
基于FP_Growth关联规则挖掘的多轨道数字音频文件分类研究
2020-03-03 13:20谢抢来杨威
现代电子技术 2020年1期
谢抢来 杨威


摘 要: 为从海量音频信息中快速准确地获取所需文件,研究基于FP_Growth关联规则挖掘的多轨道数字音频文件分类方法。以数据立方体下具有多维属性的多轨道数字音频文件为研究对象,采用FP_Growth关联规则挖掘算法排序多轨道数字音频文件数据集的频繁1?相集,采用FP tree挖掘频繁项集获取多维关联规则集。识别并提取多轨道数字音频文件中某类型音频文件中的音頻内容,使用删除停用词结合TF/IDF的计算方式获取清洁的音频文件,应用音频文件数据集的多维关联规则集,综合考虑匹配规则数和置信度,搜索规则集,获取该类型音频文件最相配类别,完成多轨道数字音频文件分类。实验结果表明,所提方法能够直观有效地分类多轨道数字音频文件,且分类结果准确率和召回率平均值分别达到96.60%和96.54%,显著高于对比方法。
关键词: 关联规则; 数据挖掘; 多轨道; 数字音频; 文件分类; 数据立方体
中图分类号: TN911.72?34; TP301.6 文献标识码: A 文章编号: 1004?373X(2020)01?0179?04
Research on multi?track digital audio file classification
based on FP_Growth association rule mining
XIE Qianglai, YANG Wei
Abstract: A multi?track digital audio file classification method based on FP_Growth association rule mining is studied to get the required files quickly and accurately from the massive audio information. By taking multi?track digital audio files with multidimensional attributes under the data cube as the research object, FP_Growth association rules mining algorithm is adopted to sort the frequent 1?phase sets of multi?track digital audio file data sets, and FP tree mining frequent item sets are adopted to obtain multidimensional association rules. The audio content in a certain type of audio file in multi?track digital audio files is identified and extracted, the calculation method of deleting stop words combined with TF/IDF is adopted to obtain clean audio files. The multidimensional association rules set of audio file data set is applied to take into account comprehensively the matching rule number and degree of confidence, search the rule sets, obtain the most suitable type of audio file categories and complete the classification of multi?track digital audio files. The experimental results show that the proposed method can intuitively and effectively classify multi?track digital audio files, and the averages of accuracy and recall rate of classification result reach 96.60% and 96.54% respectively, significantly higher than the comparison method.
Keywords: association rule; data mining; multi?track; digital audio; file classification; data cube
0 引 言
