
基于Spark平台的ALS加速算法研究
2020-02-19 11:26:42贾晓芳桑国明祁文凯
计算机工程 2020年2期
贾晓芳,桑国明,祁文凯
(大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 概述
在互联网时代,海量规模的数据信息虽然能够满足用户的多样化需求,却难以让用户在搜索时直接获取目标信息,信息处理技术的性能具有很大的提升空间。国际数据集团(IDC)2012年的报告显示,预计2020年的全球数据总量将达到35.2 ZB,是2011年的22倍[1]。从信息匮乏到信息过载[2-3],数据信息量产生巨大改变,但用户对信息的使用效率并未大幅提高。在这样的大数据背景下,推荐系统[4-5]应运而生,其根据用户潜在需求和兴趣来提供个性化的推荐服务。文献[6]中的邮件过滤系统被认为是互联网时代较早提出并被广泛应用的协同过滤系统。协同过滤推荐系统[7-8]可以尽可能地满足用户的需求,产生与用户喜好相关且数量有限的物品推荐列表。Amazon、NetFlix、淘宝等众多国内外知名网站中的推荐服务皆依赖协同过滤推荐系统,其中,用户和物品种类的数量相当庞大,这对协同过滤推荐系统的准确性、执行效率和排名精度都有非常高的要求。
协同过滤推荐算法[9]是一种典型的大数据挖掘算法,其基于用户或物品的相似性来进行推荐。尽管协同过滤推荐算法的应用使推荐系统获得了用户的认可,但稀疏性高、执行效率与排名精度低等问题依然存在。为此,研究人员提出一类高效的基于模型的协同过滤算法,其中,基于交替最小二乘(Alternating Least Squares,ALS)[10]的矩阵分解(Matrix Factorization,MF)模型[11]可实现并行计算,该特性使其在速度方面具有明显优势,但是,该模型存在数据加载时间长、矩阵分解与迭代收敛慢等问题。国内外学者先后围绕上述问题进行了优化,其中,快速矩阵分解模型IALS[12]、LS-WR、NALS-WR[13]、ALS++[14]等改进优化方法的侧重点在于缩短数据加载与矩阵分解的时间以及改变ALS预测模型等,但对于ALS迭代收敛慢的问题研究较少。
