
基于DPDK的DDoS攻击防御技术分析与实现
2020-02-27 10:58:34余思阳杨佑君李长连中讯邮电咨询设计院有限公司北京00048中国联通软件研究院北京0076
邮电设计技术 2020年1期
余思阳,杨佑君,李长连(.中讯邮电咨询设计院有限公司,北京 00048;.中国联通软件研究院,北京 0076)
0 前言
互联网技术的快速发展,运营商4G技术的广泛使用以及5G技术的快速演进给人们带来便捷的同时,也使网络攻击等违法行为的规模及数量迅速增长,分布式拒绝服务攻击(DDoS)是最主要的威胁之一。其中网络层SYN Flood和UDP Flood是流量最大的2种攻击类型,并且SYN Flood 大流量攻击数量从2018 年1 月以来显著增加。
防御DDoS 攻击的主流技术是流量清洗,其核心是采集流量并分析,传统基于Linux 内核的流量清洗技术由于较大的网络开销和系统资源消耗导致其难以满足当前需求。针对这一趋势,本文提出一种基于Intel DPDK 的DDoS 攻击防御方案,旨在当前Linux 内核流量清洗技术的基础上,达到更高的流量清洗能力,为DPDK 技术应用领域拓展以及DDoS攻击防御性能提升提供新的思路。
1 流量清洗技术性能研究
流量清洗系统主要由检测模块、清洗模块和管理模块组成,主要架构如图1 所示。首先由检测模块进行数据包捕获和识别,并将相应日志上报管理模块,然后管理模块根据清洗策略将相应的清洗命令下发到清洗模块设备,清洗模块收到清洗指令后将流量引流到清洗设备进行清洗,最后将清洗后的正常流量回注到网络中。其中影响流量清洗系统效率的一个重要因素是检测模块的数据包捕获和识别速度。

图1 流量清洗系统架构
目前主流的数据包捕获方式是基于Libpcap(Packet Capture Library)技术开发的数据包捕获机制。Libpcap 最初是由劳伦斯伯克利实验室网络研究小组的tcpdump开发人员开发,是在Unix/Linux平台中提供的网络数据包捕获函数包。其主要工作流程如下:首先设置为混杂模式的网卡根据配置进行DMA(Direct Memory Access)操作并发送中断指令到处理器,处理器被唤醒后调用指令填充读写缓冲区数据结构,即复制数据到内核缓冲区,然后在内核协议栈中进行过滤处理,最后复制数据到用户空间。在这种方式下每个数据包都会触发1 个中断和2 次拷贝,并且造成缓冲区资源和系统资源消耗。所以在大流量攻击下会导致系统负载过大,造成时延过大、丢包率过高甚至系统瘫痪。
2 Intel DPDK简介
相比Libpcap,Intel DPDK 出色的数据包加速处理性能以及充分的用户空间灵活性,使其成为更好的解决方案。下面简要介绍DPDK的原理及实现。
2.1 DPDK架构
Intel DPDK(Data Plane Development Kit)是由英特尔公司开发的一款数据平台开发套件,是一个基于x86 平台用C 语言编写的用于快速数据包处理的函数库和驱动的集合。DPDK的基本架构如图2所示,其中最底层硬件平台使用网卡接收数据包,内核空间的3个模块分别为KNI、UIO 和EAL。DPDK 利用UIO 模块将网卡硬件寄存器映射到用户空间,从而跳过Linux内核网络协议栈,在用户空间直接运行驱动从网卡上读取数据并进行处理。EAL 模块是DPDK 核心模块之一,主要进行资源分配及初始化,并为底层资源访问提供用户层入口。