不同类型音频信号经采集、量化编码压缩、多轨录入等数字化处理后,以文件形式存储在计算机硬盘等存储媒体内,最终形成多轨道数字音频文件。从多轨道数字音频文件中快速准确地获取所需类型音频文件,在视频编辑、影像分析等领域具有重要的应用价值[1]。
数据挖掘是挖掘并分析项集之间某种潜在关系,这种潜在关系称为关联规则,关联规则可划分为维间、单维、多维、量化等不同类型[2]。由于多轨道数字音频文件具有多维属性[3],因此在分类文件之前需将多轨道数字音频文件数据集内海量多维数据以数据立方体的形式存储起来,这种存储方式不仅简单,且基于数据立方体挖掘数据间关联规则不仅能够节省挖掘时间,还可提升数据挖掘准确率。FP_Growth算法是当前挖掘频繁项集算法中应用最广,且不产生候选项集的关联规则挖掘算法[4?5]。因此,本文研究基于FP_Growth关联规则挖掘的多轨道数字音频文件分类方法,在数据立方体基础上采用FP_Growth多维关联规则挖掘算法挖掘多轨道数字音频文件中不同类型音频间关联规则,根据挖掘到的关联规则对不同类型的数字音频文件进行分类。
1 基本概念
1.1 关联规则
假设[I]和[D]代表项的集合和全体事务集合,而事务[T]是集合[I]的一个子集,则[T?I]。每个事务都有独立的标识,每个标识用[TID]表示。假设[A]是一个项集,[A]在事务[T]之中,则[A?T],关联规则就是类似于[A?B]的蕴涵式,当项集[A]属于事务[T],项集[B]属于项的集合[I],且[A?B=][?]。全体事务集[D]支持规则[A?B],支持度为[s],[s]是全体事务集[D]包含[A?B]的百分比,其条件概率可表示为[PA?B]。[c]为规则[A?B]在全体事务集[D]中的置信度,[c]是全体事务集[D]中同时包含[A]和[B]的事务占[D]总量的百分比,此时条件概率为[PBA],表达式为:
[supportA?B=PA?B] (1)
[confidenceA?B=PBA] (2)
支持最小支持度的同时也支持最小置信度的阈值(min?conf)规则叫做强规则[6]。
1.2 多维关联规则
假若规则不仅只有一个维度,而是具有两个以上的维度,则该规则叫做多维关系规则。例如规则:
[agex,″32…41″∧income x,″43Κ…47Κ″ ?buysx,″?highresolutionTV″] (3)
1.3 数据立方体
使用数据立方体构建多轨道数字音频文件数据集中数据和[OLAP]多维数据模型,数据立方体构建数据模型前需要从多维角度对数据实行角度[7]观察,对数据特定角度的观察、分析所采用的一类特殊属性称为维,数据属性的集合就能形成一个维。数据立方体由维和事实定义,其中事实由数值衡量获取。
数据集中的数据立方体是多维数据存储的一种形象化比喻,且维度不仅限于2维或者3维,它可以是多维的,用[n]维描述,任意[n]维立方体都是[n-1]维立方体的序列。数据立方体中每一个方格记录的都是相应维成员的频繁衡量值[8],可用[count]表示,数据立方体的每一个方格都能够提供预计算的汇总数据,使得多维关联规则支持度以及置信度的计算更加简便。
2 FP_Growth多维关联规则挖掘算法
通過Apriori算法变换可获得基于数据立方体的多维关联规则挖掘算法,但Apriori算法在挖掘关联规则时会受两种非平凡开销影响,导致挖掘结果存在偏差。FP_Growth关联规则挖掘算法是一种在挖掘频繁项集过程中不产生候选项集的算法,该算法构建一个压缩度较高的数据结构(FP),压缩原来的事务数据集。FP_Growth关联规则挖掘算法采用模式增长方式挖掘多轨道数字音频文件中数据集的频繁项集,该算法步骤如下:
1) 频繁1?项集排序。获取频繁1?项集[L]和相应的支持度,扫描多轨道数字音频文件中数据集[L]。
2) 构建[FP tree]。使用“[null]”标记[FP tree]构建的基本点[9],假设[k?]谓词集属于全体事务集合[D],则按照频繁谓词集[L]对[k?]谓词集进行由大到小排列,并用[gG]代表排列后的[k?]谓词集列表。[g]代表第一个谓词元素,[G]代表剩余元素的列表,使用[insert?treegG?T]表示,以下为[FP tree]基本点构建过程执行情况:假设[T]有孩子[N],并设置[N]=[g],即[N.item?name=g.item?name],那么[N]的数量多1;如果[N]≠[g],则需要构建新节点[N],并设置[N]=[g],计数设置为1,与其父节点[T]产生链接,并与具有同[item?name]节点相串联,该串联过程要通过使用节点链结构实现。若剩余元素的列表[G]并不为空[10],则可以调动自身的[insert?treeG.N]。
3) FP tree挖掘。从长度为1的频繁模式开始,构造相应条件模式基。模式基构建完成后,开始构建FP tree,且在FP tree上递归实行[FP tree]挖掘。
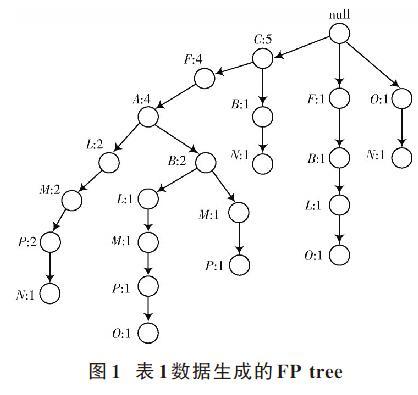