本文提出一种在ALS中融入非线性共轭梯度(Nonlinear Conjugate Gradient,NCG)的算法ALS-NCG[15],以加速ALS算法的收敛,提高执行效率和排名精度。
1 基于矩阵分解的ALS算法
MF算法具有伸缩性好、灵活性高的特点[16]。在Netflix Prize算法比赛中,文献[17]提出了基于ALS的协同过滤算法,其能很好地解决矩阵稀疏性问题。
1.1 ALS算法
ALS算法利用迭代求解一系列最小二乘的回归问题。对于用户-项目评分矩阵R,找到一个低秩矩阵R′来逼近原始数据评分矩阵R,完整过程如下:
R≈R′=UVT
(1)

损失函数定义为:
(2)
其中,L表示损失函数。
为防止过拟合,对式(2)进行正则化处理,得到优化式(3):
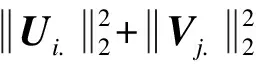
(3)
其中,λ表示正则化参数。

(4)
其中,Ri.表示用户i对项目的评分矩阵,Vui表示用户i所评价过的项目涉及的特征向量所形成的特征矩阵,nui表示用户i所评价的项目数量。同理,固定U后对Vi求导,然后根据求导结果解出Vj.:
(5)
(6)
其中,R.j表示评分过项目j的用户的评分向量,Umj表示评分过项目j的用户的特征向量所组成的特征矩阵,nmj表示评分项目j的用户数量。
1.2 ALS算法存在的问题
基于ALS矩阵分解的协同过滤推荐算法通过对ALS算法的迭代,在Spark集群环境下训练出最佳模型并获取最优参数,但是ALS算法自身存在的一些不足无法通过模型训练、参数优化来改进。比如成本消耗问题,有数据表明,推荐系统利用基于Spark的ALS算法进行实时推荐,输入数据114 GB,训练时间和预测时间总和超过50 min,是实际要求时间的3倍多,超出的时间将导致巨大的资源消耗,且推荐结果的准确性也较低。