图2 DPDK的基本架构
2.2 DPDK核心技术
DPDK实现快速数据包处理主要依赖以下技术。
a)轮询模式驱动(PMD——Poll Mode Driver):该驱动不同于Linux 内核的中断模式驱动,而是收到数据包后直接通过DMA 方式传送到预分配内存并直接处理,避免了中断上下文切换开销。
b)用户态驱动:用户态驱动可减少不必要的内存拷贝和系统调用,基本可在用户空间实现驱动,并且用户态驱动可以根据不同场景进行更新和优化。
c)大页内存(Hugepage):对于物理地址转换虚拟地址,Linux 一般通过查找TLB 表映射,其默认页大小为4K,而采用2M 或1G 的大页内存,则TLB 的页表项会显著较少,从而极大减少页表查找频率,并降低TLB miss开销。
d)亲和性和独占:利用线程的CPU 亲和绑定机制使特定任务被指定在某个特定的核上执行,这样可避免线程在不同核之间频繁切换而造成的性能损失。
3 基于DPDK的DDoS攻击防御方案
3.1 方案设计
当前应用需求多为千兆和万兆网络中的大容量数据通信与高速数据包捕获分析和处理,本方案主要针对当前攻击流量最大的TCP Flood 和UDP Flood 进行防御,主要工作流程为:首先通过IP 报文协议号(TCP 为6,UDP 为17)筛选出TCP 包和UDP 包;然后通过报文源端口号区分不同的UDP 反射放大攻击类型,例如DNS 反射放大攻击源端口号为53,NTP 反射放大攻击源端口号为123;分别实时统计不同类型攻击的速率,当速率大于设定阈值时丢弃后续收到的此类型的数据包。
使用DPDK 编写程序的目标是最大化地利用服务器的网络吞吐与处理能力,确保多个网卡、多个核并行工作,同时不出现资源竞争与冲突,因此借鉴网络负载均衡的理念,设计了一个软负载均衡的架构(见图3),其中划分了I/O 接收逻辑核、工作者逻辑核与I/O 发送逻辑核3 个角色,用于接收数据包、处理数据包、发送数据包,并分别绑定物理核,3 个角色间利用DPDK中的ring缓存队列进行数据交互。
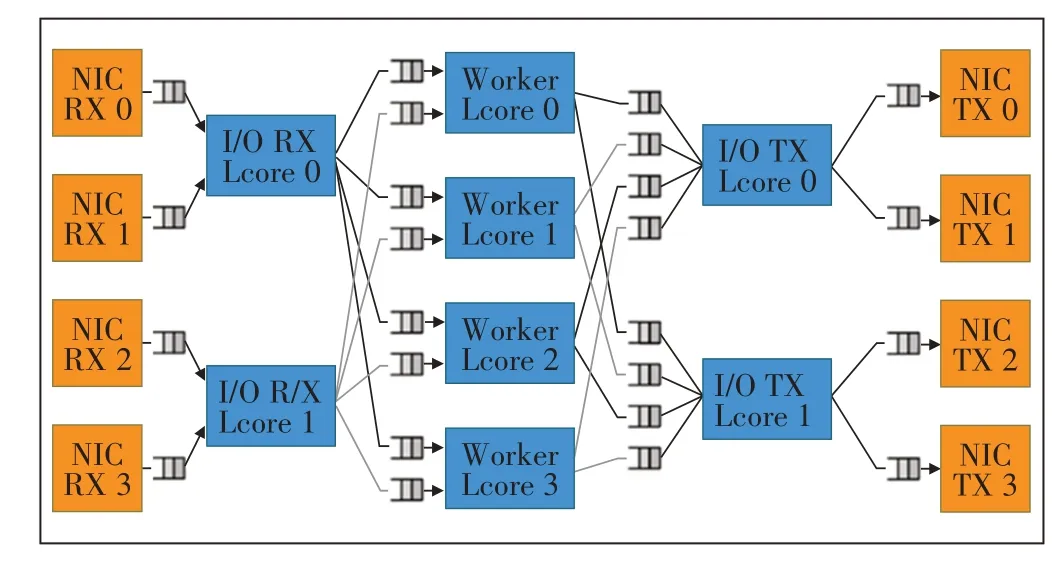
图3 软件处理架构设计图
3.2 方案实现
DPDK 的进程分为控制进程和数据进程。控制进程通常与主核绑定,主要接收用户配置,并传递配置到数据进程;数据进程通常进行数据包处理工作。
3.2.1 控制进程
控制进程主要工作流程如图4 所示,具体实现步骤为:

图4 控制进程工作流程图
a)从main 函数开始执行,首先调用rte_eal_init 函数初始化环境抽象层EAL,构建DPDK 基础工作环境;然后解析输入参数,获取分配的网口、核、队列数等配置,根据配置初始化可用端口、大页内存、发送队列和接收队列,创建LPM 表或HASH 表,用于将目的IP 为不同网段的数据包从指定网口发出。
b)完成环境配置和初始化后调用rte_eth_dev_start 函数启动设备,包括启动绑定DPDK驱动的网卡。
c)通过rte_eal_mp_remote_launch 在每个lcore 上都启动main_loop 线程,其中main_loop 函数为主处理函数。
3.2.2 数据进程
数据进程主要步骤如图5 所示,进程从main_loop函数开始,进行相关配置初始化后进入主循环,首先批量接收数据包,利用rte_pktmbuf_mtod 获取以太网头部,将其地址后移以太网头部的长度即可获取数据包的ipv4 头部地址,判断ipv4 头部中next_proto_id 字段的值,若为17 则是UDP 包,若为6 则是TCP 包;如果是UDP 包则判断src_port 的值,以区分不同类型的UDP 报文攻击;分别统计不同类型数据包数量并定时计算吞吐量,判断吞吐量是否大于设定阈值,若大于阈值则认为是攻击流量,后续收到此类型数据包将不进行转发,直接释放其mbuf;若小于阈值则认为是正常数据报文,根据ipv4 头部的dst_addr 获取目的IP 地址,查找LPM 表进行最长前缀匹配得到转发出口网口,最后将数据包通过对应网口批量转发出去。
4 实验验证及结果分析
4.1 数据源
本实验采用思博伦公司的网络数据测试仪spi⁃rent testcenter模拟不同类型的DDoS攻击流量。
4.2 实验环境
实验环境为一台dell服务器,基本配置信息如表1所示。
4.3 实验方法
根据上文所述,影响流量清洗的主要因素之一是检测模块的数据包捕获与识别性能,故本实验主要进行数据包捕获识别性能的对比,测试Libpcap 与DPDK在不同攻击流量与数据包长度条件下的处理性能。Libpcap 是Unix/Linux 系统下的用于捕获网络数据包的函数库,是大多数网络数据包分析软件的基础,如tcpdump、snort、Ethereal等。

