
智能语音识别技术在北京河长制系统中的应用
2020-03-04 13:19尹晓楠
水利信息化 2020年1期
刘 梅 ,尹晓楠 ,李 超
(1. 北京市水务信息管理中心,北京 100038; 2. 江河瑞通(北京)技术有限公司,北京 100097)
0 引言
当前以大数据、云计算、物联网、人工智能等为代表的新技术,不断与经济社会各领域深度融合,极大提升了社会运行效率,深刻改变着政府社会治理和公共服务的方式。党的十九大报告中明确提出要建设网络强国、数字中国、智慧社会,把智慧社会作为“加快建设创新型国家”的重要内容[1]。智慧水利是智慧社会的重要组成部分,但智慧水利建设与智慧社会的要求还有较大差距,与支撑水利现代化的要求还有较大差距,大数据、人工智能等技术尚未得到广泛应用、智慧功能尚未得到充分显现[2]。因此,智慧水利建设应充分发挥新一代信息技术的驱动引领作用,促进技术与水利业务的深度融合,推动智慧水利不断发展。
江河湖泊业务作为重要水利业务,对保障国家水安全和经济社会的持续健康发展意义重大。同时河湖管理保护是一项复杂的系统工程,涉及上下游、左右岸、不同行政区域和行业。为加强河湖管理保护、推进水生态文明建设,中共中央办公厅、国务院办公厅于 2016 年 12 月印发了《关于全面推行河长制的意见》,进行了全面推行河长制的决策部署[3]。为了做好河湖保护,实现水清、岸绿、景美,在中央的统一部署下,北京推行了河长制,建立了四级河长体制,根据河长制工作的需要,建立了河长制管理信息系统,有效地支撑了河长制管理。系统运行 1 a 多以来,为各级河长、巡查员和社会公众参与河湖治理、发现上报问题拓宽了渠道。但在实际使用中,因举报问题需要在手机端进行文字输入,对使用者操作手机有一定的要求,因此需要一种更加方便、快捷的方式。随着深度学习理论的发展,语音识别准确率迅速提升,为提供更加智能化、人性化的语音交互服务提供了新的契机。通过在“北京河长”微信公众号和移动 App 中引入智能语音识别技术,能够简化记录和举报问题的操作流程,从而促进社会公众监督的参与度和积极性,提升巡查人员巡河记录问题的高效性和便捷性,提高河长办工作人员处理问题的效率。本研究从河长制具体业务场景出发,探索智能语音识别技术在北京市河长制工作中的具体应用,为智能语音识别技术在水利行业的发展提供借鉴。
1 智能语音识别技术概述
语音作为一种最便捷和自然的交流形式,承载着信息传递的重要功能,在人们的日常生活中发挥着重要作用。作为人工智能技术的重要领域,智能语音识别技术主要包括自动语音识别(Automatic Speech Recognition,ARS)、自然语言处理(Natural Language Processing,NLP)和语音合成(Speech Synthesis,SS)等技术[4]。自动语音识别和自然语言处理技术让计算机能够听懂人类的语言,理解语言中的内在含义,语音合成技术则让计算机能够说话。
1.1 智能语音识别技术发展