针对ALS算法存在的问题,本文将加速收敛过程以优化ALS模型,并在优化f(U,M)的过程中提高推送结果的准确性。
2 基于NCG的ALS算法
2.1 NCG算法

(7)
NCG算法用递推关系xk+1=xk+αkpk从初始猜测x0中生成迭代序列xi,i≥1,步长参数αk>0是沿着搜索方向pk的线搜索而确定的,每次迭代包括计算线搜索方向pk和步长因子αk两部分,搜索方向pk要求为下降的方向,沿着该方向搜索找到比xk更好的点。求解minU,MLλ(R,U,M)的共轭梯度算法是根据求解线性方程组问题推广而来,搜索方向为负梯度与上一次搜索方向的线性组合。pk求解如下:
(8)
其中,βk+1表示更新参数,本文在更新βk+1时使用PRP共轭梯度法[20],如式(9)所示。
(9)
NCG算法伪代码描述如下:
算法1NCG算法
输入x0
输出xk
g0←f(xk);
p0←-g0;
k←0;
while gk≠0 do
Compute αk;
xk+1←xk+αkpk;
gk←f(xk+1);
Compute βk+1;
pk+1←-gk+1+βk+1pk;
k←k+1;
end
2.2 ALS-NCG算法设计
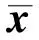
(10)
(11)
ALS-NCG算法伪代码描述如下:
算法2ALS-NCG算法
输入x0
输出xk
k←0;
while gk≠0 do
Compute αk;
xk+1←xk+αkpk;
k←k+1;
end
算法2是改进的ALS算法,将初始值x0作为输入,利用递推关系求解xk并输出。算法3是步长因子αk的计算过程,将算法2求解的xk作为算法3的输入,在求解过程中,需要注意线搜索类型的选择。