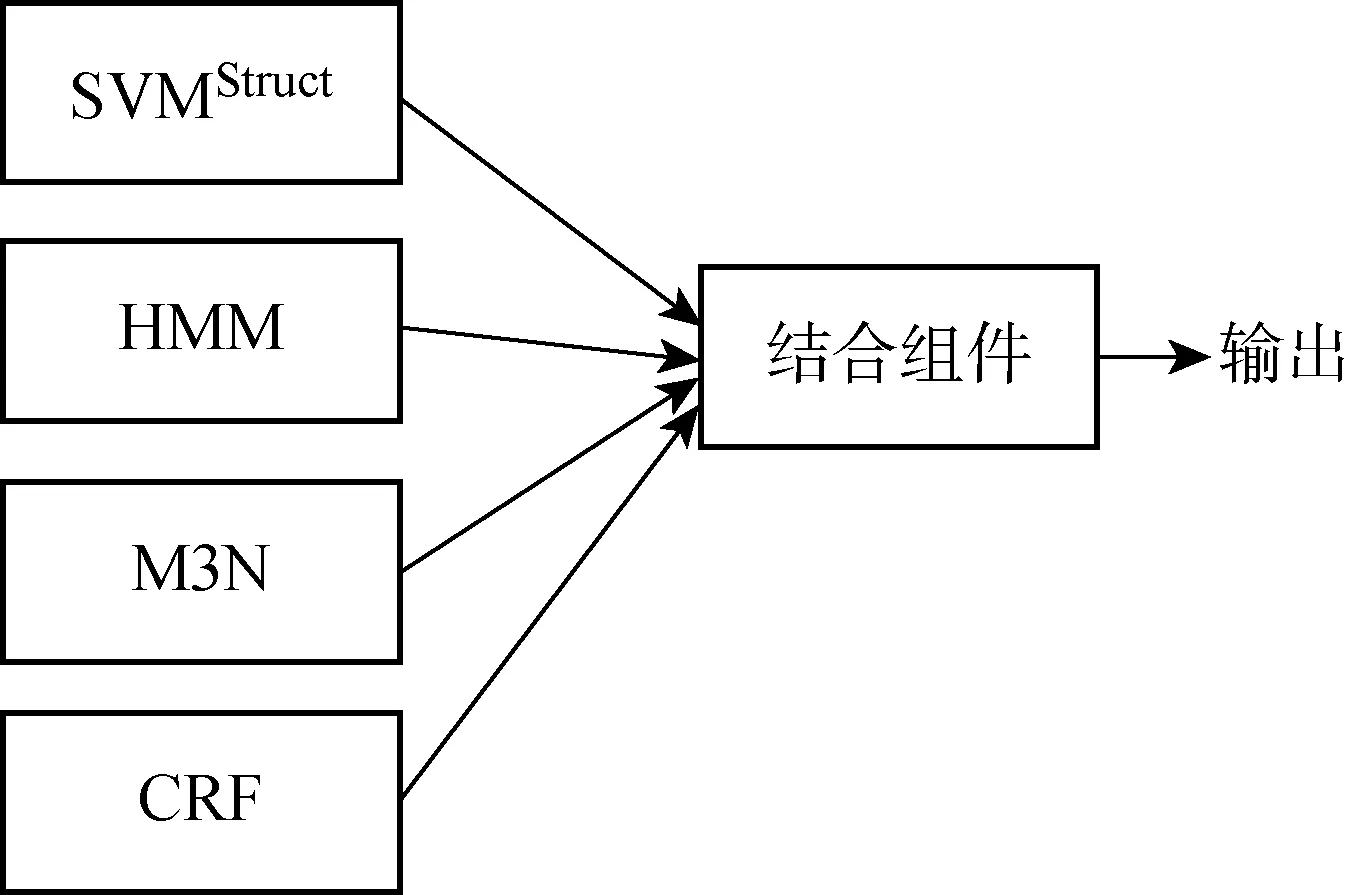
图4 JSL算法模型示意图Fig.4 Schematic diagram of JSL algorithm
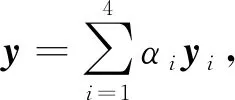
为获得序列y,构造(K-1)个2×2的转移矩阵Tk(m,n)记为countk(m,n),为k位置上的标签m变换成标签n的次数,其中,k=1,2,…,K-1;m,n∈{N,Y}.定义标签的状态权重为Uk(t)=countk(t),代表位置k上标签t出现的次数,其中,k=1,2,…,K;t∈{N,Y}.预测序列y的表达式为
(2)
3.3 特征参数
采用基于词匹配、词信息、词向量和词属性的4类特征预测一条结果摘要中哪些词应该被突出显示为红色,而哪些词不需要被突出显示,表2所示为其特征列表.