图5 数据进程工作流程图

表1 实验平台基本配置表
以UDP 包为例,利用流量测试仪发送不同包长和吞吐率的流量,测试不同条件下二者的性能差异。编写DPDK 程序实时在控制台打印数据包收发包数、吞吐量等信息,方便后续统计对比。
首先测试DPDK 数据包捕获性能,用spirent test⁃center 测试仪产生包长为128 B、256 B、1 024 B 的UDP包,分别以1 Gbit/s、8 Gbit/s、10 Gbit/s 速率发送,测试时延和丢包率;以同样的方法测试Libpcap数据包处理时延和丢包率,然后比较两者的性能。
4.4 实验结果
DPDK 与Libpcap 在不同包大小和不同发送速率情况下的平均时延分别如图6 和图7 所示。从图6 和图7 可看出随着数据包发送速率的增大,DPDK 与Lib⁃pcap 的数据包处理时延都显著增加,DPDK 方式处理数据包的时延远小于Libpcap,有4 个数量级的差距,具有明显优势。
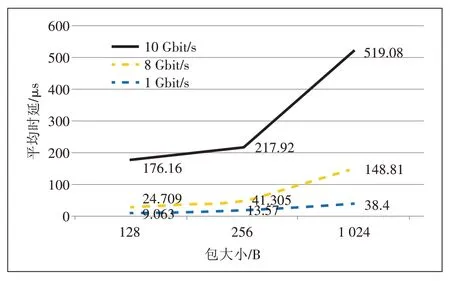
图6 DPDK处理数据包时延统计图

图7 Libpcap处理数据包时延统计图
DPDK 与Libpcap 的丢包率性能分别如图8 和图9所示,两者的丢包率都随数据包发送速率增大而增加,其中DPDK 捕获数据包的丢包率非常低,流量为10 Gbit/s时丢包率有增加是由于服务器万兆网卡本身的性能限制,而Libpcap 捕获数据包的丢包率很高,128 B 小包的丢包率接近90%,因此DPDK 处理数据包的可靠性更高。
通过DPDK 与Libpcap 的数据包处理性能对比分析,可以看出DPDK具备明显的优势。
5 结束语
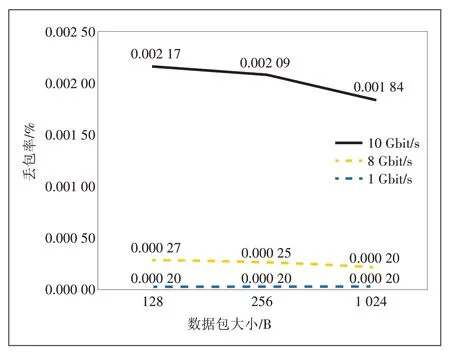
图8 DPDK处理数据包丢包率统计图

图9 Libpcap处理数据包丢包率统计图
利用DPDK 快速处理数据包的性能优势以及可在用户空间设计应用程序的特点,本文提出一种基于DPDK 的DDoS攻击防御技术。同时通过实验证明DP⁃DK相比于传统的Libpcap方案在各项性能指标上都有非常显著的优势。将DPDK 与更多的流量清洗方法以及DDoS 攻击防御方法相结合以提高防御效率将是后续研究的方向。
猜你喜欢
科技与创新(2023年17期)2023-09-17 12:26:12
舰船科学技术(2022年10期)2022-06-17 06:27:42
计算机与数字工程(2022年1期)2022-02-16 08:32:54
中国外汇(2019年20期)2019-11-25 09:54:58
网络安全和信息化(2019年1期)2019-02-15 02:45:42
电讯技术(2018年10期)2018-10-24 02:35:00
铁道科学与工程学报(2015年4期)2015-12-24 12:11:24
电脑爱好者(2015年15期)2015-09-10 07:22:44
民主与科学(2014年3期)2014-02-28 11:23:03
教育与职业(2014年7期)2014-01-21 02:35:04