线搜索类型通常可以分为精确线搜索和非精确线搜索,参数αk对线搜索类型选取至关重要,αk是从xk在沿着pk的方向寻找的一个最好的点,将其作为下一个迭代点,此时最好的点就是函数f(xk+αkpk)在该方向上数值最小的点,但是此时属于精确线搜索状态,其计算量太大,实际应用时具有较高难度,因此,本文算法求解步长因子时选择非精确线搜索类型。c和τ的取值范围为[0,1],本文算法3的参数选择最佳经验结果为:c=0.9,τ=0.5。算法3具体描述如下:
算法3步长因子αk计算算法
输入xk,pk,c=0.9,τ=0.5
输出αk
αk←10;
αk←ταk;
end
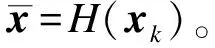
算法4ALS一次迭代算法H(xk)
输入xk
solve U and M from xk;
for i=1,2,…,nudo
End
for j=1,2,…,nmdo
End
2.3 ALS-NCG算法的Spark并行实现
将ALS-NCG算法的数据结构在Spark弹性分布式数据集(Resilient Distributed Dataset,RDD)上分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而在集群中的不同节点上进行并行计算。本文将因子矩阵U和M存储为单精度列块矩阵,分别表示用户子集的因子矢量和电影子集的因子矢量。规定单精度列块的每一块作为RDD的一个分区单元,R和RT的行块均以压缩的稀疏矩阵的方式进行存储。图1所示为M存储的分配方式,将M区块分割成若干块,编号为M1,M2,…,Mnb,共分解成nb块。
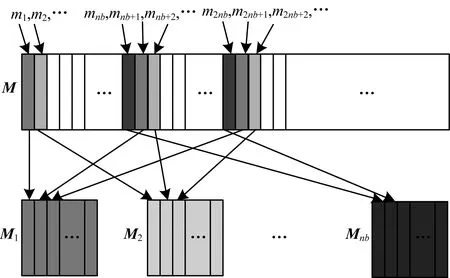
图1 数据在RDD上的分区
U的存储方式与M相同。U和R的RDD分区相同,存储U的节点也可以存储R。在更新U用户块时,需要本地评分在R中可用,而本地U块中用户评分电影的M因子矢量必须混洗。由于电影因子来自不同的节点,可通过建立路由表存储所需的本地评分数据,避免重复发送信息。缓冲区一旦构造,就会被混合集中到R的分区,此时电影因子和本地评分数据可用来计算新的U子块。