FP_Growth关联规则挖掘算法基本包括上述三个步骤,重点是构建FP tree的过程。给定一个事务数据集后,依据FP_Growth关联规则挖掘算法构建FP tree,可对数据集频繁项信息实行反馈,挖掘承载体由数据集变为FP tree,可简化数据集频繁项挖掘过程。表1为给定的事务数据集,图1为根据表1所示数据并在支持度计数为2时构建的FP tree。
对事物数据集的每个事务分别调用[insert?treegG?T]算法过程就是构建FP tree的过程。假设[Li]是频繁表项,[T]是FP tree,[Lij]代表[Li]的第[j]项,则[g=Li1,G=Li2,…,G=Lin],调用[insert?tree]算法,假设[Lij]代表频繁表项,现将[Lij]嵌入到频繁模式树FP tree中,以算法原理为依据首先判定[T]是否有子节点[N],且设置[N]=[g=Li1],若相同则计数加1,如果不相同则需要构建一个[T]的新子节点,即每一步[insert?treegG?T]算法调用都将遍及[T]的子节点,且遍及子节点的时间复杂度越高,[T]的子节点个数就越多。
假设[Li]有[m]个节点([Li1,Li2,…,Lim])与[T]的子节点([T1,T2,…,Tm],[Tm]是[Tm-1]的子节点)对应相同,设定[brotherTm]代表树节点[Tm]兄弟节点个数,由于函数每一步[insert?treegG?T]算法调用都将遍及[T]的子节点[11],因此[Li]嵌入频繁模式树FP tree的时间复杂度与遍及每一个[Tk],[1≤k≤m]子节点的时间复杂度[O]相乘后的结果相等,即[k=1mObrotherTk]。
通过上述过程基于数据立方体获取多轨道数据音频文件数据集的多维关联规则集。
3 多轨道数字音频文件分类关联规则
目前对数字型多轨道音频文件分类时经常使用关联规则方法,以多轨道数字音频文件数据集中的最强关联规则为分类依据[12]。为实现优质的多轨道数字音频文件分类,需结合上文所述的FP_Growth多维关联规则挖掘算法,研究基于FP_Growth关联规则挖掘的多轨道数字音频文件分类方法。
3.1 多轨道数字音频文件的关联规则表示和预处理
识别并提取多轨道数字音频文件中某类型音频文件的音频内容,每个音频主题数据使用数据立方体表示。设定某类型数字音频文件的类标签和音频分别为[C]和[TT=t1,t2,…,tm],该类型数字音频文件可采用全体事务集[D]的表示方法[D:C,t1,t2,…,tm]描述。多轨道数字音频文件中不同类型音频文件可表示成事务集,某一类型的音频文件由音频和音频文件所属类别共同组成该类型音频文件事务集合的项集,每一条关联规则都从表示该类型音频文件集的事务集中产生。当清理数据时,删除对构造关联分类器作用很小甚至没有作用的音频,为提高多轨道数字音频文件中某一类型音频文件的清洁度[13],通常使用删除停用词结合TF/IDF的计算方式清理音频文件。TF/IDF值获取的计算公式为:
[TFIDFi=TFWi,Doc?log DDFWi] (4)
式中:[TFWi,Doc]代表单音频[Wi]在音频文件中出现的频率;[D]代表数字音频文件总数;[DFWi]代表单音频[Wi]在其中出现至少一次的数字音频文件数目。以下为对TF/IDF权归一化处理公式:
[dij=TFIDFij=1nTFIDF2i] (5)
设置TF/IDF阈值,为获取一个清洁的数字音频文件事务集,需要在该数字音频文件事务集中清除低于该阈值的音频,并基于FP_Growth关联规则挖掘算法对该清洁的数字音频文件事务集进行多维关联规则挖掘,挖掘过程在第2节中有详细描述,此处不再重复。
3.2 利用关联规则进行多轨道数字音频文件分类
经过FP_Growth关联规则挖掘算法挖掘清洁的多轨道数字音频文件事务集获取多维关联规则后,依据该关联规则分类数字音频文件[14],通过搜索规则集获取与该类型音频文件最相配类别的过程,称为多轨道数字音频文件的分类处理过程。通常情况下将多轨道数字音频文件中不同类型音频文件分配到与之规则匹配最多的类别,或是分配给与其第一个规则相匹配的类别。但这种分配方式有一个缺陷,就是在分配过程中没有考虑置信度作用,为解决这一缺陷要综合考虑匹配规则数和置信度的作用。
现给定多轨道数字音频文件中的某一类型数字音频文件,以数字音频文件的音频为依据生成规则列表。将该规则列表按类标签分组,设置一个固定的置信度阈值,删除该类型音频文件分组中低于该置信度阈值的匹配规则,并将所有分组按照置信度的和排序[15]。以下为类识别规则:选择置信度和最大分组的标签作为该类型数字音频文件的类标签;当置信度的和均相等时,将匹配规则最多组的标签作为该类型数字音频文件类标签。具体过程如下:
输入:待分类多轨道数字音频文件中的某类型数字音频文件[Doc=t1,t2,…,tm];关联分类器;置信度阈值[τ]。
输出:待分类多轨道数字音频文件中的某类型数字音频文件[Doc]的类标签
方法:
1) [Count=0]
2) 初始化音频文件事务集[S←Φ]
3) 检索规则库中的每个规则
//以规则前件和[Doc]数字音频文件音频为依据,生成规则列表
4) [ifr Doc ∧r.confidence>τ]
5) [S←S?r]
6) 以类标签为依据将入选规则集分成多个子集,该子集可表示为[S1,S2,…,Sn]