表2 突显词识别所用词语特征列表Tab.2 The features used in tagging of the highlighting words
基于词匹配的特征(★):衡量该词语是否存在于查询、结果标题、维基百科、百度百科或者搜索推荐之中.
基于词信息的特征(■):衡量该词语与对应的词语之间的距离或者词频-逆文本频率指数(tf-idf)值.其中:tf值是该词在维基百科中的数量;而idf值则是根据所有查询词对应的维基百科文本计算得出的.
基于词向量的特征(◆):用词向量表达一个词,并基于这一向量计算该词语与对应词语之间的相似度等特征.其中,词向量是基于搜狗互联网语料库(SogouT)数据集[20]采用词向量(word2vec)[21]算法预先训练得到的,并在整个突显词识别算法的训练过程中保持不变.
基于词属性的特征(●):该词语自身包含的信息包括词性、情感以及主题特征,这部分特征可以由中科院ICTCLAS系统和MB-PL-ASUM算法得到[22].
3.4 算法性能
3.4.1模型性能 通常序列预测算法的目标是所有词语的标签预测综合性能达到最优,一般损失函数(AverageLoss)表示所有词语的预测标签与词语实际标签之间的差异程度,其表达式为
AverageLoss=
(3)
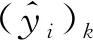
为了测试不同算法的综合性能指标,采用所有种类的特征信息计算5种算法在模型准确度、精度、召回率及F值方面的性能,计算结果如表3所示.由表3可知:① SVMstruct算法在模型准确度及召回率方面的性能较好;而CRF算法在模型精度及F值方面的性能较好.② HMM算法在模型准确度、召回率及F值3方面的性能都表现得较差,这可能是由于模型本身采用的是联合概率而非条件概率所引起的.③ JSL算法在模型准确度、精度及F值方面的性能都是最优的,相较于其他4种算法都有一定程度的提高.但由于数据的不均衡性,在提高突显词语的预测比重后导致了更多的非突显词不能被识别,故在召回率方面有所降低.各算法在JSL算法中的所占比重分别为:SVMstruct算法占70.1%;CRF算法占16.2%;M3N算法占7.1%;HMM算法占6.6%.SVMstruct算法与CRF算法所占比重较高,这是由于SVMstruct算法和CRF算法解决了M3N算法的标签偏置问题并弱化了HMM算法的独立性假设,所以在JSL算法中优势更为突出,获得了较大的比重.