图2 RDD路由表策略
3 实验结果与分析
3.1 实验数据集
本文采用MovieLens上10 M大小的数据集进行实验,该数据集包括71 567个用户、10 681部电影和10 000 054条评分,为更好地比较算法性能,ALS与ALS-NCG均使用相同的数据集。在实际应用中,并非所有数据都满足建立实验数据集的要求,因此,本文找到原始完整数据集中按照每个用户评分数目进行排序的中位数,用c表示,舍弃对电影评分数目与中位数值相差较大的用户,保留评分数目与中位数相近的用户,将这些数据组成实验数据集。
3.2 Spark运行环境
Spark是一种类Hadoop MapReduce的基于内存计算的大数据并行计算框架[21],Spark较Hadoop的优势之一是提出了RDD。RDD的高容错性表现在2个方面:1)若其中一个RDD分片丢失,则Spark可以根据日志信息重构RDD;2)在内存中缓存RDD后,只需从内存中读取数据即可计算,这样节省了大量的磁盘存取开销,适合迭代计算的矩阵分解算法。因此,本文搭建Spark集群作为实验平台。
本文将Spark计算集群搭建在Hadoop分布式平台上,以Hadoop中的HDFS作为集群的分布式文件存储系统,选择Spark原生语言Scala[22]作为编程语言,该语言比较简洁完善,是Spark领域较为常用的程序设计语言。本文实验的集群环境配置如表1所示。

表1 实验环境配置
3.3 ALS-NCG算法与ALS算法时间性能比较

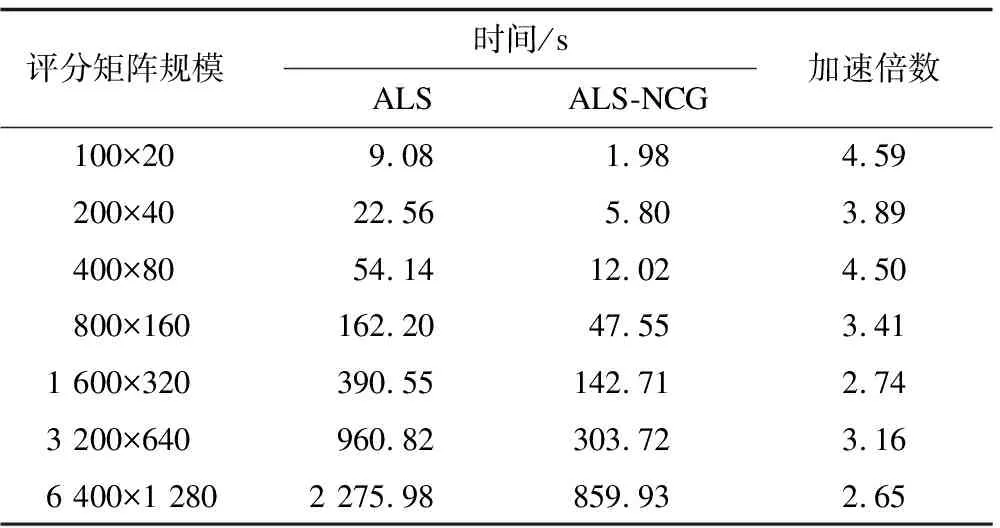
表2 收敛值为10-6时2种算法的时间性能对比

表3 收敛值为10-3时2种算法的时间性能对比
从表2、表3可以看出,ALS-NCG达到目标收敛值较快,相对ALS的加速效果明显。
