
SSCI文献引文数据的预处理
2020-02-24 16:31严建新
科学与管理 2020年1期
关键词:预处理
严建新
摘要:在SSCI的文献数据中,同一专著或文集类在被引用时题名、版本年份及作者名拼写存在着不一致的情况,为了使其具有一致性,本文提出了对引文数据进行预处理的方法。对文献数据进行文献和作者共被引分析,分别获得重要文献和作者的列表;对文献名和作者名按字母排序,找出同一文献不同的题名和出版年份以及同一作者名的不同拼写,利用“搜索”和“替换”功能对引文数据进行修改。经过对引文数据的预处理,共被引网络中的重要节点及其被引次数,以及共被引连线明显增多。对于著作和文集类被引文献占较大比例的社会科学研究领域,进行引文数据预处理有助于获得更客观的计量分析结果。
关键词:引文数据;预处理;SSCI;共被引分析
中图分类号:G353.1文献标识码: ADOI:10.3969/j.issn.1003-8256.2020.01.006
开放科学(资源服务)标识码(OSID):
基金项目:广西高校科研重点项目(ZD2014009)
《科学引文索引》(Science Citation Index,SCI)是对自然科学研究成果进行文献计量分析常用的数据源之一,针对其数据结构,已开发出多种计量分析工具[1]。1973年,美国科学情报研究所(Institute for Scientific Information)按照SCI的模式又创立了社会科学引文索引(Social Science Citation Index,SSCI)。这两个数据库的文献数据结构相同,文献的引文数据的格式也相同。因此,基于SCI文献数据结构开发的计量分析工具也同样可用于分析SSCI的文献数据。然而,笔者发现,社会科学的许多学科领域有其自身的特点,专著、文集类文献在被引文献中占有较大的比例。这类文献的题名拼写和版本年份往往存在不一致的问题。为了获得更为客观的分析结果,有必要在计量分析前对这些领域的引文数据进行预处理。
2010年,董琳[2]探讨了SCI文献数据中机构名和国名的处理问题,孙源[3],张晋辉和刘清[4]分别提出了针对SCI文献数据中地址字段的处理方案。但笔者未能检索到有关处理著作题名和版本年份的研究文献。
1期刊文献在被引文献中的比例
为了比较被引文献中期刊文献所占的比例,笔者在SSCI和SCI数据库中选择了若干期刊:
(1)根据SSCI数据库对期刊的分类,在各类别中分别选择1种有代表性的期刊,共计57种;
(2)在SSCI数据库中,以“Marx*”为检索词进行主题检索,选择载文数量最多的前8种期刊;
(3)除选择Nature和Science外,在SCI数据库按数学、物理、化学、天文、生物和地质6个一级学科各选择1种有代表性的期刊,共计8种。
以表格格式(win)分别下载上述期刊2017年最后一期的论文(article)数据。利用Excel软件分别打开上述数据文件,从中各提取20篇论文的引文信息。通过人工粗略甄别,统计出被引期刊文献在全部被引文献中的百分比。
从表1中可以看到,SCI数据库中6个一级学科的代表性期刊,以及Nature和Science的被引期刊文献在全部被引文献中的百分比都相当高,有7种期刊在90%以上,最低的Biological Reviews也接近90%。该百分比在这8种期刊中的平均值为92.5%。

SSCI數据库按研究领域将收录期刊划分为57个类别,表2为各类别的代表性期刊的被引期刊文献在全部被引文献中的百分比。这一比例在不同类别中存在较大的差异,其中百分比较高的是与自然科学有相同或相近研究范式的学科领域,如精神病学(Psychiatry)、心理学(Psychology)、管理学等学科。而历史学、社会学、文化学等学科则因研究范式的不同,这一比例就比较低,其中AmericanHistoricalReview只有28.0%。