语音识别的研究源于 20 世纪 50 年代,1952 年AT&T 贝尔实验室的 Davis 等[5]研发了第 1 台孤立数字识别系统 Audrey,实现了可以识别 10 个英文数字。20 世纪 60 年代开始,出现了动态时间规正(Dynamic Time Warping,DTW)、矢量量化(Vector Quantization,VQ)等技术,采用模版匹配的方法实现语音识别[6]。1976 年,美国卡耐基梅隆大学的 Reddy 等[7-9]开发了能够执行连续语音识别的系统 Hearsay I。20 世纪 80 年代以后,语音识别研究由基于模板匹配的方法转向基于统计模型的方法,高斯混合模型-隐马尔科夫模型(Gaussian Mixture Model-Hidden Markov Model,GMMHMM)和 N-gram 模型成为语音识别的主流,人工神经网络(Artificial Neural Networks,ANN)开始应用于语音识别。2006 年,Hinton 等[10]提出深度置信网络(Deep Belief Network,DBN),解决了深度神经网络(Deep Neural Network,DNN)训练过程中容易陷入局部最优的问题。此后,掀起了深度学习的热潮,出现了卷积神经网络(Convolutional Neural Networks,CNN),循环神经网络(Recurrent Neural Network,RNN),长短时记忆单元(Long Short Term Memory Network,LSTM)等[11-13]。深度学习模型具备多层非线性变换的深层结构,具有更强的表达与建模能力,使得语音识别模型对复杂数据的挖掘和学习能力得到了空前的提升。这些深度学习模型的应用极大地促进了语音识别技术的发展,突破了某些实际应用场景下对语音识别性能要求的瓶颈,使语音识别技术走向真正实用化[14]。
1.2 语音识别基本原理
语音识别是一门涉及了语言学、统计学、信号处理、模式识别、机器学习、计算机等学科的综合学科技术。语音识别技术通过信号处理和模式识别,将语音信号转换成对应的文本或指令。
语音识别采用统计模式识别方法,基于隐马尔科夫模型的统计框架进行训练,在给定语音特征序列{O1,O2,…,OT} 的情况下,结合声学模型和语言模型,根据最大后验概率算法,输出词序列具体公式如下:
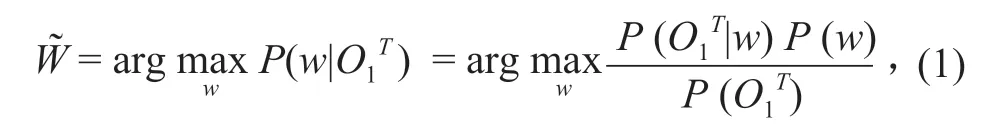
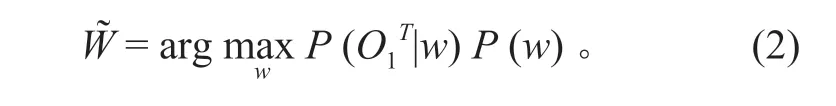
语音识别过程主要包括预处理、特征提取、声学模型、语言模型、语音解码和搜索算法。语音识别过程如图 1 所示。

图 1 语音识别过程示意图
1)预处理。计算机对输入的语音信号预处理,包括抗混叠滤波、预加权、信号分帧、端点检测等。
2)特征提取。提取预处理数据的声学特征参数,得到特征矢量序列,如线性预测系数(LPC)、线性预测倒谱系数(LPCC)、美儿频率倒谱系数(MFCC)等[15-17]。
3)声学模型。利用语音信号特征训练声学模型,建立起所需的声学模型,用来计算语音信号特征的后验概率。
4)语言模型。通过大量的文本训练,进行语法、语义分析,建立语言模型,用来计算词序列的先验概率。
5)语音解码和搜索算法。进行语音识别时,声学模型通过计算语音信号特征与声学模型的相似度生成声学模型分数,发音词典映射生成词序列,语言模型通过语料中词与词之间的约束关系,估计候选词序列出现的概率并生成语言模型分数,最终语音解码和搜索算法会综合声学和语言模型分数,将整体分数最高的词序列作为识别的结果输出,从而实现语音信号的识别。
2 智能语音识别技术在北京市河长制中的应用