图3表示不同规模的评分矩阵下2种算法在迭代次数相同时所用时间比值的变化趋势,可以看出,ALS-NCG在时间消耗上比ALS小很多,随着矩阵规模的增大,ALS-NCG的加速效果更明显,性能更加优越。在不同收敛值时,ALS与ALS-NCG的时间性能比值变化趋势近似一致,可见,将改进的组合算法应用于大数据环境中,即使收敛值扩大到10-3,也可以达到同样的加速效果。
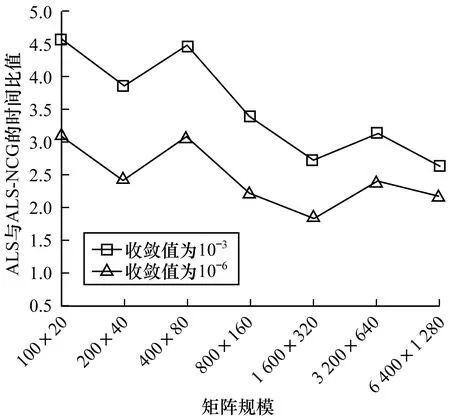
图3 不同收敛值时ALS与ALS-NCG的时间比值对比
3.4 ALS-NCG算法与ALS算法排名精度比较
由于实验条件限制,本文仅对排名前20的电影进行准确度实验,使用电影排名矢量转化所需的成对互换次数作为度量。本次实验借助Kendall-Tau距离来计算向量之间的差异,将距离归一化范围限制在[0,1]之间,再求取所有用户的距离平均值。
若p1=[6,3,1,4,2,5]、p2=[3,4,5,2,6,1]是用户u对2个不同电影的排名,设置t=4表示对排名前4的电影进行排名精度计算。p1中排名第1的电影6在p2中排名第5,若要将p2中电影6排在第1位,需要交换4次位置,此时产生第1次迭代排名顺序p21=[6,3,4,5,2,1],p1中排名第2位的是电影3,在p21中电影3同样排在第2位,此时不需要转换,即p22=p21,同理可得p23=[6,3,1,4,5,2],转换3次,p24=p23,转换0次。匹配p2到p1所需成对互换的距离总数si=4+0+3+0=7。若匹配时相同位置的电影相同,则不需要转换,否则将会发生转换,若匹配与被匹配的序列相反,则会出现最大交换次数,在第1次匹配发生nm-1次交换,第2次匹配发生nm-2次交换,以此类推,最大交换次数可表示为:
smax=(nm-1)+(nm-2)+…+(nm-t)=
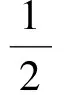