表3 各序列标签学习模型的性能对比
Tab.3 The performance comparison of different sequence label learning algorithms
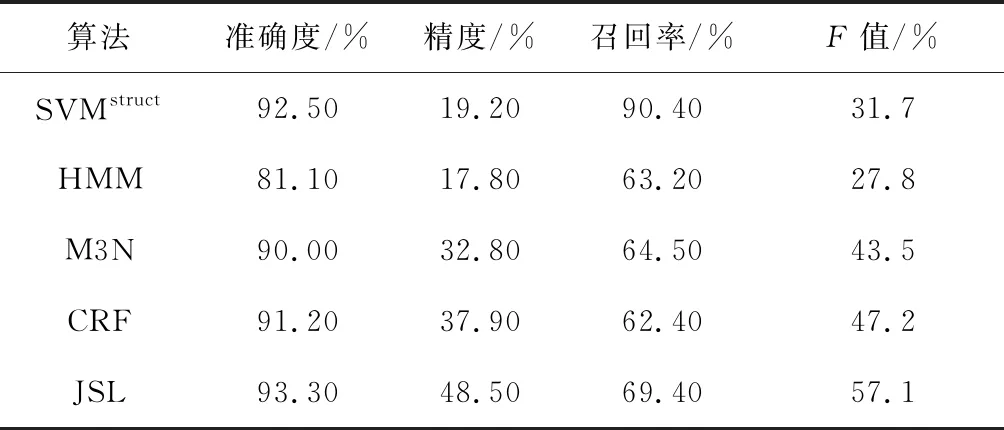
算法准确度/%精度/%召回率/%F值/%SVMstruct92.5019.2090.4031.7HMM81.1017.8063.2027.8M3N90.0032.8064.5043.5CRF91.2037.9062.4047.2JSL93.3048.5069.4057.1
3.4.2不同特征下的JSL算法性能 不同特征下的JSL算法性能如表4所示,其中↑和↓为相比于上一个数量较少的特征,F值的变化是增大还是减小.由表4可知:① 当仅采用词匹配和词属性信息特征时,查询效果较差;当采用词信息或词向量特征时,查询效果明显提高,说明用户需要更多有效的信息为搜索交互过程提供必要的线索.② 当将词向量与词匹配、词信息与词属性分别组合成2组特征信息时,则算法的F值有所下降,这可能是由于2组特征混合在一起后使得算法出现了过拟合问题,同时也说明词向量对于JSL算法而言是作用比较大的一组特征;当采用3组特征时,F值有所提高;当采用4组特征时,JSL算法性能达到最优,说明这4组特征在识别突显词这一任务中都是有效的特征.③ 当预测所有词语的整体准确度达到93%时, JSL算法的F值仅有57%,说明该数据集是一个不均衡的数据集,突显词数量非常少,因而出现了过拟合的问题.
表4 不同特征下的JSL算法性能比较
Tab.4 The performance comparison of JSL algorithm under different features
3.4.3不同任务下的JSL算法性能 不同搜索任务下,同时采用4类特征时的JSL算法性能如表5所示,其中ALL为所有任务.由表5可知:① 当搜索任务为NA类查询任务时,JSL算法的预测性能最优,这是由于NA类查询任务是搜索一个与查询高度相关的网站,此时预测算法使用的特征已经包含了查询内容;当搜索任务为TR类和IN类查询任务时,用户往往需要更加丰富的线索信息,此时预测突显词更加困难.② 当搜索任务为ALL时,预测摘要中的查询词性能较好,而预测摘要中的非查询词性能较差, 其F值分别为70.2%和38.7%.这可能是由于所采用的特征大部分是与查询相关的特征,所以预测查询词较容易,而预测非查询词较困难.③ 从预测结果可以看出,当查询任务是TR类或IN类时,用户需要更丰富的线索信息以直接突显答案,但目前的预测算法在这方面的性能有待提高,这可能会是下一步的研究重点.
表5 不同搜索任务下JSL算法的性能
Tab.5 The performance comparison of JSL algorithm under different search tasks

搜索任务突显词F值/%NA类全部摘要词语66.0TR类全部摘要词语56.4IN类全部摘要词语53.0ALL查询词70.2ALL非查询词38.7
4 用户实验
4.1 实验流程
实验邀请了12名参与者,包括4名女生和8名男生,均为同一所大学一年级的本科生,就读专业包括经济学、美学、法学、社会科学等,自我报告有1年以上的搜索引擎使用经验.每人需要完成24个查询任务,其中12个任务采用QTH策略,另外12个任务采用关键词突显(KTH)策略.实验采用希腊拉丁方及随机序列方法保证每个任务以相同的概率展现给用户.针对每种突显策略下的每个查询任务,收集到6个用户的查询任务数据.实验提供的界面形式采用Google框架的搜索引擎,用户可通过该搜索引擎完成正常的搜索功能.此外,用户交互的鼠标数据和眼动数据均会被记录下来.实验要求参与者必须在90分钟内完成所有查询任务,完成任务后通过口头询问的方式确保参与者以认真的态度完成任务,同时搜集用户关于页面突显感受的反馈.