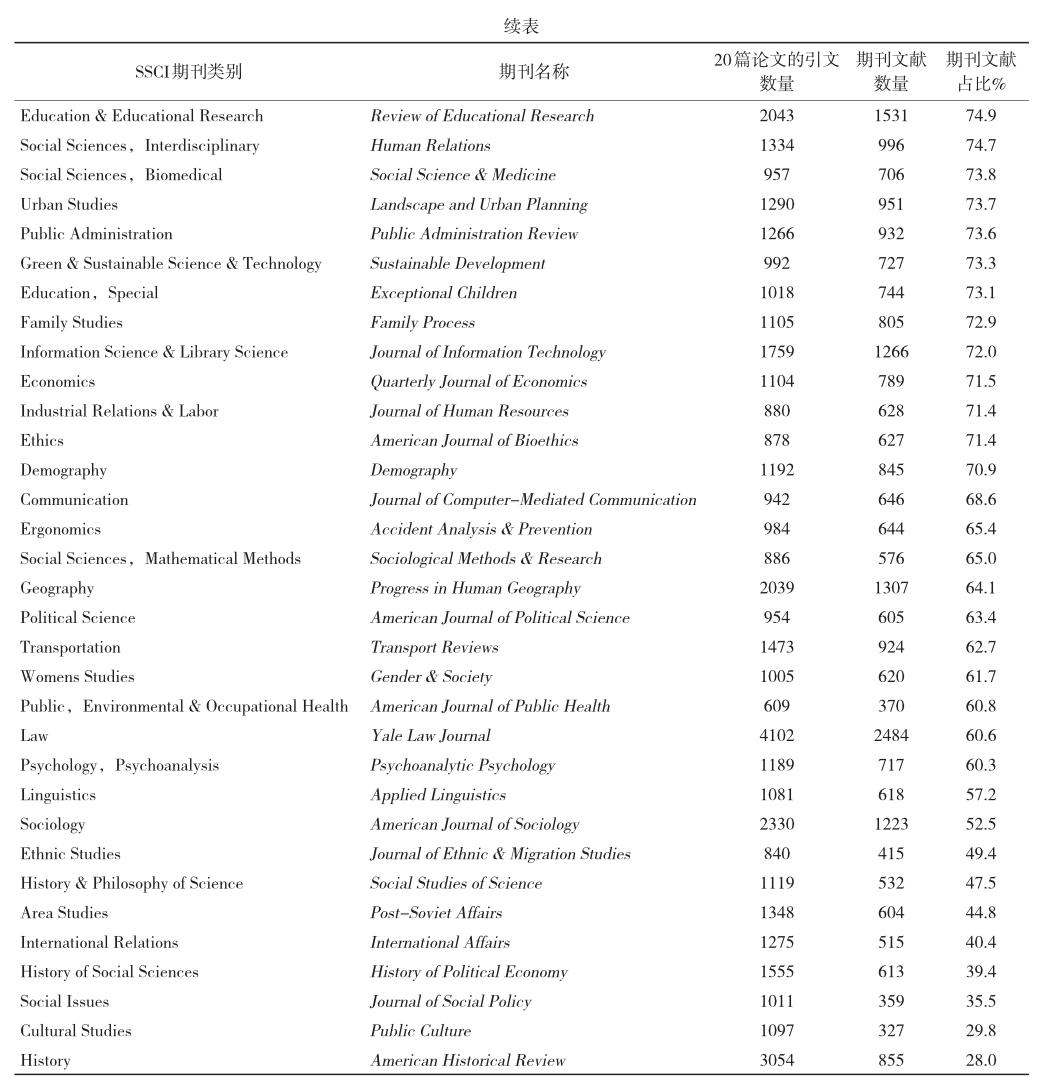
表3列出的是2017年刊载马克思主义研究成果最多的前8种期刊,被引期刊文献在全部被引文献中所占的百分比都比较低,最高的Antipode不到50%,而最低的Historical Materialism Research in Critical Marxist Theory仅有20%。这8种期刊的平均数为34.8%。
2专著和文集类引文带来的问题
期刊论文的引文主要为两大类型,一是期刊类文献,二是专著和文集类文献。其他类型的被引文献,如新闻报道、年鉴、报告等,在全部引文中所占的比例低较。
运用计量学软件对SCI和SSCI的文献数据进行作者共被引和文献共被引分析时,对于期刊类被引文献而言,主要涉及被引文献第一作者名、出版年号、期刊名、卷号等信息;对专著和文集类文献而言,则主要涉及被引文献第一作者名、出版年号、专著或文集题名、卷号等信息。如今,期刊名已实现了标准化,但专著和文集的题名则未进行标准化。当同一部专著或同一本文集中的同一文献被不同学者引用时,题名的拼写就有可能会出现不一致。如果该专著或文集被再版,或被翻译成其他语种出版,就会出现版本年份的不一致。这导致软件将其判定为不同的文献,在共被引网络中同一被引文献就会分裂成多个节点。一般而言,越是经典的专著,节点分裂的现象越是普遍。因此,对引文数据的预处理是文献计量分析的基础工作之一,它直接决定分析结果的客观性[5]。
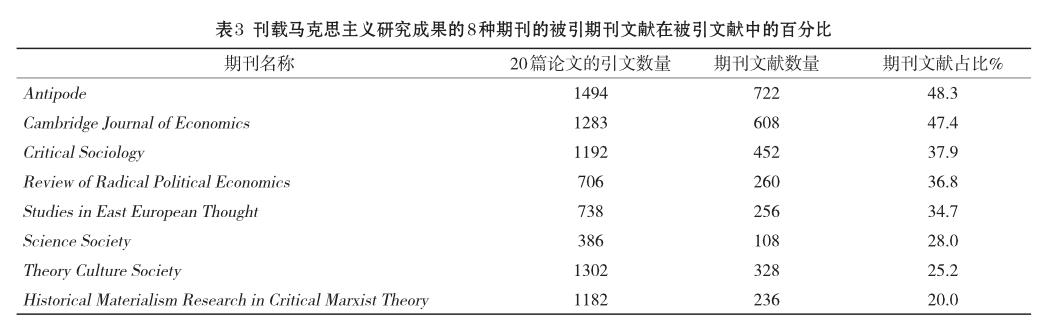
以“Marx*”为条件,对1998—2017年SSCI收录的论文进行主题检索,获得4034条文献数据。在运用CiteSpace[6]做文献共被引分析时发现,马克思的经典著作《政治经济学批判大纲》由于题名缩写和版本年份的不同(表4),这一文献在共被引网络中分裂成许多节点。类似地,《资本论》《哥达纲领批判》《共产党宣言》《德意志意识形态》《1844年经济学哲学手稿》,以及葛兰西的《狱中札记》、亚当·斯密的《国富论》、哈维的《资本的极限》等经典著作都存在节点分裂现象。
在文献共被引和作者共被引网络中的节点分裂,有可能使分析结果无法真实反映文献和作者对特定研究领域所产生的影响和作用。因此,对于著作和文集类被引文献占较大比例的研究领域,在计量分析前有必要对原始的引文数据进行预处理,尽量消除上述的不一致现象。
3引文数据的预处理
引文数据的预处理是将原始数据中同一著作或文集的题名、同一作者的姓名缩写统一起来,并将同一著作或文集的版本年份统一起来。根据笔者的经验,可通过以下步骤完成这一工作:
(1)合并文献数据。SSCI每次可下载500条文献数据,如数据量超过500条,将会得到2个以上的数据文件。为了便于预处理,需要将所有的数据文件合并为1个,在合并前应先备份全部数据文件。
用鼠标右击数据文件,在“打开方式”中选择“写字板”。每一条文献数据均以“PT”开始,并以“ER”结束。打开第一个数据文件后再打开第二个数据文件,将第二个文件中从第一个“PT”到最后一个“ER”的部分复制到第一个文件末尾的“ER”和“EF”之间。重复上述过程,直到将所有数据文件的内容全都复制到第一个数据文件中,以完成文献数据的合并。合并后,应更改文件名并做备份。
(2)获取作者和文献的信息,找出不同的拼写和版本年份。运用CiteSpace软件,设置适当的阈值对合并后的文献数据分别进行作者共被引和文献共被引分析,從而获得满足阈值的作者列表和文献列表。阈值越低,越有利于发现分裂开的小节点,但阈值的设置必须兼顾电脑的运算能力。