实验2选取400×80和800×160两种规模的评分矩阵,2种算法都以20个不同的随机起始值进行迭代运行求解,达到给定的不同排序精度,记录时间数据,结果如表4、表5所示。从表4、表5可以看出,在排序精度为70%时,ALS对于2种规模矩阵的收敛速度相对较快,而在排序精度大于70%时,ALS收敛时间较长,ALS-NCG的收敛时间比ALS算法小很多,其效率较高。
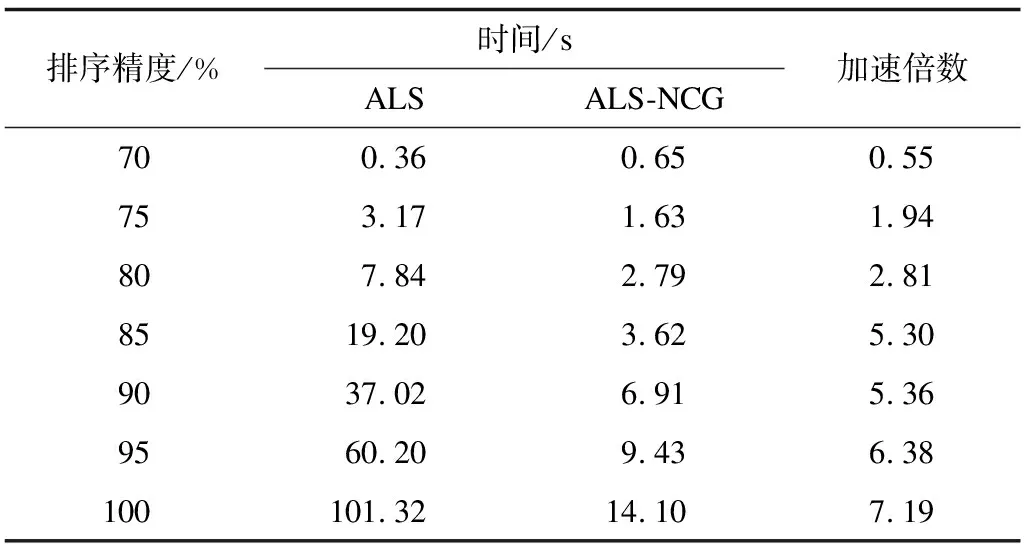
表4 400×80矩阵规模下2种算法的时间对比

表5 800×160矩阵规模下2种算法的时间对比
图4、图5分别呈现矩阵规模为400×80、800×160时2种算法的运行时间趋势。从中可以看出,随着排序精度的提高,ALS-NCG算法的时间消耗变化较为平缓,更符合实际需求,而ALS算法需要更长的时间才能达到目标精度。
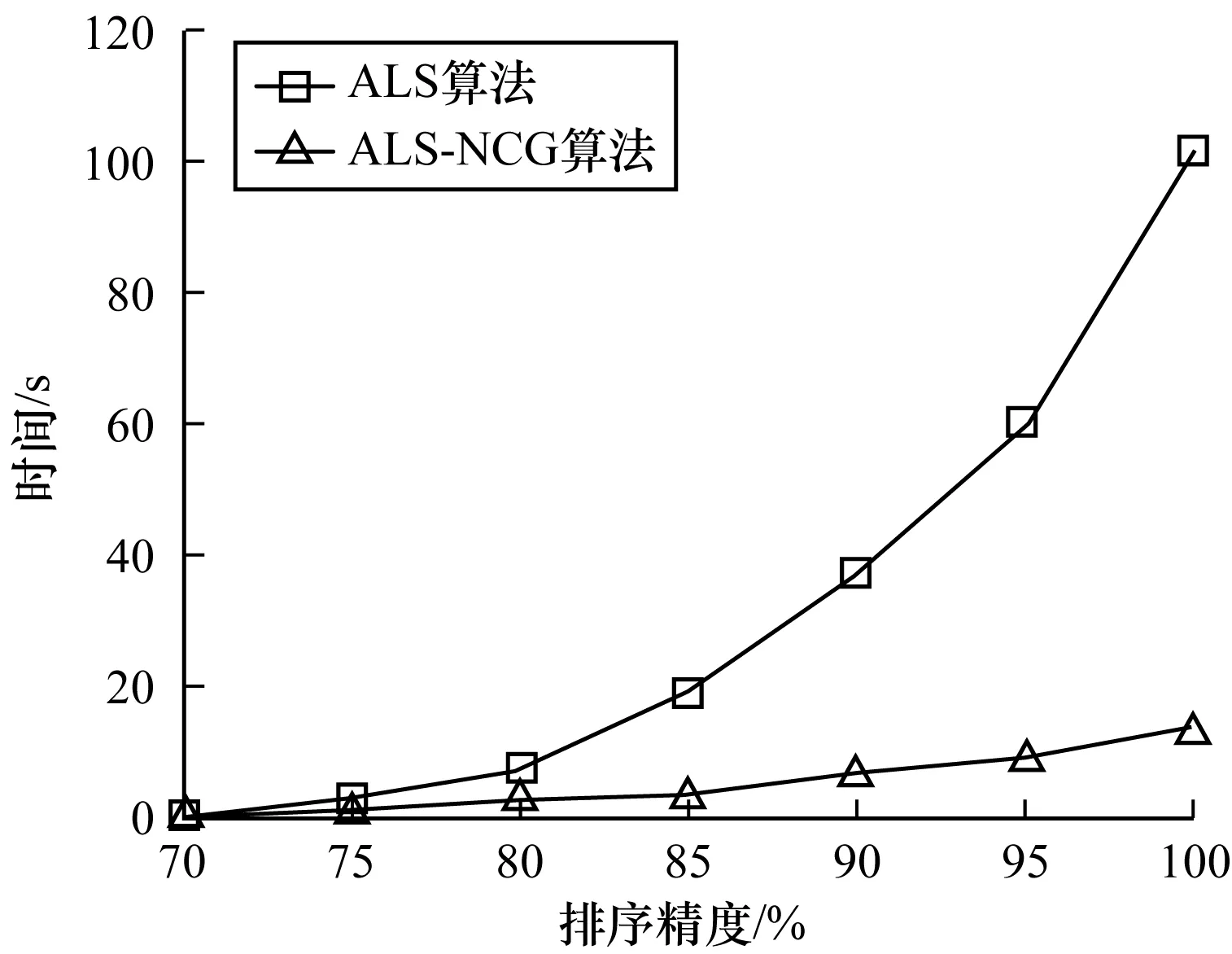
图4 矩阵规模为400×80时的算法时间趋势对比
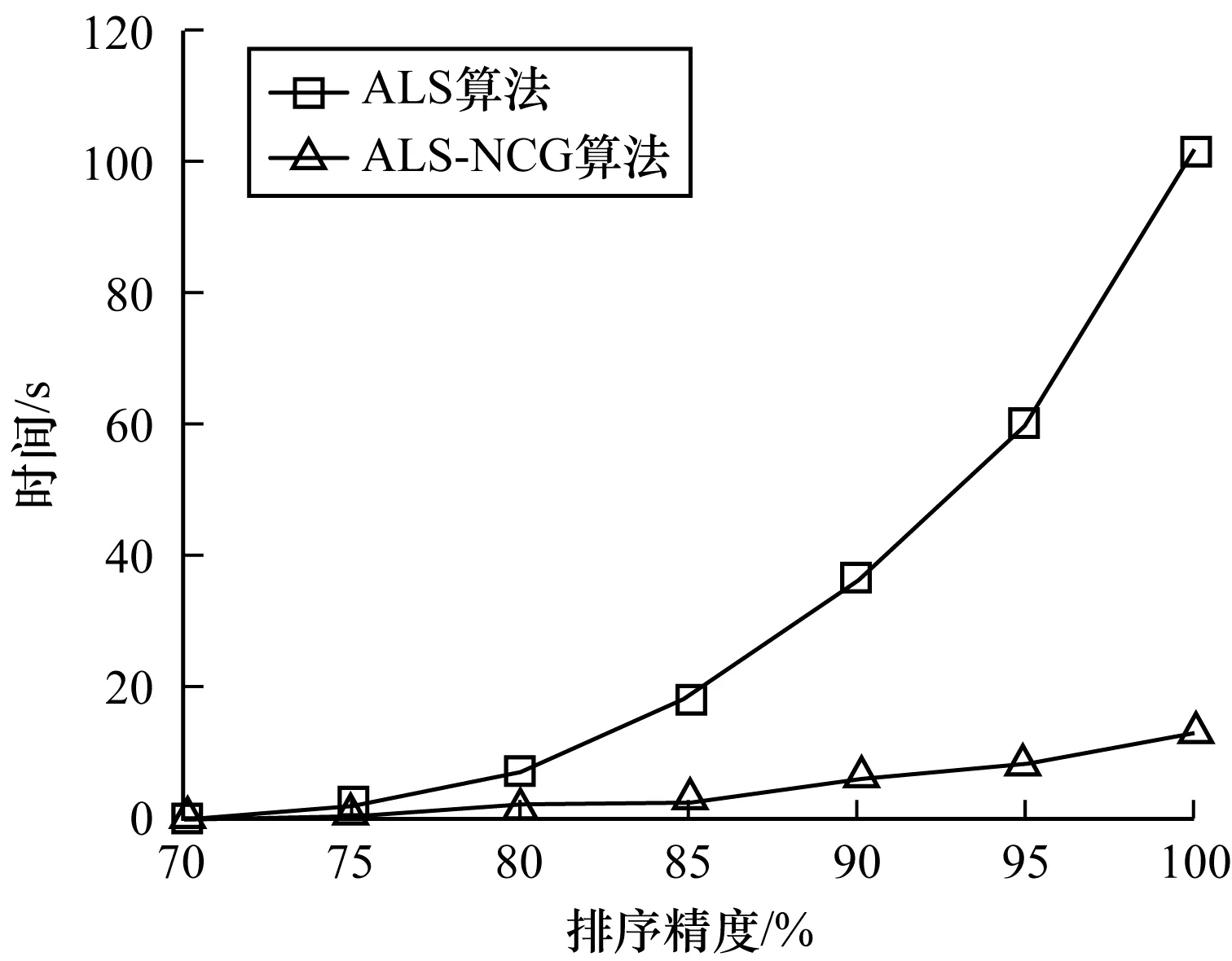
图5 矩阵规模为800×160时的算法时间趋势对比
3.5 ALS-NCG算法与ALS算法性能指标比较
本文采用推荐系统领域常用的均方根误差(Root Mean Squared Error,RMSE)来度量算法的性能。RMSE是预测值与真实值偏差的平方与预测值的比值的平方根,其值越小说明测量的精确度越高。
ALS-NCG算法在执行速度与排序精度上都优于ALS算法,实验3将在ALS训练的最优参数模型的基础上对2种算法的RMSE值进行求解,其中,ALS算法最佳迭代次数为25,实验结果如表6所示。从表6可以看出,ALS-NCG算法达到与ALS算法相近的RMSE值仅需迭代7次,迭代次数明显减少。
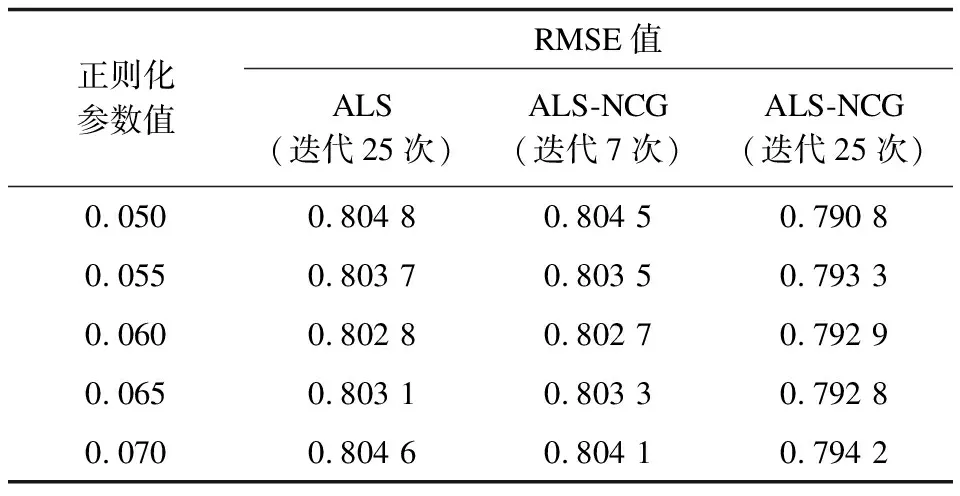
表6 2种算法的RMSE值对比
3.6 ALS-NCG算法与其他算法性能指标比较
将ALS-NCG算法与受限玻尔兹曼机(RBM)、k=21时的k近邻(kNN)算法、ALS算法、ALS+kNN+RBM组合方法以及均值模型的RMSE值进行比较,结果如表7所示。从表7可以看出,ALS-NCG算法具有明显优势,它相对其他算法的RMSE改善率最高可达25.17%。