4.2 评价指标和实验结果
搜索用户的交互过程通常采用的是成本-效益框架评价搜索引擎的性能[23-24],并以商业搜索引擎采用的QTH策略作为对比基准,与基于JSL算法产生的KTH策略进行对比,采用的评价指标如表6所示.

表6 搜索效益评价指标体系Tab.6 The evaluation index system of search performance

表7 KTH与QTH策略下的搜索效益对比
Tab.7 The performance comparison between KTH and QTH highlighting strategies
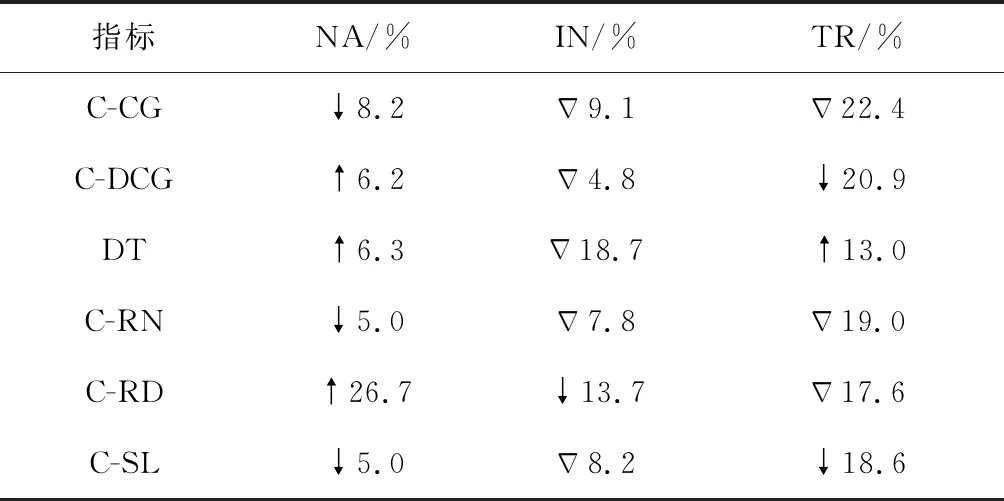
指标NA/%IN/%TR/%C-CG8.2Δ9.1Δ22.4C-DCG6.2Δ4.820.9DT6.3Δ18.713.0C-RN5.0Δ7.8Δ19.0C-RD26.713.7Δ17.6C-SL5.0Δ8.218.6
用户的注视行为热度如图5所示.突显词可以吸引用户的注意力,让用户“注意看”突显词,进而使得用户关注位置靠后但更为相关的搜索结果.当查询词为“降压药种类”时,在QTH策略下(见图5),突显词为“降压药”、“种类”等,用户优先关注排名靠前的结果,排名靠后的结果(排名为第7和第8名的结果)用户基本不会注意到;在KTH策略下(见图6),排名为第7和第8名的结果突显词为“6大类”、“5大类”、“利尿药”、“β受体阻滞药”和“钙离子拮抗剂CCB”等,用户则重点关注了这些结果突显词,原因是这些结果突出词显示了对于用户查询意图更有价值的关键词.

图5 用户注视热度图Fig.5 People’s gaze paths in the heat map

图6 用户注视热度图Fig.6 People’s gaze paths in the heat map
5 结语
基于用户标注的数据,提出一种新的突显策略,以突显更能满足用户查询意图的关键词;采用JSL算法,使用词匹配、词信息、词向量以及词属性4个方面的特征,自动识别搜索结果摘要中的突显词,取得了接近于人工标注的效果;设计用户搜索实验,并且与目前通用的QTH策略进行对比,进而分析不同突显策略对于用户行为及搜索效益的影响.实验证明不同突显词对于用户搜索行为有较大的影响,KTH策略明显优于QTH策略,能够有效地提升搜索效益.
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
计算机与网络(2022年2期)2022-03-17
疯狂英语·新阅版(2020年11期)2020-12-21
小天使·一年级语数英综合(2020年4期)2020-12-16
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
传奇故事(破茧成蝶)(2015年7期)2015-02-28
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