将作者列表复制到Word文件中,并按作者名排序,找出同一作者名的不同拼写。将文献列表复制到Word文件后,先将表格转换为文本,再以逗号为分隔符将文本转换为表格,然后分别按文献名和作者名进行排序,分别找出同一文献名的不同拼写、不同版本年份和同一作者名的不同拼写。
(3)修改引文数据,统一拼写及版本年份。用写字板打开合并后的数据文件,利用“查找”和“替换”功能,将同一作者名、同一文献的题名和同一文献的版本年份分别统一起来。例如,将《政治经济学批判大纲》的作者名统一为“Marx K”,题名和版本年份分别统一为“GRUNDRISSE”和“1857”。
(4)复查。设置适当的阈值对处理后的数据分别进行作者共被引和文献共被引分析,按步骤(2)对获得的作者和文献列表进行复查,如同一作者名、同一文献题名和同一文献的版本年号仍有不一致的情况,则应按步骤(3)进行修改。
在上述的步骤(2)中,如遇到作者和文献的一致性无法直接判定的情况,应充分利用搜索引擎、百度学术、多语种电子词典、DOI代码等工具进行交叉印证。
4结果与讨论
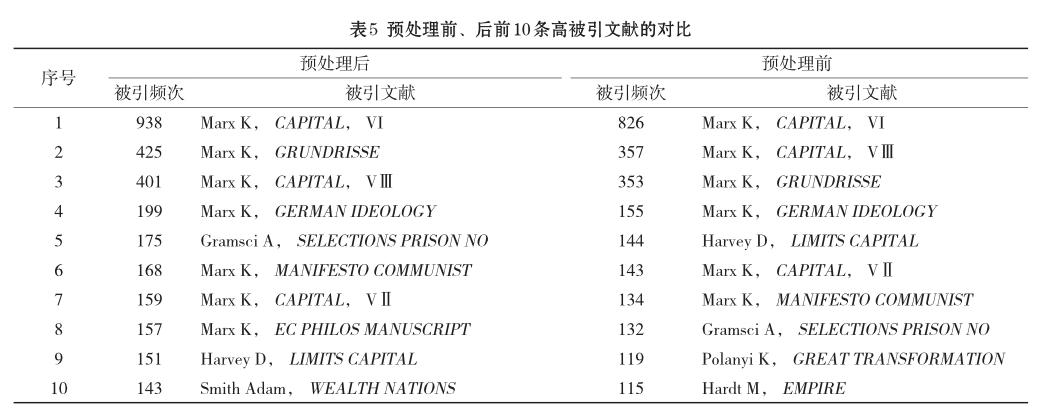
笔者对上述4034条马克思主义研究的引文数据进行多轮预处理后,获得文献共被引图谱(图1),图中包含123个文献节点,364条共被引连线。采用相同阈值对预处理前的数据进行文献共被引分析,所得图谱只包含72个文献节点,仅有188条共被引连线(图2)。相比较而言,预处理后满足阈值的节点增加了约71%,共被引连线增加了约94%。就节点《政治经济学批判大纲》而言,预处理后其被引次数由353次增加到425次,增加了20%。在预处理前、后的文献共被引网络中,被引文献的排序(表5)和被引作者的排序也相应发生了变化,这表明,经过上述的预处理,可有效地减少节点的分裂现象。

文献的共被引分析有助发现对一个研究领域的发展产生较大影响的研究成果,也有助于揭示该领域的研究热点和前沿,而作者的共被引分析则有助于评价学者对该领域的研究所做的贡献。由于著作和文集类被引文献在题名拼写、版本年份和作者名拼写上存在不一致,当这类文献在引文中占有较大比重时,就有可能会对分析结果产生不利的影响。实践表明,对引文数据进行预处理虽不能完全消除但能有效地减少节点的分裂现象,有助于提高计量分析的客观性。然而,这类文献占多大的比例就必须进行预处理,这一问题还有待开展进一步的实证研究。
参考文献:
[1]李艳,张悦,曾可,等.文献信息分析工具的比较[J].中华医学图书情报杂志, 2015, 24(11): 41-47.
[2]董琳.学科评价之文献计量数据准备[J].情报理论与实践, 2010, 33(6): 49-52.
[3]孫源.基于Word2Vec的SCI地址字段数据清洗方法研究[J].情报杂志, 2019, 38 (2): 195-200.
[4]张晋辉,刘清.基于推理机的SCI地址字段数据清洗方法设计[J].情报科学, 2010, 28(5): 741-746.
[5]闫雪,欧阳海鹰,曾首英,等.文献计量数据准备之数据采集与清洗:以中国水产科学研究院中文期刊论文分析为例[J].农业图书情报学刊, 2014, 26(4): 36-40.
[6]Chen, C. CiteSpaceⅡ: Detecting and visualizing emerging trends and transient patterns in scientific literature [J]. Journal of the American Society for Information Science and Technology, 2006, 57(3): 359-377.