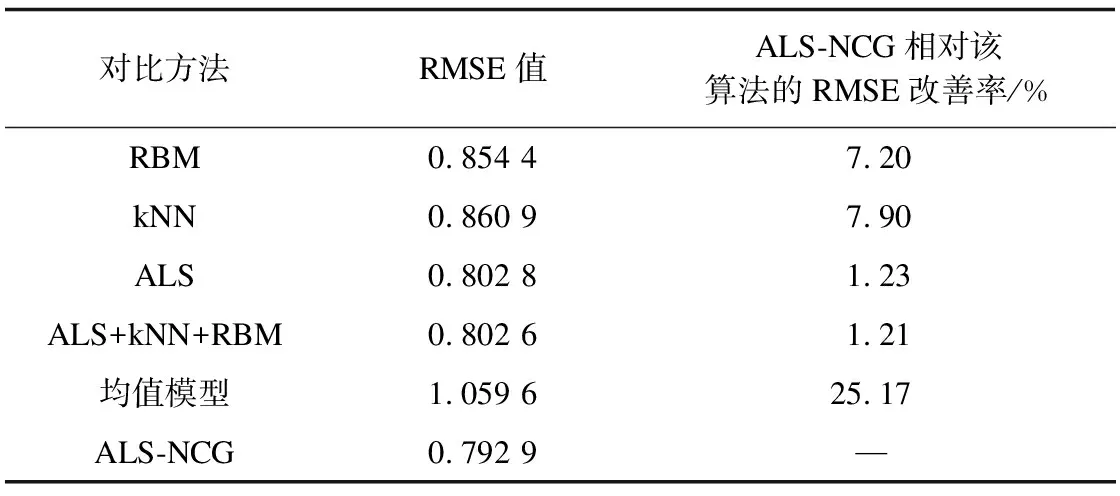
表7 不同方法的RMSE值比较
ALS算法虽然应用于推荐系统时效果较好,但是其迭代时间过长,影响推荐系统性能。NCG算法数值表现良好,并且具有较高的收敛性,可以加速ALS算法的收敛,提高推荐效果。虽然ALS-NCG算法的每一步迭代复杂度较高,但是算法整体收敛程度增大,使得总迭代次数减少,在Spark环境中,其收敛速度明显高于ALS算法,当两者的RMSE值接近时,ALS-NCG算法的迭代次数仅为ALS算法的1/3左右。
4 结束语
基于矩阵分解的ALS算法应用于推荐系统时,执行速率与排名精度均较低。本文分析ALS算法自身存在的问题,提出一种融合NCG与ALS的协同过滤推荐算法ALS-NCG,并在Spark集群环境中进行实验,结果表明,ALS-NCG算法在收敛速度和排名精度上都优于ALS算法。下一步将通过卷积神经网络对用户评论中的文本特征进行学习,并将提取的文本特征引入到ALS-NCG算法中,以进一步改善推荐效果。
猜你喜欢
数学物理学报(2021年4期)2021-08-30 08:27:50
中等数学(2020年1期)2020-08-24 07:57:42
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年8期)2020-01-02 04:45:23
电子制作(2018年11期)2018-08-04 03:25:38
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
测绘科学与工程(2016年5期)2016-04-17 06:51:15
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