7) 检索子集[S1,S2,…,Sn]
8) 汇总规则信任度,统计规则数
9) 根据置信排序子集[S1,S2,…,Sn]
10) 将类分配给新音频文件
4 仿真测试
采用本文提出的基于FP_Growth关联规则挖掘的多轨道数字音频文件分类方法对某类型音乐广播电台多轨道数字音频文件中不同类型的音频文件进行分类,得到分类结果如图2所示。
图2中,上面的音频波(绿色)为MP3歌曲音频文件,下面的音频波(红色)为WAV语音广播音频文件,不同类型音频文件使用不同颜色标注,且从图中可看出两种音频波形并不一致,说明本文方法可以有效地分类出实验多轨道数字音频文件中不同类型的音频文件。
为验证本文方法对多轨道数字音频文件分类方面的优越性能,对上一实验中的实验对象进行关联规则挖掘識别。实验对象中包含MP3,WMA,MIDI,WAV,CDA,AU,AIF,RM,VOC等格式数字音频文件共计4 296份,随机抽取其中95%作为训练集,余下5%作为测试集。采用三种方法挖掘训练多轨道数字音频文件数据集中的音频文件,并将挖掘到的关联规则运用到测试数据集中完成数字音频文件分类,分类结果见表2。
由表2可知,采用本文方法分类多轨道数字音频文件中不同类型音频文件的分类结果准确率最高,平均值达到96.60%,且召回率也是三种方法中最高的,平均值达到96.54%,说明本文方法分类多轨道数字音频文件的性能较好。
5 结 论
快速准确地从海量多轨道数字音频文件数据中找到有用的信息是网络技术发展的必然要求。本文研究基于FP_Growth关联规则挖掘的多轨道数字音频文件分类方法,该方法不仅降低了多轨道数字音频文件数据挖掘过程中候选项目集的产生数量,还减少了数字音频文件数据扫描次数,提高多轨道数字音频文件分类效率。本文方法在对多轨道数字音频文件分类方面具有较好的发展前景。
参考文献
[1] 吕璐成,赵亚娟,王学昭,等.基于关联规则挖掘的研发团队识别方法[J].科技管理研究,2016,36(17):148?152.
[2] 张雪萍,李围成,祝玉华.基于 FP?树的时空关联规则挖掘算法研究[J].微电子学与计算机,2016,33(8):130?133.
[3] 张稳,罗可.一种基于Spark框架的并行FP_Growth挖掘算法[J].计算机工程与科学,2017,39(8):1403?1409.
[4] 申彦,朱玉全,刘春华.基于磁盘存储1项集计数的增量FP_Growth算法[J].计算机研究与发展,2015,52(3):569?578.
[5] 王建明,袁伟.基于节点表的FP_Growth算法改进[J].计算机工程与设计,2018,39(1):140?145.
[6] 李维娜,任家东.软件群体中基于交互序列的频繁模式挖掘算法研究[J].小型微型计算机系统,2018,39(5):1046?1051.
[7] 王艷辉,王淑君,李曼,等.基于改进FP_Growth算法的CRHX型动车组牵引系统关联失效模型研究[J].铁道学报,2016,38(9):72?80.
[8] 程广,王晓峰.基于MapReduce的并行关联规则增量更新算法[J].计算机工程,2016,42(2):21?25.
[9] 唐晓东.基于关联规则映射的生物信息网络多维数据挖掘算法[J].计算机应用研究,2015,32(6):1614?1616.
[10] 徐开勇,龚雪容,成茂才.基于改进Apriori算法的审计日志关联规则挖掘[J].计算机应用,2016,36(7):1847?1851.
[11] 刘军煜,贾修一.一种利用关联规则挖掘的多标记分类算法[J].软件学报,2017,28(11):2865?2878.
[12] 王雯,赵衎衎,李翠平,等.Spark平台下的短文本特征扩展与分类研究[J].计算机科学与探索,2017,11(5):732?741.
[13] 王莉莉.多维多层数据的无冗余跨层挖掘算法[J].微电子学与计算机,2018,35(2):113?117.
[14] 李洪成,吴晓平,俞艺涵.基于多维频繁序列挖掘的攻击轨迹识别方法[J].海军工程大学学报,2018,30(1):40?45.
[15] 郭烨,海霞,赵长青,等.数字音频广播与航空无线电导航业务兼容性研究[J].电视技术,2017,41(6):62?67.
作者简介:谢抢来(1984—),湖南人,工程硕士,讲师,研究方向为数据挖掘、数据库信息优化。
杨 威(1985—),湖北人,工程硕士,讲师,研究方向为计算机应用。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
电子制作(2017年10期)2017-04-18
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
现代商贸工业(2016年35期)2016-04-09
西部广播电视(2015年10期)2016-01-18
西部广播电视(2015年8期)2016-01-16
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