The Citation Data Pre-Processing for SSCI Literature Data: A Case Study of Marxism Research
YAN Jianxin
(1.SchoolofMarxism,GuangxiUniversity,Nanning530004,China;2WISELab&ScienceofScienceand ManagementofScienceandTechnologyResearchInstitute,DalianUniversityofTechnology,Dalian116024,China)
Abstract: In SSCI literature data, a book or collected works sometimes is cited in different spellings in title and authors name, and in different publishing years due to different versions, this article proposes a way of citation data pre-processing in order to make them uniform.Obtain the title list of important cited literatures and name list of important author by cocitation analyses, rank the lists alphabetically and find out the different spellings and different publishing years, and then, make them uniform by searching and replacing.After the pre-processing of citation data, the important nodes and their citation frequency, as well as the co-cited links increase obviously in the co-citation networks. For the social research fields with high percentage of cited books or collected works, citation data pre-processing is helpful to make the bibliometric analysis more objective.
Keywords: citation data;pre-processing;SSCI;co-citation analysis
猜你喜欢
天津农业科学(2022年6期)2022-07-19
健康体检与管理(2022年4期)2022-05-13
安徽农学通报(2016年24期)2017-01-12
中国高新技术企业(2016年32期)2016-12-27
热带农业科学(2016年10期)2016-12-12
艺术科技(2016年9期)2016-11-18
中国市场(2016年34期)2016-10-15
科技视界(2016年16期)2016-06-29
中国实用医药(2016年10期)2016-05-04
中国实用医药(2016年6期)2016-03-17