2.1 北京市河长制管理信息系统现状
北京市属于海河流域,共有 16 个区,330 个乡镇、街道,常住人口 2 000 多万。根据第 1 次水务普查数据,全市共有河流 425 条(流域面积 10 km2以上),河流总长度 6 413.72 km,分属五大水系。全市有水库 88 座,总库容为 93.77 亿 km3,湖泊 41 个(水面面积 0.1 km2以上),总水面面积为 6.88 km2。北京水资源形势严峻,水少、水脏是水资源的主要矛盾,南水进京之后水资源紧缺的状况尚未得到根本改变,水污染问题尚未得到有效根治。
为了有效改善河湖生态环境,北京市根据河长制工作需要建设了河长制管理信息系统,系统采用 GIS、“互联网 +”和人工智能等技术,集信息采集、信息服务、河长管理、公众服务、监督考核为一体,依托 PC 端、移动端和微信公众号 3 种载体,服务于市、流域、区、乡镇和村各级河长的业务管理工作,全面实现了河道管理网格化、事件处置流程规范化、河长绩效考核差异化、河道信息公开化[18]。
通过河长制信息管理平台、微信公众号和移动 App 的应用,量化河长履职情况,实现了“工作留痕,有理有据”,进一步畅通了公众举报渠道,加强了政府与社会公众的联系。针对河道内乱堆乱弃垃圾渣土、违章建筑、偷排偷放污水等影响水环境、破坏水生态的问题,目前开放的群众投诉举报渠道包含人工和在线举报,人工举报渠道提供的服务具有方便、贴心等特点,但是人工值班时间有限,不能满足 7×24 h 在线服务的需求;在线举报渠道通过微信公众号提供表单填报功能,具有采集信息专业、全面等特点,但是未考虑到举报人的实际情况和所处环境,对程序使用的熟练度要求较高,需要进行文字记录。同时在巡河过程中,户外环境存在的日照、降雨等天气因素,以及交通、人流等环境因素,会对河长采用手工输入汉字记录问题的方式会造成一定的干扰。
2.2 智能语音交互技术应用设计
为了既让社会公众和河长更简洁、方便地反映河湖存在的问题,让巡查人员在巡河过程中能方便地记录和举报问题,又能保证系统接收到的问题信息以结构化的数据形式存入数据库,方便查询检索,在已有的河长制系统问题举报功能中增加了语音识别功能。
1)总体设计。智能语音交互系统以云服务的架构体系进行建设,在顶层提供云服务接口供“北京河长”微信公众号、移动 App 使用。语音智能交互系统按照逻辑结构,平台主要分为知识库层、知识检索层、对话交互层、语音接入层、边缘计算层等多个层次。系统总体架构如图 2 所示。
2)移动 App 语音记录功能设计。在巡河过程中,河长和巡查人员通过语音交互方式记录河湖问题,通过自然的对话方式即可完成信息录入、修改和提交等操作,提高河长巡河记录问题的高效性和便利性,节省河长办工作人员记录和处理问题的时间。移动 App 系统界面图如图 3 所示。
3)微信公众号语音举报功能设计。社会公众通过语音交互方式投诉举报发现的河湖问题,通过自然的对话方式即可完成举报信息录入,自动生成举报单,然后可对生成的表单进行修改和提交等操作。通过便捷化举报和的操作流程,提高群众监督的参与度和积极性。微信公众号系统界面如图 4 所示。
同时,智能语音交互系统应用自然语言理解(NLP)技术对举报信息中相关问题描述的分析,智能识别问题类型,对河湖中发生的问题进行分类,方便河长制信息管理平台对重点问题的分类和管理。
2.3 语音识别准确率提升解决方案
在语音智能交互系统测试初期,受到一些客观、复杂因素的影响,语音识别率为 89%,没有达到预期水平。通过对测试结果、测试用例和系统运行日志的分析,发现影响准确率的原因大致分为以下 5 类:
1)同音字词,汉语中存在很多同音的字词;
2)方言或普通话不准;
3)语音不完整引起信息缺失;

图 2 智能语音交互系统总体架构
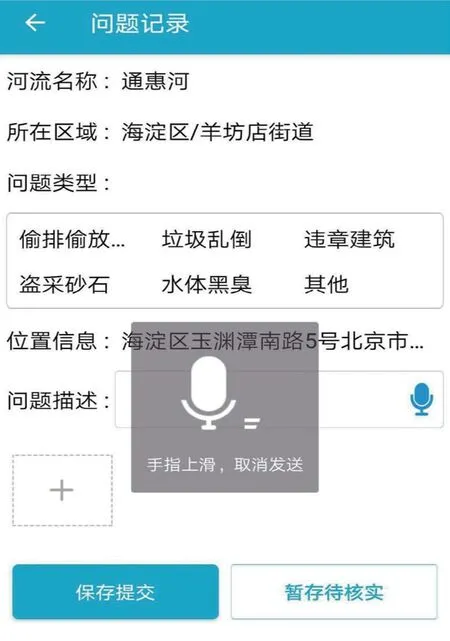
图 3 移动 App 系统界面图

图 4 微信公众号系统界面图
4)有杂音造成噪音干扰;
5)水利领域专业词汇,某些词汇只有在特定领域出现的频率较高。
根据对影响识别率相关因素的分析,并结合北京市河长制实际,通过优化神经网络算法结构、完善水行业语言学模型及词典、收集场景案例等手段,优化提升识别准确率,主要步骤包括数据准备和语言模型优化,具体如下:
1)数据准备。字典及行业词汇是系统理解语义的基础,通过行业词汇将接收到的语言内容进行分词,甄选行业热词后进行后续的识别流程。河长制相关概念的词汇属于近年新型词汇,从语言学到计算机应用方面对此方向的储备都比较少。将从政府网站、新闻媒体网站及行业相关库采集抓取的 20 多万篇文章做为河长制领域的基本语料库,在基本分词词典中加入北京地区河流、湖泊及水行业专属词汇 1 万多个。
2)N-gram 语言模型优化。N-gram 模型的思路即假设 1 个字或词出现仅与前 n 个词相关(n 为人为给定),句子整体的概率等于所有词语搭配概率的乘积。通过计算一个词语的 N-gram 分数来评估这个词语是否合理,以此检测错误词语。
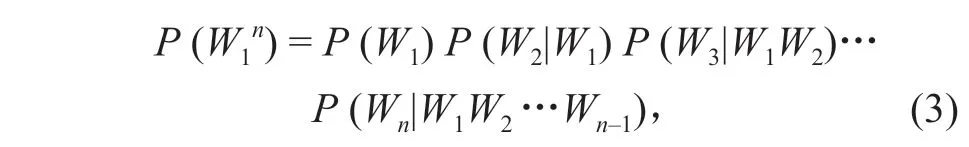
式中: P (W1) 表示 W1出现的概率;P (W2|W1) 表示在出现 W1时,出现 W2的概率。因此可以类推得到出现第 n 个词的概率与它之前的(n -1)个词相关。
在模型优化训练时,结合河长制专属语料库,以最大化目标函数为优化目标,通过计算词向量的余弦相似度进行词向量匹配和纠正词替换,从而提高语音识别准确率[19]。
最终通过大规模语料库成果的模型更新,同音词因素引起问题得到优化解决,方言或发音不准因素引起问题得到优化解决,语音识别准确率达到96%,辅助实现“一句话举报、拍张照取证、30 秒提交”,为河湖管理保护工作中问题发现上报、筛选分类、情况核实、整改反馈、跟踪复查、责任追究、统计分析提供全流程支撑,提升监督水平和处置效率,推进河湖管理保护智慧化。
3 结语
通过将智能语音识别技术应用到北京市河长制管理工作,为辅助各级河长做好日常巡河工作、提高工作效率、改善系统使用体验提供支撑,为社会公众参与河湖治理提供了便捷的手段。这项技术的应用为水利信息系统实现智慧化提供了良好的示范,也将成为北京智慧水利建设重要的组成部分。
猜你喜欢
治淮(2022年8期)2022-09-03
农业科技与信息(2022年5期)2022-06-20
党员生活·下(2019年8期)2019-09-10
党员生活·下(2019年8期)2019-09-10
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
消费导刊(2018年10期)2018-08-20
浙江人大(2018年12期)2018-03-15
